【Netty】第一章 NIO 三大组件、ByteBuffer 和文件编程
文章目录
- 【Netty】第一章 NIO 三大组件、ByteBuffer 和文件编程
- 一、Channel & Buffer
- 二、Selector
- 三、ByteBuffer
- 1.ByteBuffer 使用方式
- 2.ByteBuffer 结构
- 3.ByteBuffer 常用方法
- 4.Scattering Reads
- 4.Gathering Write
- 5.黏包半包
- 四、文件编程
- 1.FileChannel
- 2.两个 Channel 传输数据
- 3.Path
- 4.Files
一、Channel & Buffer
channel 类似于 stream,它是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 stream 要么是输入,要么是输出,channel 比 stream 更为底层
常见的 Channel 有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
常见的 buffer 有:
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
二、Selector
多线程
此前,服务器每接收到一个客户端的请求就需要开启一个线程建立 socket 连接,这样会有很多弊端:
- 内存占用高(Windows 下默认一个线程占用 1MB)
- 线程上下文切换成本高
- 只适合连接数少的场景
线程池
固定线程池,线程数量是固定的,当请求太多时,那么这些请求会被阻塞,直到有 socket 断开线程空闲下来
- 阻塞模式下,线程仅能处理一个 socket 连接
- 仅适合短连接场景
selector
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景。
调用 selector 的 select() 方法会阻塞知道 channel 发生了读写就绪事件,这些事件发生,select() 方法就会返回这些事件交给 thread 来处理
三、ByteBuffer
1.ByteBuffer 使用方式
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
2.ByteBuffer 结构
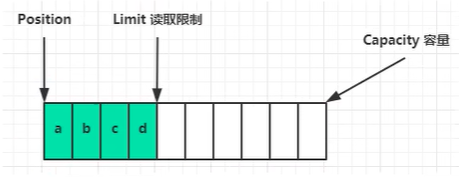
ByteBuffer 有以下重要属性:
- capacity
- position
- limit
初始状态下
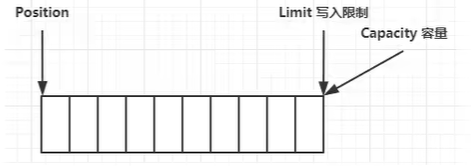
写模式下
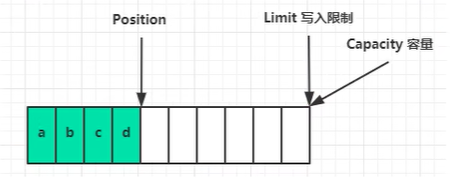
调用 flip() 后,position 切换为读取位置,limit 切换为为读取限制
3.ByteBuffer 常用方法
分配空间
可以使用 allocate() 方法为 ByteBuffer 分配空间,其他 buffer 类也有该方法
ByteBuffer buf = ByteBuffer.allocate(16);
向 buffer 写入数据
有两种方法
- 调用 channel 的 read 方法
- 调用 buffer 自己的 put 方法
int readBytes = channel.read(buf);
和
buf.put((byte)127);
从 buffer 读取数据
同样有两种方法
- 调用 channel 的 write 方法
- 调用 buffer 自己的 get 方法
int writeBytes = channel.write(buf);
和
byte b = buf.get();
get 方法会让 position 读指针向后移动,如果想重复读取数据
- 可以调用 rewind() 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动指针
4.Scattering Reads
分散读取,有一个文本文件 3parts.txt
onetwothree
使用如下方式读取,可以将数据填充至多个 buffer
try(RandomAccessFile file = new RandomAccessFile("helloworld/3parts.txt", "rw")){
FileChannel channel = file.getChannel();
ByteBuffer a = ByteBuffer.allocate(3);
ByteBuffer b = ByteBuffer.allocate(3);
ByteBuffer c = ByteBuffer.allocate(5);
channel.read(new ByteBuffer[]{a, b, c});
}catch(IOException e){
e.printStackTrace();
}
4.Gathering Write
集中写入
ByteBuffer b1 = StandardCharasets.UTF_8.encode("hello");
ByteBuffer b2 = StandardCharasets.UTF_8.encode("world");
ByteBuffer b3 = StandardCharasets.UTF_8.encode("你好");
try(FileChannel channel = new RandomAccessFile("words2.txt", "rw")){
channel.write(new ByteBuffer[]{b1, b2, b3})
}catch(IOException e){
}
5.黏包半包
网络上有多条数据发送给服务器,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时被重新组合,例如原始数据有3条:
Hello,world\n
I'm zhangsan\n
How are you?\n
变成了下面的两个 byteBuffer
Hello,world\nI'm zhangsan\nHo
w are you?\n
编写程序,将错乱的数据恢复成原始的按 \n 分隔的数据
ByteBuffer source = ByteBuffer,allocate(32);
source.put("Hello,world\nI'm zhangsan\nHo".getBytes());
split(source);
source.put("w are you?\n".getBytes());
split(source);
private static void split(ByteBuffer source){
source.flip();
for(int i = 0; i < source.limit(); i++){
//找到一条完整消息
if(source.get(i) == '\n'){
int length = i + 1 - source.position();
//把这条完整消息存入新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(256);
//从 source 读,向 target 写
for(int j = 0; j < length; j++){
target.put(source.get());
}
debugAll(target);
}
}
source.compact();
}
四、文件编程
1.FileChannel
FileChannel 只能工作在阻塞模式下
获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
- 通过 FileInputStream 获取的 channel 只能读
- 通过 FileOutputStream 获取的 channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
读取
会从 channel 读取数据填充 ByteBuffer,返回值表示读到了多少字节,-1 表示到达了文件的末尾
int readBytes = channel.read(buffer);
写入
写入的正确方式如下,SocketChannel
ByteBuffer buffer = ...;
buffer.put(...); //存入数据
buffer.flip(); //切换读模式
while(buffer.hasRemaining()){
channel.write(buffer);
}
在 while 中调用 channel.write 是因为 write 方法并不能保证一次性将 buffer 中的内容全部写入 channel
关闭
channel 必须关闭,不过调用了 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 close() 方法会间接地调用 channel 的 close 方法
位置
获取当前位置
long pos = channel.position();
设置当前位置
long newPos = ...;
channel.position(newPos);
设置当前位置时,如果设置为文件的末尾
- 这时读取会返回 -1
- 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
大小
使用 size 方法获取文件的大小
强制写入
操作系统处于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用 force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
2.两个 Channel 传输数据
String FROM = "helloworld/data.txt";
String TO = "helloworld/to.txt";
long start = System.nanoTime();
try(FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();){
//效率高,底层会利用操作系统的零拷贝进行优化
from.transferTo(0, from.size(), to);
}catch(IOException){
e.printStackTrace();
}
long end = System.nanaTime();
System.out.println("transferTo 用时:" + (end - start) / 1000_000.0);
输出
transferTo 用时:8.2001
3.Path
jdk7 引入了 Path 和 Paths 类
- Path 用来表示文件路径
- Paths 是工具类,用来获取 Path 实例
Path source = Paths.get("1.txt"); //相对路径 使用 user.dir 环境变量来定位 1.txt
Path source = Paths.get("d:\\1.txt"); //绝对路径 代表了 d:\1.txt
Path source = Paths.get("d:/1.txt"); //绝对路径 代表了 d:\1.txt
Path projects = Paths.get("d\\data", "projects"); //代表了 d:\data\projects
4.Files
检查文件是否存在
Path path = Paths.get("helloworld/data.txt");
System.out.println(Files.exists(path));
创建一级目录
Path path = Paths.get("helloworld/d1");
Files.createDirectory(path);
- 如果目录已存在,会抛异常 FileAlreadyExistsException
- 不能一次创建多级目录,否则会抛异常 NoSuchFileException
创建多级目录
Path path = Path.get("helloworld/d1/d2");
Files.createDirectories(path);
拷贝文件
Path source = Paths.get("helloworld/data.txt");
Path target = Paths.get("helloworld/target.txt");
Files.copy(source, target);
- 如果文件已存在,会抛异常 FileAlreadyExistsException
如果希望用 source 覆盖掉 target,需要用 StandardCopyOption 来空值
Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING);
移动文件
Path source = Paths.get("helloworld/data.txt");
Path target = Paths.get("helloworld/data.txt");
Files.move(source, target, StandardCopyOption.ATOMIC_MOVE);
- StandardCopyOption.ATOMIC_MOVE保证文件移动的完整性
删除文件
Path target = Paths.get("helloworld/target.txt");
Files.delete(target);
- 如果文件不存在,会抛异常 NoSuchFileException
删除目录
Path target = Paths.get("hellowworld/d1");
Files.delete(target);
- 如果目录还有内容,会抛异常 DirectoryNoEmptyException
遍历目录文件
public static void main(String[] args) throws IOException{
//计数器,需要使用原子类,匿名类如果要使用外部变量,则该变量的地址值不能发生改变
AtomicInteger dirCount = new AtomicInteger();
AtomicInteger fileCount = new AtomicInteger();
Files.walkFileTree(Paths.get("C:\\Program Files\\Java\\jdk1.8.0_91"), new SimpleFileVistor<Path>(){
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException{
System.out.println("====="+dir);
dirCount.incrementAndGet();
return super.preVisitDirectory(dir, attrs);
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException{
System.out.println("====="+file);
fileCount.incrementAndGet();
return super.visitFile(file, attrs);
}
});
System.out.println("dir count:" + dirCount);
System.out.println("file count:" + fileCount);
}
查看文件夹下有多少个指定类型的文件
public static void main(String[] args) throws IOException{
//计数器,需要使用原子类,匿名类如果要使用外部变量,则该变量的地址值不能发生改变
AtomicInteger jarCount = new AtomicInteger();
Files.walkFileTree(Paths.get("C:\\Program Files\\Java\\jdk1.8.0_91"), new SimpleFileVistor<Path>(){
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException{
if(file.toString().endWith(".jar")){
System.out.println(file);
}
return super.visitFile(file, attrs);
}
});
System.out.println("jar count:" + jarCount);
}
删除多级目录
(友情提示:不要直接执行!删掉后不会进回收站!)
public static void main(String[] args) throws IOException{
Files.walkFileTree(Paths.get("C:\\Program Files\\Java\\jdk1.8.0_91"), new SimpleFileVistor<Path>(){
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException{
Files.delete(file)
return super.visitFile(file, attrs);
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException{
Files.delete(dir);
return super.postVisitDirectory(file, exc);
}
});
}
拷贝多级目录
public static void main(String[] args) throws IOException{
String source = "D:\\sourceDir";
String target = "D:\\targetDir";
Files.walk(Paths.get(source)).forEach(path->{
try{
String targetName = path.toString().replace(source, target);
//是目录
if(Files.isDirectory(path)){
Files.createDirectory(Paths.get(targetname));
}
//是普通文件
else if(Files.isRegularFile(path)){
Files.copy(path, Paths.get(targetName));
}
}catch(IOException e){
e.printStackTrace();
}
});
}