cuda调试
由于在编程过程中发现不同的网格块的结构,对最后的代码结果有影响,所以想记录一下解决办法。
CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid
cuda context (上下文)
context类似于CPU进程上下,表示由管理层 Drive 层分配的资源的生命周期,多线程分配调用的GPU资源同属一个context下,通常与CPU的一个进程对应。
CUDA Stream
CUDA Stream是指一堆异步的CUDA操作,他们按照host代码调用的顺序执行在device上。
Stream维护了这些操作的顺序,并在所有预处理完成后允许这些操作进入工作队列,同时也可以对这些操作进行一些查询操作。
这些操作包括host到device的数据传输,launch kernel以及其他的由host发起由device执行的动作。
这些操作的执行总是异步的,CUDA runtime会决定这些操作合适的执行时机。我们则可以使用相应的cuda api来保证所取得结果是在所有操作完成后获得的。同一个stream里的操作有严格的执行顺序,不同的stream则没有此限制。
CUDA API可分为同步和异步两类,同步函数会阻塞host端的线程执行,异步函数会立刻将控制权返还给host从而继续执行之后的动作。
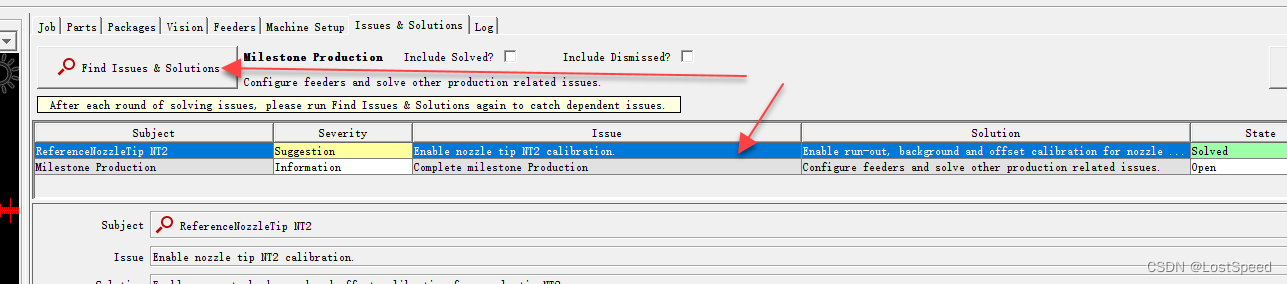
当我们使用CUDA异步函数与多流(Multi Stream)时,多线程间既可以实现并行进行数据传输与计算,如下图所示。不过需要注意的是, CUDA runtime API默认的default stream是同步串行的,且一个进程内的所有线程都在default stream下,需要显式声明default之外的Stream才可以实现多流并发。

