咖啡不冲,你一定会成功

分布式架构设计模式
- 一、什么是设计模式?
- 1.1 设计模式的由来
- 1.2 设计模式有哪些种类
- 1.3 如何学习设计模式
- 二、六大设计原则
- 2.1 开闭原则
- 2.2 单一职责原则
- 2.3 里氏替换原则
- 2.4 迪米特法则
- 2.5 接口隔离原则
- 2.6 依赖倒置原则
- 三、创建型模式
- 3.1 理解工厂模式
- 3.2 抽象工厂在项目开发中的作用
- 3.3 单例模式的设计与作用
- 3.3.1 为什么要使用单例
- 3.3.2 如何实现一个单例
- 3.4 建造者模式的设计与作用
- 3.4.1 不用建造者有什么麻烦?
- 3.4.2 建造者模式是一个好选择
- 3.5 原型模式Prototype
- 3.5.1 概述
- 3.5.2 代码实现
- 3.5.3 代码实现应用场景
- 四、结构型模式
- 4.1 门面模式Facade
- 4.1.1 什么是门面模式Facade
一、什么是设计模式?
1.1 设计模式的由来
设计模式是系统服务设计中针对常见场景的一种解决方案,可以解决功能逻辑开发中遇到的共性问题。
因为设计模式是一种开发设计指导思想,每一种设计模式都是解决某一类问题的概念模型,所以在实际的使用过程中,不要拘泥于某种已经存在的固定代码格式,而要根据实际的业务场景做出改变。
正因为设计模式的这种特点,所以即使是同一种设计模式,在不同的场景中也有不同的代码实现方式。另外,即便是相同的场景,选择相同的设计模式,不同的研发人员也可能给出不一样的实现方案。
所以,设计模式并不局限于最终的实现方案,而是在这种概念模型下,解决系统设计中的代码逻辑问题。
设计模式的概念最早是由克里斯托弗·亚历山大在其著作《建筑模式语言》中提出的,2022年病逝,享年85岁。

埃里希·伽玛、约翰·弗利赛德斯、拉尔夫·约翰逊和理查德·赫尔姆四位作者接受了模式的概念。他们于1994年出版了《设计模式:可复用面向对象软件的基础》一书,将设计模式的概念应用到程序开发领域中。

1.2 设计模式有哪些种类
设计模式共有23种,按目的分类可以分为三类:
- 创建型模式: 提供创建对象的机制,提升已有代码的灵活性和可复用性。
- 工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
- 结构型模式: 介绍如何将对象和类组装成较大的结构,并同时保持结构的灵活和高效。
- 适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
- 行为模式: 负责对象间的高效沟通和职责传递委派。
- 策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
1.3 如何学习设计模式
以前学习设计模式,通常会先学设计模式的结构、掌握类图、编写代码,这是错误的。
设计模式是前辈们日常总结的经验,首先我们要弄清楚到底工作中按原有方式编码会出现什么问题,再去通过某一种或某几种设计模式灵活运用去解决它,将设计模式能用在“刀刃”上,这才是我们学习设计模式的目的所在,至于使用了使用了单例模式的“懒汉”还是 “饿汉”形式书写,这些都是战术问题。
二、六大设计原则
2.1 开闭原则
一般认为最早提出开闭原则(Open-Close Principle,OCP)的是伯特兰·迈耶。他在1988 年发表的《面向对象软件构造》中给出的。
在面向对象编程领域中,开闭原则规定软件中的对象、类、模块和函数对扩展应该是开放的,但对于修改是封闭的。
开闭原则的核心思想也可以理解为面向抽象编程。
错误示范:
public interface UserDAO {
public void insert();
}
public interface UserDAOImpl implements UserDAO{
public void insert(){
//基于JDBC实现数据插入
...
pstmt.executeUpdate()
}
}
新需求来了,放弃JDBC改用JNDI,于是你删除原有代码,在方法中重写逻辑
public interface UserDAOImpl implements UserDAO{
public void insert(){
//pstmt.executeUpdate()
//基于JNDI实现数据插入jndi.insert();
}
}
正确的做法:
对修改关闭,对扩展开放
public interface UserDAOJndiImpl implements UserDAO{
public void insert(){
//基于JNDI实现数据插入jndi.insert();
}
}
不推荐的做法,Java对继承不友好,除非父类明确abstract,否则不推荐优先使用extends
public interface UserDAOJndiImpl extends UserDAOImpl{
public void insert(){
//基于JNDI实现数据插入jndi.insert();
}
}
2.2 单一职责原则
单一职责原则(Single Responsibility Principle,SRP)又称单一功能原则。
如果需要开发的一个功能需求不是一次性的,且随着业务发展的不断变化而变化,那么当一个Class类负责超过两个及以上的职责时,就在需求的不断迭代、实现类持续扩张的情况下,就会出现难以维护、不好扩展、测试难度大和上线风险高等问题。
错误的做法:
这里通过一个视频网站用户分类的例子,来帮助大家理解单一职责原则的构建方法。当在各类视频网站看电影、电视剧 时,网站针对不同的用户类型,会在用户观看时给出不同的服务反馈,如以下三种:
- 访客用户: 一般只可以观看480P视频,并时刻提醒用户注册会员能观看高清视频。这表示视频业务发展需要拉客,以获 取更多的新注册用户。
- 普通会员: 可以观看720P超清视频,但不能屏蔽视频中出现的广告。这表示视频业务发展需要盈利。
- VIP 会员(属于付费用户): 既可以观看 1080P 蓝光视频,又可以关闭或跳过广告。
public class VideoUserService {
public void serveGrade(String userType){
if ("VIP用户".equals(userType)){
System.out.println("VIP用户,视频1080P蓝光");
} else if ("普通用户".equals(userType)){
System.out.println("普通用户,视频720P超清");
} else if ("访客用户".equals(userType)){
System.out.println("访客用户,视频480P高清");
}
}
}
正确的做法:
接口抽象:
public interface IVideoUserService {
// 视频清晰级别;480P、720P、1080P
void definition();
// 广告播放方式;无广告、有广告
void advertisement();
}
访客逻辑:
public class GuestVideoUserService implements IVideoUserService {
public void definition() {
System.out.println("访客用户,视频480P高清");
}
public void advertisement() {
System.out.println("访客用户,视频有广告");
}
普通会员逻辑:
public class OrdinaryVideoUserService implements IVideoUserService {
public void definition() {
System.out.println("普通用户,视频720P超清");
}
public void advertisement() {
System.out.println("普通用户,视频有广告");
}
}
VIP会员逻辑:
public class VipVideoUserService implements IVideoUserService {
public void definition() {
System.out.println("VIP用户,视频1080P蓝光");
}
public void advertisement() {
System.out.println("VIP用户,视频无广告");
}
}
2.3 里氏替换原则
继承必须确保超类所拥有的性质在子类中仍然成立
子类可以扩展父类的功能,但不能改变父类原有的功能,也就是说:当子类继承父类时,除添加新的方法且完成新增功能外,尽量不要重写父类的方法。
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
- 子类可以增加自己特有的方法。
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的输入参数)要比父类的方法更宽松。
- 当子类的方法实现父类的方法(重写、重载或实现抽象方法)时,方法的后置条件(即方法的输出或返回值)要比父类的方法更严格或与父类的方法相等。
里氏替换原则的作用:
- 里氏替换原则是实现开闭原则的重要方式之一。
- 解决了继承中重写父类造成的可复用性变差的问题。
- 是动作正确性的保证,即类的扩展不会给已有的系统引入新的错误,降低了代码出错的可能性。
- 加强程序的健壮性,同时变更时可以做到非常好的兼容性,提高程序的维护性、可扩展性,降低需求变更时引入的风 险。
错误的做法
需求: 储蓄卡和信用卡在使用功能上类似,都有支付、提现、还款、充值等功能,也有些许不同,例如支付,储蓄卡做的是账户 扣款动作,信用卡做的是生成贷款单动作。
下面这里模拟先有储蓄卡的类,之后继承这个类的基本功能,以实现信用卡的功能。
public class CashCard {
private Logger logger = LoggerFactory.getLogger(CashCard.class);
public String withdrawal(String orderId, BigDecimal amount) {
// 模拟支付成功
logger.info("提现成功,单号:{} 金额:{}", orderId, amount);
return "0000";
}
public String recharge(String orderId, BigDecimal amount) {
// 模拟充值成功
logger.info("储蓄成功,单号:{} 金额:{}", orderId, amount);
return "0000";
}
public List<String> tradeFlow() {
logger.info("交易流水查询成功");
List<String> tradeList = new ArrayList<String>();
tradeList.add("100001,100.00");
tradeList.add("100001,80.00");
tradeList.add("100001,76.50");
tradeList.add("100001,126.00");
return tradeList;
}
}
信用卡:
public class CreditCard extends CashCard {
private Logger logger = LoggerFactory.getLogger(CashCard.class);
@Override
public String withdrawal(String orderId, BigDecimal amount) {
// 校验
if (amount.compareTo(new BigDecimal(1000)) >= 0){
logger.info("贷款金额校验(限额1000元),单号:{} 金额:{}", orderId, amount);
return "0001";
}
// 模拟生成贷款单
logger.info("生成贷款单,单号:{} 金额:{}", orderId, amount);
// 模拟支付成功
logger.info("贷款成功,单号:{} 金额:{}", orderId, amount);
return "0000";
}
@Override
public String recharge(String orderId, BigDecimal amount) {
// 模拟生成还款单
logger.info("生成还款单,单号:{} 金额:{}", orderId, amount);
// 模拟还款成功
logger.info("还款成功,单号:{} 金额:{}", orderId, amount);
return "0000";
}
@Override
public List<String> tradeFlow() {
return super.tradeFlow();
}
}
用卡的功能实现是在继承了储蓄卡类后,进行方法重写:支付withdrawal()、还款recharge()。其实交易流水可以复 用,也可以不用重写这个类。
这种继承父类方式的优点是复用了父类的核心功能逻辑,但是也破坏了原有的方法。此时继承父类实现的信用卡类并不满 足里氏替换原则,也就是说,此时的子类不能承担原父类的功能,直接当储蓄卡使用。
没有abstract抽象的方法不允许被重写!JDK15版本提供了名为密封类的特性,允许说明允许哪些子类继承,哪些不允许继承。
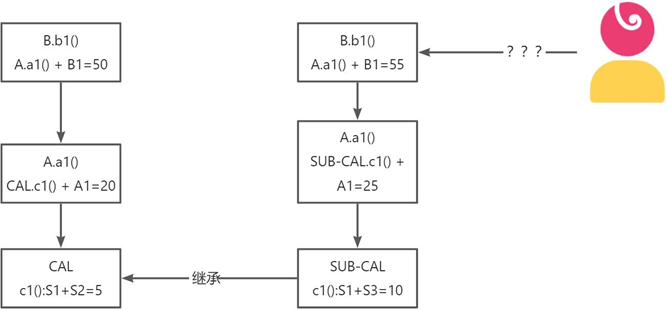
正确的做法
抽象银行卡父类: 在抽象银行卡类中,提供了基本的卡属性,包括卡号、开卡时间及三个核心方法。正向入账,加钱;逆向入账,减钱。当 然,实际的业务开发抽象出来的逻辑会比模拟场景多一些。接下来继承这个抽象类,实现储蓄卡的功能逻辑。
public abstract class BankCard {
private Logger logger = LoggerFactory.getLogger(BankCard.class);
private String cardNo; // 卡号
private String cardDate; // 开卡时间
public BankCard(String cardNo, String cardDate) {
this.cardNo = cardNo;
this.cardDate = cardDate;
}
abstract boolean rule(BigDecimal amount);
// 正向入账,+ 钱
public String positive(String orderId, BigDecimal amount) {
// 入款成功,存款、还款
logger.info("卡号{} 入款成功,单号:{} 金额:{}", cardNo, orderId, amount);
return "0000";
}
// 逆向入账,- 钱
public String negative(String orderId, BigDecimal amount) {
// 入款成功,存款、还款
logger.info("卡号{} 出款成功,单号:{} 金额:{}", cardNo, orderId, amount);
return "0000";
}
/**
* 交易流水查询
*
* @return 交易流水
*/
public List<String> tradeFlow() {
logger.info("交易流水查询成功");
List<String> tradeList = new ArrayList<String>();
tradeList.add("100001,100.00");
tradeList.add("100001,80.00");
tradeList.add("100001,76.50");
tradeList.add("100001,126.00");
return tradeList;
}
public String getCardNo() {
return cardNo;
}
public String getCardDate() {
return cardDate;
}
}
储蓄卡子类: 储蓄卡类中继承抽象银行卡父类 BankCard,实现的核心功能包括规则过滤rule、提现withdrawal、储蓄recharge和新增的扩展方法,即风控校验 checkRisk。
public class CashCard extends BankCard {
private Logger logger = LoggerFactory.getLogger(CashCard.class);
public CashCard(String cardNo, String cardDate) {
super(cardNo, cardDate);
}
boolean rule(BigDecimal amount) {
return true;
}
public String withdrawal(String orderId, BigDecimal amount) {
// 模拟支付成功
logger.info("提现成功,单号:{} 金额:{}", orderId, amount);
return super.negative(orderId, amount);
}
public String recharge(String orderId, BigDecimal amount) {
// 模拟充值成功
logger.info("储蓄成功,单号:{} 金额:{}", orderId, amount);
return super.positive(orderId, amount);
}
public boolean checkRisk(String cardNo, String orderId, BigDecimal amount) {
// 模拟风控校验
logger.info("风控校验,卡号:{} 单号:{} 金额:{}", cardNo, orderId, amount);
return true;
}
}
信用卡子类: 信用卡类在继承父类后,使用了公用的属性,即卡号 cardNo、开卡时间 cardDate,同时新增了符合信用卡功能的新方法,即贷款loan、还款repayment,并在两个方法中都使用了抽象类的核心功能。
另外,关于储蓄卡中的规则校验方法,新增了自己的规则方法 rule2,并没有破坏储蓄卡中的校验方法。
以上的实现方式都是在遵循里氏替换原则下完成的,子类随时可以替代储蓄卡类。
public class CreditCard extends CashCard {
private Logger logger = LoggerFactory.getLogger(CreditCard.class);
public CreditCard(String cardNo, String cardDate) {
super(cardNo, cardDate);
}
boolean rule2(BigDecimal amount) {
return amount.compareTo(new BigDecimal(1000)) <= 0;
}
public String loan(String orderId, BigDecimal amount) {
boolean rule = rule2(amount);
if (!rule) {
logger.info("生成贷款单失败,金额超限。单号:{} 金额:{}", orderId, amount);
return "0001";
}
// 模拟生成贷款单
logger.info("生成贷款单,单号:{} 金额:{}", orderId, amount);
// 模拟支付成功
logger.info("贷款成功,单号:{} 金额:{}", orderId, amount);
return super.negative(orderId, amount);
}
public String repayment(String orderId, BigDecimal amount) {
// 模拟生成还款单
logger.info("生成还款单,单号:{} 金额:{}", orderId, amount);
// 模拟还款成功
logger.info("还款成功,单号:{} 金额:{}", orderId, amount);
return super.positive(orderId, amount);
}
}
通过以上的测试结果可以看到,储蓄卡功能正常,继承储蓄卡实现的信用卡功能也正常。同时,原有储蓄卡类的功能可以 由信用卡类支持,即 CashCard creditCard=new CreditCard(…)。
继承作为面向对象的重要特征,虽然给程序开发带来了非常大的便利,但也引入了一些弊端。继承的开发方式会给代码带 来侵入性,可移植能力降低,类之间的耦合度较高。当对父类修改时,就要考虑一整套子类的实现是否有风险,测试成本 较高。
里氏替换原则的目的是使用约定的方式,让使用继承后的代码具备良好的扩展性和兼容性。
在日常开发中使用继承的地方并不多,在有些公司的代码规范中也不会允许多层继承,尤其是一些核心服务的扩展。而继 承多数用在系统架构初期定义好的逻辑上或抽象出的核心功能里。如果使用了继承,就一定要遵从里氏替换原则,否则会 让代码出现问题的概率变得更大。
2.4 迪米特法则
迪米特法则(Law of Demeter,LoD)又称为最少知道原则(Least Knowledge Principle,LKP),是指一个对象类对于其他对象类来说,知道得越少越好。也就是说,两个类之间不要有过多的耦合关系,保持最少关联性。
错误的做法
师需要负责具体某一个学生的学习情况,而校长会关心老师所在班级的总体成绩,不会过问具体某一个学生的学习情况。
public class Student {
private String name; // 学生姓名
private int rank; // 考试排名(总排名)
private double grade; // 考试分数(总分)
...
}
public class Teacher {
private String name; // 老师名称
private String clazz; // 班级
private static List<Student> studentList; // 学生
public Teacher() {
}
public Teacher(String name, String clazz) {
this.name = name;
this.clazz = clazz;
}
static {
studentList = new ArrayList<>();
studentList.add(new Student("花花", 10, 589));
studentList.add(new Student("豆豆", 54, 356));
studentList.add(new Student("秋雅", 23, 439));
studentList.add(new Student("皮皮", 2, 665));
studentList.add(new Student("蛋蛋", 19, 502));
}
}
public class Principal {
private Teacher teacher = new Teacher("丽华", "3年1班");
// 查询班级信息,总分数、学生人数、平均值
public Map<String, Object> queryClazzInfo(String clazzId) {
// 获取班级信息;学生总人数、总分、平均分
int stuCount = clazzStudentCount();
double totalScore = clazzTotalScore();
double averageScore = clazzAverageScore();
// 组装对象,实际业务开发会有对应的类
Map<String, Object> mapObj = new HashMap<>();
mapObj.put("班级", teacher.getClazz());
mapObj.put("老师", teacher.getName());
mapObj.put("学生人数", stuCount);
mapObj.put("班级总分数", totalScore);
mapObj.put("班级平均分", averageScore);
return mapObj;
}
// 总分
public double clazzTotalScore() {
double totalScore = 0;
for (Student stu : teacher.getStudentList()) {
totalScore += stu.getGrade();
}
return totalScore;
}
// 平均分
public double clazzAverageScore(){
double totalScore = 0;
for (Student stu : teacher.getStudentList()) {
totalScore += stu.getGrade();
}
return totalScore / teacher.getStudentList().size();
}
// 班级人数
public int clazzStudentCount(){
return teacher.getStudentList().size();
}
}
以上就是通过校长管理所有学生,老师只提供了非常简单的信息。虽然可以查询到结果,但是违背了迪米特法则,因为校长需要了解每个学生的情况。如果所有班级都让校长类统计,代码就会变得非常臃肿,也不易于维护和扩展。
正确的做法
由老师负责分数统计
public class Teacher {
private String name;
private String clazz; // 班级
private static List<Student> studentList; // 学生
public Teacher() {
}
public Teacher(String name, String clazz) {
this.name = name;
this.clazz = clazz;
}
static {
studentList = new ArrayList<>();
studentList.add(new Student("花花", 10, 589));
studentList.add(new Student("豆豆", 54, 356));
studentList.add(new Student("秋雅", 23, 439));
studentList.add(new Student("皮皮", 2, 665));
studentList.add(new Student("蛋蛋", 19, 502));
}
// 总分
public double clazzTotalScore() {
double totalScore = 0;
for (Student stu : studentList) {
totalScore += stu.getGrade();
}
return totalScore;
}
// 平均分
public double clazzAverageScore(){
double totalScore = 0;
for (Student stu : studentList) {
totalScore += stu.getGrade();
}
return totalScore / studentList.size();
}
// 班级人数
public int clazzStudentCount(){
return studentList.size();
}
public String getName() {
return name;
}
}
校长只负责从老师哪里收集信息即可,并不需要获取具体学生信息
public class Principal {
private Teacher teacher = new Teacher("丽华", "3年1班");
// 查询班级信息,总分数、学生人数、平均值
public Map<String, Object> queryClazzInfo(String clazzId) {
// 获取班级信息;学生总人数、总分、平均分
int stuCount = teacher.clazzStudentCount();
double totalScore = teacher.clazzTotalScore();
double averageScore = teacher.clazzAverageScore();
// 组装对象,实际业务开发会有对应的类
Map<String, Object> mapObj = new HashMap<>();
mapObj.put("班级", teacher.getClazz());
mapObj.put("老师", teacher.getName());
mapObj.put("学生人数", stuCount);
mapObj.put("班级总分数", totalScore);
mapObj.put("班级平均分", averageScore);
return mapObj;
}
}
2.5 接口隔离原则
一个类对另一个类的依赖应该建立在最小的接口上
接口隔离原则(Interface Segregation Principle,ISP)要求程序员尽量将臃肿庞大的接口拆分成更小的和更具体的接口,让接口中只包含客户感兴趣的方法
正确的做法
Servlet事件监听器可以监听ServletContext、HttpSession、ServletRequest等域对象的创建和销毁过程,以及监听这些域对象属性的修改。
ServletContextListener接口
public void contextInitialized(servletContextEvent sce);
public void contextDestroyed(servletContextEvent sce);
HttpSessionListener
public void sessionCreated(HttpSessionEvent se);
public void sessionDestroyed(HttpSessionEvent se)
ServletRequestListener接口
public void requestInitialized(ServletRequestEvent sre);
public void requestDestroyed(ServletRequestEvent sre);
监听应用代码
public class MyListener implements ServletRequestListener, HttpSessionListener, ServletContextListener {
public void contextInitialized(ServletContextEvent arg0) {
System.out.println("ServletContext对象被创建了");
}
public void contextDestroyed(ServletContextEvent arg0) {
System.out.println("ServletContext对象被销毁了");
}
public void sessionCreated(HttpSessionEvent arg0) {
System.out.println("HttpSession对象被创建了");
}
public void sessionDestroyed(HttpSessionEvent arg0) {
System.out.println("HttpSession对象被销毁了");
}
public void requestInitialized(ServletRequestEvent arg0) {
System.out.println("ServletRequest对象被创建了");
}
public void requestDestroyed(ServletRequestEvent arg0) {
System.out.println("ServletRequest对象被销毁了");
}
}
2.6 依赖倒置原则
依赖倒置原则(Dependence Inversion Principle,DIP)是指在设计代码架构时,高层模块不应该依赖于底层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
DIP就是我们常说的“面向接口编程”。
依赖倒置原则是实现开闭原则的重要途径之一,它降低了类之间的耦合,提高了系统的稳定性和可维护性,同时这样的代 码一般更易读,且便于传承。
错误的做法
在互联网的营销活动中,经常为了拉新和促活,会做一些抽奖活动。这些抽奖活动的规则会随着业务的不断发展而调整, 如随机抽奖、权重抽奖等。其中,权重是指用户在当前系统中的一个综合排名,比如活跃度、贡献度等。
抽奖用户类
public class BetUser {
private String userName; // 用户姓名
private int userWeight; // 用户权重
}
抽奖逻辑类
public class DrawControl {
// 随机抽取指定数量的用户,作为中奖用户
public List<BetUser> doDrawRandom(List<BetUser> list, int count) {
// 集合数量很小直接返回
if (list.size() <= count) return list;
// 乱序集合
Collections.shuffle(list);
// 取出指定数量的中奖用户
List<BetUser> prizeList = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
prizeList.add(list.get(i));
}
return prizeList;
}
// 权重排名获取指定数量的用户,作为中奖用户
public List<BetUser> doDrawWeight(List<BetUser> list, int count) {
// 按照权重排序
list.sort((o1, o2) -> {
int e = o2.getUserWeight() - o1.getUserWeight();
if (0 == e) return 0;
return e > 0 ? 1 : -1;
});
// 取出指定数量的中奖用户
List<BetUser> prizeList = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
prizeList.add(list.get(i));
}
return prizeList;
}
}
正确的做法
抽奖接口
public interface IDraw {
// 获取中奖用户接口
List<BetUser> prize(List<BetUser> list, int count);
}
随机抽奖实现
public class DrawRandom implements IDraw {
@Override
public List<BetUser> prize(List<BetUser> list, int count) {
// 集合数量很小直接返回
if (list.size() <= count) return list;
// 乱序集合
Collections.shuffle(list);
// 取出指定数量的中奖用户
List<BetUser> prizeList = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
prizeList.add(list.get(i));
}
return prizeList;
}
}
权重抽奖实现
public class DrawWeightRank implements IDraw {
@Override
public List<BetUser> prize(List<BetUser> list, int count) {
// 按照权重排序
list.sort((o1, o2) -> {
int e = o2.getUserWeight() - o1.getUserWeight();
if (0 == e) return 0;
return e > 0 ? 1 : -1;
});
// 取出指定数量的中奖用户
List<BetUser> prizeList = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
prizeList.add(list.get(i));
}
return prizeList;
}
}
开奖
public class DrawControl {
public List<BetUser> doDraw(IDraw draw, List<BetUser> betUserList, int count) {
return draw.prize(betUserList, count);
}
public static void main(String[] args){
List<BetUser> userList = new ArrayList();
//初始化userList
//这里的重点是把实现逻辑的接口作为参数传递
new DrawControl().doDraw(new DrawWeightRank() , userList , 3);
}
}
}
在这个类中体现了依赖倒置的重要性,可以把任何一种抽奖逻辑传递给这个类。
这样实现的好处是可以不断地扩展,但是 不需要在外部新增调用接口,降低了一套代码的维护成本,并提高了可扩展性及可维护性。
另外,这里的重点是把实现逻辑的接口作为参数传递,在一些框架源码中经常会有这种做法。
三、创建型模式
3.1 理解工厂模式
工厂模式也称简单工厂模式,是创建型设计模式的一种,这种设计模式提供了按需创建对象的最佳方式。同时,这种创建 方式不会对外暴露创建细节,并且会通过一个统一的接口创建所需对象。
工厂模式属于创建型模式的一种,其目的就是隐藏创建类的细节与过程。
可以以电脑店为例,我是一个纯小白,面对琳琅满目的各种电脑一脸懵X,根本无从下手
电脑接口
public interface Computer {
public String describe();
}
外星人游戏笔记本
public class Alienware implements Computer{
@Override
public String describe() {
return "外星人ALIENWARE m15 R7 15.6英寸高端游戏本 12代i7 32G RTX3060 QHD 240Hz 高刷屏 轻薄笔记本电脑2765QB";
}
}
高性能独显PC主机
public class Desktop implements Computer{
@Override
public String describe() {
return "外星人ALIENWARE R13 水冷电竞游戏高端台式机 第12代i7 32G 512GB+2T RTX3070 办公台式机 9776W";
}
}
Macbook办公轻薄本
public class Macbook implements Computer{
@Override
public String describe() {
return "Apple MacBook Pro 13.3 八核M1芯片 8G 256G SSD 深空灰 笔记本电脑 轻薄本 MYD82CH/A";
}
}
2U戴尔服务器
public class Server implements Computer{
@Override
public String describe() {
return "戴尔(DELL) R740丨R750丨2U机架式服务器主机双路GPU深度学习 R740〖1*银牌4210R 10核20线程〗 8G 内存丨1TB SATA硬盘 丨H350戴尔(DELL);
}
}
此时顾客将面对几十种不同性能,不同规格不同种类的电脑,难道顾客必须了解所有细节才能决定使用哪一个吗?
这里就破坏了“迪米特法则(知道的越少越好)”,大多数客户并不需要了解每一台细节,我们要把选择权交还给电脑店这一方。
控制权在顾客方是不对的,我们需要一个工厂类,帮助顾客进行决策,这样控制权掌握
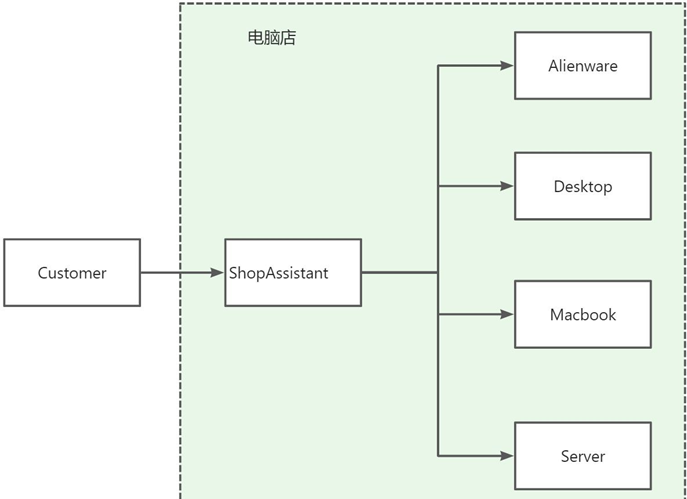
正确的做法
增加一个售货员帮助用户实现决策,根据客户的不同要求提供对应的产品。这个售货员就是充当了“工厂"的角色。
工厂模式的特点:提供方法,返回接口。
public class ShopAssistant {
public Computer suggest(String purpose){
Computer computer = null;
if(purpose.equals("网站建设")){
return new Server();
}else if(purpose.equals("电竞比赛")){
return new Desktop();
}else if(purpose.equals("日常办公")){
return new Macbook();
}else if(purpose.equals("3A游戏")){
return new Alienware();
}
return computer;
}
}
}
站在顾客这一方,获取对象的过程变得非常简单,通过售货员这个工厂帮助我们获取需要的对象,同时不再关注对象创建的过程与细节。
public class Customer {
public static void main(String[] args) {
ShopAssistant shopAssistant = new ShopAssistant();
Computer c = shopAssistant.suggest("3A游戏");
System.out.println(c.describe());
}
}
项目中的作用
难道让用户自己选择使用那个语言吗?在界面上提供个下拉选择框,让用户自己选择语言?
