The What, Where, When, and How of Data Processing
第一章主要关注三个领域:术语,准确定义我使用重载术语时的意思,如“流”;批处理和流处理,比较两种类型系统的理论能力,并假设使流处理系统超越批处理系统只有两件事是必要的:correctness and tools for reasoning about time;以及数据处理模式。
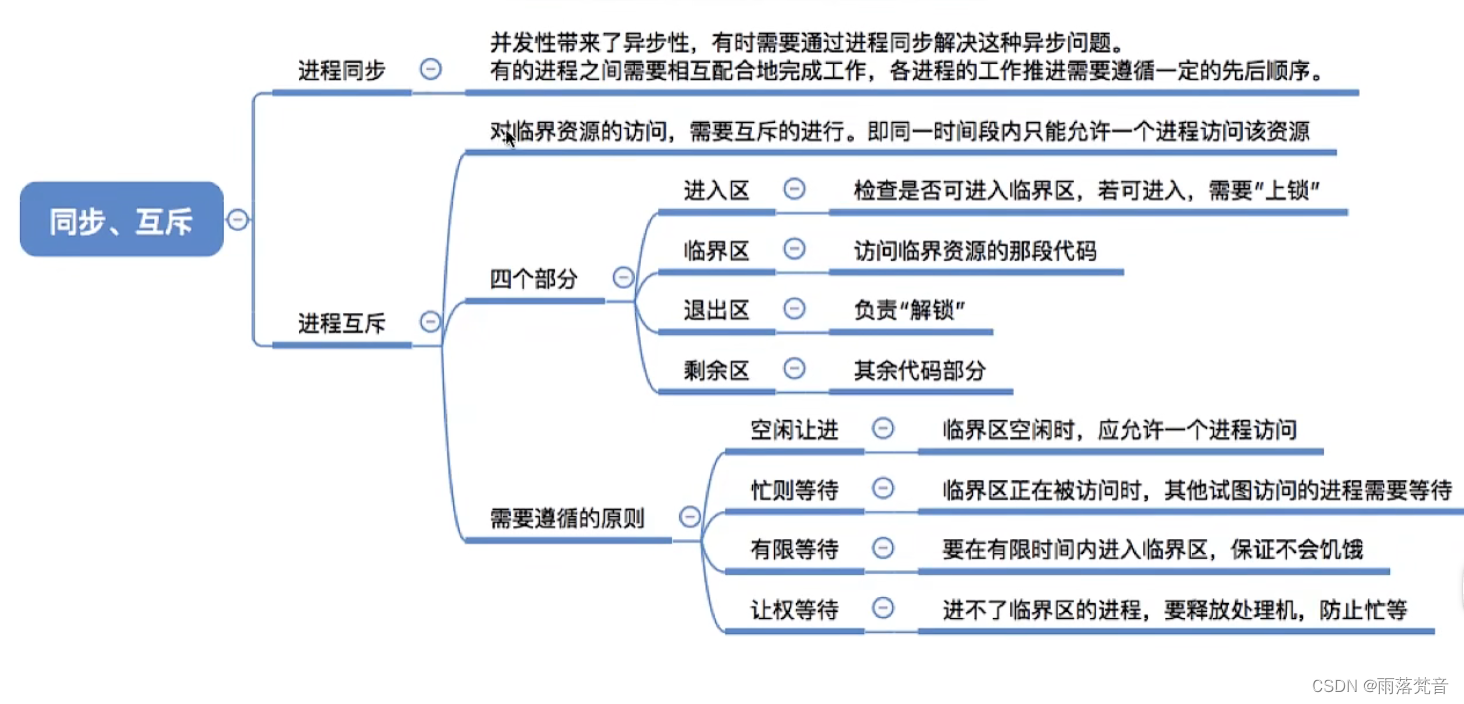
在本章中,我们现在将进一步关注第一章中的数据处理模式,但将在具体示例的上下文中更详细地介绍这些模式。在我们结束之前,我们将讨论我认为的无序数据处理所需的核心原则和概念;这些是用来判断时间的工具,真正超越了传统的批处理。
为了让您了解实际情况,我使用了Apache Beam代码片段,并结合时间推移图来提供概念的可视化表示。Apache Beam是一个统一的编程模型和可移植性层,用于批处理和流处理,有一组使用各种语言(例如,Java和Python)的具体sdk。然后,用Apache Beam编写的管道可以移植地运行在任何受支持的执行引擎上(Apache Apex、Apache Flink、Apache Spark、Cloud Dataflow等)。
Roadmap
为了为本章打下基础,我想列出5个主要概念,这些概念将支持其中的所有讨论,实际上,对于第一部分的其余大部分内容来说,我们已经讨论了其中的两个概念。
在第1章中,我首先确定了事件时间(事件发生的时间)和处理时间(处理过程中观察到它们的时间)之间的关键区别。这为本书提出的一个主要论点提供了基础:如果您既关心正确性,又关心事件实际发生的上下文,那么您必须根据数据的固有事件时间来分析数据,而不是根据分析过程中遇到的处理时间来分析数据。
然后,我介绍了窗口的概念(即,沿着时间边界划分数据集),这是一种常用的方法,用于处理技术上无限的数据源可能永远不会结束的事实。窗口策略的一些简单例子是固定窗口和滑动窗口,但更复杂的窗口类型,如会话(其中窗口是由数据本身的特征定义的;例如,捕获每个用户的活动会话,然后是一个不活动间隙)也会得到广泛的应用。
除了这两个概念,我们现在要仔细看看另外三个:
Triggers
A trigger is a mechanism for declaring when the output for a window should be materialized relative to some external signal.触发器在选择何时发出输出方面提供了灵活性。在某种意义上,您可以将它们视为一种流控制机制,用于指示何时应该实现结果。另一种看待它的方式是,触发器就像相机上的快门释放,允许您在计算结果时声明何时拍快照。
触发器还可以在窗口演化的过程中多次观察窗口的输出。这反过来又为随着时间的推移而细化结果打开了一扇门,它允许在数据到达时提供推测性的结果,以及随着时间的推移处理上游数据的变化(修订)或延迟到达的数据(例如,在移动场景中,某人的电话记录了各种操作和他们的事件时间,而此人离线,然后继续上传这些事件以在恢复连接时进行处理)。
Watermarks
水印是关于事件时间的输入完整性的概念。时间值为X的水印表示:“all input data with event times less than X have been observed”。因此,当观察一个没有已知终点的无界数据源时,水印作为一个进步的度量标准。我们在这一章中接触了水印的基础知识,然后Slava在第三章中对这个主题进行了非常深入的讨论。
水印是针对事件时间而设计的概念,它提供了一种在事件时间相对于处理时间是乱序的系统合理推测无界数据集中数据完整性的手段。
Accumulation
Accumulation模式指定同一窗口观察到的多个结果之间的关系。这些结果可能是完全脱节的;也就是说,表示一段时间内的独立函数,或者它们之间可能有重叠。不同的Accumulation模式具有不同的语义和成本,因此可以在各种用例中找到适用性。
累计类型表示流处理系统在处理单个窗口时,窗口输出后的数据需要随着流处理的时间进展而如何发生改变的变化类型。
what
