文章目录
- 数据源是什么
- 一、spring中是如何处理各种数据源的?
- 1.开搞springboot
- 2.创建一个测试类
- 二、有了如上的理论,那么想想动态切换数据源吧
- 参考若依的动态数据源配置
- 总结
数据源是什么
数据源,对于java来说,就是可用的数据库,那么我平时开发的springboot springcloud项目,那么也就是yml或者properties中的链接信息, 例如 mysql redis influx mongodb sqlserver clickhouse nebula-graph …
一般在spring中,都已经对其做好了封装
一、spring中是如何处理各种数据源的?
那就不得不说下JdbcTemplate 了,只要是各种遵循了jdbc标准的数据源,也就是大部分的关系型数据库,都是可以通过它来操作的;简直就是神奇~~ 怎么使用呢?
1.开搞springboot
搞一个springboot项目 由于我使用了mysql,所以还引入了mysql驱动包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
然后在yml加入相应配置
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://xxxxx:3307/yuque
username: root
password: 123456
2.创建一个测试类
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.DEFINED_PORT)
class WordApplicationTests1 {
@Test
void contextLoads() {
}
@Autowired
JdbcTemplate jdbcTemplate;
@SneakyThrows
@Test
public void query() {
List<Bom> bomList = jdbcTemplate.query("select DISTINCT * from bom", new BeanPropertyRowMapper<>(Bom.class));
System.out.println(JSONUtil.toJsonStr(bomList));
}
}
相当于可以了,用的就是yml中的配置查询的数据库
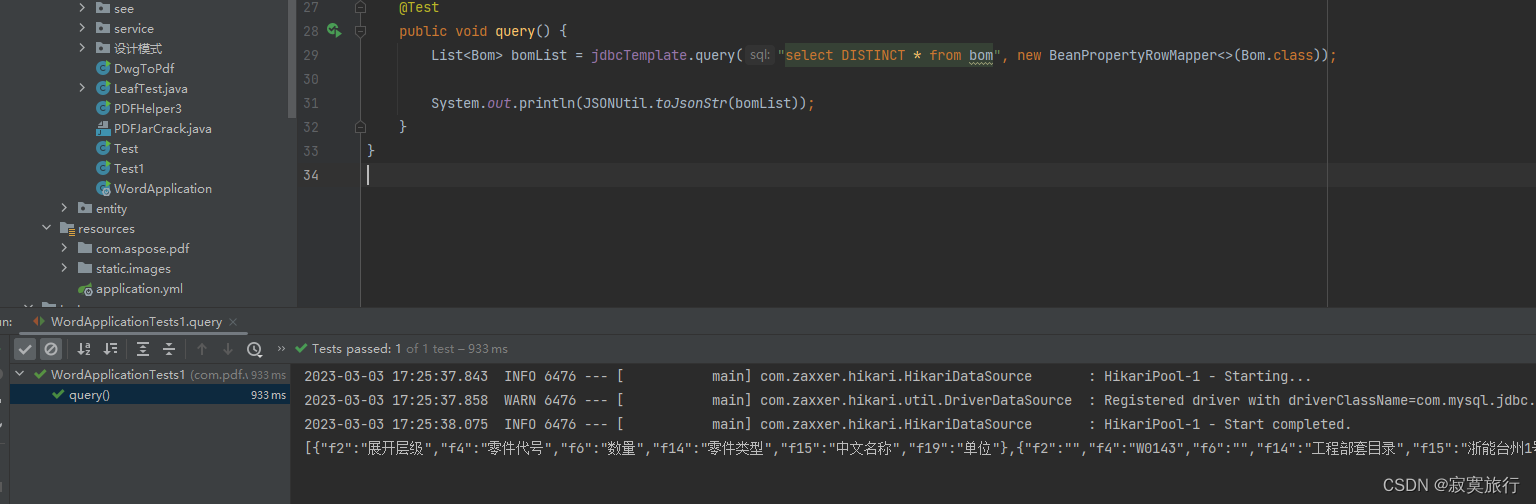
- 我有一个想法,我想查询一个其他的库的数据,但是之前的yml中的我还想用
改造后,变成了
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.DEFINED_PORT)
class WordApplicationTests1 {
@Test
void contextLoads() {
}
@Autowired
JdbcTemplate jdbcTemplate;
@SneakyThrows
@Test
public void query() {
List<Bom> bomList = jdbcTemplate.query("select DISTINCT * from bom", new BeanPropertyRowMapper<>(Bom.class));
System.out.println(JSONUtil.toJsonStr(bomList));
Properties properties = new Properties();
properties.put("url", "jdbc:mysql://localhost:3306/test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true");
properties.put("username", "root");
properties.put("driverClassName", "com.mysql.jdbc.Driver");
properties.put("password", "root");
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
JdbcTemplate template = new JdbcTemplate(dataSource);
List<Bom> list = template.query("select * from bom", new BeanPropertyRowMapper<>(Bom.class));
System.out.println(JSONUtil.toJsonStr(list));
}
}
还是能用的,两个都能查询出数据
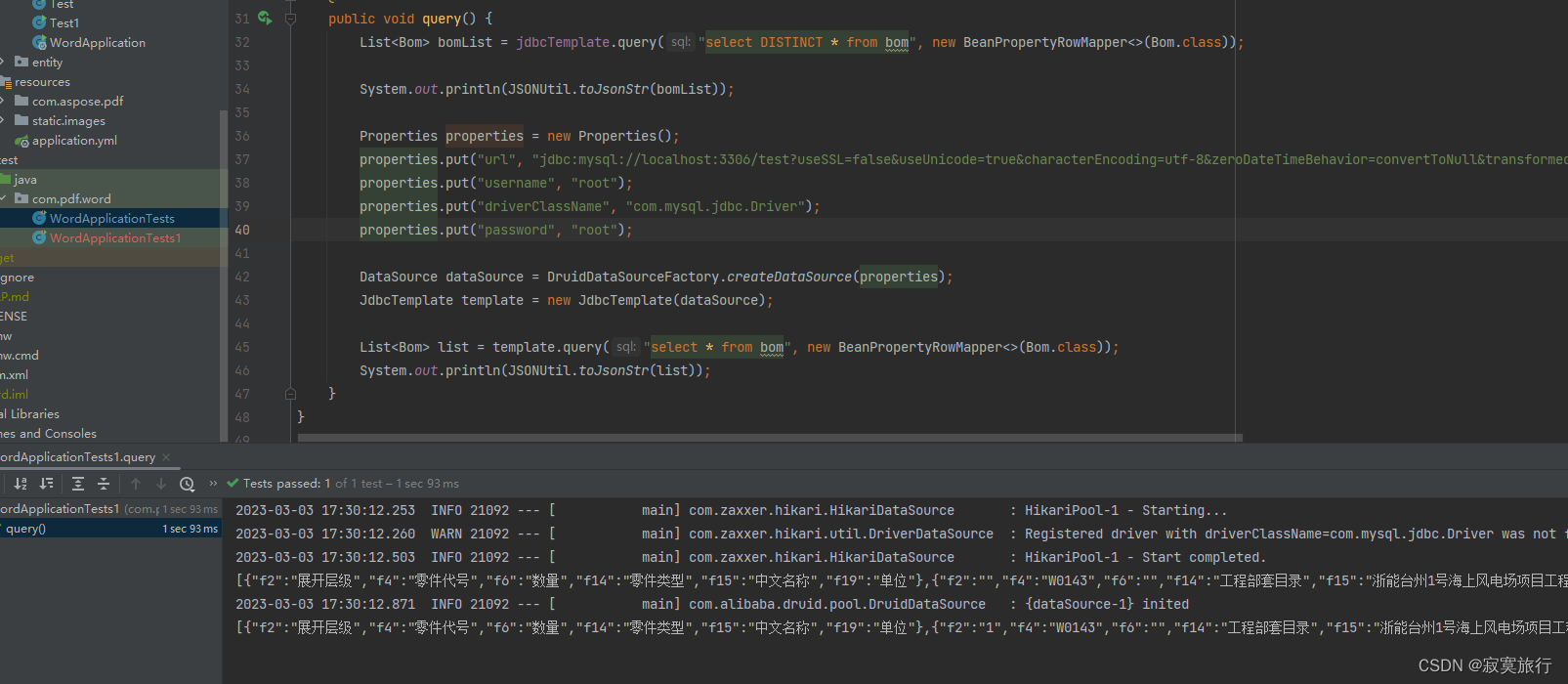
那…请小伙伴思考下,如果是用jdbc弄一个动态数据源,是不是也不是很难,我需要用哪个库的信息,就让他加载哪个库的配置信息就ok了呀.对吧?
甚至,我可以将配置信息放入数据库中,启动后,一次性加载到内存,并实例化相应的datasource 实例,然后在实例化相应的jdbctemplete,放入到的全局中,那么我就可以自如切换了!!!
二、有了如上的理论,那么想想动态切换数据源吧
参考若依的动态数据源配置
若依
大体思路如下:
- 首先利用本地线程搞一个缓存,目的是为了存放当前可用的数据源,这样就可以设置/移除 某个数据源了;
DynamicDataSourceContextHolder 仅仅是个缓存
- 由于为了使用方便,所以他自定义了注解,用来切换数据源,也就是更改上面的当前线程缓存,那么自定义之后,就需要通过切面去实现这个自定义的注解,里面的中心思想就是获取传入的可用数据源(可能有多个),替换之为当前数据源(只能有一个);
DataSourceAspect 切面实现切换
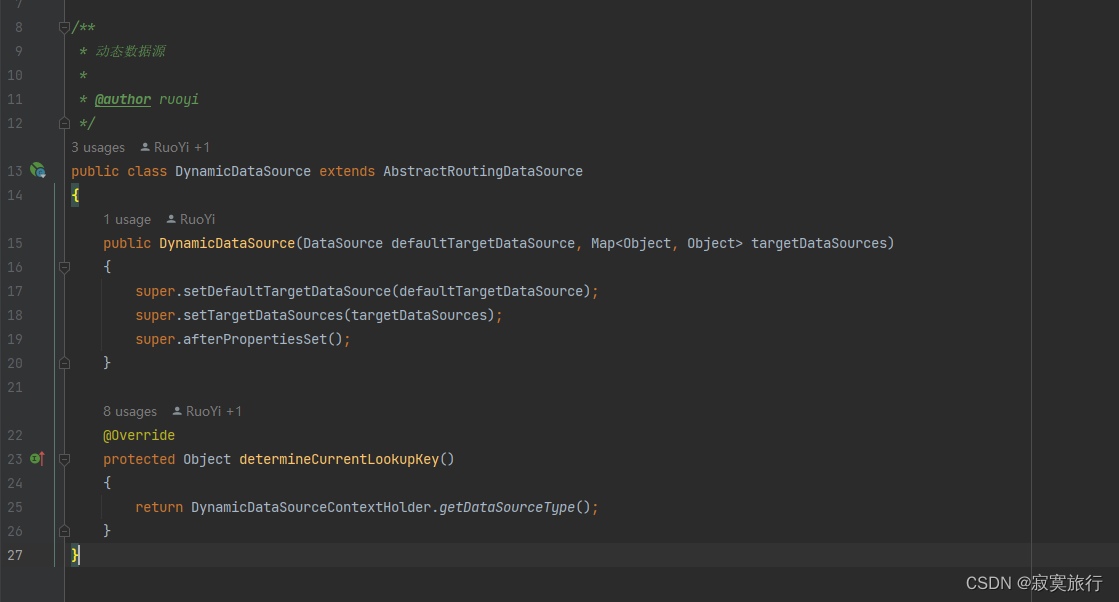
- 那么多个数据源是从哪里来的呢,是在项目启动的时候,他就已经把可用数据源都实例化好了,然后存放起来了,就像我之前分析的那样,关键点就是 实现这个方法 AbstractRoutingDataSource 其中 放入一个map 就是数据源本尊了
DruidConfig 把所有数据源都加载进去了
- 之后就可以通过map.getkey 那样,获取到自己想要的数据源了;然后更改本地线程的数据源
- 切换之后,查询的时候,就会重新查询到当前设置后的数据源,然后再去查询
重点中的重点
DynamicDataSource extends AbstractRoutingDataSource
@Override
protected Object determineCurrentLookupKey(){
return DynamicDataSourceContextHolder.getDataSourceType();// 每次执行都会重新获取新值
}
总结
通过此次JdbcTemplate 的数据源切换,想到了之前看过的若依项目中的多数据源切换问题,这次带着我自己的想法去看,果然再次阅读,收获颇丰;算是彻底看懂了吧;
希望我的理解能为你带来启发




![[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程](https://img-blog.csdnimg.cn/img_convert/803b59e25db6790514020005607041aa.png)