上周三,TDengine 正式发布了基于 TSBS 的时序数据库(Time Series Database,TSDB)性能基准测试报告,该报告采用 TSBS 平台中针对 DevOps 的场景作为基础数据集,在相同的 AWS 云环境下对 TDengine 3.0、TimescaleDB 2.6 和 InfluxDB 1.8 进行了对比分析。为了便于大家更好地阅读和理解,基于报告内容,我们将从写入、查询及测试过程如何复现等几大维度输出系列文章。本篇文章将为大家解读三大时序数据库在写入性能上的差异点。
在《TSBS 是什么?为什么 TDengine 会选择它作为性能对比测试平台?》一文中,我们对测试场景和基本配置已经进行了详细介绍,本篇文章便不再赘述,还没有了解过的小伙伴可以点击上文链接查看。
五大场景下,TDengine 写入性能实现全面超越
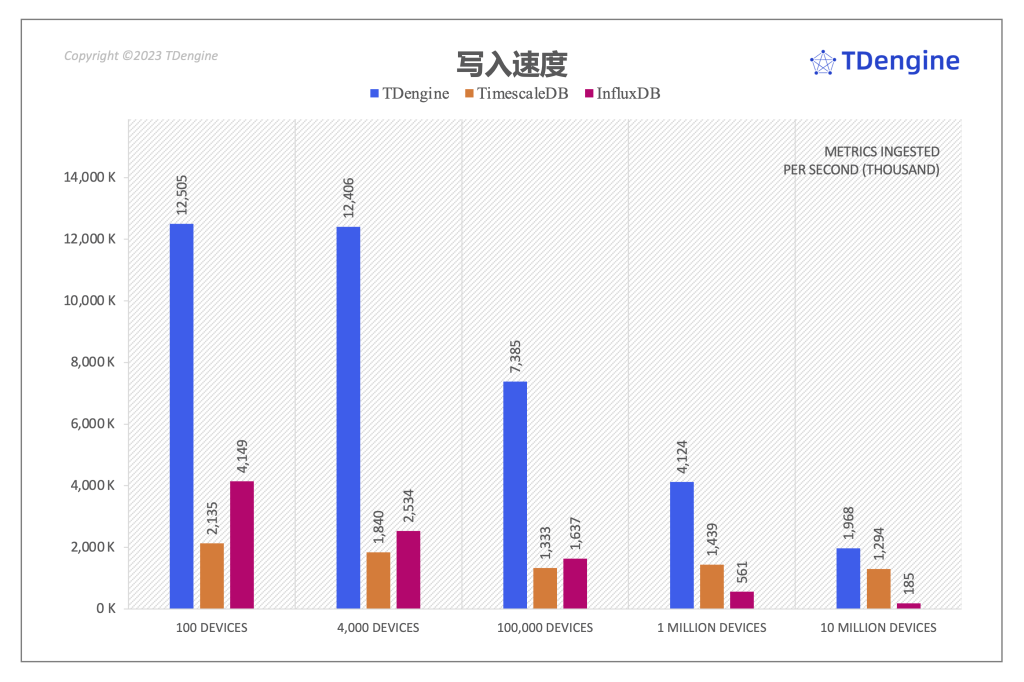
不同场景下写入性能的对比(metrics/sec. 数值越大越好)
如上图所示,我们可以看到在全部五个场景中,TDengine 的写入性能全面超越了 TimescaleDB 和 InfluxDB。在场景二中 TDengine 写入性能最大达到了 TimescaleDB 的 6.74 倍,在差距最小的场景五中,TDengine 也是 TimescaleDB 的 1.52 倍。相比 InfluxDB,TDengine 在场景五中写入性能达到 InfluxDB 的 10.63 倍,在差距最小的场景一中也有 3.01 倍,具体的倍率关系请参见下表。
TDengine/InfluxDB | TDengine/TimescaleDB | |
100 devices × 10 metrics | 301.41% | 585.63% |
4,000 devices × 10 metrics | 489.69% | 674.12% |
100,000 devices × 10 metrics | 451.25% | 554.07% |
1,000,000 devices × 10 metrics | 735.38% | 286.46% |
10,000,000 devices × 10 metrics | 1063.46% | 152.16% |
TDengine 与 InfluxDB、TimescaleDB 的写入性能对比
此外,我们还注意到,随着设备数规模的增加,所有系统写入基本上呈现下降趋势。TimescaleDB 在小规模数据情况下写入性能不及 InfluxDB,但是随着设备数量的增加,其写入性能超过了 InfluxDB。
在数据完全落盘后,我们又比较了一下三个系统在不同场景下的磁盘空间占用情况。
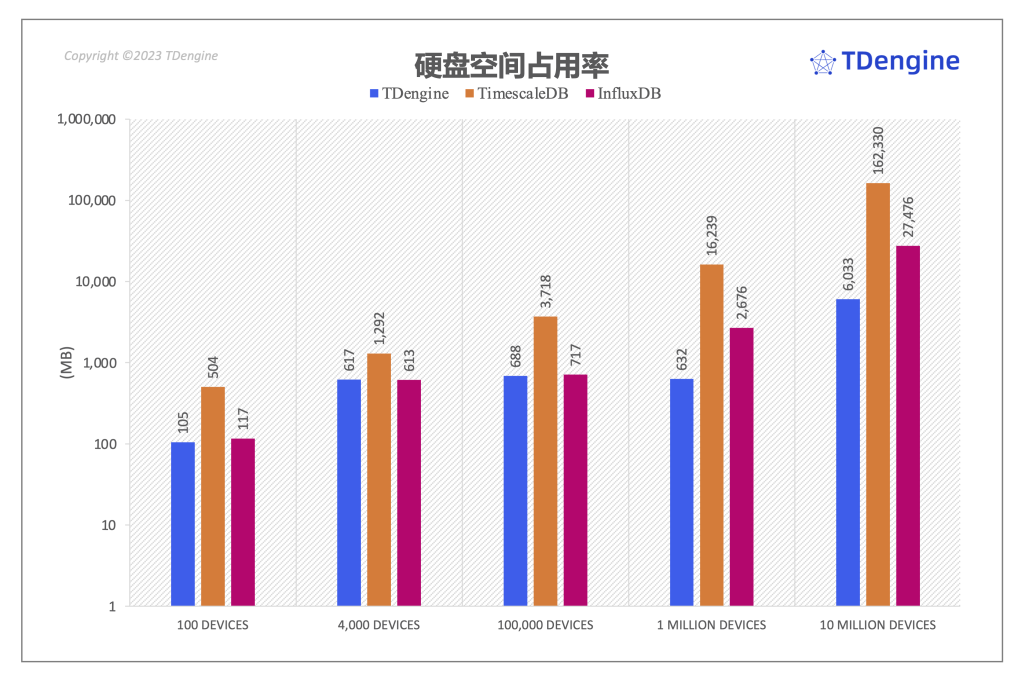
磁盘空间占用(数值越小越优)
可以看到,TimescaleDB 在所有的场景下数据规模均显著地大于 InfluxDB 和 TDengine,并且这种差距随着数据规模增加快速变大——TimescaleDB 在场景四和场景五中占用磁盘空间是 TDengine 的 25 倍。在前面三个场景中,InfluxDB 落盘后数据文件规模与 TDengine 非常接近(在场景二中,TDengine 的数据落盘规模比 InfluxDB 大了 1%),但是在场景四/五两个场景中,InfluxDB 落盘后文件占用的磁盘空间却达到了 TDengine 的 4 倍以上。
写入过程资源消耗对比,InfluxDB>TimescaleDB>TDengine
仅凭数据写入速度,并不能全面地反映出三个系统在不同场景下数据写入的整体表现。为此我们以 1,000,000 devices × 10 metrics(场景四)为数据模板,检查三大数据库在数据写入过程中服务器和客户端的整体负载状况,并以此来对比它们在写入过程中服务器/客户端节点的资源占用情况。这里的资源占用主要包括服务器端的 CPU 开销/磁盘 IO 开销和客户端 CPU 开销。
服务端 CPU 开销
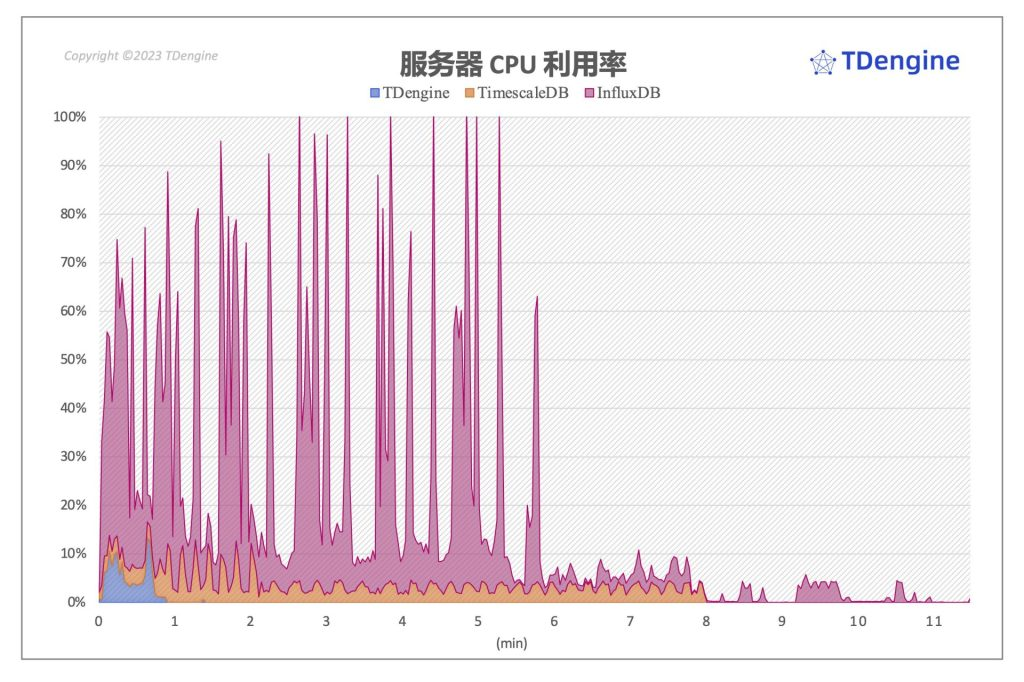
写入过程中服务器 CPU 开销
上图直观地展示出了三大系统在场景四写入过程中的服务器端 CPU 负载状况,在图中我们使用虚线标识出了服务端给客户端确认写入完成的时刻。可以看到,三个系统在返回给客户端写入完成消息以后,都还继续使用服务器资源进行相应的处理工作,这点上,TimescaleDB 尤为明显——TimescaleDB 在 7x 秒时即反馈客户端写入完成,但是其服务器端仍然再调用 CPU 资源进行数据压缩和整理工作,当然整个工作带来的 CPU 负载相对而言并不高,只有其峰值 CPU 开销的一半左右,但是持续时间相当长,接近净写入时间的 4 倍。
InfluxDB 则在写入过程中使用了相当多的 CPU 资源,瞬时峰值甚至使用了全部的 CPU 资源,其写入负载较高,并且持续时间比 TimescaleDB 更长,当然也远长于 TDengine。三个系统对比,TDengine 对服务器的 CPU 需求最小,峰值也仅使用了 17% 左右的服务器 CPU 资源。由此可见,TDengine 独特的数据模型不仅体现在时序数据写入的性能上,在整体的资源开销上优势也极为明显。
磁盘 I/O 对比

写入过程中服务器 IO 开销
图五展示了场景四下数据写入过程中服务器端磁盘 IO 趋势。可以看到,结合着服务器端 CPU 的开销表现,三大系统的 IO 动作与 CPU 呈现同步的活跃状态。写入相同规模的数据集下,TDengine 在写入过程中对于磁盘写入能力的占用远小于 TimescaleDB 和 InfluxDB,写入过程只占用了部分磁盘写入能力(125MiB/Sec. 3000IOPS)。从图上能看到,数据写入过程中磁盘的 IO 瓶颈是确实存在的——InfluxDB 运行中有相当长一段时间将全部的磁盘写入能力消耗殆尽,TimescaleDB 对于写入能力的消耗相对 InfluxDB 来说要更具优势,但是仍然远超过了 TDengine。
客户端 CPU 开销
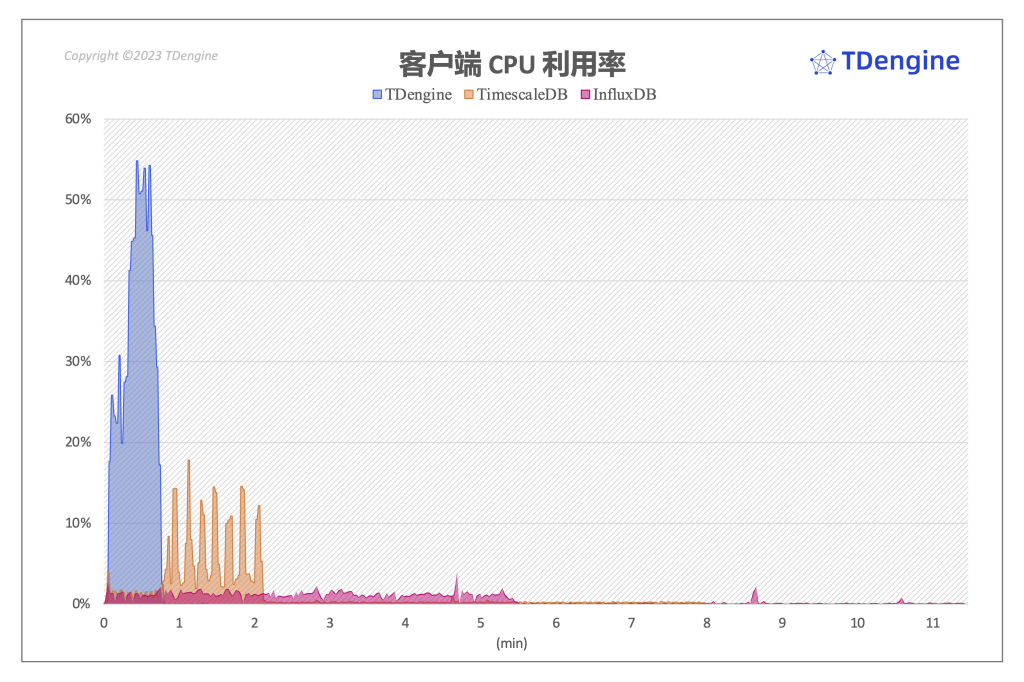
写入过程中客户端 CPU 开销
从上图可以看到,三个系统在服务器确认写入完成以后客户端均不再有 CPU 开销。客户端上 TDengine 对 CPU 的需求大于 TimescaleDB 和 InfluxDB,而 InfluxDB 在整个写入过程中,客户端负载整体上来说是三个系统中计算资源占用最低的,对客户端压力也是三者中最小的,其写入的压力基本上完全集中在服务端,这种模式很容易导致服务端发生瓶颈。
再看 TimescaleDB,对于客户端压力比 InfluxDB 要更大,CPU 峰值达到 17% 左右。而 TDengine 在客户端的开销最大,峰值瞬间达到了 56%,然后快速回落。虽然 TDengine 在客户端的开销相比于 TimescaleDB 多了 1 倍,但其写入持续时间更短,综合服务器与客户端的资源开销来看,在系统整体 CPU 开销上 TDengine 仍然具有相当大的优势。
写入性能基准评估扩展部分
为了更全面地评估 TDengine 在默认参数下的写入性能,我们在下面的性能评估中对可能会影响写入性能的多个参数进行了调整,以便开展更全面的评估工作。
虚拟节点(vnodes)数量
我们调整数据库中虚拟节点数量(默认是 6)为 6、8、12、24,并衡量不同 vnode 数量情况下 TDengine 的写入性能。
虚拟节点数量 | 6 | 8 | 12 | 24 |
100 devices × 10 metrics | 13,694,875 | 13,780,359 | 13,569,666 | 13,429,903 |
(vnodes = 6) / (vnodes = #p) | 100.00% | 100.62% | 99.09% | 98.07% |
4,000 devices × 10 metrics | 11,604,459 | 11,592,558 | 11,565,546 | 11,637,392 |
(vnodes = 6) / (vnodes = #p) | 100.00% | 99.90% | 99.66% | 100.28% |
100,000 devices × 10 metrics | 5,339,835 | 5,296,044 | 5,296,268 | 5,397,590 |
(vnodes = 6) / (vnodes = #p) | 100.00% | 99.18% | 99.18% | 101.08% |
1,000,000 devices × 10 metrics | 3,367,111 | 3,351,568 | 3,360,974 | 3,334,824 |
(vnodes = 6) / (vnodes = #p) | 100.00% | 99.54% | 99.82% | 99.04% |
10,000,000 devices × 10 metrics | 2,349,628 | 3,031,325 | 3,135,838 | 3,268,176 |
(vnodes = 6) / (vnodes = #p) | 100.00% | 129.01% | 133.46% | 139.09% |
不同虚拟节点数据量情况写入性能变化
从上表可以看到,在设备数最小的场景一中,随着虚拟节点数的增加,写入变化趋势不明显。在较多设备的场景(场景五)中,增加 vnodes 的数量 ,写入性能获得了显著的提升。可见在不同规模的场景中,通过调整 TDengine 虚拟节点的数量可以获得更好的写入性能,大规模场景中尤甚。
fsync 对写入性能的影响
TDengine写入速度(metrics/sec.) | scale=100 | scale=4000 | scale=100000 | scale=1000000 | scale=10000000 |
fysnc=0ms | 12,530,045 | 12,176,290 | 7,566,922 | 4,199,325 | 2,588,922 |
fsync=200ms | 12,842,668 | 12,477,106 | 7,681,030 | 4,264,758 | 1,974,915 |
fsync=3000ms | 12,505,486 | 12,406,330 | 7,385,493 | 4,123,547 | 1,968,498 |
不同 fsync 配置下写入性能趋势
我们使用 fsync 参数控制写入到预写日志(write ahead log, WAL)文件中的数据调用 fsync 的频率,以确保数据可靠落盘。一般来说,调用 fsync 会消耗较多的 IO 资源,并会对写入过程造成一定的影响。但从上表可以看到,fsync 的配置调整对 TDengine 写入性能影响很小。
在前四个场景中,fsync 配置为实时同步刷入磁盘(fsync 为 0)的情况下,写入性能并没有出现显著降低。这是由于写入过程采用了大批量的写入模式,降低了每次刷入磁盘的次数需求,所以对性能影响并不明显,反之写入性能将降低。因此,我们可以获得一个信息,在此种情况下应用 TDengine,增加每批次写入数据量,可以有效缓解 fsync 配置写入的影响。
设备记录数量
TDengine 的“一个设备一张表”数据模型使得其在进行数据写入时要先创建表,建表操作对每个设备只执行一次,但这会让 TDengine 在数据写入的准备阶段耗时较多。当单个表中数据量增加以后,数据准备(建表)的开销会被分摊到数据写入的整体开销中,所以应该有更好的数据写入性能。
以场景四为例,单个设备的数据量仅有 18 条。当我们调整参数,将单个设备记录数据增加到 36、72、144 条时,整体写入时间也变得更长,即建表开销被分摊到更多的数据写入过程中,建表的开销相对于数据写入的耗时占比越来越小,相应的整体写入速度也就越来越快。因此可以看到,随着设备记录数量增加,TDengine 表现出了更加明显的写入优势。