- 计算出什么结果? transformations within the pipeline可以回答这个问题。这包括计算和,建立直方图,训练机器学习模型等。这也是经典批处理所回答的问题。
Where
- Where in event time are results calculated?(在事件时间中的哪个位置计算结果) 这个问题可以通过在管道中使用事件时间窗口来回答。这包括第一章中常见的窗口示例(固定、滑动和会话);似乎没有窗口概念的用例(例如,时间无关的处理;经典的批处理通常也属于这一类);还有其他更复杂的窗口形式,比如限时拍卖。还请注意,如果您将记录到达系统时的输入时间指定为事件时间,那么它还可以包括处理时间窗口。
When
- When in processing time are results materialized?(在处理时间中的哪个时刻触发计算结果) 这个问题可以通过使用触发器和(optionally)水印来回答。在这个主题上有无数的方案,但是最常见的模式是那些涉及到重复更新的模式(例如,物化视图语义),那些只有在相应的输入被认为是完整的之后才利用水印为每个窗口提供单个输出的模式(例如,经典的批处理语义应用于每个窗口),或者两者的一些组合。
How
How do refinements of results relate? (如何修正结果)使用的accumulation类型可以回答这个问题:discarding(结果都是独立和独立的)、accumulating(后面的结果建立在前面的结果的基础上),或accumulating and retracting(累积值和先前触发值的撤回都被触发)。
Batch Foundations: What and Where
好了,我们开始吧。第一站:批处理。
What: Transformations
在经典批处理中transformations applied回答了这样一个问题:“计算出了什么结果?”“尽管你可能已经熟悉了经典的批处理,但我们还是要从那里开始,因为它是我们添加其他所有概念的基础。
在本章的其余部分(实际上,贯穿本书的大部分内容),我们看一个简单的例子:在由9个值组成的简单数据集上计算键值整数和。让我们假设我们正在编写一款基于团队的手机游戏,并且我们希望能够通过将用户手机所报告的个人分数相加而计算出团队分数。如果我们要在名为“UserScores”的SQL表中捕获我们的9个示例分数,它可能看起来像这样:
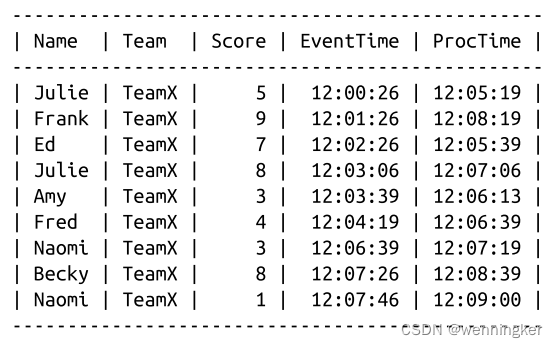
注意,这个例子中的所有分数都来自同一个团队的用户;这是为了使示例保持简单,因为我们在下面的图中只有有限的维数。因为我们是分组的,所以我们只关心最后三列:
- Score
与此事件关联的单个用户得分 - EventTime
分数发生的时间 - ProcTime
the time at which the score was observed by the pipeline
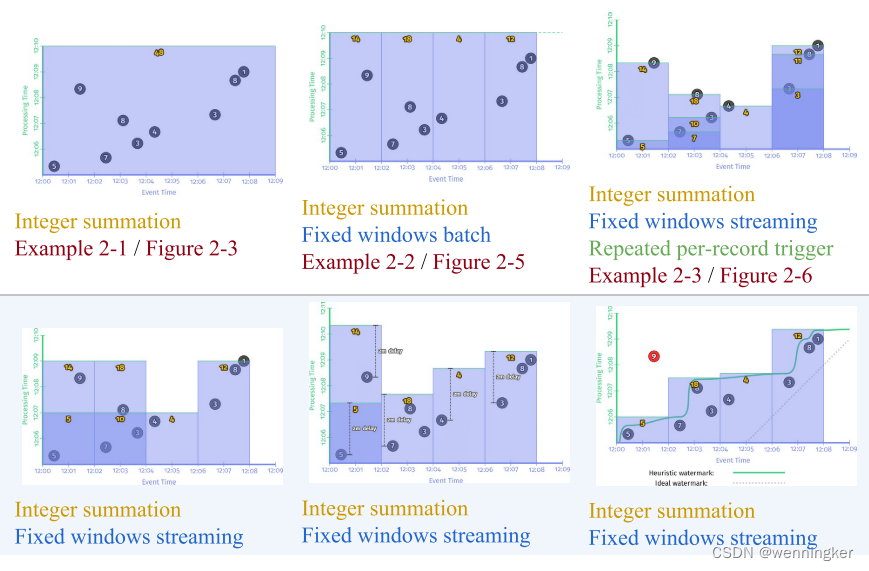
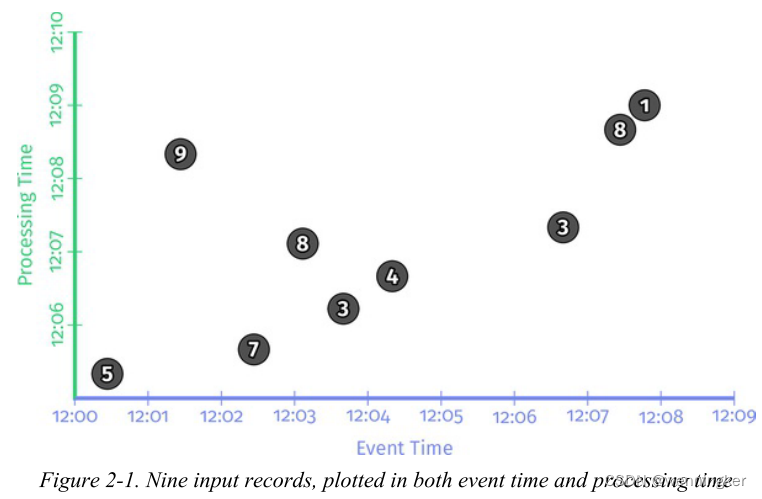
对于每个示例pipeline,我们将查看一个时间推移图,该图突出显示数据如何随时间变化。这些图表将我们所关心的两个时间维度上的9个分数表示出来:x轴上是事件时间,y轴上是处理时间。图2-1演示了输入数据的静态图。
如果您已经熟悉Spark或Flink之类的东西,那么您应该能够相对容易地理解Beam代码的功能。但为了给你一个速成课程,在Beam中有两个基本的原语:
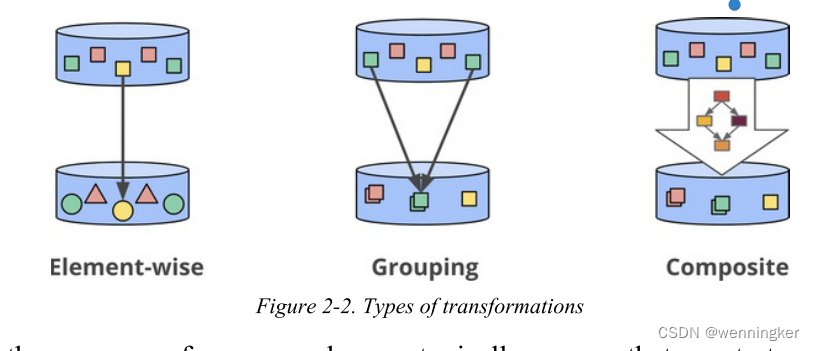
- PCollections
这些表示可以跨数据集(可能是大量的数据集)执行并行转换(因此名称开头有“P”)。 - PTransforms
这应用于PCollections以创建新的PCollections。PTransforms可以执行元素方向的转换,它们可以将多个元素分组/聚合在一起,或者它们可以是其他PTransforms的复合组合,如图2-2所示。
为了我们的例子,我们通常假设我们从一个名为“input”的预先加载的PCollection<KV<Team, Integer>>开始(也就是说,一个由Teams和Integers的键/值对组成的PCollection,其中Teams是类似于代表球队名称的字符串,而Integers是对应球队中任何个人的分数)。在实际的管道中,我们可以通过从I/O源读取PCollection<String>的原始数据(例如,日志记录)来获取输入,然后通过将日志记录解析为适当的键/值对,将其转换为PCollection<KV<Team, Integer>>。为了清晰起见,在第一个示例中,我包含了所有这些步骤的伪代码,但是在后面的示例中,我省略了I/O和解析。
因此,对于简单地从I/O源读取数据、解析团队/分数对并计算每个团队的分数之和的管道,我们将会看到如例2-1所示的内容。

键/值数据从I/O源读取,键为Team(例如,团队名称的字符串),值为Integer(例如,团队成员的分数)。然后将每个键的值相加,以在输出集合中生成每个键的总和(例如,团队总得分)。
每个图在两个维度上绘制输入和输出:事件时间(x轴)和处理时间(y轴)。因此,管道所观察到的是实时从下到上的过程,由水平黑线表示,该黑线在处理时间轴上随时间的推移而上升。输入是圆,圆内的数字表示特定记录的值。它们开始是浅灰色的,随着管道的观察逐渐变暗。
当管道观察值时,它将这些值累积到中间状态,并最终将累积的结果具体化为输出。状态和输出用矩形表示(灰色表示状态,蓝色表示输出),聚合值靠近顶部,矩形所覆盖的区域表示累积到结果中的事件时间和处理时间的部分。对于例2-1中的管道,在经典的批处理引擎上执行时,它看起来就像图2-3所示的那样。
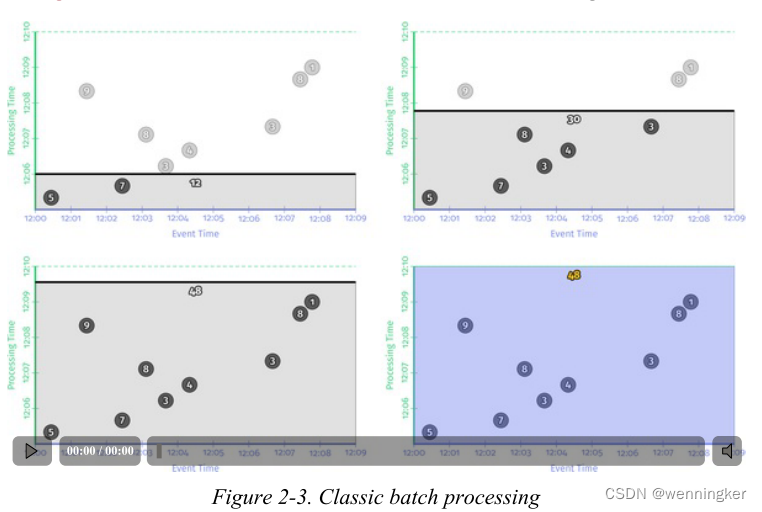
因为这是一个批处理管道,它会累积状态,直到看到所有的输入(由顶部的绿色虚线表示)。在这个例子中,我们在计算所有事件时间的总和。因为我们没有应用任何特定的窗口转换;因此状态和输出的矩形覆盖了整个x轴。然而,如果我们想处理一个无限制的数据源,经典的批处理是不够的;我们不能等待输入结束,因为它实际上永远不会结束。我们需要的概念之一是窗口,我们在第一章中介绍过。因此,在我们第二个问题的上下文中——“在事件时间的什么地方计算结果?”——我们现在会简要地重新讨论窗口。
Where: Windowing
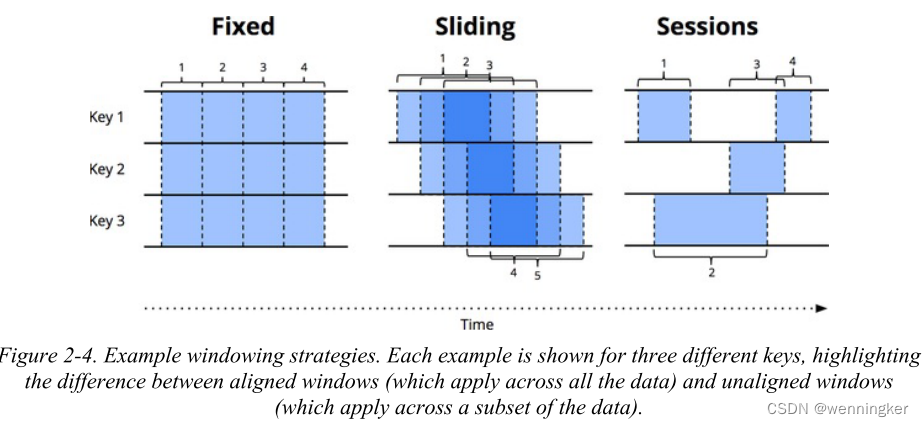
如第一章所述,窗口是沿着时间边界分割数据源的过程。常用的窗口策略有固定窗口、滑动窗口和会话窗口,如图2-4所示。
为了更好地理解在实践中窗口是什么样子的,让我们将整数求和管道设置为固定的、两分钟的窗口。对于Beam,这个改变只是简单地添加了一个Window.into transform,你可以在例2-2中看到它突出显示。

回想一下,Beam提供了一个统一的模型,既适用于批处理,也适用于流处理,因为从语义上讲批处理实际上只是流处理的一个子集。因此,让我们先在批处理引擎上执行这个管道;机制更加直接,当我们切换到流引擎时,它将提供给我们一些直接比较的内容。结果如图2-5所示。
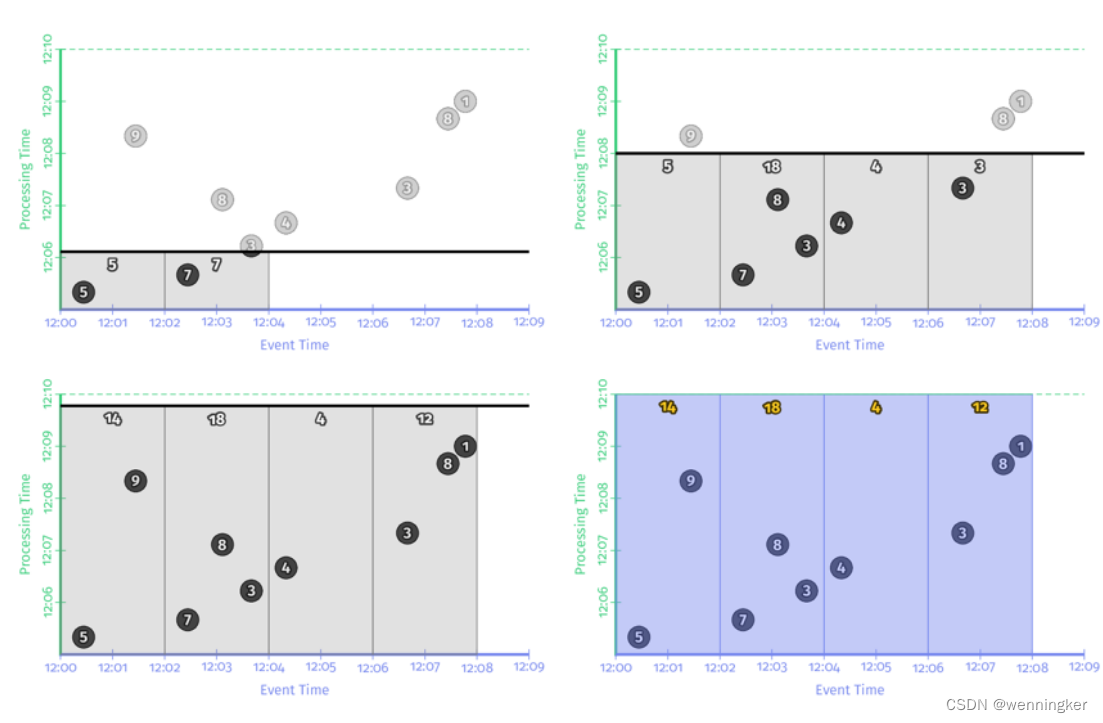
与前面一样,输入一直处于accumulated状态,直到它们被完全处理结束,然后才产生输出。然而,在本例中,我们得到的不是一个输出,而是四个:四个相关的两分钟事件时间窗口的每个都有一个输出。至此,我们重新回顾了我在第一章中介绍的两个主要概念:event-time and processing-time domains之间的关系,以及窗口。如果我们想更进一步,我们需要开始添加本节开始时提到的新概念:triggers,
watermarks, and accumulation.
Going Streaming: When and How
我们刚刚观察了批处理引擎上窗口管道的执行情况。但是,理想情况下,我们希望结果有更低的延迟,并且我们还希望本机处理无限的数据源。切换到流引擎是朝着正确方向迈出的一步,但我们之前的策略是等到我们的输入全部被处理后再生成输出,这种策略不再可行。
When: The Wonderful Thing About Triggers Is Triggers Are Wonderful Things!
触发器提供了这个问题的答案:“在处理时间中,什么时候输出结果?”触发器声明窗口的输出在处理时间内应该发生(尽管触发器本身可能会根据在其他时间域发生的事情做出这些决定,例如事件时间域的水印进展,我们稍后将看到)。窗口的每个特定输出被称为窗口的一个pane。
虽然可以想象出相当广泛的触发语义,但从概念上讲,通常只有两种类型的触发器有用,实际应用中几乎总是使用其中一种或两者的结合:
Repeated update triggers
- 随着窗口内容的出现,这些组件会周期性地为窗口生成更新的panes。这些更新可以与每个新记录一起实现,也可以在一些processing-time延迟之后发生,比如每分钟一次。为重复更新触发器选择周期主要是为了平衡延迟和成本。
Completeness triggers
- 仅当窗口的数据完整时,才输出窗口结果。跟传统批处理非常类似。只不过窗口的大小不同,传统批处理是要等整个数据集的数据都到齐,才进行计算。
重复更新触发器是最常用的触发器,因为其易于理解和使用,并且跟数据库中的物化视图语义非常相似。流计算中,完整性触发器的语义跟传统批处理更相似,能够处理late event。Watermark是驱动Completeness Triggers被触发的原语。接下来我们会重点介绍watermark。
我们先看个重复更新触发器的代码示例片段,这个片段实现了每个元素都触发的功能:
PCollection<KV<Team, Integer>> scores = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))
.triggering(Repeatedly(AfterCount(1))));
.apply(Sum.integersPerKey());
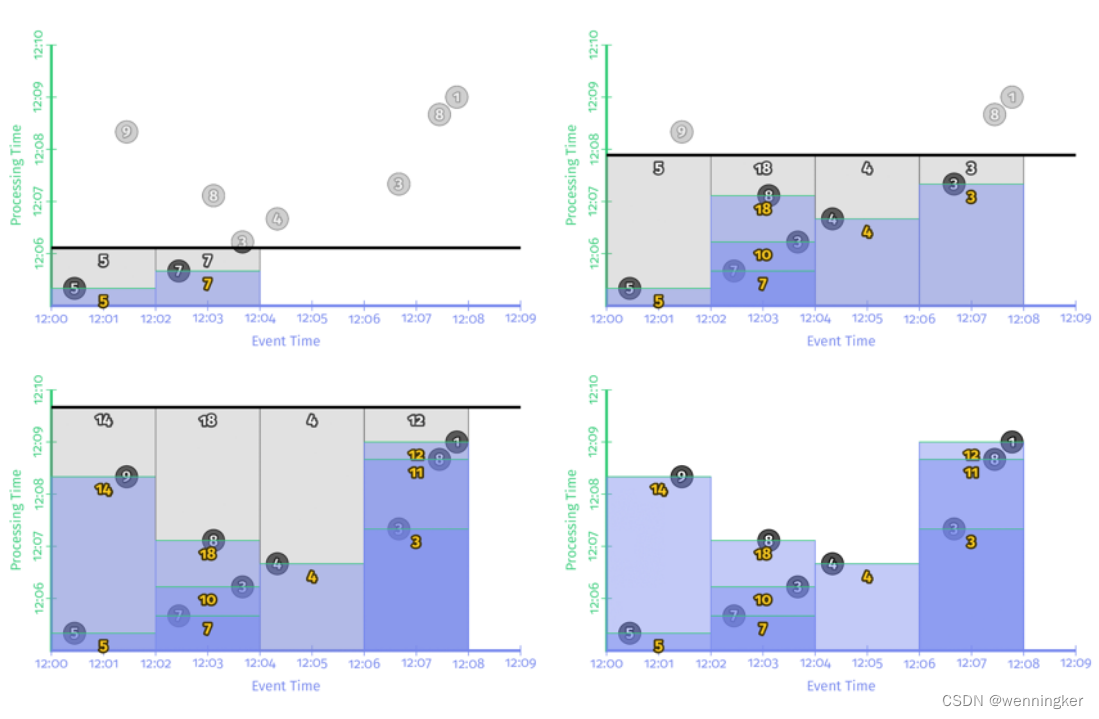
您可以看到我们现在如何为每个窗口获得多个输出(窗格)一次输入对应一次输出。这种触发模式在输出流被写入某种表(您可以简单地轮询结果)时工作得很好。无论何时查看这个表,都将看到给定窗口的最新值,并且这些值将随着时间的推移而趋于正确性。
每个事件都触发计算的模式不适合在大规模数据量的情况下使用,系统的计算效率会非常低,并且会对下游系统造成很大的写压力。一般情况下,在实际使用过程中,用户通常会在处理时间上定义一个延时,多长时间输出一次(比如每秒/每分钟等)。
触发器中,在处理时间延时上有两种方式:
- 对齐延时:将处理时间上切分成固定大小的时间片,对每个key的每个窗口,时间片大小都相同。
- 非对齐延时:延时时间与窗口内数据有关。
译者注:简单理解,对齐延时,就是按固定时间来触发计算。而非对齐延时,是按照数据进入系统的时间+延时时间触发计算。
对齐延时
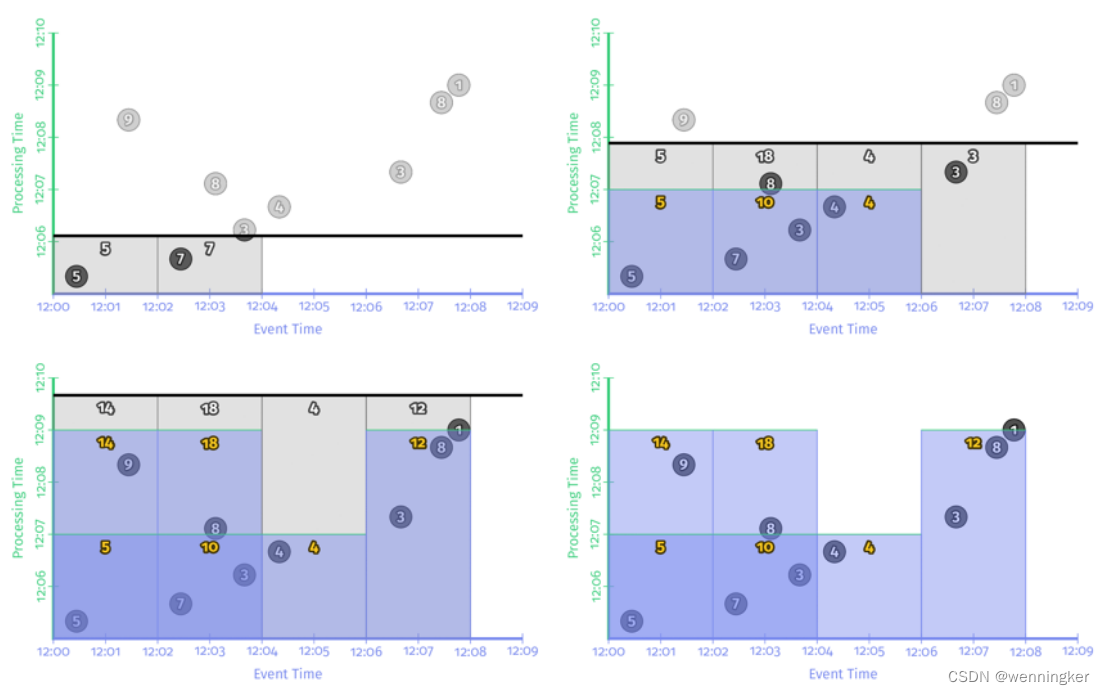
每两分钟各个窗口都会输出一次数据。好处是会定期输出结果。缺点是如果数据有负载高峰,在tps很高的时候,系统的负载也会很高。
非对齐延时
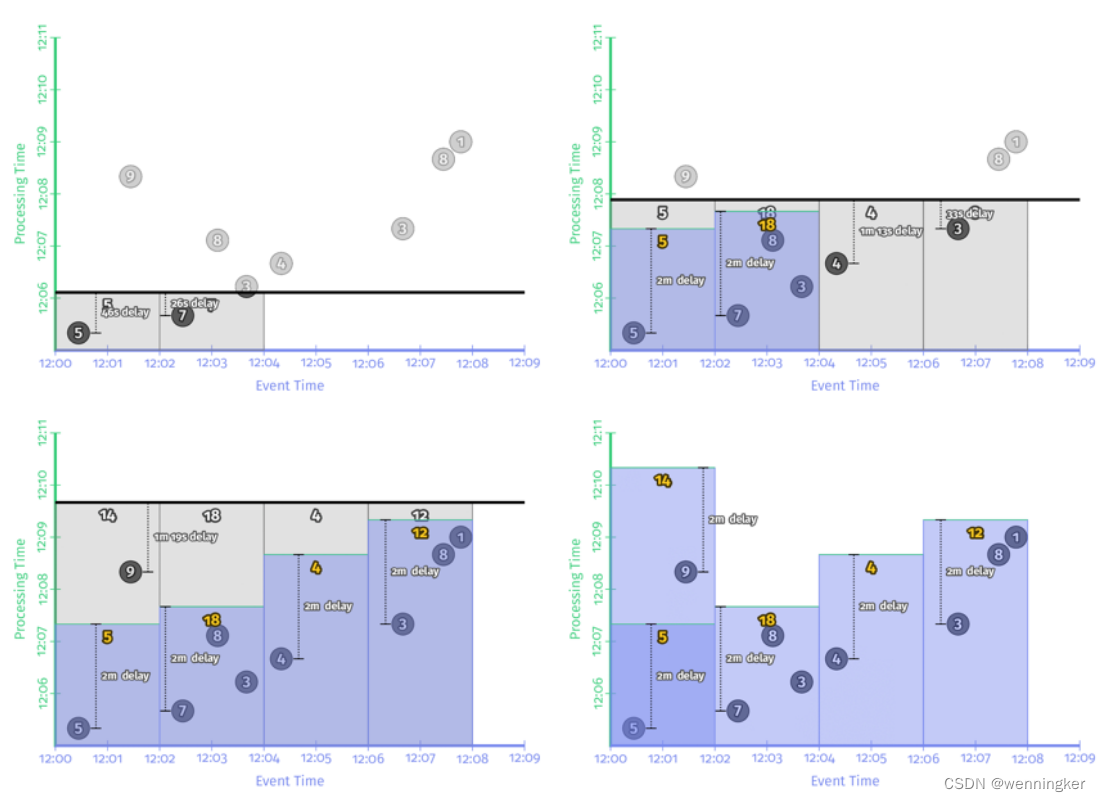
将非对齐延迟与对齐延迟进行对比,可以很容易地看出非对齐延迟如何在时间上更均匀地分散负载。任何给定窗口所涉及的实际延迟在两者之间是不同的,有时多一些,有时少一些,但最终平均延迟基本上保持不变。从这个角度来看,对于大规模处理来说,非对齐延迟通常是更好的选择,因为它们会导致负载随时间的分布更加均匀。