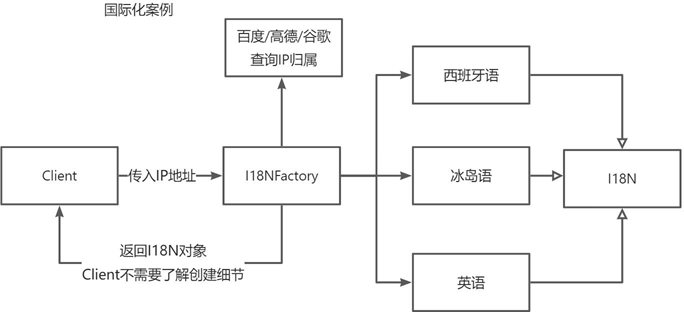
3.2 抽象工厂在项目开发中的作用
抽象工厂也可以称作其他工厂的工厂,它可以在抽象工厂中创建出其他工厂,与工厂模式一样,都是用来解决接口选择的 问题,同样都属于创建型模式。
需求
公司早期接入七牛云OSS(对象存储服务)上传图片与视频,后因业务调整,公司要求额外支持阿里云、腾讯云等其他云 服务商,并且可以对客户提供外界访问。
设计要求为: 允许在不破坏原有代码逻辑情况下,实现对任意三方云厂商的接入。
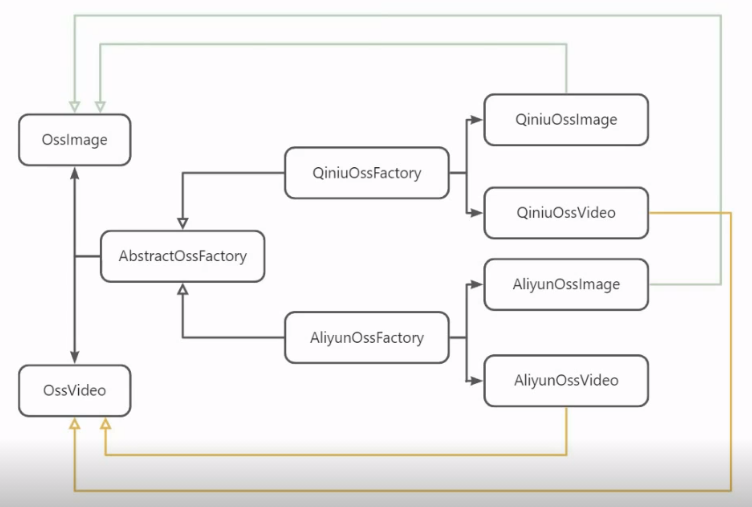
抽象工厂模式
顾名思义即为工厂的工厂,通过构建顶层的抽象工厂和抽象的产品,屏蔽系列产品的构建过程。
演示代码
抽象工厂与抽象的系列产品接口
public interface AbstractOssFactory {
public OssImage uploadImage(byte[] bytes);
public OssVideo uploadVideo(byte[] bytes);
}
public interface OssImage {
public String getThumb() ;
public String getWatermark() ;
public String getEnhance();
}
public interface OssVideo {
public String get720P();
public String get1080P();
}
七牛工厂
public class QiniuOssFactory implements AbstractOssFactory {
@Override
public OssImage uploadImage(byte[] bytes) {
return new QiniuOssImage(bytes,"IT老齐");
}
@Override
public OssVideo uploadVideo(byte[] bytes) {
return new QiniuOssVideo(bytes,"IT老齐");
}
}
七牛图片产品
public class QiniuOssImage implements OssImage {
private byte[] bytes;
public QiniuOssImage(byte[] bytes,String watermark){
this.bytes = bytes;
System.out.println("[七牛云]图片已上传至七牛云OSS,URL:http://oss.qiniu.com/xxxxxxx.jpg");
System.out.println("[七牛云]已生成缩略图,尺寸800X600像素");
System.out.println("[七牛云]已为图片新增水印,水印文本:" + watermark + ",文本颜色#cccccc");
System.out.println("[七牛云]已将图片AI增强为1080P高清画质");
}
@Override
public String getThumb() {
return "http://oss.qiniu.com/xxxxxxx_thumb.jpg";
}
@Override
public String getWatermark() {
return "http://oss.qiniu.com/xxxxxxx_watermark.jpg";
}
@Override
public String getEnhance() {
return "http://oss.qiniu.com/xxxxxxx_enhance.jpg";
}
}
七牛视频产品
public class QiniuOssVideo implements OssVideo {
private byte[] bytes;
public QiniuOssVideo(byte[] bytes, String watermark) {
this.bytes = bytes;
System.out.println("[七牛云]视频已上传至阿里云OSS,URL:http://oss.qiniu.com/xxx.mp4");
System.out.println("[七牛云]1080P转码成功,码率:3500K");
System.out.println("[七牛云]720P转码成功,码率:2500K");
}
@Override
public String get720P() {
return "http://oss.qiniu.com/xxx_720p_2500.mp4";
}
@Override
public String get1080P() {
return "http://oss.qiniu.com/xxx_1080p_3500.mp4";
}
}
阿里云工厂
public class AliyunOssFactory implements AbstractOssFactory {
@Override
public OssImage uploadImage(byte[] bytes) {
return new AliyunOssImage(bytes,"IT老齐",true);
}
@Override
public OssVideo uploadVideo(byte[] bytes) {
return new AliyunOssVideo(bytes,"IT老齐");
}
}
阿里云图片产品
public class AliyunOssImage implements OssImage {
private byte[] bytes;
public AliyunOssImage(byte[] bytes, String watermark,boolean transparent){
this.bytes = bytes;
System.out.println("[阿里云]图片已上传至阿里云OSS,URL:http://oss.aliyun.com/xxxxxxx.jpg");
System.out.println("[阿里云]已生成缩略图,尺寸640X480像素");
System.out.println("[阿里云]已为图片新增水印,水印文本:" + watermark + ",文本颜色:#aaaaaa,背景透明:" +
transparent);
System.out.println("[阿里云]已将图片AI增强为4K极清画质");
}
@Override
public String getThumb() {
return "http://oss.aliyun.com/xxxxxxx_thumb.jpg";
}
@Override
public String getWatermark() {
return "http://oss.aliyun.com/xxxxxxx_watermark.jpg";
}
@Override
public String getEnhance() {
return "http://oss.aliyun.com/xxxxxxx_enhance.jpg";
}
}
阿里云视频产品
public class AliyunOssVideo implements OssVideo {
private byte[] bytes;
public AliyunOssVideo(byte[] bytes, String watermark) {
this.bytes = bytes;
System.out.println("[阿里云]视频已上传至阿里云OSS,URL:http://oss.aliyun.com/xxx.mp4");
System.out.println("[阿里云]720P转码成功,码率:5000K");
System.out.println("[阿里云]1080P转码成功,码率:7000K");
}
@Override
public String get720P() {
return "http://oss.aliyun.com/xxx_720p.mp4";
}
@Override
public String get1080P() {
return "http://oss.aliyun.com/xxx_1080p.mp4";
}
}
用户端根本不需要了解阿里云/七牛云的处理细节,直接创建工厂对象就好啦。你建哪个工厂,就采用哪个工厂生产品, 产品的特质也不同。
同时,未来接入腾讯云也不需要修改现在的代码,按上面的套路实现一个工厂和图片、视频对象即可
public class Client {
public static void main(String[] args) {
// AbstractOssFactory factory = new AliyunOssFactory();
AbstractOssFactory factory = new QiniuOssFactory();
OssImage ossImage = factory.uploadImage(new byte[1024]);
OssVideo ossVideo = factory.uploadVideo(new byte[1024]);
System.out.println(ossImage.getThumb());
System.out.println(ossImage.getWatermark());
System.out.println(ossImage.getEnhance());
System.out.println(ossVideo.get720P());
System.out.println(ossVideo.get1080P());
}
}
3.3 单例模式的设计与作用
3.3.1 为什么要使用单例
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
案例一:处理资源访问冲突
在这个例子中,我们自定义实现了一个往文件中打印日志的 Logger 类。具体的代码实现如下所示:
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) { writer.write(message);
}
}
// Logger类的应用示例:
public class UserController {
private Logger logger = new Logger();
public void login(String username, String password) {
// ...省略业务逻辑代码...
logger.log(username + " logined!");
}
}
public class OrderController {
private Logger logger = new Logger();
public void create(OrderVo order) {
// ...省略业务逻辑代码...
logger.log("Created an order: " + order.toString());
}
}
在上面的代码中,我们注意到,所有的日志都写入到同一个文件 /var/log/app.log 中。
在UserController 和 OrderController 中,我们分别创建两个 Logger 对象。在 Web 容器的Servlet 多线程环境下,如果两个 Servlet 线程同时分别执行 login() 和 create() 两个函数,并且同时写日志到log.txt 文件中,那就有可能存在日志信息互相覆盖的情况。
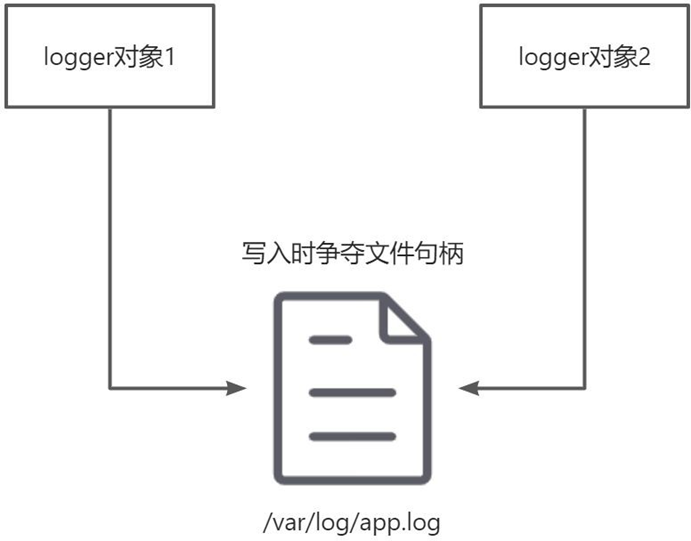
在类对象层面上锁解决争执问题
public class Logger {
private FileWriter writer;
public Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public void log(String message) {
synchronized(Logger.class) { // 类级别的锁
writer.write(mesasge);
}
}
除了使用类级别锁之外,实际上,解决资源竞争问题的办法还有很多。不过,实现一个安全可靠、无bug、高性能的分布 式锁,并不是件容易的事情。除此之外,并发队列(比如 Java 中的BlockingQueue)也可以解决这个问题:多个线程同时往并发队列里写日志,一个单独的线程负责将并发队列中的数据,写入到日志文件。这种方式实现起来也稍微有点复杂。
单例模式的解决思路就简单一些了。单例模式相对于之前类级别锁的好处是,不用创建那么多 Logger对象,一方面节省内存空间,另一方面节省系统文件句柄(对于操作系统来说,文件句柄也是一种资源,不能随便浪费)。
我们将 Logger 设计成一个单例类,程序中只允许创建一个 Logger 对象,所有的线程共享使用的这一个 Logger 对象, 共享一个FileWriter 对象,而 FileWriter 本身是对象级别线程安全的,也就避免了多线程情况下写日志会互相覆盖的问题。
public class Logger {
private FileWriter writer;
private static final Logger instance = new Logger();
private Logger() {
File file = new File("/Users/wangzheng/log.txt");
writer = new FileWriter(file, true); //true表示追加写入
}
public static Logger getInstance() {
return instance;
}
public void log(String message) {
writer.write(mesasge);
}
}
// Logger类的应用示例:
public class UserController {
public void login(String username, String password) {
// ...省略业务逻辑代码... Logger.getInstance().log(username + " logined!");
}
}
public class OrderController {
public void create(OrderVo order) {
// ...省略业务逻辑代码...
Logger.getInstance().log("Created a order: " + order.toString());
}
}
案例二:表示全局唯一类
public class StringUtils(){
public static String toUpperCase(){
}
public static String toLowerCase(){
}
}
从业务概念上,如果有些数据在系统中只应保存一份,那就比较适合设计为单例类。比如,配置信息类。在系统中,我们 只有一个配置文件,当配置文件被加载到内存之后,以对象的形式存在,也理所应当只有一份。
比如id生成器也很适合
import java.util.concurrent.atomic.AtomicLong;
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
//在初始化操作提前到类加载时完成
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() {
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
// IdGenerator使用举例
long id = IdGenerator.getInstance().getId();
3.3.2 如何实现一个单例
实现一个单例,需要关注的点有下面几个:
- 构造函数需要是 private 访问权限的,这样才能避免外部通过 new 创建实例;
- 考虑对象创建时的线程安全问题;
- 考虑是否支持延迟加载;
- 考虑 getInstance() 性能是否高(是否加锁)。
饿汉式
类加载时直接实例化单例对象
- 构造方法私有
- 内部持有自己的私有静态final对象
- 通过getInstance()返回唯一的实例
饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载(在真正用到 IdGenerator 的时候,再创建实例),从名字中我们也可以看出这一点。具体的代码实现如下所示:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() { return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要 加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。
如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能
(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实 现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。
如果实例占用资源多,按照 fail-fast的设计原则(有问题及早暴露),那我们也希望通过饿汉式在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如Java中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。
懒汉式
第一次调用时实例化对象(延迟加载)
有饿汉式,对应的,就有懒汉式。懒汉式相对于饿汉式的优势是支持延迟加载。具体的代码实现如下所示:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static synchronized IdGenerator getInstance() { if (instance == null) {
instance = new IdGenerator();
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
不过懒汉式的缺点也很明显,我们给 getInstance()这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低。量化一下的话,并发度是1,也就相当于串行操作了。而这个函数是在单例使用期间,一直会被调用。如果这个单例 类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致 性能瓶颈,这种实现方式就不可取了。
双重校验
道理我都懂,可是鬼才会这么写
饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。
在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance()函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。
具体的代码实现如下所示:
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance;
private IdGenerator() {}
public static IdGenerator getInstance() {
if (instance == null) {
synchronized(IdGenerator.class) { // 此处为类级别的锁
if (instance == null) {
instance = new IdGenerator();
}
}
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
网上有人说,这种实现方式有些问题。因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给instance之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。
要解决这个问题,我们需要给 instance 成员变量加上 volatile 关键字,禁止指令重排序才行。实际上,只有很低版本的Java才会有这个问题。我们现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new操作和初始化操作设计为原子操作,就自然能禁止重排序)
为什么需要两次判断if(instance==null)?
第一次校验: 由于单例模式只需要创建一次实例,如果后面再次调用getInstance方法时,则直接返回之前创建的实例, 因此大部分时间不需要执行同步方法里面的代码,大大提高了性能。如果不加第一次校验的话,那跟上面的懒汉模式没什 么区别,每次都要去竞争锁。
第二次校验: 如果没有第二次校验,假设线程t1执行了第一次校验后,判断为null,这时t2也获取了CPU执行权,也执行 了第一次校验,判断也为null。接下来t2获得锁,创建实例。这时t1又获得CPU执行权,由于之前已经进行了第一次校 验,结果为null(不会再次判断),获得锁后,直接创建实例。结果就会导致创建多个实例。所以需要在同步代码里面进行第二次校验,如果实例为空,则进行创建。
静态内部类
再来看一种比双重检测更加简单的实现方法,那就是利用 Java 的静态内部类。它有点类似饿汉式,但又能做到了延迟加载。具体是怎么做到的呢?我们先来看它的代码实现。
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private IdGenerator() {}
private static class SingletonHolder{
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
return id.incrementAndGet();
}
}
SingletonHolder 是一个静态内部类,当外部类 IdGenerator 被加载的时候,并不会创建
SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder才会被加载,这个时候才会创建instance。instance 的唯一性、创建过程的线程安全性,都由 JVM来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
枚举
枚举对象是单例的,一种对象只会在内存中保存一份。
基于枚举类型的单例实现。这种实现方式通过 Java枚举类型本身的特性,是最简单实现单例的方式,保证了实例创建的线程安全性和实例的唯一性。具体的代码如下所示:
public enum IdGenerator {
INSTANCE;
private AtomicLong id = new AtomicLong(0);
public long getId() {
return id.incrementAndGet();
}
public static void main(String[] args) {
IdGenerator instance = IdGenerator.INSTANCE;
System.out.println(instance.getId());
}
}
3.4 建造者模式的设计与作用
3.4.1 不用建造者有什么麻烦?
假设我们要自己开发一个RabbitMQ消息队列的客户端,有很多需要初始化的参数,你会怎么做?
/**
* 基于构造方法为属性赋值无法适用于灵活多变的环境,且参数太长很难使用
*/
public class RabbitMQClientSample1 {
private String host = "127.0.0.1";
private int port = 5672;
private int mode;
private String exchange;
private String queue;
private boolean isDurable = true;
int connectionTimeout = 1000;
private RabbitMQClientSample1(String host, int port , int mode, String exchange , String queue , boolean isDurable, int connectionTimeout){
this.host = host;
this.port = port;
this.mode = mode;
this.exchange = exchange;
this.queue = queue;
this.isDurable = isDurable;
this.connectionTimeout = connectionTimeout;
if(mode == 1){ //工作队列模式不需要设置交换机,但queue必填if(exchange != null){
throw new RuntimeException("工作队列模式无须设计交换机");
}
if(queue == null || queue.trim().equals("")){
throw new RuntimeException("工作队列模式必须设置队列名称");
}
if(isDurable == false){
throw new RuntimeException("工作队列模式必须开启数据持久化");
}
}else if(mode ==2){ //路由模式必须设置交换机,但不能设置queue队列
if(exchange == null || exchange.trim().equals("")){
throw new RuntimeException("路由模式请设置交换机");
}
if(queue != null){
throw new RuntimeException("路由模式无须设置队列名称");
}
}
//其他各种验证
}
public void sendMessage(String msg) {
System.out.println("正在发送消息:" + msg);
}
public static void main(String[] args) {
//面对这么多参数恶不恶心?
RabbitMQClientSample1 client = new RabbitMQClientSample1("192.168.31.210", 5672, 2, "sample-exchange", null, true, 5000);
client.sendMessage("Test");
}
}
我的天,这么多参数要死啊,还是改用set方法灵活赋值吧
public class RabbitMQClientSample2 {
private String host = "127.0.0.1";
private int port = 5672;
private int mode;
private String exchange;
private String queue;
private boolean isDurable = true;
int connectionTimeout = 20;
//让对象不可变
private RabbitMQClientSample2(){
}
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
public int getMode() {
return mode;
}
public void setMode(int mode) {
this.mode = mode;
}
public String getExchange() {
return exchange;
}
public void setExchange(String exchange) {
if(mode == 1){ //工作队列模式不需要设置交换机,但queue必填if(exchange != null){
throw new RuntimeException("工作队列模式无须设计交换机");
}
if(queue == null || queue.trim().equals("")){
throw new RuntimeException("工作队列模式必须设置队列名称");
}
if(isDurable == false){
throw new RuntimeException("工作队列模式必须开启数据持久化");
}
}else if(mode ==2){ //路由模式必须设置交换机,但不能设置queue队列
if(exchange == null || exchange.trim().equals("")){
throw new RuntimeException("路由模式请设置交换机");
}
if(queue != null){
throw new RuntimeException("路由模式无须设置队列名称");
}
}
this.exchange = exchange;
}
public String getQueue() {
return queue;
}
public void setQueue(String queue) {
if(mode == 1){ //工作队列模式不需要设置交换机,但queue必填
if(exchange != null){
throw new RuntimeException("工作队列模式无须设计交换机");
}
if(queue == null || queue.trim().equals("")){
throw new RuntimeException("工作队列模式必须设置队列名称");
}
if(isDurable == false){
throw new RuntimeException("工作队列模式必须开启数据持久化");
}
}else if(mode ==2){ //路由模式必须设置交换机,但不能设置queue队列
if(exchange == null || exchange.trim().equals("")){
throw new RuntimeException("路由模式请设置交换机");
}
if(queue != null){
throw new RuntimeException("路由模式无须设置队列名称");
}
}
this.queue = queue;
}
public boolean isDurable() {
return isDurable;
}
public void setDurable(boolean durable) {
isDurable = durable;
}
public int getConnectionTimeout() {
return connectionTimeout;
}
public void setConnectionTimeout(int connectionTimeout) {
this.connectionTimeout = connectionTimeout;
}
//没办法,必须增加一个额外的validate方法验证对象是否复合要求
public boolean validate(){
if(mode == 1){ //工作队列模式不需要设置交换机,但queue必填if(exchange != null){
throw new RuntimeException("工作队列模式无须设计交换机");
}
if(queue == null || queue.trim().equals("")){
throw new RuntimeException("工作队列模式必须设置队列名称");
}
if(isDurable == false){
throw new RuntimeException("工作队列模式必须开启数据持久化");
}
}else if(mode ==2){ //路由模式必须设置交换机,但不能设置queue队列
if(exchange == null || exchange.trim().equals("")){
throw new RuntimeException("路由模式请设置交换机");
}
if(queue != null){
throw new RuntimeException("路由模式无须设置队列名称");
}
}
return true;
//其他各种验证
}
public void sendMessage(String msg) {
System.out.println("正在发送消息:" + msg);
}
public static void main(String[] args) {
RabbitMQClientSample2 client = new RabbitMQClientSample2();
client.setHost("192.168.31.210");
client.setMode(1);
client.setDurable(true);
client.setQueue("queue");
client.validate();
client.sendMessage("Test");
}
}
利用SET方法虽然灵活,但是存在中间状态,且属性校验时有前后顺序约束,或者还需要构建额外的校验方法 并且SET方法破坏了“不可变对象”的密闭性
如何保障灵活组织参数,有可以保证不会存在中间状态以及基本信息不会对外泄露呢?
3.4.2 建造者模式是一个好选择
构建者模式的特点: 摆脱超长构造方法参数的束缚的同时也保护了”不可变对象“的密闭性
建造者模式的格式如下:
- 目标类的构造方法要求传入Builder对象
- Builder建造者类位于目标类内部且用static描述
- Builder建造者对象提供内置属性与各种set方法,注意set方法返回Builder对象本身
- Builder建造者类提供build()方法实现目标类对象的创建
Builder
public class 目标类(){
//目标类的构造方法要求传入Builder对象
public 目标类(Builder builder){
}
public 返回值 业务方法(参数列表){
//doSth
}
//Builder建造者类位于目标类内部且用static描述
public static class Builder(){
//Builder建造者对象提供内置属性与各种set方法,注意set方法返回Builder对象本身private String xxx ;
public Builder setXxx(String xxx) { this.xxx = xxx;
return this;
}
//Builder建造者类提供build()方法实现目标类对象的创建
public 目标类 build() {
//业务校验
return new 目标类(this);
}
}
}
/**
* 建造者模式进行优化
*/
public class RabbitMQClient {
private RabbitMQClient(Builder builder){
}
public void sendMessage(String msg) {
System.out.println("正在发送消息:" + msg);
}
public static class Builder {
private String host = "127.0.0.1";
private int port = 5672;
private int mode;
private String exchange;
private String queue;
private boolean isDurable = true;
private int connectionTimeout = 20;
public Builder setHost(String host) {
this.host = host;
return this;
}
public Builder setPort(int port) {
this.port = port;
return this;
}
public Builder setMode(int mode) {
this.mode = mode;
return this;
}
public Builder setExchange(String exchange) {
this.exchange = exchange;
return this;
}
public Builder setQueue(String queue) {
this.queue = queue;
return this;
}
public Builder setDurable(boolean durable) {
isDurable = durable;
return this;
}
public RabbitMQClient build() {
if(mode == 1){ //工作队列模式不需要设置交换机,但queue必填
if(exchange != null){
throw new RuntimeException("工作队列模式无须设计交换机");
}
if(queue == null || queue.trim().equals("")){
throw new RuntimeException("工作队列模式必须设置队列名称");
}
if(isDurable == false){
throw new RuntimeException("工作队列模式必须开启数据持久化");
}
}else if(mode ==2){ //路由模式必须设置交换机,但不能设置queue队列
if(exchange == null || exchange.trim().equals("")){
throw new RuntimeException("路由模式请设置交换机");
}
if(queue != null){
throw new RuntimeException("路由模式无须设置队列名称");
}
}
//其他验证
return new RabbitMQClient(this);
}
}
public static void main(String[] args) {
RabbitMQClient client = new RabbitMQClient.Builder()
.setHost("192.168.31.201").setMode(2).setExchange("test-exchange").build();
client.sendMessage("Test");
}
}
3.5 原型模式Prototype
3.5.1 概述
定义
用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型相同或相似的新对象。在这里,原型实例指定了 要创建的对象的种类。用这种方式创建对象非常高效,根本无须知道对象创建的细节。

优点
- Java 自带的原型模式基于内存二进制流的复制,在性能上比直接 new 一个对象更加优良。
- 可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份,并将其状态保存起来,简化了创建对象的过 程,以便在需要的时候使用(例如恢复到历史某一状态),可辅助实现撤销操作。
缺点
- 需要为每一个类都配置一个 clone 方法
- clone 方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违背了开闭原则。
- 当实现深克隆时,需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对 应的类都必须支持深克隆,实现起来会比较麻烦。因此,深克隆、浅克隆需要运用得当。
3.5.2 代码实现
浅克隆与深克隆: 原型模式实现对象克隆有两种形式:浅克隆与深克隆
浅克隆: 创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内 存地址。

public class Car {
public String number;
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
}
被复制的对象需要实现Clonable接口与clone()方法
public class Employee implements Cloneable{
private String name;
private Car car;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
//重写Clone方法@Override
protected Object clone() throws CloneNotSupportedException {
System.out.println("正在复制Employee对象");
return super.clone();
}
}
public class App {
public static void main(String[] args) throws CloneNotSupportedException {
Employee king = new Employee();
king.setName("King"); Car car = new Car();
car.setNumber("FBW 381"); king.setCar(car);
Employee cloneKing = (Employee)king.clone();
System.out.println("King == CloneKing:" + (king == cloneKing));
System.out.println("King.car == CloneKing.car:" + (king.getCar() == cloneKing.getCar()));
}
}
执行结果
正在复制Employee对象
King == CloneKing:false
King.car == CloneKing.car:true
深克隆
创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
Car代码完全相同,省略
基于Json实现对象深度Clone,不再需要实现Clonable接口与clone()方法
import com.google.gson.Gson;
public class Employee{
private String name;
private Car car;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
//基于JSON实现深度序列化
public Employee deepClone(){
Gson gson = new Gson();
String json = gson.toJson(this);
System.out.println(json);
Employee cloneObject = gson.fromJson(json, Employee.class);
return cloneObject;
}
}
public class App {
public static void main(String[] args) throws CloneNotSupportedException {
Employee king = new Employee();
king.setName("King"); Car car = new Car();
car.setNumber("FBW 381"); king.setCar(car);
Employee cloneKing = (Employee) king.deepClone();
System.out.println("King == CloneKing:" + (king == cloneKing));
System.out.println("King.car == CloneKing.car:" + (king.getCar() == cloneKing.getCar()));
}
}
{"name":"King","car":{"number":"FBW 381"}} King == CloneKing:false
King.car == CloneKing.car:false
3.5.3 代码实现应用场景
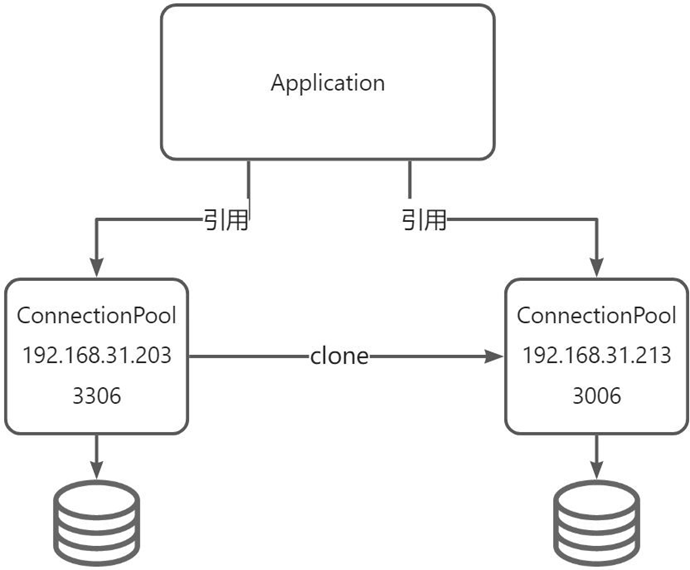
- 对象之间相同或相似,即只是个别的几个属性不同的时候。
- 创建对象成本较大,例如初始化时间长,占用CPU太多,或者占用网络资源太多等,需要优化资源。 - 创建一个对象需要繁琐的数据准备或访问权限等,需要提高性能或者提高安全性。
- 系统中大量使用该类对象,且各个调用者都需要给它的属性重新赋值。