ChatAug: Leveraging ChatGPT for Text Data Augmentation 论文精读
- Information
- Abstract
- 1 Introduction
- 2 RELATED WORK
- 2.1 Data Augmentation
- 2.2 Few-shot Learning
- 2.3 Very Large Language Models
- 2.4 ChatGPT: Present and Future
- 3 DATASET
- 3.1 Symptoms Dataset
- 3.2 PubMed20k Dataset
- 4 METHOD
- 4.1 Overall Framework
- 4.2 Data Augmentation with ChatGPT
- 4.3 Few-shot Text Classification
- 4.4 Baseline Methods
- 4.5 Evaluation Metrics
- 4.5.1 Embedding Similarity
- 4.5.2 TransRate
- 5 EXPERIMENT RESULTS
- 5.1 Classification Performance Comparison
- 5.2 Evaluation of Augmented Datasets
- 6 CONCLUSION AND DISCUSSION
- 自结[^1]
Information
标题: ChatAug:利用ChatGPT增强文本数据
时间: 暂无
会议: 预印本2023/2/27
作者: Haixing Dai∗, Zhengliang Liu∗, Wenxiong Liao∗, Xiaoke Huang, Zihao Wu, Lin Zhao, Wei Liu, Ninghao Liu, Sheng Li, Dajiang Zhu, Hongmin Cai, Quanzheng Li, Dinggang Shen, Tianming Liu, and Xiang Li
单位: 美国乔治亚大学计算学院、华南理工大学计算机科学与工程学院、美国凤凰城梅奥诊所放射肿瘤科、美国弗吉尼亚大学数据科学学院、美国德克萨斯大学阿灵顿分校计算机科学与工程系、美国马萨诸塞州波士顿市的麻省总医院和哈佛医学院放射科、上海科技大学生物医学工程学院、上海联合影像智能有限公司(上海200230)和上海临床研究与试验中心 好多人 oh my good!
链接: https://arxiv.org/pdf/2302.13007.pdf
Abstract
摘要 文本数据增强是克服许多自然语言处理任务中样本容量有限的挑战的一种有效策略。这一挑战在少镜头学习场景中尤为突出,在这种场景中,Q:目标领域中的数据通常更稀少,质量也更低。 为了缓解这种挑战,一种自然且广泛使用的策略是对训练数据进行数据增强,以更好地捕捉数据的不变性,并增加样本容量。然而,Q:目前的文本数据增强方法要么不能保证生成数据的正确标注(缺乏忠实性),要么不能保证生成数据的足够多样性(缺乏完整性),或者两者兼有。 受最近大型语言模型的成功,特别是ChatGPT的开发的启发,在本工作中,我们提出了一种基于ChatGPT的文本数据增强方法(名为ChatAug)。ChatGPT基于语言丰富程度无可比拟的数据进行训练,并采用大规模人类反馈的强化训练过程,使模型与人类语言的自然性具有亲和力。Q:我们的文本数据扩展方法ChatAug将训练样本中的每个句子重新表述成多个概念相似但语义不同的样本。增加的样本可以用于下游模型训练。 在少量学习文本分类任务上的实验结果表明,本文提出的ChatAug方法在测试精度和增强样本分布方面优于目前最先进的文本数据增强方法。
1 Introduction
自然语言处理的有效性在很大程度上依赖于训练数据的质量和数量。由于可获得的训练数据有限,这在实践中是一个常见的问题,原因是对隐私的担忧或人类标注的高成本,因此训练一个准确的NLP模型,并将其很好地泛化到未见过的样本,可能是一个挑战。训练数据不足的挑战在少镜头学习(FSL)场景中尤为突出,在该场景中,在原始(源)域数据上训练的模型有望从新(目标)域[1]中的几个示例中泛化。许多FSL方法已经在各种任务中克服了这一挑战,取得了令人满意的结果。现有的FSL方法主要是通过更好的架构设计[3]、[4]、[5]来提高模型的学习和泛化能力,利用预先训练好的语言模型作为基础,然后使用有限的样本[6],通过元学习[4]、[7]或基于提示的方法[8]、[9]、[10]、[11]对其进行微调。然而,这些方法的性能在本质上仍然受到源领域和目标领域数据质量和数量的限制。
除了模型开发外,文本数据增强还可以克服样本容量的限制,与NLP中[12]、[13]等其他FSL方法协同工作。数据扩展通常与模型无关,不涉及对底层模型体系结构的更改,这使得这种方法特别实用,适用于广泛的任务。在自然语言处理中,有几种不同类型的数据增强方法。传统的文本级数据扩展方法依赖于对现有样本库的直接操作。常用的技术包括同义词替换、随机删除和随机插入[14]。最近的方法利用语言模型来生成可靠的样本,以更有效地增强数据,包括反向翻译[15]和隐含空间[16]中的词向量插值。然而,现有的数据增强方法在生成的文本数据的准确性和多样性方面都受到限制,在很多应用场景[14],[17],[18]中仍然需要人工标注。
(非常)大型语言模型(LLMs)的出现,如GPT家族[8],[19],为生成类似于人类标记数据的文本样本带来了新的机会,这大大减轻了人类标记数据[20]的负担。LLM以自我监督的方式进行训练,这种方式会随着开放领域中几乎无限数量的文本语料库而扩大。LLMs的大参数空间也使它们能够存储大量的知识,而大规模的预训练(如训练GPTs时的自回归目标)使LLMs能够编码丰富的事实知识来生成语言。此外,ChatGPT的训练遵循Instruct-GPT[21]的训练,后者利用人类反馈的强化学习(RLHF),从而使其对输入产生更有信息量和更公正的反应。
受到语言模型在文本生成中成功应用的启发,我们提出了一种新的数据增强方法ChatAug,该方法利用ChatGPT生成辅助样本,用于少片段文本分类。我们通过在通用域和医学域数据集上的实验测试了ChatAug的性能。本文提出的ChatAug方法与现有数据增强方法的性能比较表明,该方法在句子分类精度上有两位数的提高。进一步对生成文本样本的信度和完整性进行研究发现,ChatAug可以在保持其准确性(即与数据标签的语义相似度)的同时生成更多样化的增强样本。我们预想,LLM的发展将达到人类水平的注释性能,从而彻底改变NLP的少镜头学习和多任务领域。
2 RELATED WORK
2.1 Data Augmentation
数据增强是一种通过转换人工生成新文本的方法,被广泛用于提高文本分类中的模型训练。在NLP中,现有的数据增强方法可以在不同的粒度级别上工作:字符、单词、句子和文档。
字符级的数据增强是指在文本[22]中随机插入、交换、替换或删除某些字符的方法,提高了NLP模型对文本数据噪声的鲁棒性。 另一种称为光学字符识别(OCR)数据增强的方法,通过模拟使用OCR工具从图片中识别文本时发生的错误,生成新的文本。拼写增强[23]故意拼错一些经常拼错的单词。键盘扩展[22]通过用QWERTY布局键盘上与所选键相近的另一个键替换所选键来模拟随机打字错误。
数据扩充也可以在词的层面上工作。 随机交换增广随机交换文本中的两个单词,随机删除增广随机删除一些单词[24]。同义词扩展使用PPDB[25]等同义词数据库替换随机选择的单词[26]。WordNet[27]也被广泛用作同义词扩展的参考。该方法保持了样本语义的一致性,适用于文本分类任务。Wang et al.[28]提出了一种基于单词嵌入的数据增强方法,该方法用其top-n相似的单词替换所选的单词,生成一个新的句子。考虑不同的预先训练的单词嵌入(例如,GoogleNews词汇嵌入[29])。这种方法基于的原则是,在嵌入空间中相邻的词经常出现在相似的上下文中,这可能有助于保持语法的一致性。
然而,基于词嵌入的方法存在一个严重的缺陷,即嵌入空间中的近词不一定语义相似,但语义的变化会影响分类结果。 例如,“热”和“冷”通常出现在相似的上下文中,所以它们的词嵌入很接近,但它们的语义却完全相反。反拟合嵌入增强算法[30]、[31]通过使用同义词词典和反义词词典对初始词嵌入进行调整,解决了这一问题。具体而言,近义词的嵌入距离会缩短,反义词的嵌入距离会扩大。
上下文增强[32]、[33]是另一种词级数据增强方法,它使用掩蔽语言模型(MLMs)如BERT[34]、DistilBERT[35]和RoBERTA[36]根据上下文生成新的文本。 具体来说,它们在文本的某些位置插入< mask >标记,或者用< mask >标记替换文本中的某些单词,然后让传销预测哪些单词应该放在这些屏蔽位置。由于传销是在大量的文本上预先训练,语境增强通常可以产生有意义的新文本。
一些文本数据增强方法在句子和文档级别工作。 例如,反向翻译增强[37]使用语言翻译模型进行数据增强。具体来说,语言模型首先将文本翻译成另一种语言,然后再将其翻译回原始语言。由于翻译过程的随机性,增译文本与原文本有所不同,但语义保持了一致性。在文档级别,Gangal等人提出了一种方法来意译整个文档,以保持文档级别的一致性。
通常,无论粒度级别或文本生成主干(即,基于规则的方法或语言模型)如何,数据增强的目标都是生成可感知的、多样化的、保持语义一致性的新样本。
2.2 Few-shot Learning
深度学习在各种数据密集型应用中取得了显著的成功。然而,在下游任务中,如果数据集较小,则深度模型的性能可能会受到影响。少镜头学习是一个科学分支,专注于开发解决方案来应对小样本规模的挑战[1],[39]。FSL研究的目的是利用先验知识,快速概括到只包含少数标记样本的新任务。对于少镜头学习,一个经典的应用场景是,由于隐私、安全或道德考虑,获取受监督的示例很困难或不可能。少镜头学习的发展使从业者能够在各种场景下提高文本分类的效率和准确性,并部署实际应用。
近年来,少镜头学习在克服文本分类训练数据有限的挑战方面取得了可喜的进展。例如,在NLP中,一种常见的方法是使用一个预先训练的语言模型(如BERT[6])作为起点,然后用有限的样本对其进行微调。一些最新的方法发展[2],[4],[40]方法已经获得了支持,包括提示调优[8],[9],[10],[11]和metalearning[4],[7]。一般来说,现有的FSL方法要么针对架构设计[3]、[4]、[5],要么针对数据增强[12]、[13],要么针对训练过程[41]。
尽管即时调整和元学习方法最近有所发展,但它们存在一些主要的局限性。例如,即时工程是一种繁琐的艺术,需要大量的经验和手工尝试。另一方面,元学习存在训练不稳定性[43]、[44]、[45]以及对超参数[43]、[44]的敏感性等问题。此外,所有这些FSL管道都需要深厚的机器学习专业知识,熟悉复杂的模型架构和培训策略,这是普通从业者和一般开发人员无法达到的。如2.1节所述,数据增强是一种有效的FSL解决方案,可以与其他FSL模型相结合。因此,本文提出的ChatAug方法能够生成准确和全面的训练样本,可以克服当前FSL方法的问题,并有可能改变NLP中少镜头学习的局面。
2.3 Very Large Language Models
基于转换器体系结构的预训练语言模型(PLMs),如BERT[6]和GPT[46]模型系列,已经彻底改变了自然语言处理。与以前的方法相比,它们在广泛的下游任务上提供了最先进的性能,并有助于语言模型的日益普及和民主化。一般来说,预训练语言模型有三类:自回归语言模型(例如基于解码器的GPT)、掩蔽语言模型(例如基于编码器的BERT)和编码器-解码器模型(例如基于编码器的BERT)。BART[47]和T5[48])。这些模型通常包含100M和1B参数[19]之间。
近年来,NLP社区见证了非常大型的语言模型的兴起,如GPT-3 (175B参数)[8]、PaLM (540B参数)[49]、Bloom (176B参数)[50]、OPT(多达175B参数)[51],以及FLAN系列(FLAN有137B参数)[52]。这些大型语言模型的核心是受BERT和GPT启发的转换器模型,尽管其规模要大得多。
大型语言模型的目标是准确地学习输入文本的潜在特征表示。这些表示通常依赖于上下文和领域。例如,“治疗”一词的向量表示可能在医学领域和一般领域之间有很大的不同。对于较小的预先训练的语言模型,经常需要不断地预先训练和调整这些模型,以达到可接受的性能[53]。然而,非常大的语言模型可以潜在地消除微调的需要,同时保持具有竞争力的性能[8],[54]。
已有的研究表明,预先训练的语言模型可以帮助在数据集上添加语义相似的新样本[14],[18],这对实际应用具有重要的实用价值。在本研究中,我们的目标是使用ChatGPT,一个流行的LLM来进行数据增强。ChatGPT基于GPT-3[8],它是在海量的网络数据上训练而成的,信息丰富多样。此外,ChatGPT通过人类反馈强化学习(RLHF)进行训练。在RLHF过程中,人类的反馈被纳入生成和选择最佳结果的过程。更具体地说,奖励模型是根据人类注释者的排名或生成的结果进行训练的。反过来,这个奖励模型会奖励最符合人类偏好和价值观的模型输出。我们相信,这些创新使ChatGPT成为生成人类水平高质量数据样本的最佳候选人。
2.4 ChatGPT: Present and Future
ChatGPT是自然语言处理领域的颠覆者。事实上,在人类历史上,大型语言模型的力量第一次通过用户友好的聊天机器人界面被大众所接受。反过来,这种常见的可访问性也促进了ChatGPT的空前流行。数以百万计的用户进一步释放了语言模型的潜力,这为新用例带来了无数的可能性。
ChatGPT已经成为许多NLP应用程序[55]的通用问题解决器。Qin et al.[55]对ChatGPT进行了全面的NLP任务评估,包括自然语言推理、算术推理、命名实体识别、情感分析、问答、对话和总结等方面的共同基准。他们得出结论,ChatGPT在大多数任务中都表现出色,除了那些专注于特定细节的任务(例如,序列标记)。
对于多语言任务,ChatGPT也是一种有价值的解决方案。[56]最近的一项实证研究报告显示,ChatGPT擅长处理涉及高资源语言(各种欧洲语言和中文)的任务,可与谷歌翻译、深度翻译和腾讯TranSmart相媲美。尽管如此,ChatGPT在低资源语言上表现很差,并且在处理远程语言翻译时面临额外的挑战(即,英德翻译被认为比英北印度翻译“远”)。 后来的一项研究[57]证实了ChatGPT在低资源语言方面遇到了困难,尽管作者观察到ChatGPT在理解非拉丁脚本方面比生成这些脚本做得更好。
此外,还可以使用纯基于文本的ChatGPT与多模态数据交互。一组研究人员[57]使用HTML Canvas和Python Turtle图形作为生成文本到图像的媒体。ChatGPT可以忠实地生成HTML和Python代码,然后这些代码可以用来生成所需的图像。作者设计了一个绘制国旗的任务,该任务需要ChatGPT生成可以生成国家国旗的代码。我们发现,当提示符前面有一个查询标志描述的提示符时,ChatGPT可以生成更好的标志。换句话说,描述性文本提示可以提高多模式任务的性能。
除了计算机科学,ChatGPT还可以很容易地应用于医学报告的生成和理解[58],[59],教育[60],[61],[62],严谨的数学研究[63]和金融[64]。总的来说,ChatGPT是一个通用的工具,可以促进AI的普遍使用。
然而,研究人员也对聊天聊天可能产生的负面影响持谨慎态度。一些比较突出的问题与偏见[65]、[66]、伦理[67]、[68]、剽窃[69]、[70]和大量的工作替代[71]、[72]有关。作为回应,发表在《自然》杂志上的一篇评论呼吁人们迫切关注问责制、开源大型语言模型以及社会对人工智能的拥抱[65]。
3 DATASET
在这项工作中,我们使用临床自然语言处理(临床NLP)作为任务,并在两个流行的公共基准上进行我们的实验。在临床NLP中,数据增强是特别需要的,因为专家标注的巨大负担和严格的隐私规定使得大规模的数据标注不可行。我们将在下面的章节中详细描述这些数据集。
3.1 Symptoms Dataset
该数据集发布在Kaggle1上。它包含超过8小时的常见医学症状描述的音频数据。我们使用与音频数据对应的文本文本,并执行示例重复数据删除。预处理后的数据集包括7个症状类别的231个样本。
3.2 PubMed20k Dataset
PubMed20K是自然语言处理(NLP)和文本挖掘研究中广泛使用的数据集。它由大约20,000个生物医学领域的科学摘要组成,这些摘要已经用特定于任务的标签进行了注释,例如命名实体(例如,基因、疾病、化学品)、实体之间的关系以及其他语义角色。该数据集已被用于开发和评估各种NLP任务的机器学习模型,如命名实体识别、关系提取和文本分类。
PubMed20K是基于美国国家医学图书馆(US National Library of Medicine)维护的大型生物医学文献数据库PubMed构建的。PubMed20K中的摘要涵盖了生物医学的广泛主题,包括基因组学、药理学和临床医学。由于其规模、多样性和高质量的注释,PubMed20K已成为评估机器学习模型在生物医学NLP中的性能的流行基准数据集[73]。
4 METHOD
4.1 Overall Framework
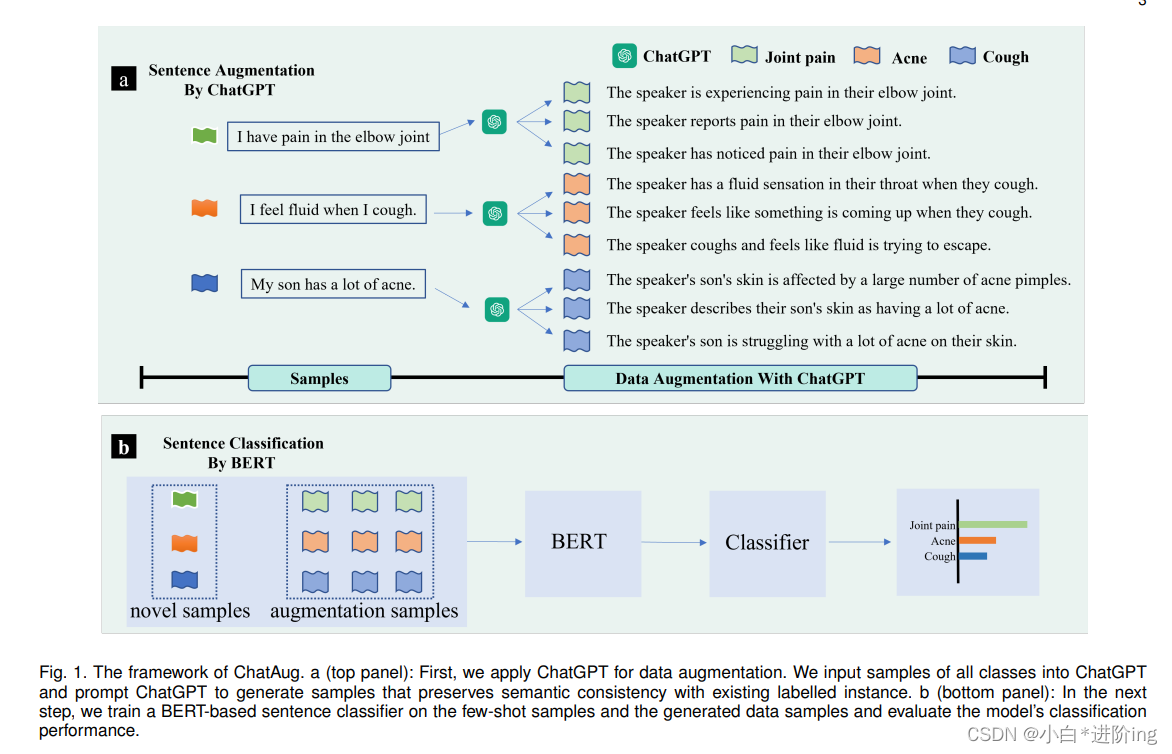
图1。ChatAug的框架。a(顶部面板):首先,我们应用ChatGPT进行数据增强。我们将所有类的样本输入到ChatGPT,并提示ChatGPT生成的样本保持了与现有标签实例的语义一致性。b(下面板):下一步,我们对少镜头样本和生成的数据样本训练一个基于bert的句子分类器,并评估模型的分类性能。

给定基数据集Db = {(xi, yi)}Nb i=1,标签空间yi∈Yb,新数据集Dn = {(xj, yj)}Nn j=1,标签空间yj∈Yn, Yb∩Yn =∅。在少镜头分类场景中,基本数据集Db有较大的标注样本集,而新数据集Dn只有少量标注样本集。在新数据集上评价了少镜头学习的性能。我们的目标是训练一个既包含基本数据集又包含有限新数据集的模型,同时在新数据集上实现令人满意的通用性。
ChatAug整体框架如图1所示,训练步骤如图算法1所示。首先,我们对Db上的BERT进行了微调。然后,使用ChatGPT对数据进行扩增,生成Daug n。最后,我们用D’= Dn∪Daug n对BERT进行了微调。
4.2 Data Augmentation with ChatGPT
与GPT[46]、GPT-2[74]、GPT-3[8]相似,ChatGPT属于自回归语言模型家族,使用变压器解码器块[75]作为模型主干。
在训练前,将ChatGPT视为一组样本X = {x1, x2,…, xn},由m个标记组成的样本xi定义为xi = (s1, s2,…, sm)。预训练的目标是使下列可能性最大化:
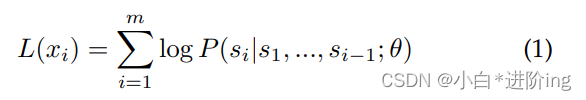
式中,θ表示ChatGPT的可训练参数。令牌由令牌嵌入和位置嵌入表示:
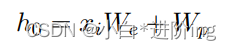
其中,We为标记嵌入矩阵,Wp为位置嵌入矩阵。然后用N个变压器块提取样本的特征:

其中n∈[1,n]。
最后,预测目标令牌:
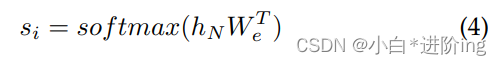
式中hN为顶部变压器块的输出。
在预训练之后,ChatGPT的开发人员应用了来自人类反馈的强化学习(RLHF)[21]来微调预训练的语言模型。RLHF通过根据人类反馈对语言模型进行微调,将语言模型与用户对各种任务的意图结合起来。ChatGPT的RLHF包含三个步骤:
监督微调(SFT): 与GPT、GPT-2和GPT-3不同,ChatGPT使用标记好的数据进行进一步的训练。人工智能培训师将扮演用户和人工智能助手的角色,根据提示构建答案。带有提示的答案将作为有监督的数据构建,以进一步训练预训练的模型。经过进一步的预训练,可以得到SFT模型。
奖励建模(RM): 基于SFT方法,对奖励模型进行训练,输入提示和响应,输出标量奖励。标签器将输出按最佳到最差排序,以构建一个排序数据集。两个输出之间的损失函数定义如下:
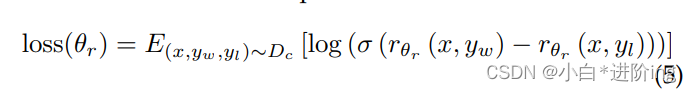
式中,θr为奖励模型参数;X是提示符,yw是yw和yl中首选的补全符;Dc是人类比较的数据集。
强化学习(RL): 通过使用奖励模型,ChatGPT可以通过近端策略优化(Proximal Policy Optimization, PPO)进行微调[76]。为了修复公共NLP数据集上的性能回归,RLHF将训练前的梯度与PPO梯度(也称为PPOptx)混合:
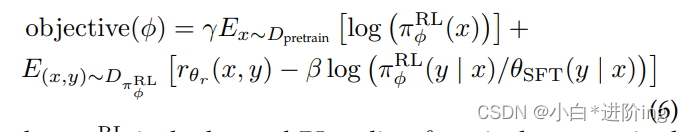
其中πRL φ为学习后的RL策略,θSFT为监督训练模型,Dpretrain为训练前分布。γ为控制训练前梯度强度的训练前损失系数,β为控制KL惩罚强度的训练前奖励系数。
与以前的数据增强方法相比,ChatGPT更适合用于数据增强,因为以下原因:
- ChatGPT使用大规模语料库进行预训练,具有更广阔的语义表达空间,有利于增强数据增强的多样性。
- 由于ChatGPT的微调阶段引入了大量的手工标注样本,所以ChatGPT生成的语言更符合人类的表达习惯。
- ChatGPT通过强化学习,可以比较不同表达式的优缺点,保证增强数据的高质量。
在BERT框架下,我们引入ChatGPT作为少镜头文本分类的数据增强工具。具体地说,ChatGPT用于将每个输入句子重新表达为6个额外的句子,从而增加了少量的样本。
4.3 Few-shot Text Classification
我们使用BERT[77]来训练一个少镜头文本分类模型。BERT的顶层输出特性h可以写为:
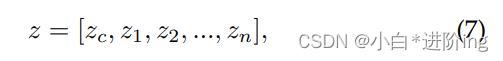
其中zc是类特殊令牌CLS的表示。对于文本分类,通常将zc输入到特定于任务的分类器头以进行最终预测。然而,在FSL场景中,由于样本量少,容易导致过拟合,缺乏泛化能力,通过微调BERT难以获得满意的性能。
为了有效地解决少镜头文本分类的挑战,人们提出了许多方法。一般来说,基于大型语言模型的少镜头文本分类方法有四类:元学习、提示调优、模型设计和数据增强。元学习是指通过任务来更新元参数[4],[7]的学习过程。基于提示的方法通过设计模板[8],[9],[10],[11]来指导大型语言模型预测正确的结果。模型设计方法通过改变模型的结构,引导模型从少炮样本中学习[78]。数据扩展使用相似的字符[22]、相似的词语义[30]、[31]或知识库[54][79]来扩展样本。我们的方法直接通过大型语言模型的语言能力进行数据扩充,是一种简单而有效的数据扩充方法。
目标函数: 我们的目标函数由交叉熵和对比学习损失两部分组成。我们将zc输入到一个全连接层中作为最终预测的分类器:
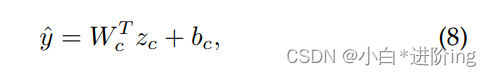
其中Wc和bc为可训练参数,以交叉熵为目标函数之一:
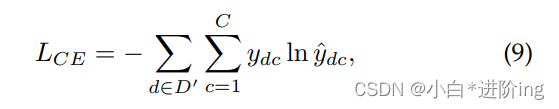
其中C为输出维数,等于基本数据集和新数据集的标签空间的并集,yd为基真值。
然后,为了充分利用基础数据集中的先验知识来指导新数据集的学习,引入对比损失函数使同一类别的样本表示更紧凑,不同类别的样本表示更独立。同一批次中对样品的对比损失定义如下:
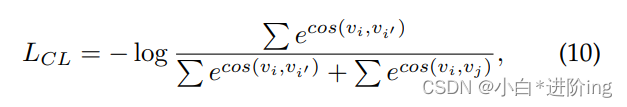
式中,vi和vI为同一类样本的zc;Vi和vj是属于不同类别的样本的zc;cos(·;·)为余弦相似度。
在基本数据的BERT微调阶段,我们只使用交叉熵作为目标函数。在少镜头学习阶段,我们结合交叉熵和对比学习损失作为目标函数:
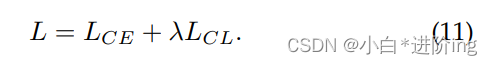
4.4 Baseline Methods
在实验部分,我们将我们的方法与其他流行的数据增强方法进行了比较。对于这些方法,我们使用开放源码库中的实现,包括nlpaug[80]和textattack[81]。
- InsertCharAugmentation(插入增强)。该方法在文本的随机位置插入随机字符,通过向数据中注入噪声来提高模型的泛化能力。
- SubstituteCharAugmentation。这种方法随机地用其他字符替换选中的字符。
- SwapCharAugmentation[22]。该方法随机交换两个字符。
- DeleteCharAugmentation.删除。该方法随机删除字符。
- 扩充。OCR增强模拟OCR识别过程中可能出现的错误。例如,OCR工具可能会将“0”错误地识别为“o”,将“I”错误地识别为“l”。
- 拼写增强[23]。它通过故意拼错一些单词来创建新的文本。该方法使用牛津词典提供的最容易拼错的英语单词列表,例如,将“because”拼成“because”。
- 键盘增强[22]。它通过用QWERTY布局键盘中相邻的字符替换随机选择的字符来模拟打字错误。例如,将“g”替换为“r”、“t”、“y”、“f”、“h”、“v”、“b”或“n”。
- SwapWordAug[24]。它在文本中随机交换单词。该方法是Wei等人提出的Easy Data Augmentation (EDA)的一个子方法。
- DeleteWordAug. 8DeleteWordAug随机删除文本中的单词,也是EDA的一个子方法。
- ppdb同义词[26]。它用PPDB词库中的同义词替换单词。同义词替换可以保证语义的一致性,适用于分类任务。
- 单词同义词它用WordNet同义词库中的同义词替换单词。
- 替换wordbygooglenewsembeddings[28]。它将单词替换为它们在嵌入空间中的前n个相似单词。使用的单词嵌入是通过GoogleNews语料库进行预训练的。
- InsertWordByGoogleNewsEmbeddings[80]。它从GoogleNews语料库中随机选取单词,并将其插入文本的随机位置。
- CounterFittedEmbeddingAug[30],[31]。它将单词替换为它们的邻居,在反向匹配的嵌入空间中。相对于SubstituteWordByGoogleNewsEmbeddings使用的GoogleNews词向量,反拟合嵌入引入了同义词和反义词的约束,即同义词之间的嵌入会拉近,反之亦然。
- ContextualWordAugUsingBert(插入)[32],[33]。该方法使用BERT根据上下文插入单词,即在输入文本的任意位置添加< mask >标记,然后让BERT预测该位置的标记。
- ContextualWordAugUsingDistilBERT(插入)。该方法使用蒸馏伯特代替BERT进行预测,其余与ContextualWordAugUsingBert(Insert)相同。
- ContextualWordAugUsingRoBERTA(插入)该方法使用RoBERTA代替BERT进行预测,其余与ContextualWordAugUsingBert(Insert)相同。
- ContextualWordAugUsingBert(替换)。该方法[32],[33]使用BERT根据上下文替换单词,即用< mask >令牌替换文本中随机选择的单词,然后让BERT预测该位置的令牌。
- ContextualWordAugUsingDistilBERT(替代品)。本方法使用蒸馏伯特代替BERT进行预测,其余与ContextualWordAugUsingBert(Substitute)相同。
- ContextualWordAugUsingRoBERTA本方法使用RoBERTA代替BERT进行预测,其余与ContextualWordAugUsingBert(Substitute)相同。
- 反向翻译8月方法[37]将文本翻译成德语,然后翻译成英语,从而产生与原文不同但具有相同语义的新文本。我们使用facebook开发的wmt19-en-de和facebook/wmt19-de-en语言翻译模型[82]进行翻译。
4.5 Evaluation Metrics
我们使用余弦相似度和TransRate[83]作为度量来评估我们的增广数据的完整性(即特征是否包含关于目标任务的足够信息)和紧凑性(即每一类特征是否紧凑到可以很好地泛化)。
4.5.1 Embedding Similarity
为了评估数据增强方法生成的样本与实际样本之间的语义相似度,我们采用了测试数据集中生成的样本与实际样本之间的嵌入相似度。一些最常见的相似度度量包括欧氏距离、余弦相似度和点积相似度。在本研究中,我们选择余弦相似度来捕捉潜在空间中的距离关系。余弦相似度度量两个向量之间夹角的余弦值。当两个向量更相似时,这个值会增加,范围在0到1之间。我们将样本输入到预训练的BERT中,并使用CLS标记的表示作为样本嵌入。余弦相似度度量在NLP中是常用的[84],我们遵循这个约定。
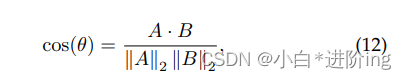
式中,A和B分别表示比较的两个嵌入向量。
4.5.2 TransRate
TransRate是一个度量指标,它基于由预先训练的模型提取的特征与其标签之间的相互信息,通过一次对目标数据的传递来量化可转移性。当所有类的数据协方差矩阵相同时,度量值达到最小值,使得不可能区分来自不同类的数据,防止任何分类器获得比随机猜测更好的结果。因此,TransRate越高,表明数据的可学习性越好。具体来说,从源任务t到目标任务Tt的知识转移测量如下:
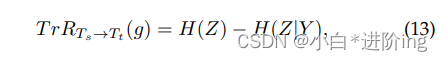
其中,Y表示增广样本的标签,Z表示经过预训练的特征提取器g提取的潜伏期嵌入特征。TrR表示TransRate值。H(·)为Shannon熵[85]。
5 EXPERIMENT RESULTS
在实验中,我们使用BERT作为基本模型。首先,我们在基本数据集上训练我们的模型以得到预训练的模型。然后,我们利用少样本对模型进行微调,并采用不同的数据扩充方法生成扩充样本。我们将这些样本输入BERT模型,对预训练的模型进行微调。为了评估不同数据增强方法的有效性,我们应用了两种不同的设置。第一个是裸BERT模型。在第二种情况下,我们在训练中增加对比损失。在我们对症状数据集进行的实验中,我们对150个epoch使用8个批处理大小,设置最大序列长度为25,λ为1,并使用4e-5的学习速率。同样,在我们对PubMed20K数据集的实验中,我们采用了相同的训练配置,最大序列长度设置为40。
5.1 Classification Performance Comparison
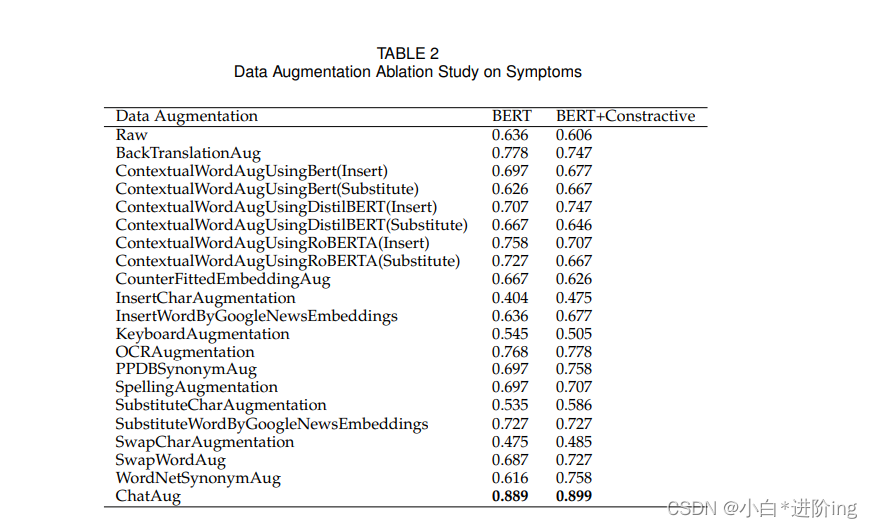
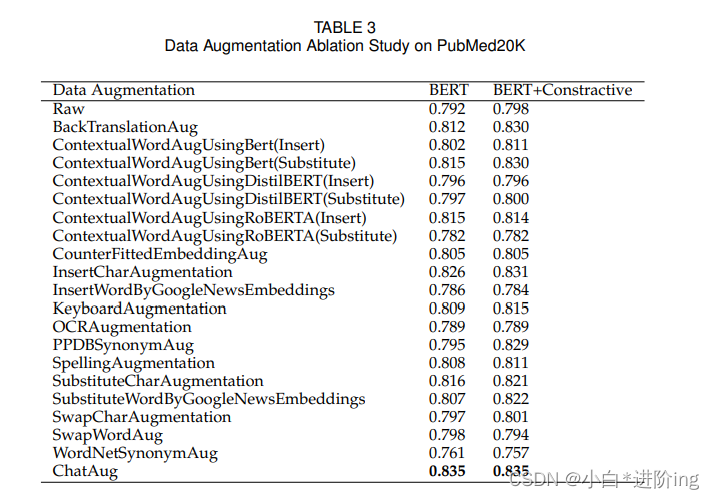
表2和表3显示,ChatAug在Symptoms和PubMed20K数据集上都获得了最高的准确性。在PubMed20K数据集上,ChatAug对BERT和具有对比损失的BERT的准确率均达到83.5%,而在没有数据增强的情况下,准确率分别仅为79.2%和79.8%。在“症状”数据集中,在没有数据增强的情况下,BERT的准确性仅为63.6%,在有对比损失的情况下为60.6%。然而,我们的ChatAug方法显著提高了准确度,分别为88.9%和89.9%。这些结果表明,使用ChatGPT的数据增强对于提高机器学习模型在各种应用中的性能是更有效的。
5.2 Evaluation of Augmented Datasets
在本节中,我们评估我们的增强数据在潜在空间中的性能,并将结果可视化在图2中。使用余弦相似度和TransRate度量来评估潜在嵌入(更多细节请参阅4.5节)。横轴表示余弦相似度值和Transrate值,纵轴表示分类精度。嵌入式相似度度量的是增广数据与测试数据集之间的相似度,相似度越高,说明增广数据与真实数据的匹配度越高,完整性和紧凑性也越高。由于TransRate越高,表明数据的可学习性越好,所以TransRate越高,意味着数据质量越高。最理想的候选方法应该位于可视化的右上角。如图2所示,根据症状数据集和PubMed20K数据集的完整性和紧凑性,ChatAug生成了高质量的样本。
6 CONCLUSION AND DISCUSSION
在本文中,我们提出了一种新的数据增强方法来进行少镜头分类。与其他方法不同的是,我们的模型在语义级别上扩展了有限的数据,增强了数据的一致性和鲁棒性,从而得到了一个性能更好的训练模型。
虽然ChatAug在数据增强方面取得了很好的成果,但也存在一定的局限性。F:例如,在医学文本的识别和扩展过程中,由于缺乏领域知识,可能会产生不正确的增强数据。在未来的研究中,我们可以先对原始模型进行微调,然后再进行数据扩充来解决这个问题。
本文提出的ChatAug方法在文本分类中取得了良好的效果。未来研究的一个有前途的方向是在更广泛的下游任务上调查ChatAug的有效性。例如,ChatGPT具有很强的提取关键点和理解句子的能力,我们可以预见在文本摘要中可能会有很好的结果。具体而言,ChatGPT可能对特定领域的科学论文摘要[86]和临床报告摘要[87]有价值。公开可获得的领域特定的科学论文摘要数据集和临床报告数据集很少,而且由于隐私问题和需要专家知识来生成带注释的摘要,这些数据集通常以小范围提供。然而,ChatGPT可以通过以不同的表示风格生成不同的增强摘要样本来解决这个挑战。ChatGPT生成的数据通常是简洁的,这对于进一步增强训练后的模型的泛化能力是有价值的。
生成图像模型如DALLE2[88]和Stable Diffusion[89]的急剧兴起,为ChatAug应用于计算机视觉中的少镜头学习任务提供了机会。例如,精确的语言描述可以用于指导生成模型从文本生成图像,或在现有图像的基础上生成新的图像,作为少镜头学习任务的数据增强方法,特别是当与高效的微调方法相结合时[90],[91],如稳定扩散的LoRA。因此,来自大型语言模型的先验知识可以促进更快的领域适应和更好的计算机视觉生成模型的少镜头学习。
最近的研究表明,大型语言模型(LLMs),如GPT-3和ChatGPT,能够解决心理理论(Theory of Mind, ToM)任务,这在以前被认为是人类独有的[92]。虽然LLM的类似汤姆的能力可能是改进性能的一个无意的副产品,但认知科学和人类大脑之间的潜在联系是一个成熟的探索领域。认知和脑科学的进步也可以用来启发和优化LLM的设计。例如,有人提出BERT模型中神经元的激活模式与人脑网络中的神经元的激活模式可能有相似之处,并可能耦合在一起[93]。这为利用脑科学的先验知识开发LLM提供了一个很有前途的新方向。随着研究人员继续研究LLM和人类大脑之间的联系,我们可能会发现提高人工智能系统的性能和能力的新方法,导致该领域令人兴奋的突破。
自结1
本文主要是利用chatgpt和gpt3.5首次用在文本简化方面,经过人工评估和相关的评估指标详细研究之后发现,这两种表现性能都非常好,甚至可以与人工简化相媲美,但是chatgpt更倾向于使句子的单词和语法更简单,从而删除替换句子在不必要的成分,gpt3.5更倾向于保留句子的基本含义。而且这种能力也可以适应多语言应用,具有很强的泛化能力,简化的句子倾向于按照句子最简程度依次排列,所以一般第一个简化结果就是最好的。同时,作者也发现,随着学习简化示例的增加,简化的性能也会打折扣。由此可见,对于few-shot的设计也是非常重要的。作者也打算研究更精细的方法,进行进一步的研究。
本文主要是在ChatGpt的基础上提出的一种新的数据增强方法ChatAug,该方法先将基本数据集在Bert上进行微调,然后用少量标签的数据集通过ChatGpt进行数据增强,扩充数据集,从而提高了模型的泛化能力和鲁棒性,并将新的数据集与原有数据集结合再放入Bert中进行微调,根据在两个基准数据集上的测试表现证明这种数据增强方法都取得了很好的效果。
最后,作者也指出该方法存在可能由于缺乏领域知识从而生成错误的数据,并提出该方法也可以进一步扩展到多个领域,诸如文本摘要、计算机视觉以及认知脑科学等领域,未来的发展可能是无限大的。
扬州大学研一在读学生,本篇笔记仅以帮助自己更好理解论文,也方便日后复查学习。 ↩︎