重复更新触发器使用和理解起来非常简单,但不能保证计算结果的正确性,无法处理late event。而Completeness triggers(完整性触发器)能解决这个问题。我们先来了解一下watermark。
When: Watermarks
水印是回答这个问题的一个支持方面:“在处理时间中,什么时候才能实现结果?”“水印是事件时间域内输入完整性的时间概念。换句话说,它们是系统度量进度和相对于事件流中处理的记录的事件时间的完整性的方式(有界或无界,尽管在无界情况下它们的有用性更明显)。
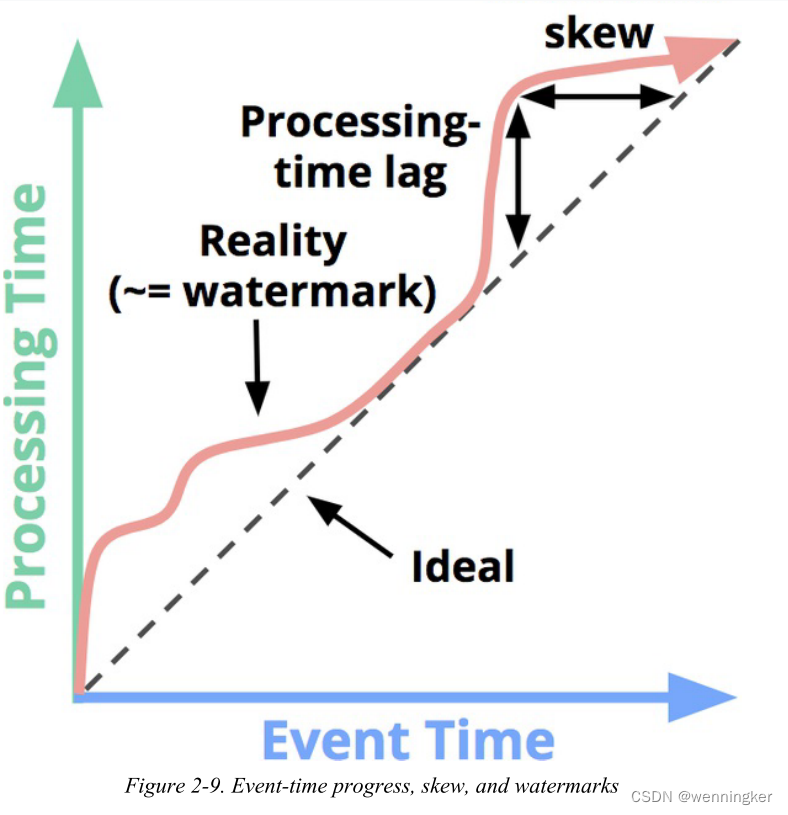
我声称代表现实的那条蜿蜒的红线本质上是水印;随着处理时间的进展,它捕获事件时间完整性的进展。从概念上讲,您可以将水印看作一个函数F§→E,它取一个处理时间点并返回一个事件时间点。事件时间点E,是系统认为所有事件时间小于E的输入都被观测到的点。换句话说,它是一个断言,不会再看到更多事件时间小于E的数据。根据水印的类型,完美或启发式(perfect or heuristic):
Perfect watermarks
对于我们完全了解所有输入数据的情况,可以构造一个Perfect watermarks。在这种情况下,没有迟到数据这回事;所有的数据都是提前或准时的。
Heuristic watermarks
对于许多分布式输入源,完全了解输入数据是不切实际的,在这种情况下,下一个最佳选择是提供启发式水印。启发式水印使用任何可用的输入信息(分区、分区内的排序,如果有的话,文件的增长速度等)来提供尽可能准确的进度估计。在许多情况下,这样的水印可以非常准确地预测。即便如此,启发式水印的使用意味着它有时可能是错误的,这将导致延迟的数据。我们将向您展示处理迟来数据的方法。
因为它们提供了相对于我们的输入的完整性概念,所以水印构成了前面提到的第二种类型触发器的基础:完整性触发器。
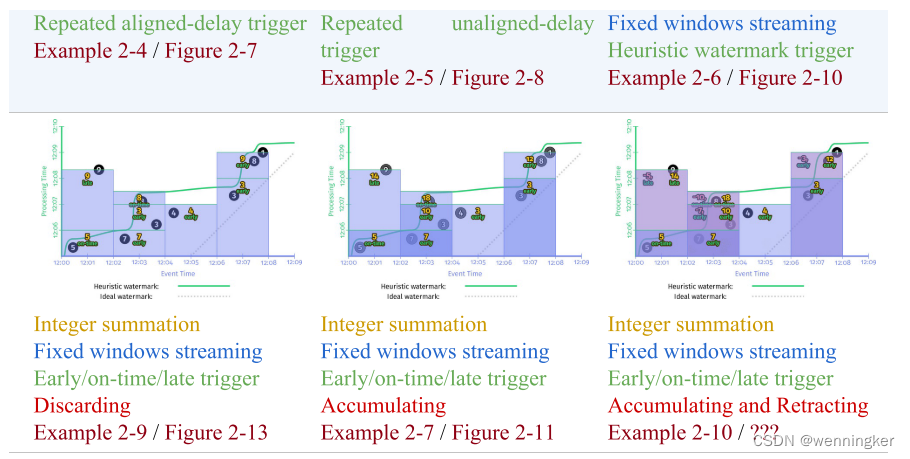
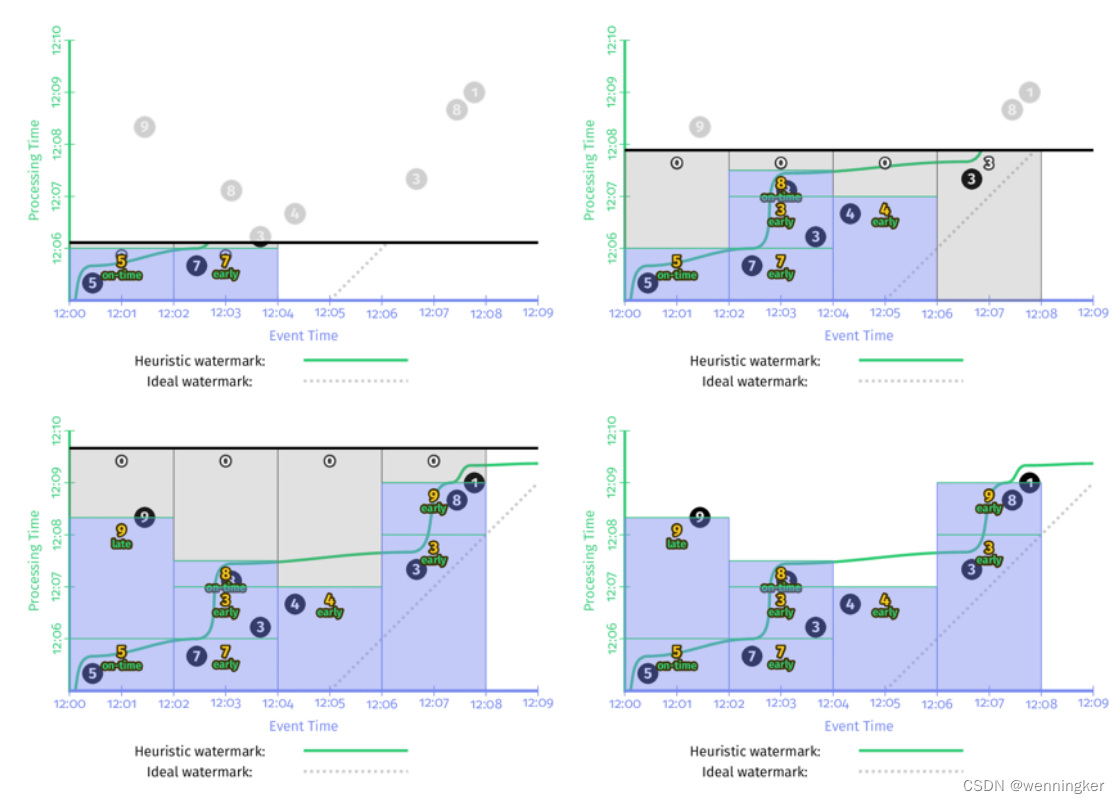
如果能确切知道数据是否完整,就可以用Prefect Watermark。如果不能,则要使用启发式watermark。下图是在同一个数据集上使用两种不同的watermark的行为,左边是perfect watermark,右边是启发式的watermark。
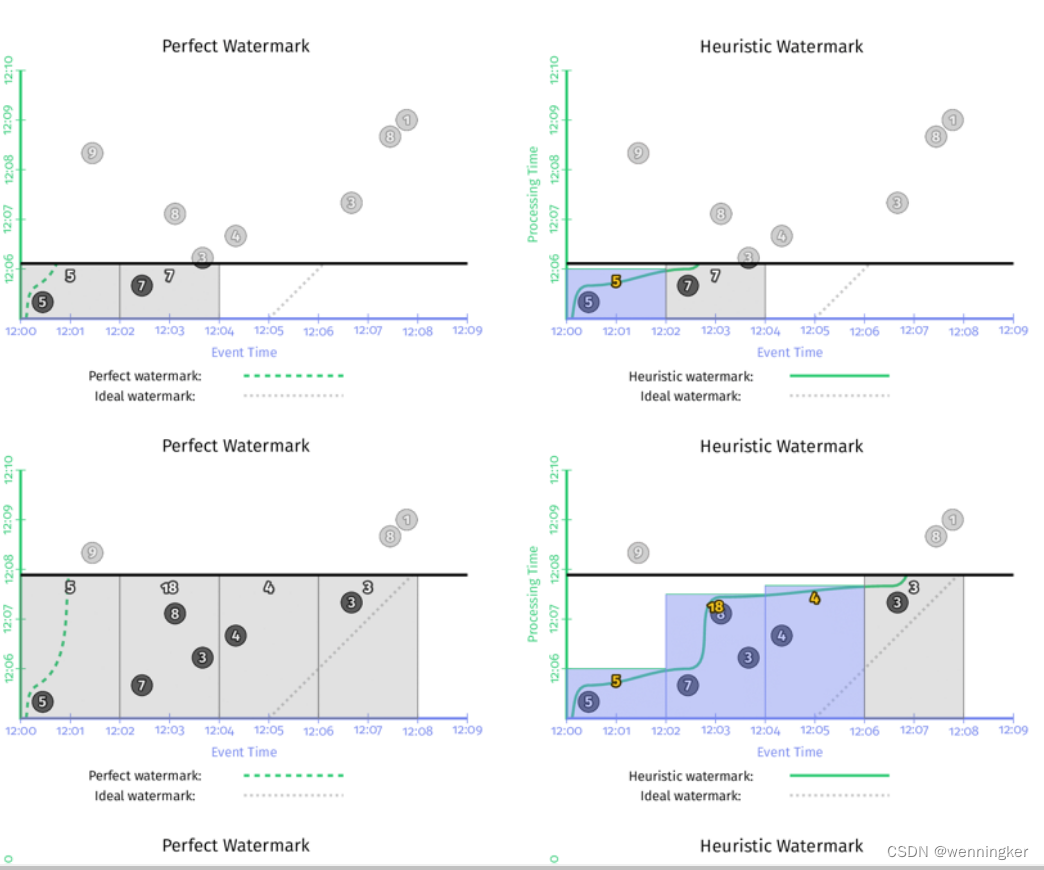
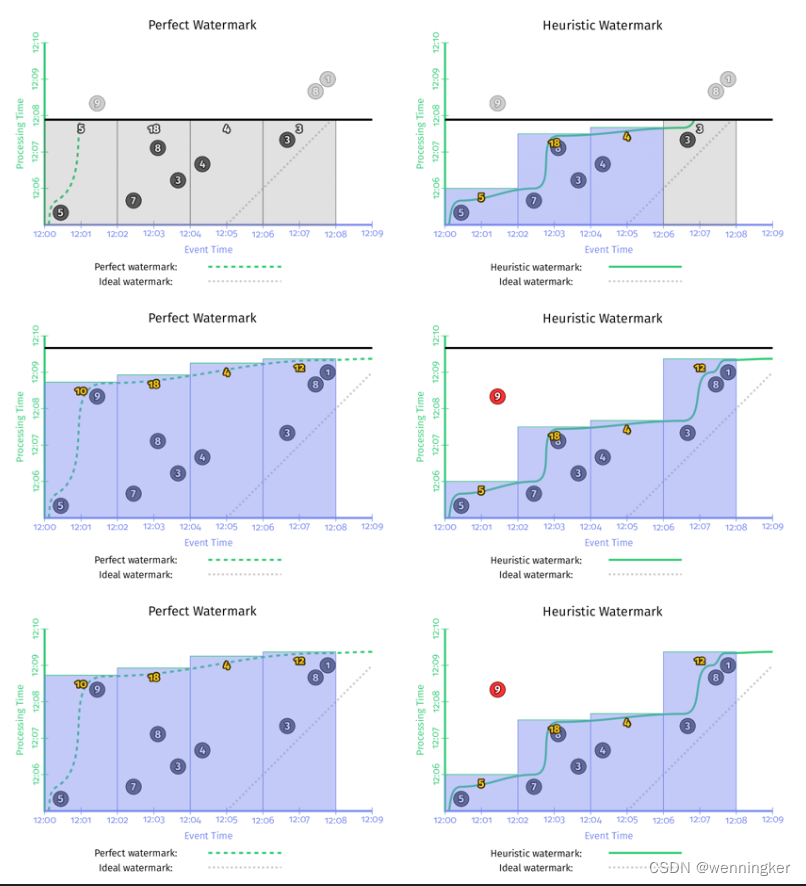
在以上两种情况中,每次watermark经过event time窗口时,窗口都会输出计算结果。区别是perfect watermark的结果是正确的,但推断型watermark的结果是错误的,少了第一个窗口中‘9’这个数据。
在两个流的outer join场景中,如何判断输入数据是否完整?是否能做join?如果采用在process time上延时的重复更新型触发器进行计算,如果数据在event time有较大延时或者数据有乱序,那么计算结果就错了。在这种场景下,event time上的watermark对处理late event,保证结果正确性,就非常关键了。
当然,没有完美的设计,watermark也有两个明显的缺点:
- 输出太慢:如果数据流中有晚到数据,越趋近于perfect watermark的watermark,将会一直等这个late event,而不会输出结果,这回导致输出的延时增加。如上图左边的一侧所示。在[12:00,12:02)这个窗口的输出,与窗口第一个元素的event time相比,晚了将近7分钟。对延时非常敏感的业务没办法忍受这么长的延时。
- 输出太快:启发式watermark的问题是输出太快,会导致结果不准。比如上图中右边一侧所示,对late event ‘9’,被忽略了。
因此,水印并不能同时保证无界数据处理过程中的低延时和正确性。既然重复更新触发器(Repeated update triggers)可以保证低延时,完整性触发器(Completeness triggers),能保证结果正确。那能不能将两者结合起来呢?
When: early/on-time/late triggers FTW!
上文中,我们介绍了两种触发器:重复更新触发器(Repeated update triggers)和完整性触发器(Completeness triggers),如果将两种触发器的优势结合,即允许在watermark之前/之时/之后使用标准的重复更新触发器。就产生了3种新的触发器:early/on-time/late trigger:
- Zero or more early panes:在watermark经过窗口之前,即周期性的输出结果。这些结果可能是不准的,但是避免了watermark 输出太慢的问题。
- A single on-time pane:仅在watermark通过窗口结束时触发一次。这时的结果可以看作是准确的。
- Zero or more late panes:在watermark通过窗口结束边界之后,如果这个窗口有late event,也可以触发计算。这样就可以随时更新窗口结果,避免了输出太快导致的结果不对的问题。
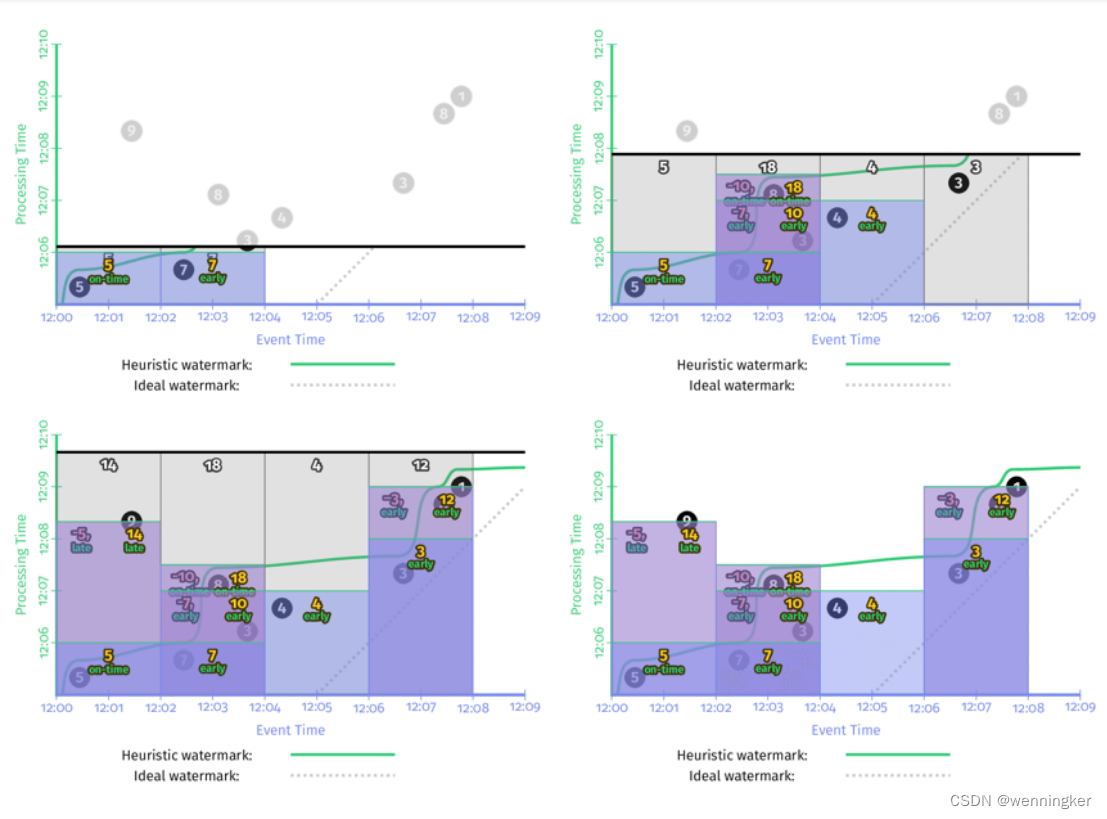
在本章的例子中,在watermark的基础上,如果加一个1min的early firing trigger和一个每个record都会输出的late firing trigger,那么在event time上2min的窗口,使用1min的early firing trigger每隔一分钟就会输出一次,并且如果有late event,late firing trigger还能纠正之前窗口输出的结果。这样保证了正确性的情况下,还不增加延时。
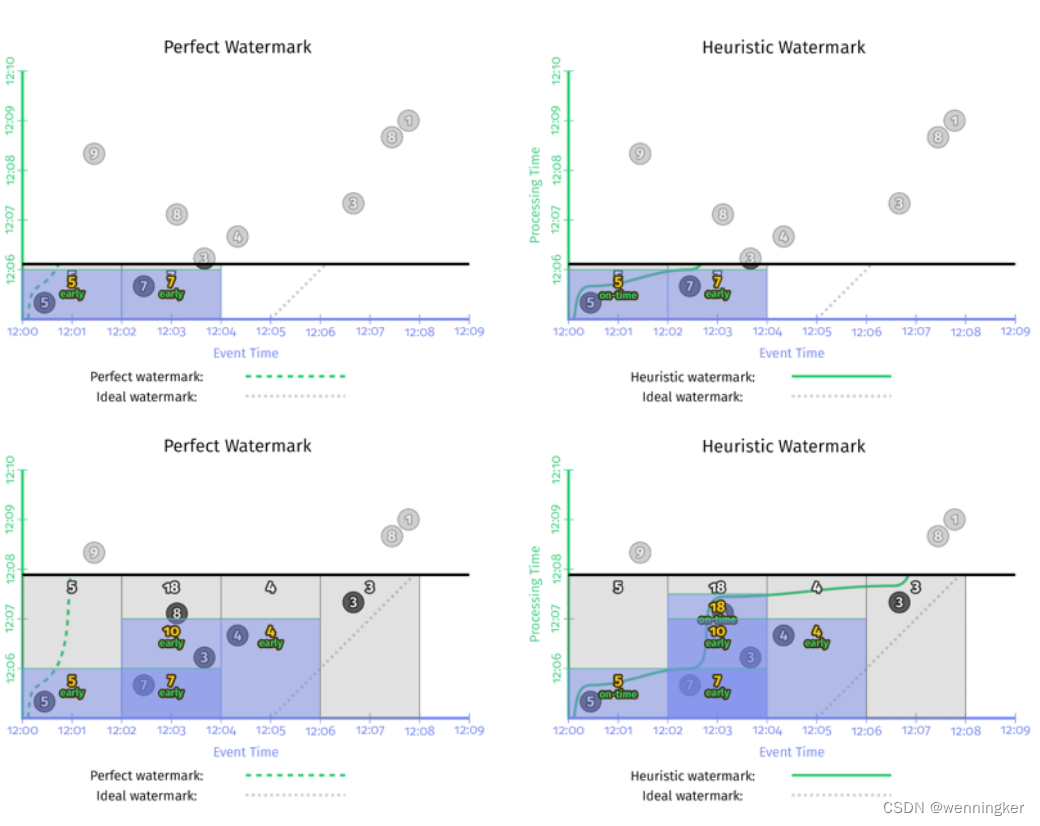
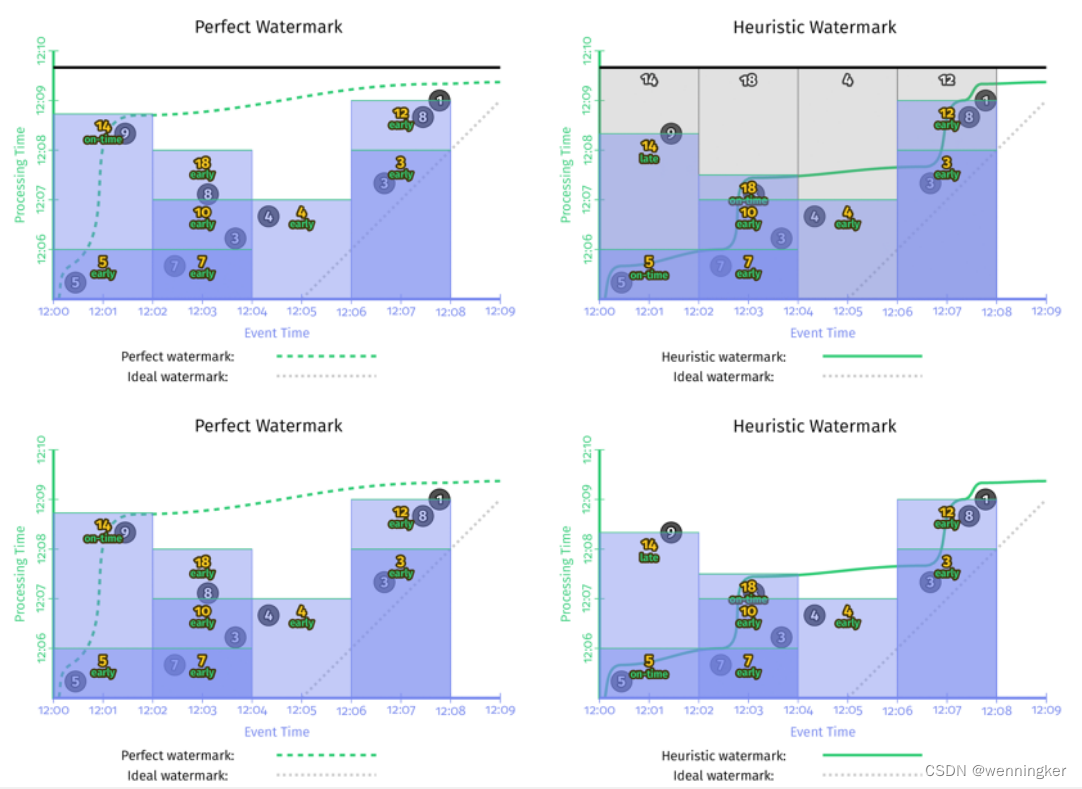
由上如所示,加上了early firing trigger和late firing trigger后,完美型watermark和推断型watermark的结果就一致了。与没有加这两种trigger的实现相比,有了两点很明显的改进:
- 输出太晚(too slow):在左侧perfect watermark的时序图中,第二个窗口[12:02,12:04)中,如果没有加early firing trigger,第一个数据‘7’发生的时间是12:02, 窗口的输出是12:09,第二个窗口的输出延时了近7分钟。加了early firing trigger之后,窗口第一次输出时间是12:06,提前了3分钟。上图右侧启发式watermark情况也非常类似。
- 输出太早(too fast):第一个窗口[12:00,12:02)中,启发式窗口的watermark太早,late event ‘9’没有被算进去,加了late firing trigger之后,当’9’进入系统时,会触发窗口的再次计算,更正了之前窗口输出的错误结果,保证了数据的正确性。
完美型watermark和推断型watermark一个非常大的区别是,在完美型watermark例子中,当watermark经过窗口结束边界时,这个窗口里的数据一定是完整的,因此得出该窗口计算结果之后,就可以吧这个窗口的数据全部删除。但启发式watermark中,由于late event的存在,为了保证结果的正确性,需要把窗口的数据保存一段时间。但其实我们根本不知道要把这个窗口的状态保存多长时间。这就引出了一个新的概念:允许延时(allowed lateness)。
When: Allowed Lateness (i.e., Garbage Collection)
为了保证数据正确性,当late event到来后能够更新窗口结果,因此窗口的状态需要被持久化保存下来,但到底应该保存多长时间呢?实际生产环境中,由于磁盘大小等限制,某窗口的状态不可能无限的保存下去。因此,定义窗口状态的保存时间为allowed lateness(允许的延迟)。也就是说,过了这个时间,窗口中数据会被清掉,之后到来的late event就不会被处理了。
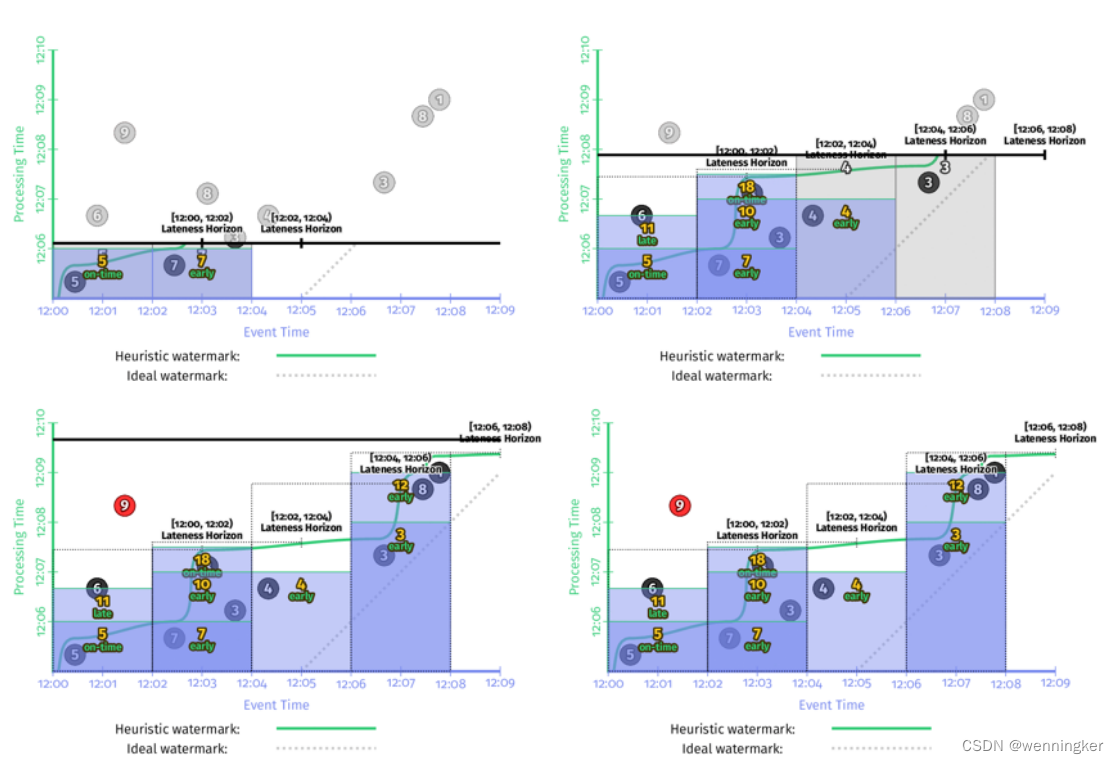
关于allowed lateness的两个重点:
- 如果数能够使用perfect watermark,即有序,则不需要考虑allowed lateness的问题
- 如果是对有限个key做全局聚合,则不必考虑allowed lateness问题。(因为部分全局聚合比如sum/agg等,可以做增量计算,不必要保存所有数据)
How: Accumulation
如果遇到late event,要如何修改窗口之前输出的结果呢?有三种方式:
- Discarding(抛弃):每个窗口产生输出之后,其state都被丢弃。也就是各个窗口之间完全独立。比较适合下游是聚合类的运算,比如对整数求和。
- Accumulating(累积):所有窗口的历史状态都会被保存,每次late event到了之后,都会触发重新计算,更新之前计算结果。这种方式适合下游是可更新的数据存储,比如HBase/带主键的RDS table等。
- Accumulating & Retracting(累积&撤回):Accumulating与第二点一样,即保存窗口的所有历史状态。撤回是指,late event到来之后,出了触发重新计算之外,还会把之前窗口的输出撤回(我之前告诉过你结果是X,但我错了。去掉我上次告诉你们的X,用y代替它)。以下两个case非常适合用这种方式:
- 如果窗口下游是分组逻辑,并且分组的key已经变了,那late event的最新数据下去之后,不能保证跟之前的数据在同一个分组,因此,需要撤回之前的结果。
- 动态窗口中,由于窗口合并,很难知道窗口之前emit的老数据落在了下游哪些窗口中。因此需要撤回之前的结果。
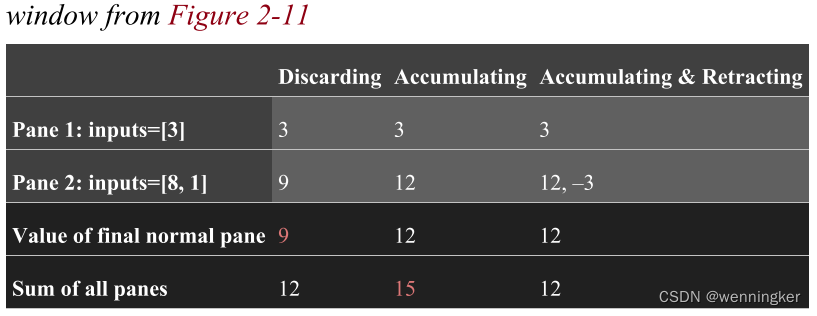
Discarding
每个窗格只包含在该特定窗格期间到达的值。因此,观察到的最终值并不能完全捕获总数。然而,如果将所有独立的窗格本身相加,就会得到12的正确答案。这就是为什么当下游消费者本身对物化窗格执行某种聚合时,丢弃模式是有用的。
Accumulating
如图2-11所示,每个窗格合并了在该特定窗格中到达的值,加上以前窗格中的所有值。因此,最终观测到的值正确地捕获了12的总和。但是,如果将各个窗格相加,那么实际上是重复计算窗格1中的输入,从而得出不正确的总数15。这就是为什么当您可以简单地用新值覆盖以前的值时,累加模式是最有用的:新值已经包含了到目前为止看到的所有数据。
Accumulating and retracting
每个窗格都包含一个新的累积模式值以及前一个窗格值的回缩。因此,最后观察到的值(excluding retractions)以及所有物化窗格的总和(including retractions)都为您提供了12的正确答案。这就是撤回如此强大的原因。
Discarding 模式的代码示例如下:

使用启发式水印,在流计算引擎中,上述代码对应的时序图如下:
Accumulating&Retraction示例代码:

三种模式时序图放在一起比较如下:
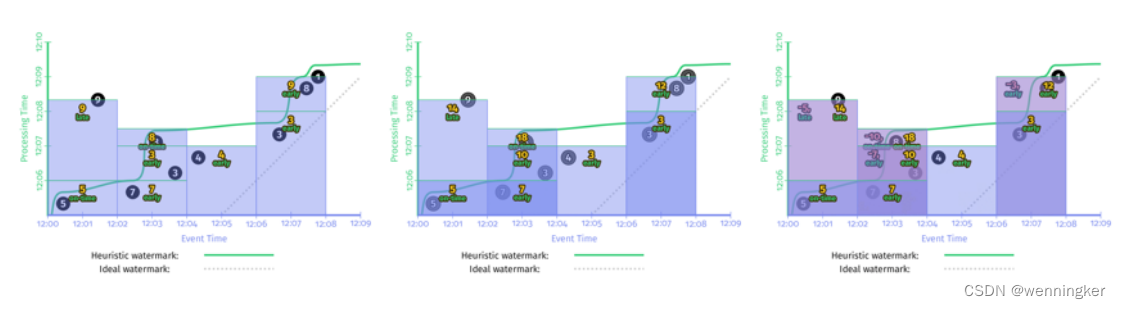
三个图从左到右分别为discarding,accumulation,accumulation&retraction三种模式的时序图。在计算消耗(单作业使用的资源)和存储消耗上,从左到右依次增加。
Summary
Event time versus processing time
事件何时发生和数据处理系统何时观察到它们。
Windowing
管理无界数据的常用方法是沿着时间边界(处理时间或事件时间,尽管我们将Beam模型中的窗口定义缩小为仅在事件时间内)对数据进行切片。
Triggers
何时输出
Watermarks
事件时间进展的强大概念,它提供了一种对操作无界数据的无序处理系统的完整性(以及丢失的数据)进行推理的方法。
Accumulation
单个窗口的细化结果之间的关系,在这种情况下,随着它的发展,它会被多次具体化。
- What results are calculated? = transformations.
- Where in event time are results calculated? = windowing.
- When in processing time are results materialized? = triggers plus watermarks.
- How do refinements of results relate? = accumulation.
为了说明这种流处理模型所提供的灵活性(因为归根结底,这就是真正的问题所在:平衡正确性、延迟和资源之间的关系),回顾一下我们在相同的数据集上能够实现的主要输出变化,而只需要进行最小的代码更改: