死海效应: 公司发展到一定阶段后,工作能力强的员工,就会离职,因为他无法容忍公司的某些行为,即使辞职也很快会找到好工作;工作能力差的员工,却赖着不走,因为辞职以后也不太好找工作,在公司时间久了就变成了中高层。
好员工像死海的淡水一样蒸发掉,然后死海盐度就变得很高,正常生物不容易存活。

系列文章目录
- 项目搭建
- App登录及网关
- App文章
- 自媒体平台(博主后台)
- 内容审核(自动)
- 热点文章-实时计算(kafkaStream)
文章目录
- 系列文章目录
- 一、实时流式计算
- 1. 概述
- 1.1 概念
- 1.2 应用场景
- 1.3 技术方案选型
- 1.4 Kafka Stream
- 1.4.1 概述
- 1.4.2 Kafka Streams的关键概念
- 1.4.3 KStream
- 2. 入门案例
- 2.1 需求分析
- 2.2 pom依赖
- 2.3 流式处理
- 2.4 生产者
- 2.5 消费者
- 2.6 测试
- 3. SpringBoot集成
- 3.1 自定配置参数
- 3.2 自定义配置
- 3.3 配置类
- 3.4 测试
- 二、app端热点文章计算
- 1. 思路分析
- 2. 功能实现
- 2.1 配置
- 2.1.1 集成kafka生产者配置
- 2.1.2 topic常量类
- 2.2 发送消息
- 2.2.3 点赞
- 2.2.4 阅读
- 2.3 流式处理
- 2.3.1 聚合流式处理
- 2.3.2 格式化消息
- 2.4 测试
- 2.5 监听器
- 2.6 更新文章分值
- 2.7 综合测试
一、实时流式计算
1. 概述
1.1 概念
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。
同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。
流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。
同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。

流式计算就相当于上图的右侧扶梯,是可以源源不断的产生数据,源源不断的接收数据,没有边界。
1.2 应用场景
- 日志分析: 网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策
- 大屏看板统计: 可以实时的查看网站注册数量,订单数量,购买数量,金额等。
- 公交实时数据: 可以随时更新公交车方位,计算多久到达站牌等
- 实时文章分值计算: 头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
1.3 技术方案选型
-
Hadoop: Hadoop是一个分布式系统基础架构。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
-
Apche Storm: Storm 是一个分布式实时大数据处理系统,可以帮助我们方便地处理海量数据,具有高可靠、高容错、高扩展的特点。是流式框架,有很高的数据吞吐能力。
-
Kafka Stream: 可以轻松地将其嵌入任何Java应用程序中,并与用户为其流应用程序所拥有的任何现有打包,部署和操作工具集成。
1.4 Kafka Stream
1.4.1 概述
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)

1.4.2 Kafka Streams的关键概念
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。

1.4.3 KStream
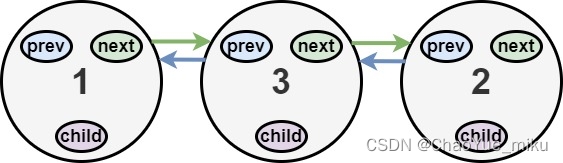
数据结构类似于map,如下图,key-value键值对

KStream

KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。
数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
为了说明这一点,让我们想象一下以下两个数据记录正在发送到流中:
(“ alice”,1)->(“” alice“,3)
如果您的流处理应用是要总结每个用户的价值,它将返回4了alice。为什么?因为第二条数据记录将不被视为先前记录的更新。(insert)新数据
2. 入门案例
2.1 需求分析

2.2 pom依赖
编辑 heima-leadnews-test\kafka-demo\pom.xml 文件:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<exclusions>
<exclusion>
<artifactId>connect-json</artifactId>
<groupId>org.apache.kafka</groupId>
</exclusion>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
2.3 流式处理
新建 heima-leadnews-test\kafka-demo\src\main\java\com\heima\kafka\sample\KafkaStreamQuickStart.java 文件:
/**
* 流式处理
*/
public class KafkaStreamQuickStart {
public static void main(String[] args) {
// kafka的配置信息
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-quickstart");
//stream 构建器
StreamsBuilder streamsBuilder = new StreamsBuilder();
//流式计算
streamProcessor(streamsBuilder);
//创建kafkaStream对象
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), prop);
//开启流式计算
kafkaStreams.start();
}
/**
* 流式计算
*
* @param streamsBuilder
*/
private static void streamProcessor(StreamsBuilder streamsBuilder) {
//创建KStream对象,同时指定从那个topic中接收消息
KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");
/**
* 处理消息的value
*/
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
})
//按照value进行聚合处理
.groupBy((key, value) -> value)
//时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
//统计单词的个数
.count()
//转换为kStream
.toStream()
.map((key, value) -> {
System.out.println("key:" + key + ",value:" + value);
return new KeyValue<>(key.key().toString(), value.toString());
})
//发送消息
.to("itcast-topic-out");
}
}
2.4 生产者
新建 heima-leadnews-test\kafka-demo\src\main\java\com\heima\kafka\sample\ProducerStreamQuickStart.java 文件:
/**
* 生产者
*/
public class ProducerStreamQuickStart {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1. kafka链接配置信息
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.200.130:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.ACKS_CONFIG, "all");
prop.put(ProducerConfig.RETRIES_CONFIG, 10);
prop.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
// 2. 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
// 3. 发送消息 流式处理
for (int i = 0; i < 5; i++) {
ProducerRecord<String, String> kvProducerRecord = new ProducerRecord<String, String>("itcast-topic-input", "hello kafka");
producer.send(kvProducerRecord);
}
// 4. 关闭消息通道(必须关闭,否则信息发送不成功)
producer.close();
}
}
2.5 消费者
编辑 heima-leadnews-test\kafka-demo\src\main\java\com\heima\kafka\sample\ConsumerQuickStart.javal 文件:
// 3. 订阅主题
//consumer.subscribe(Collections.singletonList("topic-first"));
// 流式计算
consumer.subscribe(Collections.singletonList("itcast-topic-out"));
2.6 测试
启动 ConsumerQuickStart(监听器)、 KafkaStreamQuickStart(流式处理),执行 ProducerStreamQuickStart(生产者) 方法:


3. SpringBoot集成
3.1 自定配置参数
新建 heima-leadnews-test\kafka-demo\src\main\java\com\heima\kafka\config\KafkaStreamConfig.java 文件:
/**
* 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数
*/
@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {
private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;
private String hosts;
private String group;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");
props.put(StreamsConfig.RETRIES_CONFIG, 10);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return new KafkaStreamsConfiguration(props);
}
}
3.2 自定义配置
编辑 heima-leadnews-test\kafka-demo\src\main\resources\application.yml 文件:
kafka:
hosts: 192.168.200.130:9092
group: ${spring.application.name}
3.3 配置类
新建 heima-leadnews-test\kafka-demo\src\main\java\com\heima\kafka\stream\KafkaStreamHelloListener.java 文件:
@Configuration
@Slf4j
public class KafkaStreamHelloListener {
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder) {
//创建kstream对象,同时指定从那个topic中接收消息
KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
})
//根据value进行聚合分组
.groupBy((key, value) -> value)
//聚合计算时间间隔
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
//求单词的个数
.count()
.toStream()
//处理后的结果转换为string字符串
.map((key, value) -> {
System.out.println("key:" + key + ",value:" + value);
return new KeyValue<>(key.key().toString(), value.toString());
})
//发送消息
.to("itcast-topic-out");
return stream;
}
}
3.4 测试
启动 ConsumerQuickStart(监听器)、 KafkaStreamHelloListener(启动类),执行 ProducerStreamQuickStart(生产者) 方法:

二、app端热点文章计算
1. 思路分析

2. 功能实现
(阅读量,评论,点赞,收藏)发送消息,以阅读和点赞为例
2.1 配置
2.1.1 集成kafka生产者配置
修改nacos leadnews-behavior:
spring:
application:
name: leadnews-behavior
kafka:
bootstrap-servers: 192.168.200.130:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
2.1.2 topic常量类
新建 heima-leadnews-common\src\main\java\com\heima\common\constants\BehaviorConstants.java 文件:
public class BehaviorConstants {
public static final String LIKE_BEHAVIOR="LIKE-BEHAVIOR-";
public static final String UN_LIKE_BEHAVIOR="UNLIKE-BEHAVIOR-";
public static final String COLLECTION_BEHAVIOR="COLLECTION-BEHAVIOR-";
public static final String READ_BEHAVIOR="READ-BEHAVIOR-";
public static final String APUSER_FOLLOW_RELATION="APUSER-FOLLOW-";
public static final String APUSER_FANS_RELATION="APUSER-FANS-";
}
2.2 发送消息
2.2.3 点赞
编辑 heima-leadnews-service\heima-leadnews-behavior\src\main\java\com\heima\behavior\service\impl\ApLikesBehaviorServiceImpl.java 文件:
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
...
UpdateArticleMess mess = new UpdateArticleMess();
mess.setArticleId(dto.getArticleId());
mess.setType(UpdateArticleMess.UpdateArticleType.LIKES);
//3.点赞 保存数据
...
//发送消息,数据聚合
kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(mess));
...
2.2.4 阅读
编辑 heima-leadnews-service\heima-leadnews-behavior\src\main\java\com\heima\behavior\service\impl\ApReadBehaviorServiceImpl.java 文件:
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
...
// 保存当前key
...
//发送消息,数据聚合
UpdateArticleMess mess = new UpdateArticleMess();
mess.setArticleId(dto.getArticleId());
mess.setType(UpdateArticleMess.UpdateArticleType.VIEWS);
mess.setAdd(1);
kafkaTemplate.send(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC,JSON.toJSONString(mess));
...
2.3 流式处理
2.3.1 聚合流式处理
新建 heima-leadnews-service\heima-leadnews-article\src\main\java\com\heima\article\stream\HotArticleStreamHandler.java 文件:
@Configuration
@Slf4j
public class HotArticleStreamHandler {
@Bean
public KStream<String,String> kStream(StreamsBuilder streamsBuilder){
//接收消息
KStream<String,String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);
//聚合流式处理
stream.map((key,value)->{
UpdateArticleMess mess = JSON.parseObject(value, UpdateArticleMess.class);
//重置消息的key:1234343434 和 value: likes:1
return new KeyValue<>(mess.getArticleId().toString(),mess.getType().name()+":"+mess.getAdd());
})
//按照文章id进行聚合
.groupBy((key,value)->key)
//时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
/**
* 自行的完成聚合的计算
*/
.aggregate(new Initializer<String>() {
/**
* 初始方法,返回值是消息的value
* @return
*/
@Override
public String apply() {
return "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";
}
/**
* 真正的聚合操作,返回值是消息的value
*/
}, new Aggregator<String, String, String>() {
@Override
public String apply(String key, String value, String aggValue) {
if(StringUtils.isBlank(value)){
return aggValue;
}
String[] aggAry = aggValue.split(",");
int col = 0,com=0,lik=0,vie=0;
for (String agg : aggAry) {
String[] split = agg.split(":");
/**
* 获得初始值,也是时间窗口内计算之后的值
*/
switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){
case COLLECTION:
col = Integer.parseInt(split[1]);
break;
case COMMENT:
com = Integer.parseInt(split[1]);
break;
case LIKES:
lik = Integer.parseInt(split[1]);
break;
case VIEWS:
vie = Integer.parseInt(split[1]);
break;
}
}
/**
* 累加操作
*/
String[] valAry = value.split(":");
switch (UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){
case COLLECTION:
col += Integer.parseInt(valAry[1]);
break;
case COMMENT:
com += Integer.parseInt(valAry[1]);
break;
case LIKES:
lik += Integer.parseInt(valAry[1]);
break;
case VIEWS:
vie += Integer.parseInt(valAry[1]);
break;
}
String formatStr = String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);
System.out.println("文章的id:"+key);
System.out.println("当前时间窗口内的消息处理结果:"+formatStr);
return formatStr;
}
}, Materialized.as("hot-atricle-stream-count-001"))
.toStream()
.map((key,value)->{
return new KeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));
})
//发送消息
.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);
return stream;
}
}
2.3.2 格式化消息
新建 heima-leadnews-model\src\main\java\com\heima\model\mess\ArticleVisitStreamMess.java 文件:
@Data
public class ArticleVisitStreamMess {
/**
* 文章id
*/
private Long articleId;
/**
* 阅读
*/
private int view;
/**
* 收藏
*/
private int collect;
/**
* 评论
*/
private int comment;
/**
* 点赞
*/
private int like;
}
编辑 heima-leadnews-service\heima-leadnews-article\src\main\java\com\heima\article\stream\HotArticleStreamHandler.java 文件:
/**
* 格式化消息的value数据
* @param articleId
* @param value
* @return
*/
public String formatObj(String articleId,String value){
ArticleVisitStreamMess mess = new ArticleVisitStreamMess();
mess.setArticleId(Long.valueOf(articleId));
//COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0
String[] valAry = value.split(",");
for (String val : valAry) {
String[] split = val.split(":");
switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){
case COLLECTION:
mess.setCollect(Integer.parseInt(split[1]));
break;
case COMMENT:
mess.setComment(Integer.parseInt(split[1]));
break;
case LIKES:
mess.setLike(Integer.parseInt(split[1]));
break;
case VIEWS:
mess.setView(Integer.parseInt(split[1]));
break;
}
}
log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));
return JSON.toJSONString(mess);
}
2.4 测试
启动 ArticleApplication、 BehaviorApplication、 UserApplication、 AppGatewayApplication 微服务,以及 nginx,查看App端首页文章列表 http://localhost:8801:

开启两个浏览器,不同用户对同一文章取消点赞:

2.5 监听器
新建 heima-leadnews-service\heima-leadnews-article\src\main\java\com\heima\article\listener\ArticleIncrHandleListener.java 文件:
@Component
@Slf4j
public class ArticleIncrHandleListener {
@Autowired
private ApArticleService apArticleService;
@KafkaListener(topics = HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC)
public void onMessage(String mess){
if(StringUtils.isNotBlank(mess)){
System.out.println(mess);
}
}
}
2.6 更新文章分值
新建 heima-leadnews-model\src\main\java\com\heima\model\mess\ArticleVisitStreamMess.java 文件:
@Data
public class ArticleVisitStreamMess {
/**
* 文章id
*/
private Long articleId;
/**
* 阅读
*/
private int view;
/**
* 收藏
*/
private int collect;
/**
* 评论
*/
private int comment;
/**
* 点赞
*/
private int like;
}
编辑 heima-leadnews-service\heima-leadnews-article\src\main\java\com\heima\article\service\ApArticleService.java 文件:
/**
* 更新文章分值, 同时更新缓存中的热点文章数据
* @param mess
*/
public void updateScore(ArticleVisitStreamMess mess);
编辑 heima-leadnews-service\heima-leadnews-article\src\main\java\com\heima\article\service\impl\ApArticleServiceImpl.java 文件:
/**
* 更新文章分值, 同时更新缓存中的热点文章数据
* @param mess
*/
@Override
public void updateScore(ArticleVisitStreamMess mess) {
//1.更新文章的阅读、点赞、收藏、评论的数量
ApArticle apArticle = updateArticle(mess);
//2.计算文章的分值
Integer score = computeScore(apArticle);
score = score * 3;
//3.替换当前文章对应频道的热点数据
replaceDataToRedis(apArticle, score, ArticleConstants.HOT_ARTICLE_FIRST_PAGE + apArticle.getChannelId());
//4.替换推荐对应的热点数据
replaceDataToRedis(apArticle, score, ArticleConstants.HOT_ARTICLE_FIRST_PAGE + ArticleConstants.DEFAULT_TAG);
}
/**
* 替换数据并且存入到redis
* @param apArticle
* @param score
* @param s
*/
private void replaceDataToRedis(ApArticle apArticle, Integer score, String s) {
String articleListStr = cacheService.get(s);
if (StringUtils.isNotBlank(articleListStr)) {
List<HotArticleVo> hotArticleVoList = JSON.parseArray(articleListStr, HotArticleVo.class);
boolean flag = true;
//如果缓存中存在该文章,只更新分值
for (HotArticleVo hotArticleVo : hotArticleVoList) {
if (hotArticleVo.getId().equals(apArticle.getId())) {
hotArticleVo.setScore(score);
flag = false;
break;
}
}
//如果缓存中不存在,查询缓存中分值最小的一条数据,进行分值的比较,如果当前文章的分值大于缓存中的数据,就替换
if (flag) {
if (hotArticleVoList.size() >= 30) {
hotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());
HotArticleVo lastHot = hotArticleVoList.get(hotArticleVoList.size() - 1);
if (lastHot.getScore() < score) {
hotArticleVoList.remove(lastHot);
HotArticleVo hot = new HotArticleVo();
BeanUtils.copyProperties(apArticle, hot);
hot.setScore(score);
hotArticleVoList.add(hot);
}
} else {
HotArticleVo hot = new HotArticleVo();
BeanUtils.copyProperties(apArticle, hot);
hot.setScore(score);
hotArticleVoList.add(hot);
}
}
//缓存到redis
hotArticleVoList = hotArticleVoList.stream().sorted(Comparator.comparing(HotArticleVo::getScore).reversed()).collect(Collectors.toList());
cacheService.set(s, JSON.toJSONString(hotArticleVoList));
}
}
/**
* 更新文章行为数量
* @param mess
*/
private ApArticle updateArticle(ArticleVisitStreamMess mess) {
ApArticle apArticle = getById(mess.getArticleId());
apArticle.setCollection(apArticle.getCollection()==null?0:apArticle.getCollection()+mess.getCollect());
apArticle.setComment(apArticle.getComment()==null?0:apArticle.getComment()+mess.getComment());
apArticle.setLikes(apArticle.getLikes()==null?0:apArticle.getLikes()+mess.getLike());
apArticle.setViews(apArticle.getViews()==null?0:apArticle.getViews()+mess.getView());
updateById(apArticle);
return apArticle;
}
/**
* 计算文章的具体分值
* @param apArticle
* @return
*/
private Integer computeScore(ApArticle apArticle) {
Integer score = 0;
if(apArticle.getLikes() != null){
score += apArticle.getLikes() * ArticleConstants.HOT_ARTICLE_LIKE_WEIGHT;
}
if(apArticle.getViews() != null){
score += apArticle.getViews();
}
if(apArticle.getComment() != null){
score += apArticle.getComment() * ArticleConstants.HOT_ARTICLE_COMMENT_WEIGHT;
}
if(apArticle.getCollection() != null){
score += apArticle.getCollection() * ArticleConstants.HOT_ARTICLE_COLLECTION_WEIGHT;
}
return score;
}
2.7 综合测试
启动 ArticleApplication、 BehaviorApplication、 UserApplication、 AppGatewayApplication 微服务,以及 nginx,查看App端首页文章列表 http://localhost:8801: