Mysql的索引详解
- 1.索引定义
- 2.索引结构
- 2.1数据结构分析
- 2.1.1熟知的数据结构
- 2.1.2分析为什么这么多的数据结构不全适用于索引结构
- 2.2Hash结构
- 2.3B+ tree结构
- 3.索引分类
- 3.1聚集索引(聚簇索引)
- 3.2非聚集索引(稀疏索引)
- 3.3联合索引
- 3.4主键索引和非主键
1.索引定义
索引是mysql帮我们排好序的数据结构,可以更快捷的查找数据
2.索引结构
2.1数据结构分析
2.1.1熟知的数据结构
- hash
- 二叉树
- 红黑树
- B-tree
2.1.2分析为什么这么多的数据结构不全适用于索引结构
- 二叉树:其中二叉树有个众所周知的问题,就是容易形成“歪脖子”树,形成类似链表的结构查询速度很慢。
- 红黑树:红黑树对二叉树做了优化,保证了左子树和右子树的均衡,不会出现歪脖子树,但是缺点是层级太深,不适合作为mysql的索引结构(索引的查找方式会在下面进行分析)
索引的查找方式:索引结构实际上存储在磁盘上的文件中,mysql根据索引定位,每定位一个位置后都需要加载到内存中然后在查找下一层级,如果层级很深就需要进行多次磁盘io,而这个操作是很耗时的。
总结:排除掉二叉树和红黑树后适合作为索引结构就是hash结构和B-tree
但是实际上mysql的索引结构使用的是B+tree,这里就需要说明B-tree和B+tree的区别了。
B-tree和B+tree的区别:
- 非叶子节点不存储数据,只存储索引(因为叶子节点有全量的索引,非叶子节点存储的为冗余索引),这样可以在非叶子节点的层级放更多的索引。
- 叶子节点包含所以的索引
- 叶子节点使用指针链接,提高了区间的访问能力
针对上面说的非叶子节点存储更多的索引做解释:
我们知道mysql在加载索引时一个磁盘页的大小为16k,如果非叶子节点存储数据,那么它的大小就远远大于只存储索引时的大小。所以如果非叶子节点只存储索引数据,那么一个磁盘页加载的索引数据就更多,减少了磁盘加载次数,这样可以优化mysql的查询效率。
2.2Hash结构
hash结构有个好处,就是查找的时候只需要对key进行一次hash运算就能算出存储位置。但是也存在这很多问题,比如hash冲突,以及sql中的范围查询。所以一板情况下我们不是hash结构建立索引。
2.3B+ tree结构
B+tree结构可以很好的解决索引数据存储层级过深的问题,而且相比与B-tree优化了每个磁盘页可加载的索引数量,同时在叶子节点使用指针链接,提高了区间的访问能力,我们常用的索引结构就是B+tree.
3.索引分类
3.1聚集索引(聚簇索引)
聚集索引实际上是一种文件存储方式,索引文件和数据文件存储在一起称之为聚集索引
InnoDB存储引擎的索引和数据就存放在一个文件。
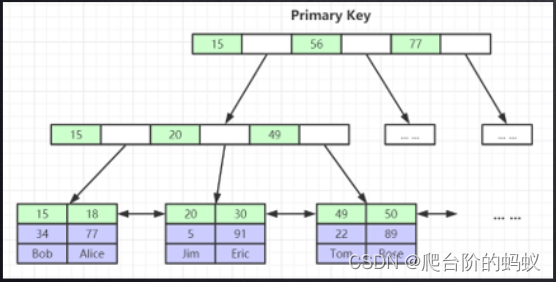
主键索引的叶子节点存储的就是响应的行数据
3.2非聚集索引(稀疏索引)
索引文件和数据文件分开存储称为非聚集索引
MyISAM存储引擎的索引文件和数据文件分开存储。
 主键索引的叶子节点指向数据存储的位置,通过主键索引定位到数据后需要再根据主键索引指向的位置加载相应数据
主键索引的叶子节点指向数据存储的位置,通过主键索引定位到数据后需要再根据主键索引指向的位置加载相应数据
3.3联合索引
多列字段联合建立索引,按照执行顺序一次排序。
3.4主键索引和非主键
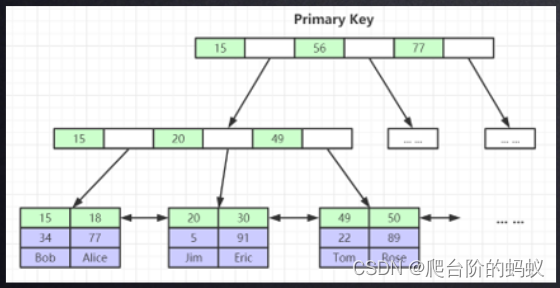
 非主键索引的叶子节点存储的是主键索引,需要进行回表操作,根据定位的主键索引在进行查询对应的行数据。
非主键索引的叶子节点存储的是主键索引,需要进行回表操作,根据定位的主键索引在进行查询对应的行数据。
回表:跨两个B+tree查找数据,我们称之为回表操作。
由此可以引发很多索引优化需要注意的地方,比如可以通过二级索引直接查询的结果避免回表查询。(假设联合索引为二级索引,查询数据时使用覆盖索引,所有查询字段在二级索引树就能获取到,此时就直接在二级索引树查询结果返回,另外二级索引树因为不存具体行数据,索引比主键索引小因此效率也能更高)