设备记录数增加时数据写入性能对比(数值越大越好)
随后我们调整了 vnodes 的数量配置,并同时测试两个不同 vnodes 数量情况下的写入性能指标。如上图所示,随着表中记录数的增加,单表记录增加到 72 时,TDengine 设置为 6 vnodes 的写入性能出现了下降,但是在 24 vnodes 的情况下,写入性能呈现出持续增加的趋势,并且在全部场景下写入性能均优于 6 vnodes 的写入性能。
当设备记录数达到 576 行(此时数据集规模为 1,000,000 × 576 = 5.76 亿行数据记录)时,写入性能达到 6,605,515 metrics/sec. 。在单设备记录达到 576 行时,默认 6 vnodes 配置下 TDengine 写入性能是 TimescaleDB 和 InfluxDB 的 7 倍多,当设置为 24 vnodes 时,性能更是大幅领先于 TimescaleDB 与 InfluxDB,最高达到了 TimescaleDB 和 InfluxDB 的 13 倍多。
TimescaleDB 写入性能在单表记录数量大于 72 行时就出现了下降趋势,在单表记录数 144 行以后出现了快速衰减。InfluxDB 在单设备记录增加过程中,写入性能有衰减,但衰减趋势比较缓慢。
写在最后
由此可见,TDengine 在五个测试场景中,写入性能均超过了 TimescaleDB 和 InfluxDB。且在整个写入过程中,TDengine 不仅提供了更高的写入能力,还保证了最小的资源消耗,不论是服务器的 CPU 还是 IO,TDengine 均远优于 TimescaleDB 和 InfluxDB。即使加上客户端的开销统计,TDengine 在写入开销上也远优于 TimescaleDB 和 InfluxDB。
在后面的拓展部分,通过调整不同的参数,以及设置不同的数据规模、调整 fsync 参数等方式,我们在更多的方面评估了 TDengine 在 TSBS 基准数据集上的写入性能。通过这一系列深入的对比可以看到,针对更大规模数据集,TDengine 可以通过简单调整虚拟节点数量的方式获得更高的写入性能,并且 TDengine 在针对大数据集写入场景下展现出了更大的性能优势。
TDengine 高效的写入性能在企业实践中也得到了验证,此前在机器人骨干企业拓斯达的工厂整体解决方案项目案例中,就阐述了应用 TDengine 后的改造结果——一个设备一天最多能写入近十万条数据,近千个设备同时写入也完全没有问题,相较于之前,写入速度提升了数十倍。
如果你也面临着数据处理难题或想要进行数据架构升级,欢迎添加小T vx:tdengine1,加入 TDengine 用户交流群,和更多志同道合的开发者一起攻克难关。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。