显卡硬件架构:SM、SP、Warp
具体到nvidia硬件架构上,有以下两个重要概念:
SP(streaming processor):最基本的处理单元,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
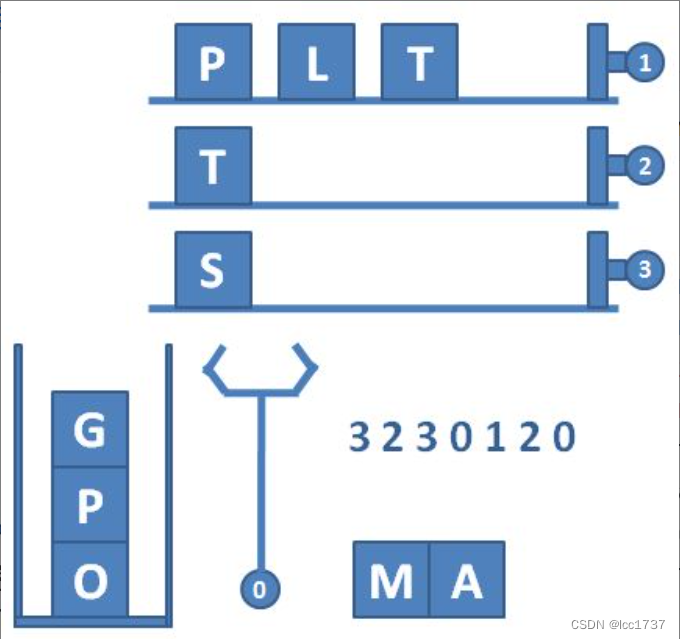
SM(streaming multiprocessor):多个SP加上其他的一些资源组成一个SM,也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。如下图是一个SM的基本组成,其中每个绿色小块代表一个SP。
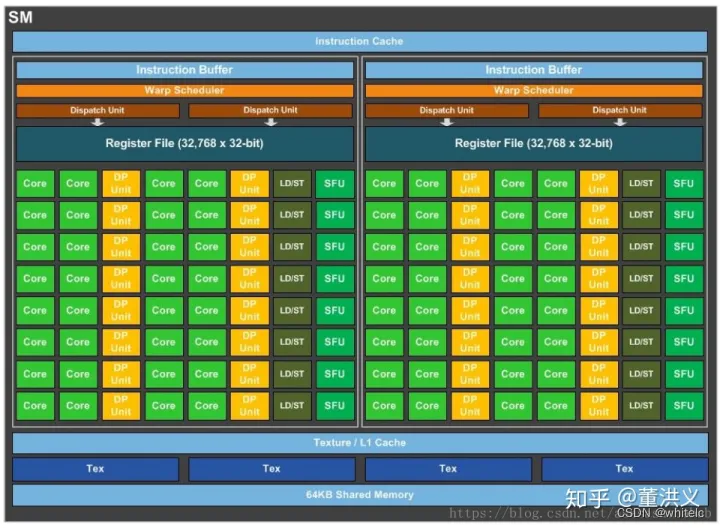
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个。当一个kernel启动后,thread会被分配到很多SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
Warp调度
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident thread最多只有 SM*warp个。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以新调度的warp的状态已经存储在SM中了。
每个SM有一个32位register集合放在register file中,还有固定数量的shared memory,这些资源都被thread瓜分了,由于资源是有限的,所以,如果thread比较多,那么每个thread占用资源就叫少,thread较少,占用资源就较多,这需要根据自己的要求作出一个平衡。
软件架构:Kernel、Grid、Block
上面的context与stream类似进程、线程的概念,具体到我们如何调用GPU上的线程实现我们的算法,则是通过Kernel实现的。在GPU上调用的函数成为CUDA核函数(Kernel function),核函数会被GPU上的多个线程执行。我们可以通过如下方式来定义一个kernel:
func_name<<<grid, block>>>(param1, param2, param3....);
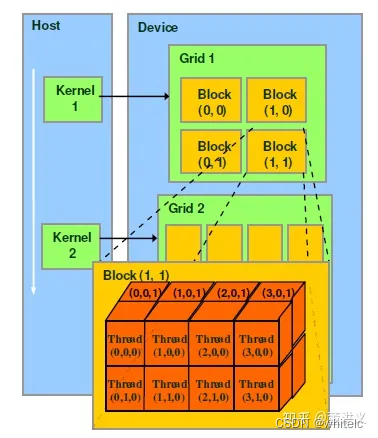
Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。
Block:一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。
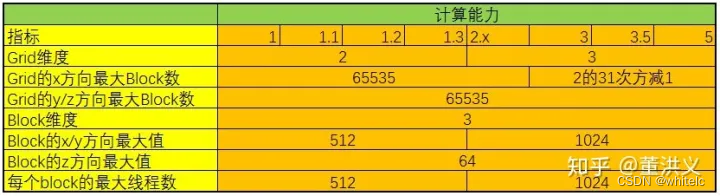
CUDA中可以创建的网格数量跟GPU的计算能力有关,可创建的Grid、Block和Thread的最大数量如下所示:
以上是引用:
https://zhuanlan.zhihu.com/p/266633373
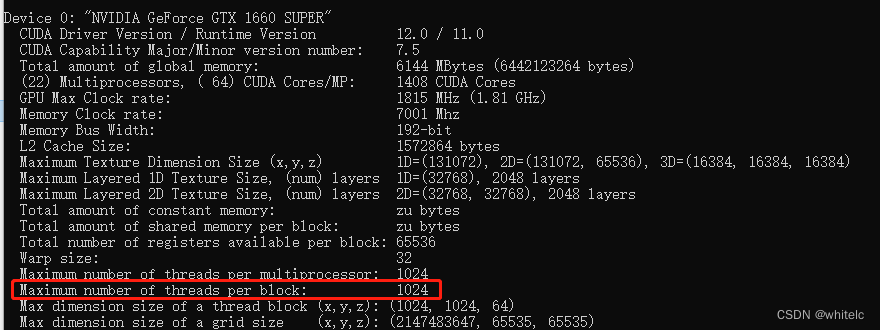

通过deviceQuery可以知道,每个block中只有1024个thread,而32 × 32× 32 = 32768 > 1024:会出现以下错误,运行时参数传递得太大了,出现这类问题后,cuda仍可继续提供服务,仅单纯拒绝了启动核函数。
cudaErrorInvalidConfiguration = 9,"invalid configuration argument"
所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。在分配Grid、Block大小时,我们可以遵循这几点原则:
- 保证block中thread数目是32的倍数。这是因为同一个block必须在一个SM内,而SM的Warp调度是32个线程一组进行的。
- 避免block太小:每个blcok最少128或256个thread。
- 根据kernel需要的资源调整block,多做实验来挖掘最佳配置。
- 保证block的数目远大于SM的数目。
配置Nsight system
低开销的性能分析工具,Nvidia nsight Systems旨在提供开发人员优化其软件所需的洞察力。在工具中可视化活动数据,以帮助用户调查瓶颈,避免推断误报,并以更高的性能提高概率进行优化。用户将能够识别问题,例如GPU不足、不必要的GPU同步、CPU并行化不足,甚至目标平台的CPU和GPU之间的算法异常。
- 打开该程序
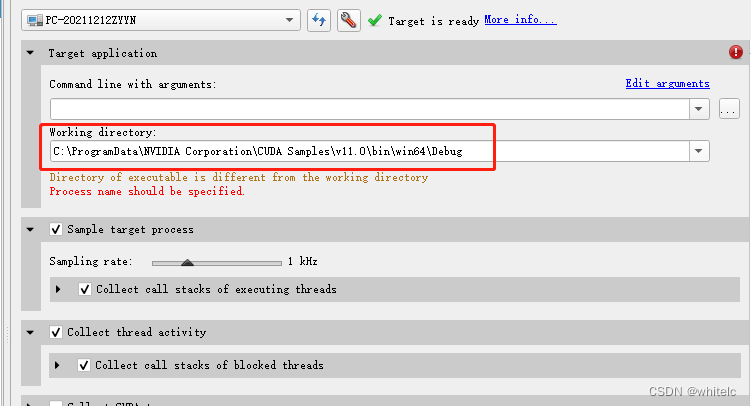
- 上面的 command line with arguments中填写 要调试的cuda项目的exe文件我的目录是
F:\E_cuda\test1\testCUDA\x64\Debug\testCUDA.exe
注意这个路径需要是全英文的
3.下面的 working directory 填写 cuda中的Debug文件,我的cuda中的默认目录是
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64\Debug
F:\E_cuda\test1\testCUDA\x64\Debug\testCUDA.exe
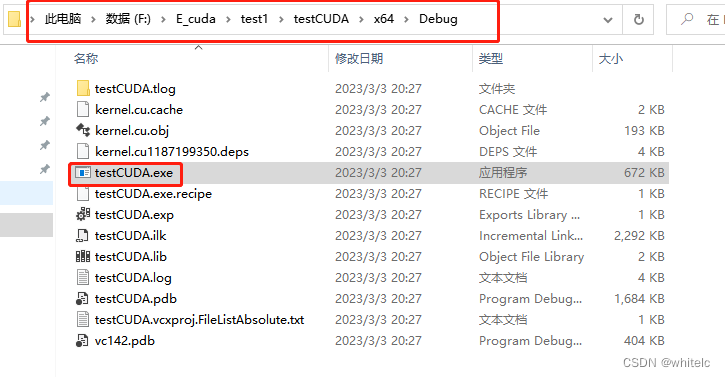
然后start就行了
但是还不知道怎么去看具体的kernel
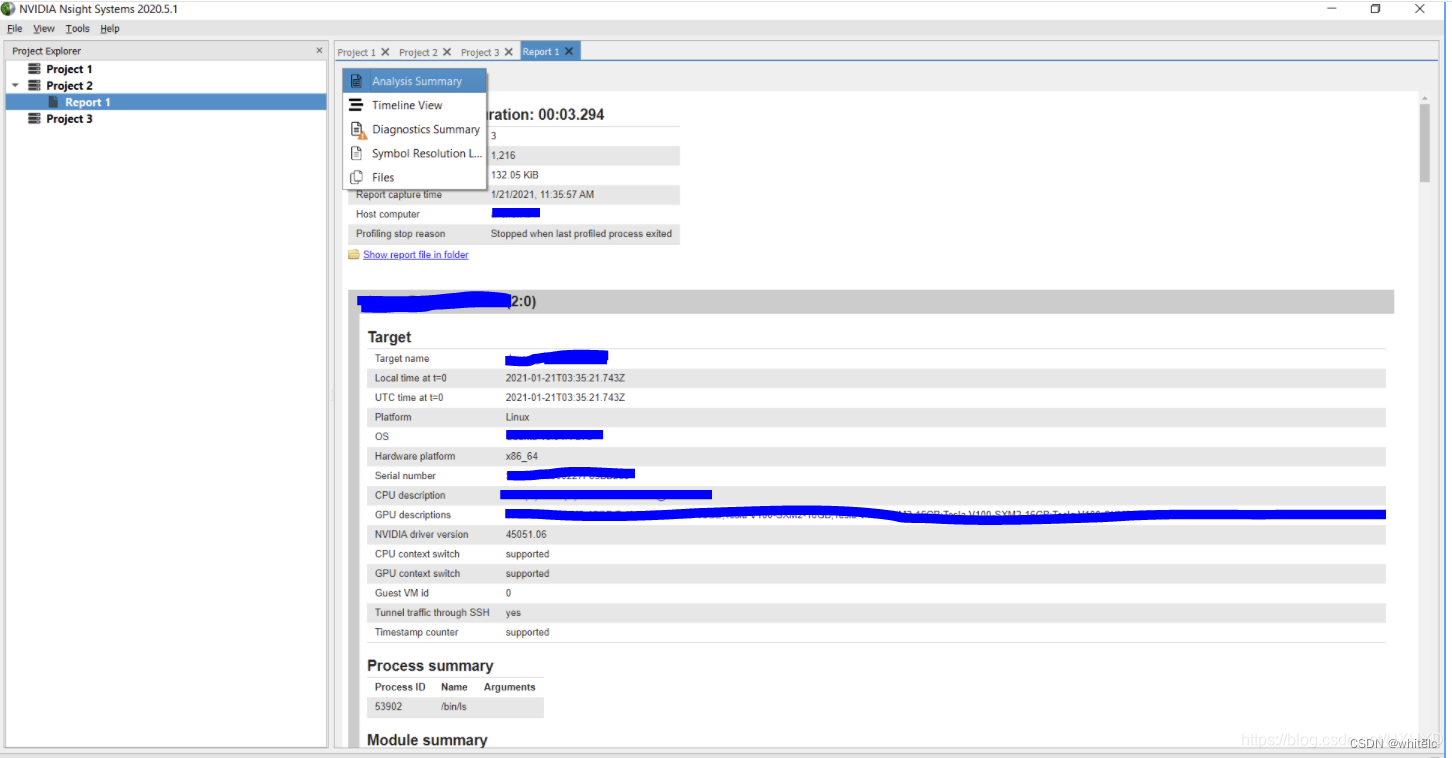
这个Report包含5部分内容:
- Analysis Summary (分析总结,内容非常全面,包含了Target的详细信息,Process summary, Module summary, Thread summary, Environment Variables, CPU info, GPU info等等)
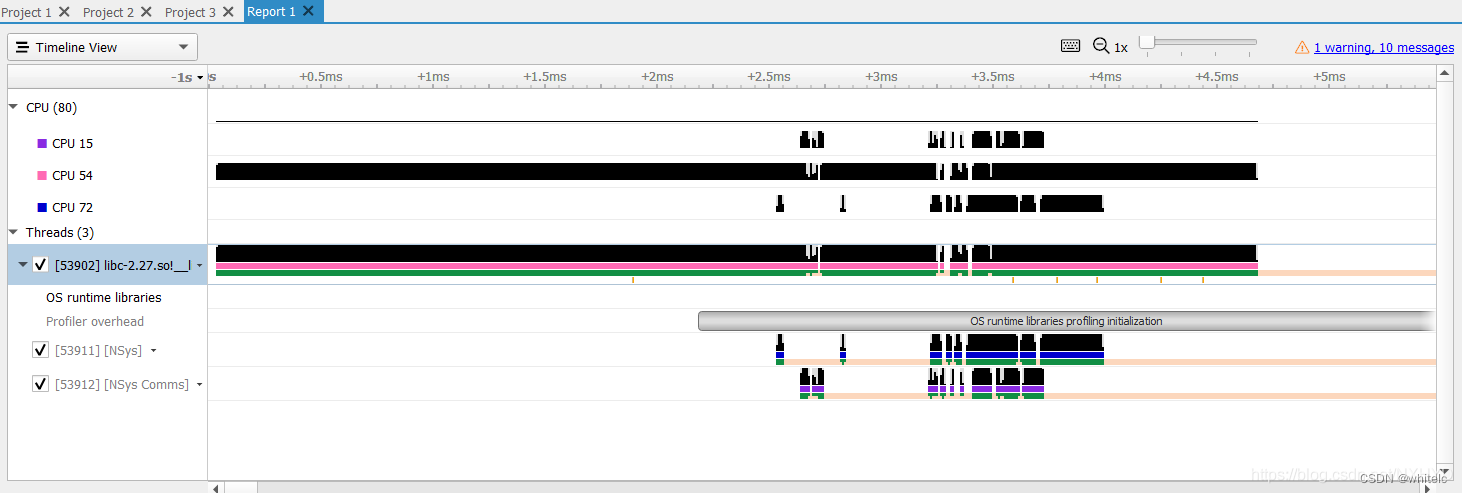
- Timeline View (展示CPU/GPU各个核的工作时间线,一般用来来勘察模型训练或者推理的瓶颈在哪里)
- Diagnostics Summary (顾名思义,诊断总结。就是程序在运行中做了什么,有什么warning , error,或者message的,都在这里汇总)
- Symbol Resolution Logs(暂时不知道是干嘛的)
Files (执行结果的log 文件:pid_stdout.log,& 执行出错的log 文件pid_stderr.log)
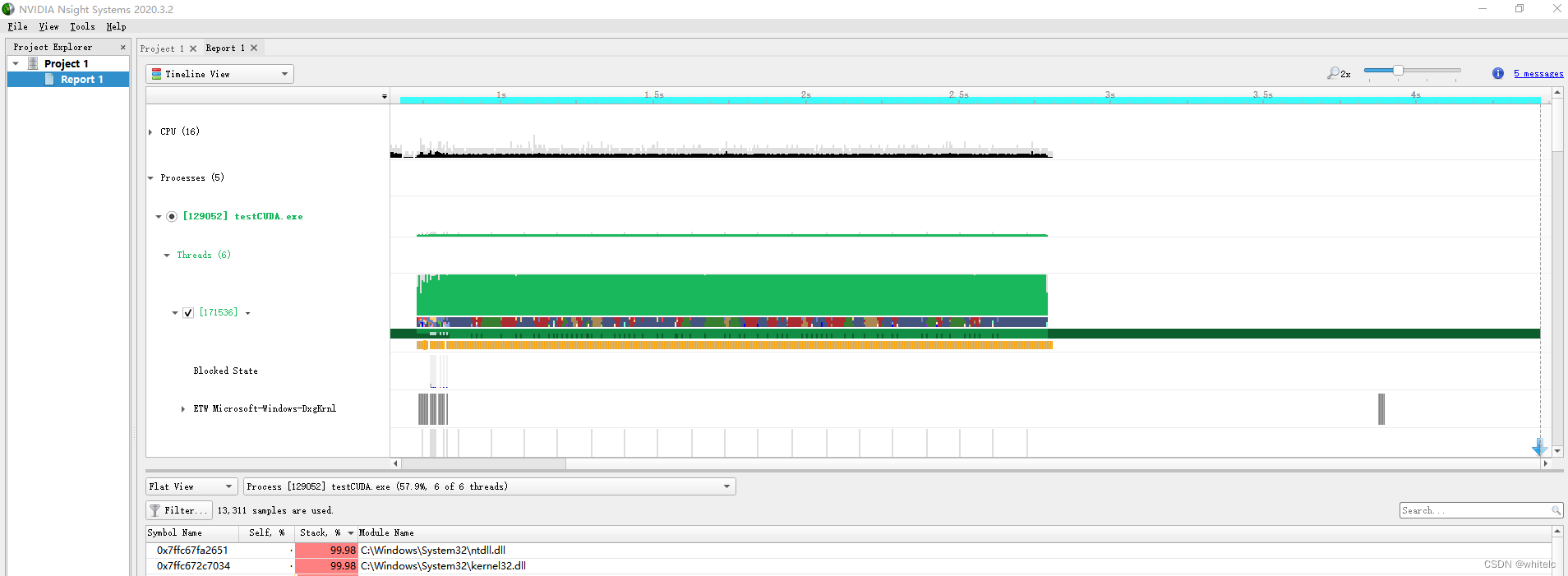
简单看看Timeline view。如下,这里有三个CPU核在工作,它们启动和停止的时间可以从timeline上看到。还可以看到下面有三个Thread的时间线。
https://blog.csdn.net/NXHYD/article/details/112915968
这位博主的图和说明
我在b站上找的视频发现别人用的是 nsight system profiles 这个,(还没找到是啥,只有一个visoul profiler—需要java的环境)但是他讲的时候又说是NVTX,有点晕
https://www.bilibili.com/video/BV13w411o7cu/?spm_id_from=333.337.search-card.all.click&vd_source=0a4d8c47345ce0df71cd9cdb01575134
就是这个
以下是我使用visoul profiler—的报错
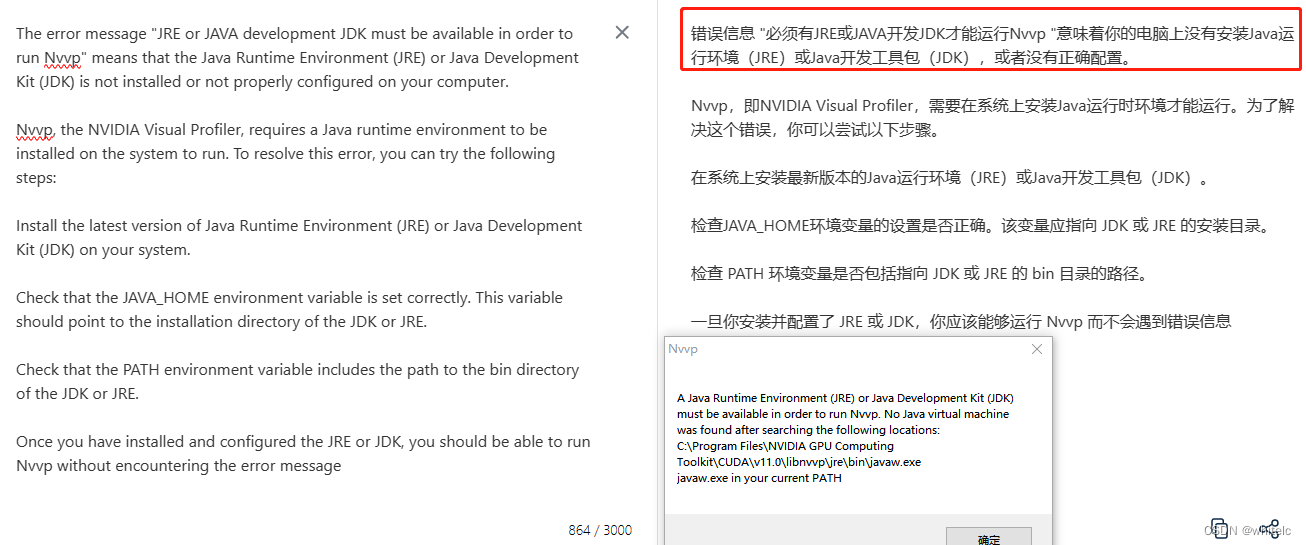
英伟达的官方文档关于nsight-system的
https://docs.nvidia.com/nsight-systems/2020.3/profiling/index.html
NVTX是一种CUDA Profiler的工具
可以用于在CUDA程序中进行标记和注释,以便更好地理解和优化程序的性能。以下是使用NVTX的一些示例代码和步骤:
- 在CUDA代码中包含nvToolsExt.h文件。
#include <nvToolsExt.h>
解决:右键cuda项目——属性——配置属性——C/C++——常规——附加包含目录
可能遇到的问题:无法在 Visual Studio 中打开 nvToolsExt.h 文件,可能是因为 Visual Studio 找不到 CUDA 的 include 目录。
错误示范
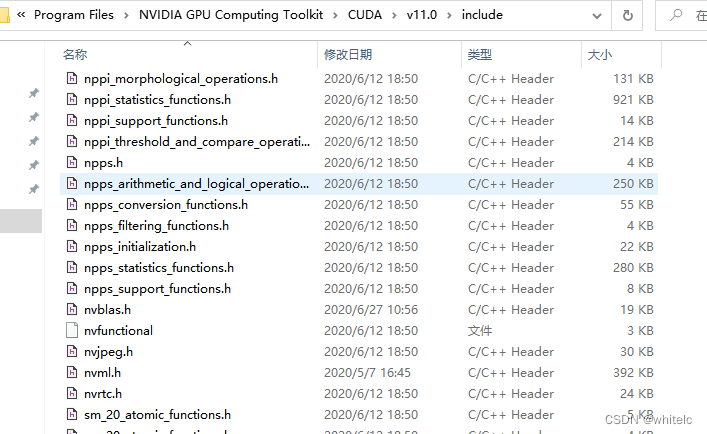
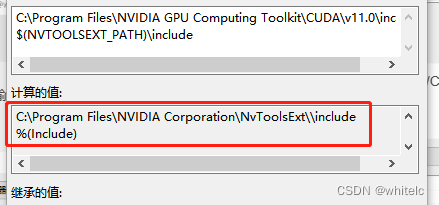
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include
but我这里没有这个头文件
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\common\inc
这个目录下也没有
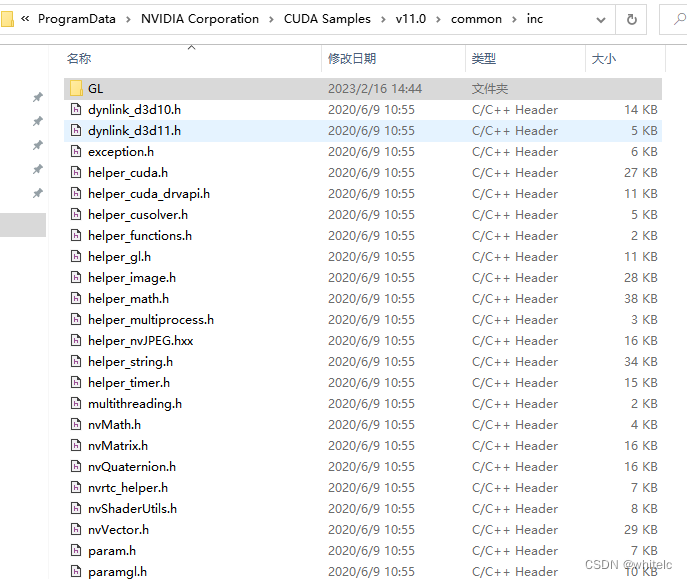
正确示范 可以通过在vs项目属性里面进行设置
第一步:在项目属性页,打开vc++目录(c程序是c目录会略微有些不同),打开外部包含目录,输入:$(NVTOOLSEXT_PATH)\include
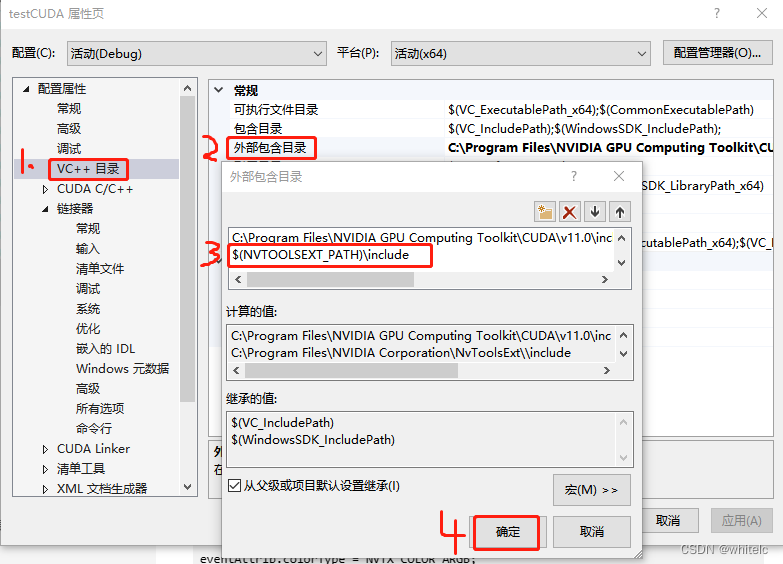
第二步,打开链接器–常规----附加库目录,输入:$(NVTOOLSEXT_PATH)\lib\$(Platform)
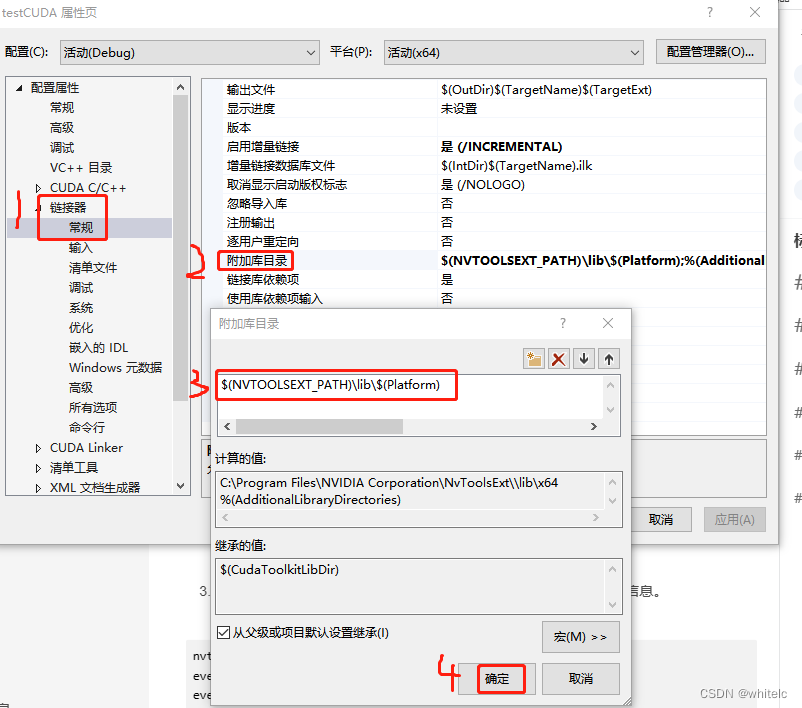
第三步,打开链接器–输入—附加依赖项,输入:nvToolsExt64_1.lib
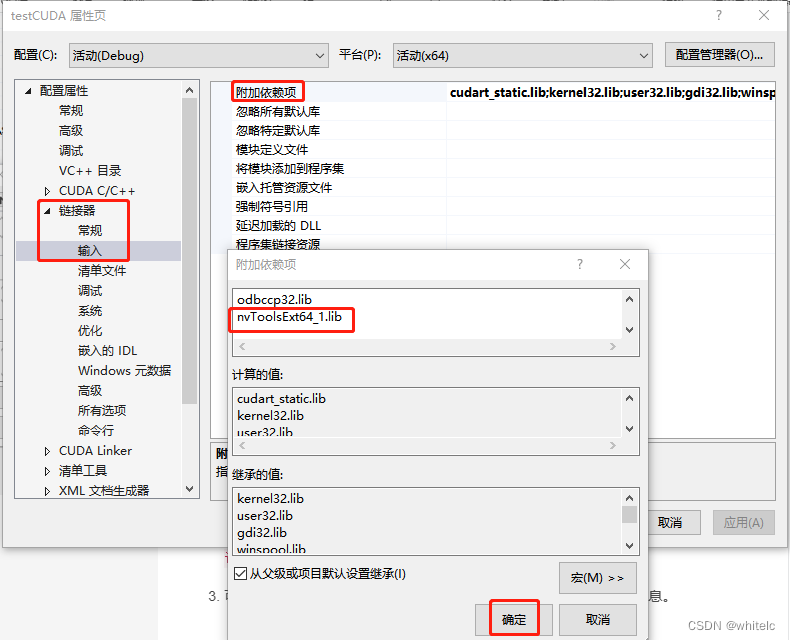
在 .cu 文件中注释代码,还应该设置:打开CUDA C/C+±-common—附加依赖项,输入:$(NVTOOLSEXT_PATH)\include
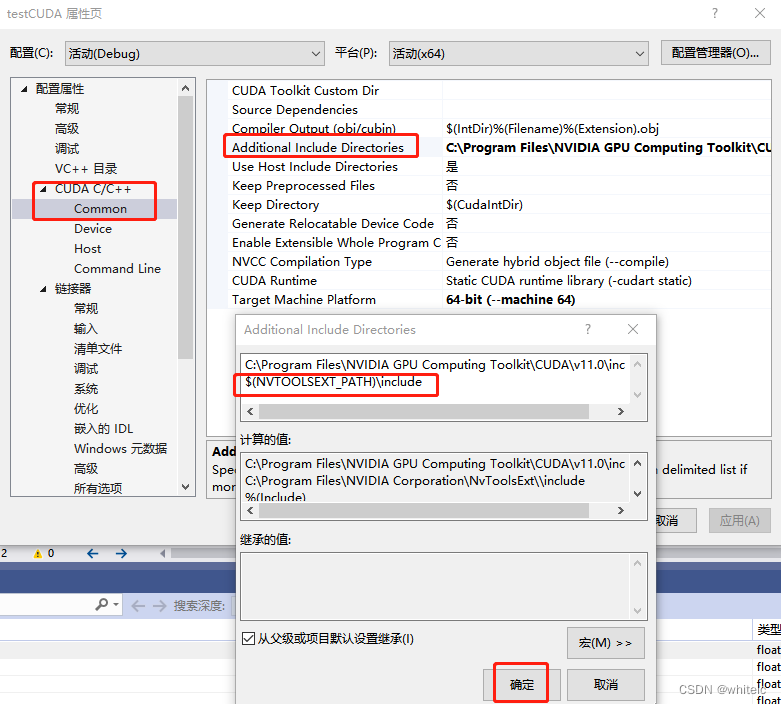
英伟达官方NVTX文档
https://docs.nvidia.com/nsight-visual-studio-edition/nvtx/index.html
-
在需要标记的代码块前后插入标记函数。
nvtxRangePushA("My Code Block"); // 开始标记代码块 nvtxRangePop(); // 结束标记 -
可以使用nvtxEventAttributes_t结构体自定义标记的颜色和描述等信息。
nvtxEventAttributes_t eventAttrib = {0};
eventAttrib.version = NVTX_VERSION;
eventAttrib.size = NVTX_EVENT_ATTRIB_STRUCT_SIZE;
eventAttrib.colorType = NVTX_COLOR_ARGB;
eventAttrib.color = 0xFF00FF00;
eventAttrib.messageType = NVTX_MESSAGE_TYPE_ASCII;
eventAttrib.message.ascii = "My Custom Event";
nvtxRangePushEx(&eventAttrib);
// 代码块
nvtxRangePop();
- 还可以使用nvtxMarkA()函数在代码中插入注释。
nvtxMarkA("My Comment");
- 在运行程序时,可以使用nvprof或Nvvp等工具来查看标记和注释。
注意:使用NVTX可能会对程序的性能产生一定的影响
cuda运行时间记录
在python里面
异步计算的结果是没有同步的时间测量是不准确的。要获得精确的测量值,应该在测量前调用 torch.cuda.synchronize(),或者使用 torch.cuda.Event 记录时间,如下所示:
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
start_event.record()
# 在这里运行一些东西
end_event.record()
torch.cuda.synchronize() # 等待事件被记录!
elapsed_time_ms = start_event.elapsed_time(end_event)
https://blog.csdn.net/dedell/article/details/121574306
先这样,后续会补充,老师让我去搞二维的共享内存的程序,祝我好运!!!