文章目录
- 前言
- 用法
- PostgreSQL
- RocksDB
- 实现
- PostgreSQL 2PC
- RocksDB 2PC
- WRITE_COMMITTED
- WRITE_PREPARED
- 解决 snapshot-read 问题
- 解决 rollback 问题
- WRITE_UNPREPARED
- 总结
前言
本节中提到的代码实现是基于
PG:REL_15_STABLE和Rocksdb: master-fcd816d534代码介绍的
2PC (2 Phase Commit) 作为目前业界主流分布式系统实现分布式事务的主要方案,本文希望通过介绍两个经典的开源实现来展示其底层的实现细节,有很多工程上的细节需要考虑。
2PC 被提出的背景主要是用来解决 事务(A-Atomic)语义在分布式跨节点的系统中无法严格保证的问题。
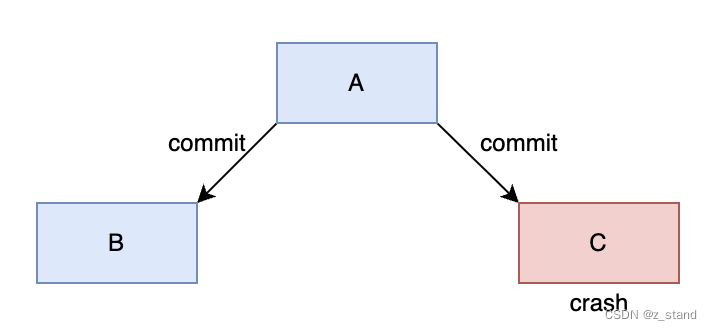
原子性的要求是对于一批操作,要么都成功,要么都不成功。 上图 A 发送两个提交请求到 B 和 C,其中B提交成功了,但是C提交时crash导致没有成功,那这一批操作就不是原子的了。
所以,期望这种场景下的事物实现能够有更多的中间状态来容忍这一些异常,从而能够保证 Atomic的语义。
2PC 在这个大背景下应运而生,大体就是下图的操作流程。
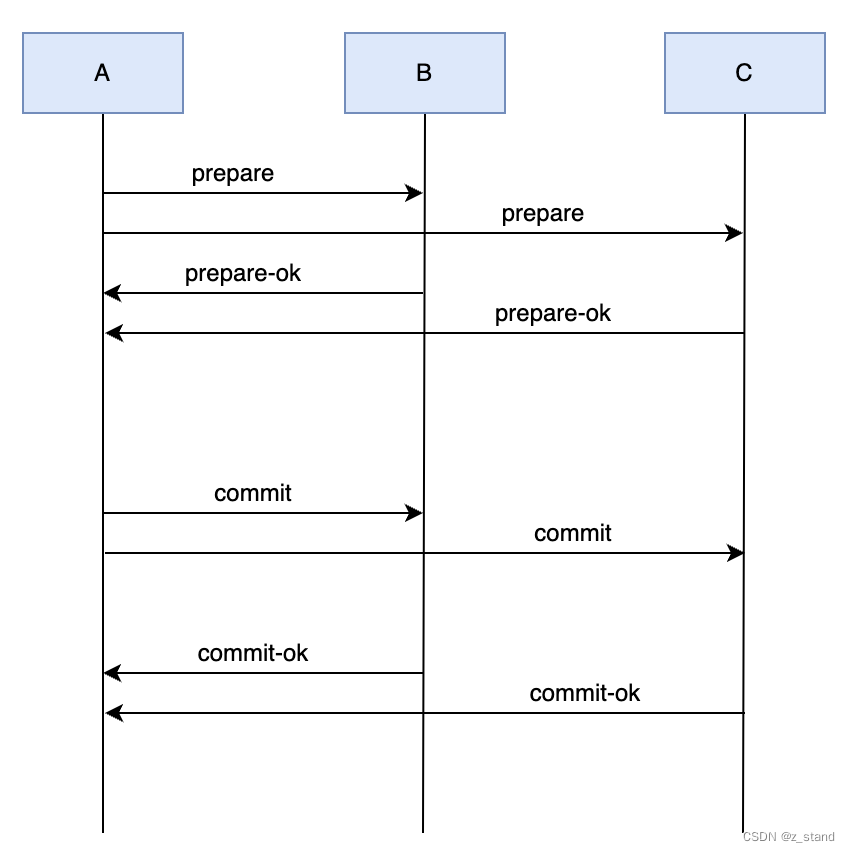
两个阶段分别是 prepare和commit,看图就很简单:
- prepare 阶段 A将 prepare request 发送给各个参与者, 等待他们反馈是否ok
- 全部ok之后,A进入commit阶段,发送commit request给参与者,持久化成功则返回成功,A再将成功的消息反馈给client。
重点需要知道这样的策略是如何解决 ATOMIC 的问题的:
1. B/C故障:A发现 B/C 在发送 完 prepare/commit/abort request之后故障(多长时间没有返回,超时)。这个时候 B/C 内部记录的 事物状态可能有四种:prepare-ok, commit-ok, abort, no-request。B/C 恢复之后 :
- 对于prepare-ok,因为是第一阶段状态,需要询问 A 应该怎么做,由A 决定他们后续的操作行为。
- 对于commit-ok,则直接redo 提交该事务。因为请求在故障发生之前已经提交了。
- 对于 abort,则需要undo,撤销当前事物操作。
- 对于 no-request,则是没有收到任何事物相关的请求(prepare压根没收到),啥也不做。
2. A故障::如果A发生故障,则 B/C 需要自行决定是否提交或者撤销事务,在某一些情况下 B/C其实也不知道是否应该提交或者撤销,这个时候系统只能是不可用,等待A恢复了,这个时候的 B/C 的处理可能有以下几种情况:
- 如果B/C 中包含 commit 请求,则他们都必须提交事务。
- 如果B/C 包含abort, 则改事务必须撤销,undo。
- B/C 包含 prepare-ok ,但是没有其他请求,则什么也做不了,必须等待A 恢复。(为了避免该问题,又提出3PC,增加了一个 canCommit 阶段,在这个阶段 假如A故障,则B/C 会因为等待超时主动撤销改事务,当然这个阶段是没有持久化信息的,无状态)。所以使用2PC 方案的业界实现,对于A这样的协调者角色的实现都是需要考虑高可用,这样才能安全得使用2PC 方案。
本篇我们主要是关注2PC 的实现,在实际调度实现的过程中需要注意的是:
- 2PC 在系统中需要有一个集中的协调者,它用来向其他的参与者发送请求,当然实际实现中它也会有很多其他功能,比如分配事务ID,冲突检测,分布式锁管理等等。
- Prepare 阶段是有状态的,也就是需要 B/C 这样的参与者持久化 prepare的状态。
实现上就是一些具体的细节了。
用法
在考虑实现时,我们先提前看看 2PC 在 PG 和 Rocksdb 中是怎么使用的。
PostgreSQL
PG 默认是不启用 2PC方案,需要修改配置
max_connections大于0 才能使用。
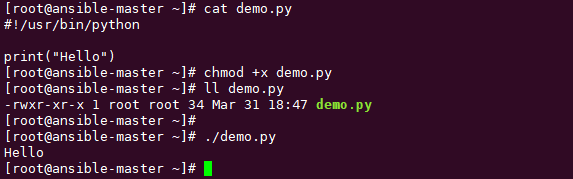
psql 开启两个backend, session1 开启一个事务:
-- session1
postgres=# create table test(c1 int);
postgres=# begin;
BEGIN
postgres=*# insert into test values (1),(2),(3);
INSERT 0 3
postgres=*# select * from test;
c1
----
1
2
3
(3 rows)
postgres=*# PREPARE TRANSACTION 'T1';
PREPARE TRANSACTION
postgres=# select * from test;
c1
----
(0 rows)
此时 session1 中已经开启了一个 2pc事务,且完成了prepare。 命令 PREPARE TRANSACTION 接受一个字符串类型的参数 指定全局事务id,prepare完成之后 postgresql 会将 改prepare日志写盘。
因为这个事务还未完成,不应该对任何事物可见。 所以session1 prepare 成功之后查找的时候会看不到insert 的内容。
我们可以通过系统表 pg_prepared_xacts 看到当前数据库全局的活跃 2pc 事务列表:
-- session 2
postgres=# select * from pg_prepared_xacts;
transaction | gid | prepared | owner | database
-------------+-----+-------------------------------+-------------+----------
772 | T1 | 2023-02-25 12:15:48.712044+08 | zhanghuigui | postgres
(1 row)
同时,可以在 session2 中 通过 commit prepared 语句提交事务,这样就能看到第二步插入的数据。
postgres=# commit prepared 'T1';
COMMIT PREPARED
postgres=# select * from test;
c1
----
1
2
3
(3 rows)
当然,也可以通过 rollback prepared 撤销前面 prepare 成功的事务。
因为 PG 本身是支持复制的单机数据库,其分布式事务功能的支持都是为在其上构建分布式数据库的应用提供的,比如 CITUS 以及 GreenPlum 。
RocksDB
RocksDB 和 PG的性质类似,其作为单机存储引擎,同样提供了2PC 功能的接口,供上层实现分布式事务的系统调度,比如默认就是为 MyRocks提供支持。
对于2PC 的使用就是就是和基本的事务操作接口一样:
TransactionDB* txn_db;
TransactionDBOptions txndb_opts;
TransactionOptions txn_opts;
Options opts;
std::string value;
opts.create_if_missing = true;
opts.compression = kNoCompression;
Status s = TransactionDB::Open(opts, txndb_opts, "./txn_db", &txn_db);
PrintStatus("TransactionDB::Open", s);
// 开启事务
Transaction* txn = txn_db->BeginTransaction(WriteOptions(), txn_opts);
assert(txn != nullptr);
// 创建一个2pc 全局事务的唯一标识,需要保证name 唯一
PrintStatus("txn->SetName", txn->SetName("test-2pc"));
// 该事务写数据,到自己的 WBWI
PrintStatus("txn->Put", txn->Put("key1", "value1"));
// 先Prepare
PrintStatus("txn->Prepare", txn->Prepare());
// 最终的事务提交
PrintStatus("txn->Commit", txn->Commit());
在实际的应用过程中,只要上层拿到了实际的 事务对象txn,就可以跨节点完成对于同一个事务的 prepare/commit 操作。
不过RocksDB只在 悲观事务(PessimisticTransaction) 中实现了 2PC,在 乐观事务(OptimisticTransaction)中不支持。
当然在悲观事务中,rocksdb也支持了三种 write_policy,来提供不同场景下的事务实现优化功能,本节也会一一介绍。
实现
这两个都是非常具有代表性的开源系统,一个演进了接近30年了,另一个演进也是多年了。 一个是如火如荼的 工业级开源数据库,一个是拥有极致性能也极为易用的工业级单机存储引擎,它们支持的 2PC 实现基本代表了 开源方向工业级 2PC 实现的顶峰了,有很多值得学习借鉴的细节。
PostgreSQL 2PC
关于 PG事务,之前也介绍过 其整体的事务体系及实现原理,本节我们重点关注 2PC的实现。
先来看看整体的 Prepare 和 Commit 流程:
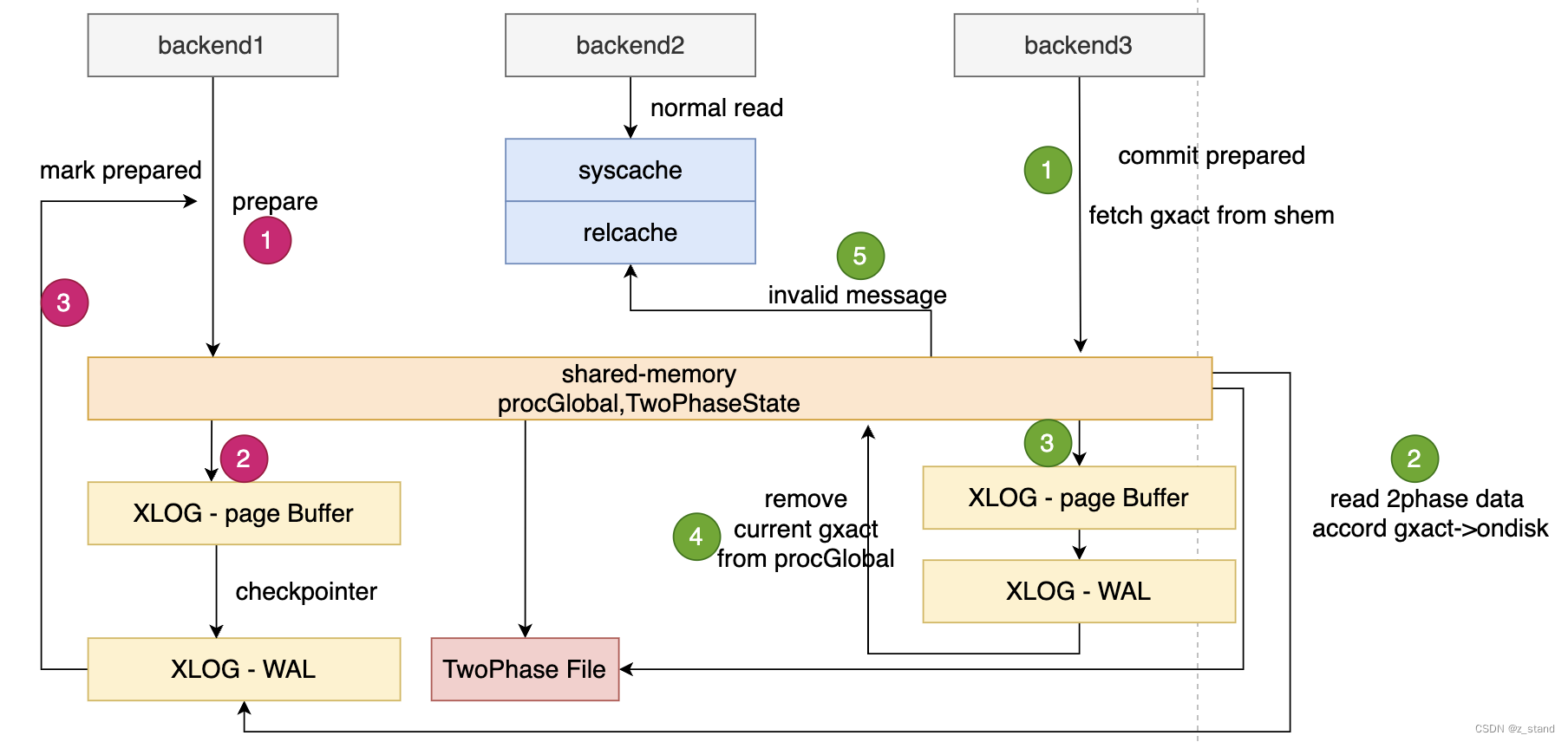
PG 支持的2PC 实现是比较标准的分布式事务的实现方式,核心是通过一个 GlobalTransactionData 数据结构来实现跨backend 的事务交互,大体流程如下:
PREPARE 阶段
在 TBLOCK_PREPARE 状态下 会执行 PrepareTransaction函数,进行prepare 的操作
- 在共享内存创建全局事务状态 gxact 并保存到共享内存中,实现是在
MarkAsPreparing以及StartPrepare中,先创建一个全局事务对象并保存到共享内存链表TwoPhaseState中。 - 在
EndPrepare函数中 将当前事务 record 写入 xlog中,并由 checkpointer 控制是否刷盘(包括手动创建checkpoint,会写pg_twophase目录) - 标记当前 gxact 为prepared,并标记事务状态为
in_progress,添加到ProcGlobal共享内存变量中。此时因为事务所在的 pgproc 被添加到了全局的ProcGlobal中, 则改事务会被认为是 in progress的,也就是这个事务的修改并不会被其他事务看到。
COMMIT 阶段
其他backend 能够通过命令 COMMIT PREPARED 't1' 来对backend1 中执行的 prepare事务进行提交,通过传入的事务名找到 two_phase transaction 的 gid,通过FinishPreparedTransaction 进行事务提交的逻辑处理。
- 通过传入的gid 从共享内存中的
TwoPhaseState找到 gxact - 从xlog(WAL) 或者
pg_twophase目录中读取 TwhoPhaseState 数据到 buf中 - 通过函数
RecordTransactionCommitPrepared写commit 标记到 xlog中,并标记当前事务状态为committed,则其对其他事务本来是是可见的,但是还没有从ProcGlobal移除procno,所以这个事务还是 in-progress的。 - 通过 ProcArrayRemove 从共享内存变量
ProcGlobal移除当前proc,这样就能继续推进latestCompletedXid。 - 发送 invalid message 到其他的cache,标记当前tuple已被更新,需要重新读取填充。
- 提交成功 之后就是清理一些锁信息 以及 从
TwoPhaseState移除 gxact。
整个流程还是比较清晰的,利用共享内存保存全局事务状态, 实际的事务数据则在prepare也会写入到wal中,commit的时候会从 wal中重新读取再进行状态重置进行写入。
需要注意的是 prepare 之后,这个2pc 事务会加一个 AccessExclusiveLocks 最高级别的锁,如果prepare之后其他事务有更新同一行,那其他事务肯定就会被阻塞(正常的事务处理流程),所以分布式事务的实现过程中如果 commit不及时,可能会导致有冲突的事务延时较高。
不过PG 的2pc实现并不会有内存占用过高的问题,因为prepare 之后只会在共享内存中保留一些全局事务信息 以及 标识事务是 in-progress 的proc信息,其他的事务数据已经写入到 WAL中了。虽然在 commit 的时候需要牺牲性能,从WAL 中重新读取,但是并不会有因为commit 执行时间过长导致大量内存被 执行prepare的进程hold住,整个集群并不会有2pc事务过多导致的内存高速上涨问题。至于commit 的延时问题,PG 只保证稳定性,需要上层基于PG实现的分布式事务体系中去考虑事务数据的缓存,从而加速commit的调度。
RocksDB 2PC
关于Rocksdb 事务体系的基本实现原理,很久以前有完整介绍过,感兴趣的同学可以先了解下一下基本的实现链路。
在2020年的乐观事务中还支持了两种 write_policy,分别是WRITE_COMMITTED 和 WRITE_PREPARED,但是因为以上两种都有问题,所以在2021年的时候又实现了 WRITE_UNPREPARED 策略 来解决以上两种实现在部分实际应用场景的问题。
这rocksdb 为 MyRocks 2PC 的实现支持,考虑到生产环境的需求,rocksdb 实现了几种不同的方案。个人理解,这一部分是 rocksdb 事务体系最难的,因为是直接服务于数据库的,对 性能 以及 内存的控制都需要极为小心谨慎。
对于WRITE_POLICY的初始化,是在 初始化事务DB的时候进行的:
TransactionDB::Open
TransactionDB::WrapDB
WrapAnotherDBInternal
在 WrapAnotherDBInternal 里面会根据 txn_db_options.write_policy 配置来决定使用哪一种 TxnDB,其中默认创建的是 WriteCommittedTxnDB。
当然实际使用的时候还需要注意接口 SetName,它用来唯一标识一个2pc事务,这样用户就可以拿着name 去不同的机器上做 COMMIT 操作。
WRITE_COMMITTED
直接看一个 WRITE_COMMITED 操作的简略时序图
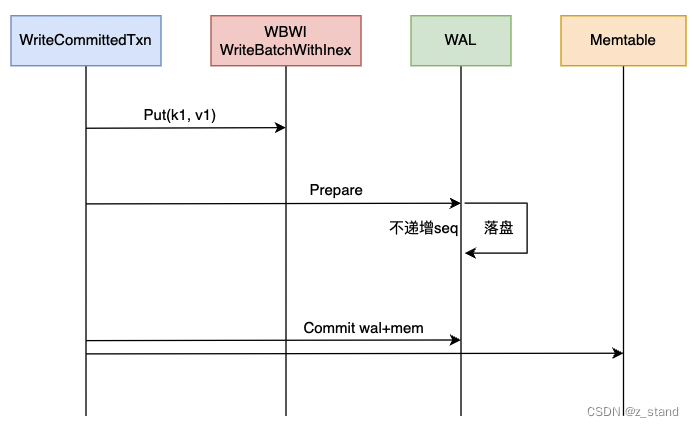
大体分为三步(也是RocksDB 的2PC 实现的基本三步,不同的write-policy三步的实现细节不同):
- 创建好的 WriteCommitTxn 事务调用更新操作 Put,这一步基本就是写内存数据结构 writebacth。不过rocksdb为了加速长事务的读性能,构造了一个 WriteBatchWithIndex数据结构,即放入 普通的writebatch 之后会将key + value offset in writebatch 的数据 再插入 一个跳表中,方便快速查询key。
细节可以参考之前介绍的 rocksdb 事务体系的文章。 - Prepare 阶段,WriteCommited policy 支持的语义是仅仅在提交的时候才会写 memtable,所以prepare阶段只会写WAL,这里需要注意的是 写wal 并不会递增seq,所以wal中的 seq 序列并不一定满足严格的 seq[n] < seq[n+1](正常情况写WAL 会以write-batch为单位递增,在memtable中是单调递增的)。
而且这个时候的writebach数据会补充两条record ,唯一标识一个在wal中的prepare数据:
这里的实现是在如下逻辑中:write-batch header(12B) + kTypeBeginPrepareXid(no-op) + NormalData + kTypeEndPrepareXID + txn_nameWriteCommittedTxn::PrepareInternal DBImpl::WriteImpl 开启 two_write_queues_ ? DBImpl::WriteImplWALOnly : WriteToWAL - Commit 阶段,这个阶段会写 WAL 以及 memtable。
在WriteCommittedTxn::CommitInternal DBImpl::WriteImplWriteCommittedTxn::CommitInternal中会先在前面prepare之后的 wb 中追加一个 recordkTypeCommitXID + txn_name。在后续 DBImpl::WriteImpl 中 wb数据循环插入memtable的时候,memtable会自动过滤掉 这种类型的op,只插入 writebatch中实体的数据。
综合来看 WRITE_COMMITTED 的整体流程:
- 创建 WRITE_COMMITED 事务
- SetName 注册到 DB级别的全局事务管理map中,将唯一标识当前2pc的事务名和事务对象标识起来。
- Put 更新数据到事务对象中,因为是悲观事务,所以会在加锁的时候做冲突检测以及死锁检测
- Prepare 增加 begin/end prepare标识到wirtebatch中,并只写WAL,但是不递增全局seq
- Commit,增加commit 标识到 writebatch,写WAL + memtable。
整体流程就比较清晰了,可靠性也是严格按照2PC 的协议来实现,有prepare标识,方便recovery回滚。接下来直接看看问题:
-
可以看到只有在 Commit阶段 事务才会写Memtable,也就是Prepare的时候事务的更新数据都会被存到 WBWI 的内存中。假如整个系统有大量的长事务,内存会有非常大的压力。
PS: rocksdb 默认不会对事务的执行时间做限制,当然提供了事务超时配置来避免长事务的存在。
-
另一个问题是 Commit阶段 memtable的写压力会非常大,尤其是在 2pc 这样的分布式事务的场景,肯定都是写同一个db (当然上层可以让key 按照hash做数据分片),但是本身会有集中并发写memtable的压力, 这个时候很容易导致 write-stall,无法提升整体服务的 TPS。
所以rocksdb 先提供了 WRITE_PREPARED 和 WRITE_UNPREPARED 策略解决这个问题。
-
WRITE_PREPARED是解决内存的问题的一个开端,因为考虑到rollback,其还需要在内存中保存write-batch 的数据;它要解决的核心是 集中commit 造成的write-stall ,影响sql操作的延时问题,需要在 prepare 阶段就进行提交。 -
WRITE_UNPREPARED则允许在 Put的时候就写入一批write_batch的数据到memtable,写完就可以释放,这样在prepare的时候就只需要写入剩余的write_batch数据,能极大得降低内存在整个长事务期间的消耗,不过这个实现需要对rollback有较大的改动;除了这个优化之外WRITE_UNPREPARED还优化了事务的并发控制中锁相关的内存(range-lock)。 所以它才是解决内存 问题的核心,当然因为也是prepare 阶段就写memtable,所以也缓解了 写延时问题。
PS: 这里这里有人会思考,改成这样如果集中 prepare,那metable 的压力也会很大,也有可能造成writestall的问题?我们要考虑在分布式事务的实现中,用户关注的是整个事务的执行延时,可以看到最前面介绍2PC 的基本流程时 prepare 完成之后首先参与者需要将请求发送到协调者,协调者经过本地冲突检测发现可以提交 还会再发送 commit请求到参与者。 这两次网络发送跨服务器场景肯定是 ms级别的,即使有集中prepare,但这一些时间我们完全可以用来让 rocksdb 在write-stall场景坚挺,commit 请求过来时一波 write-stall 高峰很大程度已经过去了,这样整体的分布式事务延时相比于 commit 写 memtable 完成的延时肯定有所缓解。
WRITE_PREPARED
介绍 该策略之前先思考几个问题:
需要注意的是这个策略标识的是一个事务会在 Prepare 阶段就会写入Memtable中,而memtable是属于 读链路的关键路径,所以需要非常小心得处理可见性问题,否则就无法满足 Rocksdb支持的 RC 以及 RR级别了。
- 如何判断一个写事务 写入的key-value 是否在一个读事务的读取快照中?
- 如何回滚事务?
大体流程如下:
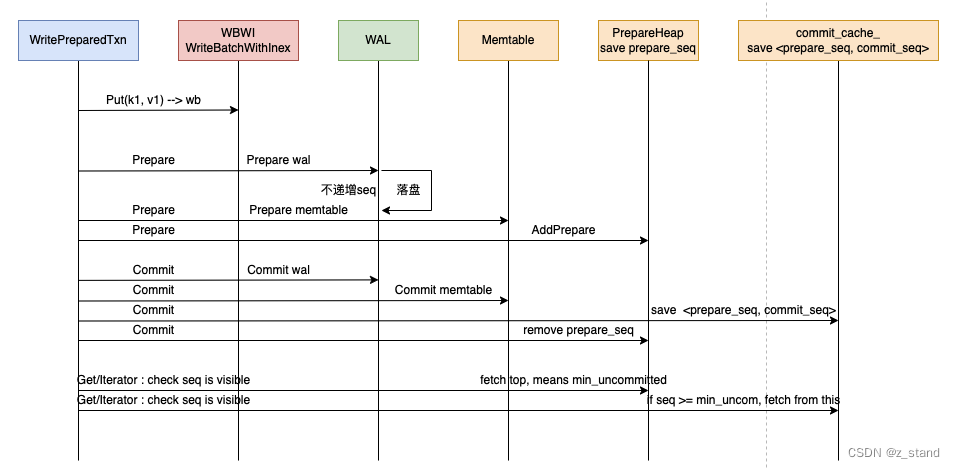
相比于 WRITE_COMMITTED ,最为核心的差异前面也提到了:为了缓解内存的压力,这个策略允许在 Prepare阶段就写 memtable。 write_batch 中的数据在prepare 成功之后就可以释放了,commit的时候只需要提交一个 当前事务name 的 commit-mark 的 wb 就好了,也不会有像 WRITE_COMMITTED 并发commit时导致的 写延时 问题。
但是如果这样实现就需要回答上面的两个问题:
解决 snapshot-read 问题
因为memtable 是读的关键链路,如何保证 Rocksdb的 RR 隔离级别,即 rocksdb 在读的时候本身需要拿一个最新的或者使用用户自己提供的 snapshot(最新的seq),只会返回这个seq之前的 key;我们需要保证在 prepare完成时未提交的数据对用户不可见 这样的语义。
所以 在 WRITE_PREPARED 策略下,rocksdb 设计了额外的两个数据结构 : PrepareHeap prepared_txns_ 以及 std::unique_ptr<std::atomic<CommitEntry64b>[]> commit_cache_; 。
- prepared_txns_ 用来保存 writebatch prepare 成功的 一批 seq, prepare 写memtable完成后通过回调函数更新, commit完成后清理
- commit_cache_ 是一个数组,用来暂时缓存 commit成功的一批 <prepare_seq, commit_seq>的映射,commit完成写memtable后通过回调函数更新 。
这两种数据结构的更新需要保证严格的时序关系,否则就存在事务的一致性问题了(可能就会读到未提交的数据),这两个数据结构的更新都有有严格的访问屏障。
其他事务走读链路的时候 判断一个 key 是否对一个 snapshot 可见就可以利用以上两个数据结构实现,先提前定义以下三个 seq:
- key_seq : 当前要判断的这个key 的seq
- snapshot_seq : 当前读的时候拿到的或者用户传入的 snapshot 的seq
- min_uncommitted_seq:执行读的时候会先拿
prepared_txns_.top(),其为当前db 最小的uncommitted的事务,填充给 min_uncommitted_seq。
有了这三个基本的 seq,后续的可见性判断就比较清晰了(必须要按照顺序判断,必须要不满足前面的条件,后续的条件生效才有效,&& 的关系):
- key_seq == 0, 可见。Compaction 会把对所有snapshot可见的key的seq设置为0 (bottom-level)
- key_seq > snapshot_seq , 不可见,已经超过snapshot_seq了,不满足snapshot读了
- key_seq < min_uncommitted_seq,可见。当前key在snapshot_seq内 且 比最小的未提交的seq还要小,肯定可见。
- 此时 min_uncommitted_seq <= key_seq < snapshot_seq,接下来的判断需要用到 commit_cache_ 中的数据。需要拿 key_seq 去commit_cache_ 中匹配是否有对应的record,有则说明当前 key_seq 是两阶段中已经 committed的了,这样就可以见了;否则就不可见。
需要注意的是这里介绍的是其他事务 snapshot read 时判定可见性规则的逻辑。如果是同一个txn 的read,则是需要read_your_writes语义,也就是在第4)步的时候一定是需要返回可见,不论有没有提交。
解决 rollback 问题
rollback 因为相对简单,并没有在上面的流程图中展示。对于 2PC 的过程中如果需要 rollback,则是需要用户发送rollback指令的情况(最前面介绍 2PC 流程时提到的 A/B/C 故障进行 undo的场景)。这个时候关键时解决prepare 成功时的rollback,因为数据已经写入到了memtable(有可能已经触发flush了)。
rocksdb 因为 时append-only形态,所以 rollback也是需要构造delete形态,rollback 阶段会构造一个 rollback_batch,将当前事务的key全部填充到这个rollback_batch中,并设置当前batch的 seq为 kMaxSequenceNumber,走写入逻辑(这样这一批key的所有seq 都比snapshot大,肯定对它们不可见,compaction的时候也会清理 seq为 kMaxSequenceNumber的key ); 实际走写memtable的时候rollback也会有一些优化,比如先读一下当前要处理的key,如果已经存在,则直接写;如果不存在则会下发一个delete ,确保一定删除了(不知道为什么要多这一步? ),这里多了一个读操作,主要是为了防止将value也写入,rollback 比较多造成较多的空间放大。
实际的代码实现细节非常多,需要保证安全。也是看了一个多小时才把完整链路梳理出来,更细节的实现都是在 write_prepared_txn.cc中。
接下来再看看 WRITE_UNPREPARED 策略 也是为了解决2PC 实现过程中 内存占用过大问题,因为其还继承 WRITE_PREPARED 策略下 prepare 阶段写 memtable的逻辑,所以 事务延时也能有所缓解。
WRITE_UNPREPARED
WriteUnpreparedTxn 和 WritePreparedTxn 基本 prepare/commit 流程没有太大的差异,很多数据结构都可以公用,所以 WriteUnpreparedTxn 也是继承自 WritePreparedTxn。
直接看整个流程图:
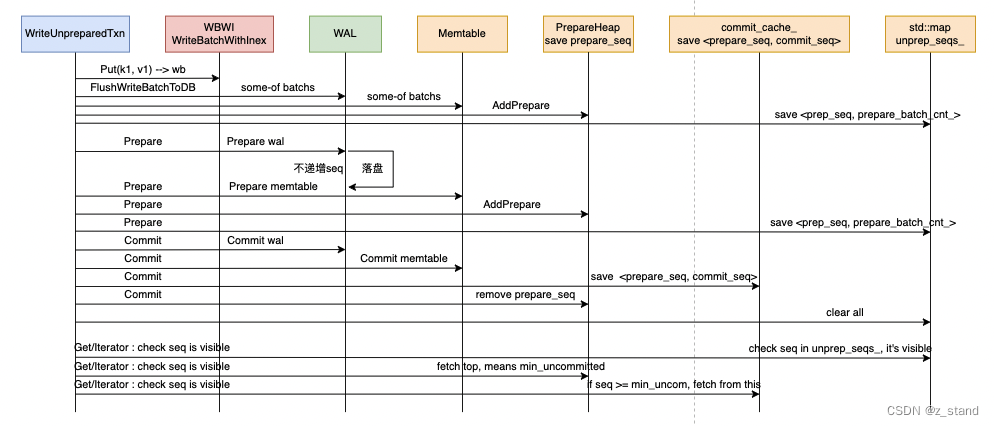
差异部分主要是 增加了一个 std::map unprep_seqs_ 数据结构,它用来track 处于prepare 阶段的write_batch,有了它就能够在 Put 的时候进行 write_batch 数据集的拆分了。
目前的实现是 Put 的时候检测如果 write_batch 写入的k/v累积达到了 write_batch_flush_threshold_,则会先将当前batch 的数据进行持久化,因为还没有到 prepare阶段,所以也需要有一个追踪能力来保证后续 rollback 和读的正确性,这里会在写入的过程中将当前batch的最小 seq 以及 batch_cnt保存到 unprep_seqs_ 中,这样在 Put 完成时就能将 write_batch的数据清空,剩余的部分到 prepare 阶段再做同样的持久化就好了。
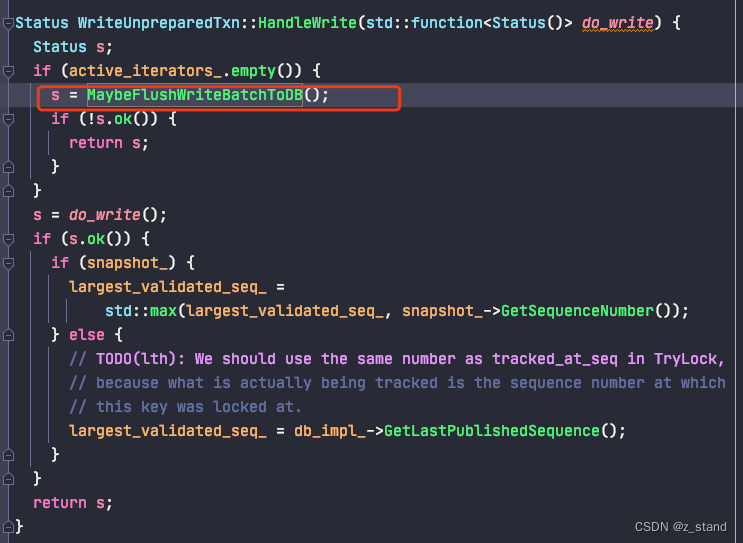
内存中只要有了 unprep_seqs_ 作为读时的第一步可见性判断就好了:如果当前事务的一个读请求判的 seq 在 unprep_seqs_ 之间,也是满足read-your-writes语义的,则肯定是可见的。
rollback的实现是有点重,主要是内存不再保存所有的write-bach数据,需要有一个集中拿的地方:
- 首先要拿到当前事务的所有曾经写入的key 。这里会直接从 TransactionLockMgr 中保存的
TrackedKeys tracked_keys_;拿,它会保存当前事务生命周期内所有写入key,用来做冲突检测。这里会直接从 TransactionLockMgr 里面进行读取。 - 从base-db中挨个读它们的旧value。因为是 base-db,所以读的可见性不再是 read-your-writes,是直接走basedb的读取。
- 重新将旧的value写入。
不过这里的工作还都没有完成,这里在rollback的时候对内存的消耗还是比较大的,后续还需要在这方面做一些优化。
客观来说,这里的功能估计也就只有 myrocks 来用了,对于普通的rocksdb用户,除了想要做支持分布式事务的kv 存储,其他的应该都不会有这一块功能的需求,实在是过于复杂 😦
总结
总的来说2PC 在 postgresql 以及 rocksdb 的实现中都是比较标准的实现方式,即2PC 中 prepare 阶段也需要写 WAL,这样才能保证prepare 之后不论是协调者还是参与者异常,都能进行安全的数据恢复。
至于在 rocksdb里面 是否写memtable,则是rocksdb 在这个场景下做的一些工业级指标的优化(内存消耗、commit 延时等考虑),相对来说PG 因为是一个单机数据库,仅用作TP场景,所以只需要专注于稳定性以及 主从同步的功能(前面没有介绍,prepare/commit 写wal之后 如果开启replication ,则会同步 wal到从数据库),用相对简单的实现方式以及严格的锁保护增强稳定性就好了。而 Rocksdb 作为极为通用的单机k/v存储引擎,其需要考虑的指标是方方面面,所以需要提供足够多的实现选项来供用户选择(不过2pc 这里的主要用户还是myrocks 😃 )。