今天要说到的查询情况,平时项目里边其实用到的并不是很多,使用正则表达式无非是为了匹配结果比较灵活,最常见的,我们的查询条件一般一个参数仅仅只是一种情况的筛选,对于如何选择查询方式,主要还是要看前端传递的查询条件格式,比如单参数只表示单个值,而且数据表对应也是单个值,这种最简单,精确匹配的话,就直接where 字段=参数值,如果模糊查询,就使用like匹配,如果前端传递的某个参数,值是用逗号分割的一个字符串,实际上可以看做是多个匹配条件,而数据表中,对应的字段值是单个值的话,可以where find_in_set(字段,字符串参数值)或者将分割的字符串转换成List,然后用in匹配
还有一种就是前端传递的参数值是逗号分割的字符串,对应要查询匹配的字段,数据表中存的也是以逗号分割的字符串,查询的时候,一般是或关系,就需要从表中查询出只要包含查询条件中的其中一个值的匹配结果
举例来说吧,比如昨天一个需求是需要根据标签id来查询只要含有这些标签中其中给一个标签的企业。
先看swagger文档:

这是一个get请求方式的分页查询,重点就是下边那个tagIdList参数,前端传递的是 一个逗号分割的id字符串,是两个标签,而企业也是多标签的,现在从企业中查询出有这两个标签的企业(其实就是或的关系)
接下来看mybatis xml中的sql写法吧
<select id="pageList" resultType="com.xiaomifeng1010.response.vo.EtpSrvcListedCltvtnVO">
select
cltvtn.id,
SUBSTRING_INDEX(cltvtn.state_record,',',-1) as state,
cltvtn.name,
(select name from sys_dict where code = cltvtn.nature) as nature,
(select name from sys_dict where code = cltvtn.register_region) as register_region,
(select name from sys_dict where code = cltvtn.industry) as industry,
cltvtn.uscc,
cltvtn.master_data_id,
cltvtn.wr_tech_type_mid_small_etp,
cltvtn.wr_high_new_tech_industry,
group_concat(distinct tag.tag_name) as tag_names
from
etp_srvc_listed_cltvtn cltvtn
join enterprise_info info
on cltvtn.uscc=info.uscc
left join enterprise_tag_mid mid on info.id=mid.enterprise_id
left join enterprise_tag tag on mid.tag_id=tag.id
where cltvtn.del_flag = 0
<if test="param.name != null and param.name != ''">
and cltvtn.name like concat('%',#{param.name},'%')
</if>
<if test="param.uscc != null and param.uscc != ''">
and cltvtn.uscc like concat('%',#{param.uscc},'%')
</if>
<if test="param.nature != null">
and cltvtn.nature = #{param.nature}
</if>
<if test="param.registerRegion != null and param.registerRegion != ''">
and cltvtn.register_region = #{param.registerRegion}
</if>
<if test="param.state!=null">
and SUBSTRING_INDEX(cltvtn.state_record,',',-1)=#{param.state,jdbcType=INTEGER}
</if>
group by cltvtn.name,cltvtn.uscc
<if test="param.tagIdList != null and param.tagIdList.size() != 0">
HAVING group_concat(distinct tag.id) REGEXP
replace(<foreach collection="param.tagIdList" item="tagId" separator="|" open="concat("
close=")">
#{tagId,jdbcType=BIGINT}
</foreach>,' ','')
</if>
<if test="param.sort != '' and param.sort != null">
order by ${param.sort}
</if>
<if test="param.sort == '' or param.sort == null">
order by cltvtn.create_time desc
</if>
</select>要匹配标签或关系:

我一开始是这样写的,为什么这样写的,因为以前我使用Integer类型的枚举值List时候这样用是可以正常匹配的,所以Id值是Long类型的依然这样用,但是结果查询结果出乎我的预料,当我选择单个标签或者不选标签的时候,是可以正常查询结果的,但是当我选择的是两个标签时候,奇怪的事情就发生了,居然一条结果都没有了!像下边这样:


我选单个标签的时候,是可以查询出231条结果的
但是当我选择两个标签的时候,居然一条结果都没有:


正常情况下,foreach拼接的tagId,拼接好,完整的sql应该是这样的:

我在navicat中直接执行这个语句是可以正常查询到结果的,但是在程序中就是没有查询结果,所以我又去试了一下测试环境,并查看日志,并且我把#{tagId}换成了${tagId}方便直接打印sql的时候直接带上参数,而不是占位符,看到的日志信息就是这样的:
 可以看到使用concat拼接的正则表达式每个id以及‘|’符号之间都加上了空格,应该是mybatis加上的,所以为了去掉空格,所以我又加上了replace函数,然后在本地测试,结果本地可以查询出来一些结果了,但是结果却是只有匹配第二个标签的结果,好家伙,replace没有替换掉‘|’符号前边那个id的空格?然后发到测试环境,结果测试环境,还是查不到结果,就非常诡异,正常情况下replace是可以替换掉字符串中所有空格的,在Navicat中运行也是正常的:
可以看到使用concat拼接的正则表达式每个id以及‘|’符号之间都加上了空格,应该是mybatis加上的,所以为了去掉空格,所以我又加上了replace函数,然后在本地测试,结果本地可以查询出来一些结果了,但是结果却是只有匹配第二个标签的结果,好家伙,replace没有替换掉‘|’符号前边那个id的空格?然后发到测试环境,结果测试环境,还是查不到结果,就非常诡异,正常情况下replace是可以替换掉字符串中所有空格的,在Navicat中运行也是正常的:
 既然mybatis会改变最终的拼接结果,那么索性不用mybatis来拼接了,解决方案是使用ognl表达式,直接用java的api就可以了,所以最终改写成了:
既然mybatis会改变最终的拼接结果,那么索性不用mybatis来拼接了,解决方案是使用ognl表达式,直接用java的api就可以了,所以最终改写成了:
<select id="pageList" resultType="com.xiaomifeng1010.response.vo.EtpSrvcListedCltvtnVO">
select
cltvtn.id,
SUBSTRING_INDEX(cltvtn.state_record,',',-1) as state,
cltvtn.name,
(select name from sys_dict where code = cltvtn.nature) as nature,
(select name from sys_dict where code = cltvtn.register_region) as register_region,
(select name from sys_dict where code = cltvtn.industry) as industry,
cltvtn.uscc,
cltvtn.master_data_id,
cltvtn.wr_tech_type_mid_small_etp,
cltvtn.wr_high_new_tech_industry,
group_concat(distinct tag.tag_name) as tag_names
from
etp_srvc_listed_cltvtn cltvtn
join enterprise_info info
on cltvtn.uscc=info.uscc
left join enterprise_tag_mid mid on info.id=mid.enterprise_id
left join enterprise_tag tag on mid.tag_id=tag.id
where cltvtn.del_flag = 0
<if test="param.name != null and param.name != ''">
and cltvtn.name like concat('%',#{param.name},'%')
</if>
<if test="param.uscc != null and param.uscc != ''">
and cltvtn.uscc like concat('%',#{param.uscc},'%')
</if>
<if test="param.nature != null">
and cltvtn.nature = #{param.nature}
</if>
<if test="param.registerRegion != null and param.registerRegion != ''">
and cltvtn.register_region = #{param.registerRegion}
</if>
<if test="param.state!=null">
and SUBSTRING_INDEX(cltvtn.state_record,',',-1)=#{param.state,jdbcType=INTEGER}
</if>
group by cltvtn.name,cltvtn.uscc
<if test="param.tagIdList != null and param.tagIdList.size() != 0">
<bind name="joiner" value="@com.google.common.base.Joiner@on('|')"/>
<bind name="tagIds" value="joiner.join(param.tagIdList)"/>
HAVING group_concat(distinct tag.id) REGEXP
#{tagIds}
</if>
<if test="param.sort != '' and param.sort != null">
order by ${param.sort}
</if>
<if test="param.sort == '' or param.sort == null">
order by cltvtn.create_time desc
</if>
</select>然后再到swagger文档中测试,就可以正常查询到准确的结果条数了:

但是如果是Integer类型的枚举值列表,使用foreach来拼接正则表达式,目前测试是可以正常查询的,比如另外一个查询场景:之前的一个业务,在新增金融政策的时候, 政策类型下拉选只能单选,所以设计的数据表字段直接是枚举int类型,1,2,3来存储的,后来要求这个字段可以下拉多选,所以就改成了字符串类型,多选的时候,传递过来的参数值就类似‘1,2,3’这样逗号拼接的字符串存储到该字段中,同时查询也由单选改成了多选:
政策类型下拉选只能单选,所以设计的数据表字段直接是枚举int类型,1,2,3来存储的,后来要求这个字段可以下拉多选,所以就改成了字符串类型,多选的时候,传递过来的参数值就类似‘1,2,3’这样逗号拼接的字符串存储到该字段中,同时查询也由单选改成了多选:
所以查询也要改写成这样:
<select id="pageList" resultType="com.xiaomifeng1010.response.vo.FinancePolicyVO">
select
fp.id,
fp.title,
fp.publish_date,
fp.content,
fp.publish_office,
fp.written_date,
fp.type
from finance_policy fp
where fp.del_flag = 0
<if test="param.title != '' and param.title != null">
and fp.title like concat('%',#{param.title},'%')
</if>
<if test="param.supportType != '' and param.supportType != null">
and fp.support_type like concat('%',#{param.supportType},'%')
</if>
<if test="param.supportMode != '' and param.supportMode != null">
and fp.support_mode like concat('%',#{param.supportMode},'%')
</if>
<if test="@org.apache.commons.lang3.StringUtils@isNotBlank(param.type)">
and fp.type like concat('%',#{param.type},'%')
</if>
<if test="@org.apache.commons.collections4.CollectionUtils@isNotEmpty(param.typeList)">
and fp.type REGEXP
<foreach collection="param.typeList" open="concat(" item="type" close=")" separator="|">
#{type,jdbcType=INTEGER}
</foreach>
</if>
<if test="param.dateRange != null">
and fp.publish_date >= subdate(CURRENT_DATE,#{param.dateRange})
</if>
<if test="param.sort != '' and param.sort != null">
order by ${param.sort}
</if>
<if test="param.sort == '' or param.sort == null">
order by fp.publish_date desc
</if>
</select>
注意这里拼接的是integer类型的值:

没有出现查询不到结果的情况,当前端选择两种政策类型时,只要包含这两种类型的一种都会查询出来:
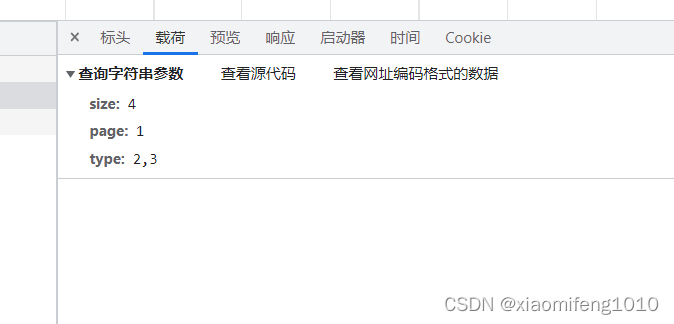

可以看到type是2或者3的都可以查出来,以及同时是2,3的也可以查出来
最后再说明一下其他注意事项:
如果要在foreach中使用#{item}的形式,那么open和close的值不能直接是单引号,因为#参数值两边不能直接是单引号,open值可以是concat(,close的值是)这样的,如果要用单引号也不是不可以,将#换成$就可以了
另外还有一种就是匹配英文字符串或者中文的那种情况,比如查询某字段包含某个编码或另一个编码,以及某字段是否包含某段文字或其他文字之类的,也可以使用全文索引,需要对查询字段创建全文索引,并且查询语句使用match against形式查询语句,具体的匹配模式可以查询相关资料
不过全文索引创建的字段,只对新添加或更新的行数据生效,也就是说即使旧数据满足匹配条件也查询不出来,所以可以做全表更新或者旧数据清除处理之后,再用全文索引匹配

![[媒体分流直播]媒体直播和传统直播的区别,以及媒体直播的特点](https://img-blog.csdnimg.cn/e2d0bf206aba43c28b8dec38fc23e62d.png)











![3.crypto-config.yaml配置文件分析和cryptogen工具使用[fabric2.2]](https://img-blog.csdnimg.cn/632b626448e6412c8a6e2f3bd6929bae.png)