目录
- 一、引言
- 二、 统一语言Ubiquitous Language
- 三、 三个阶段(战略、战术、实现)
- 阶段1:战略设计阶段
- 阶段2:战术设计阶段
- 阶段3:技术实现阶段
- 四、限界上下文Bounded Context
- 五、上下文映射Context Map
- 防腐层Anti-Corruption Layer
- 开放主机服务Open Host Service
- 发布者-订阅者
- 共享内核Shared Kernel
- 六、领域模型大杂烩
- 七、微服务、限界上下文、聚合等的关系
一、引言
领域(Domain),即对应特定行业的业务场景(业务概念、业务概念之间的联系、业务流程),也可简单理解为业务,如电商业务、医疗业务、社保业务、政府业务、车厂业务等。
领域驱动设计(Domain Driven Design,简称DDD),即通过对特定行业的业务场景的分析 来驱动(转换、产生) 软件的架构设计与代码实现,而这里的软件架构设计与是实现即可理解为 微服务的拆分 与 面向对象(封装、继承、多态、高内聚低耦合等)的设计与编程。领域驱动设计,可以简单理解将业务逻辑转换为代码实现一种方法论。
这里提到的面向对象编程,即真正的面向对象,
而非我们后端开发常使用SpringMVC的分层架构时贫血模型:
- service几乎包含全部逻辑实现
- entity对象直接对应数据库table,仅包含属性,没有业务逻辑
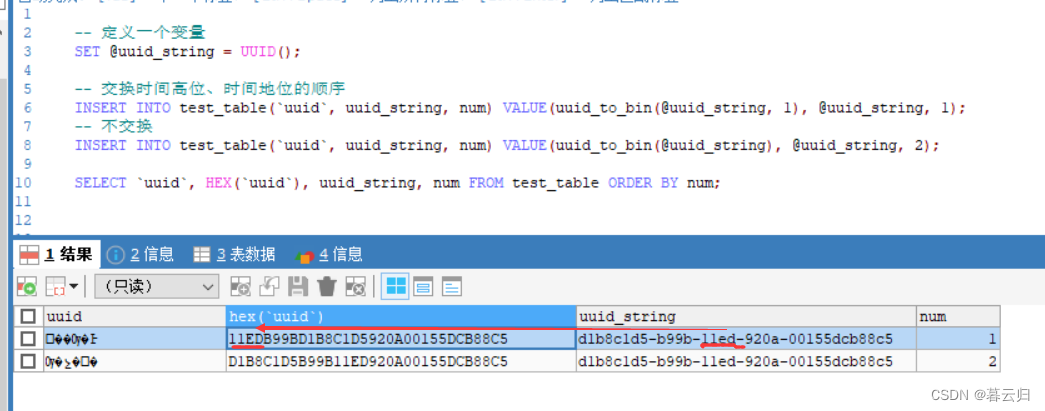
学生时代老师讲的面向对象是将现实世界中的人、物、逻辑实体等映射为OOP中的类,现实中的物体的状态、操作等映射为类的属性和方法,而随着近些年MVC模式的流行,entity类只有属性(getter/setter、贫血模式),而所有的操作都放在service层实现,通常会先进行数据库的设计,而后将数据库中的table直接映射为entity,后续的编码都是围绕这个强关联数据库table定义的entity进行展开,只不过是使用了面向对象的编程语言,但并不是真正的面向对象的编程思想,倒更像是面向数据库编程,也可以叫做数据模型驱动设计,如此若切换底层数据库实现,则涉及entity的相关代码都需要修改。不过用惯了MVC分层开发模式,写起代码、维护代码时也还是很顺手的,那为什么还要切换到领域驱动设计呢?
使用领域驱动设计,我能想出的理由如下:
- DDD(限界上下文)有助于微服务的划分
- DDD将业务逻辑、技术实现进行分离(六边形架构思想),核心业务逻辑实现保持不变,可以自由切换底层技术实现
- Rest切换gRPC、底层存储MySql切换ES、RabbitMq切换Kafka、切换第三方云存储服务等
- 最大限度的领域核心代码的复用
- DDD是面向对象编程经过合理重构后一定会抵达的终点
- DDD中包括分层架构、六边形架构(内部业务、外部技术)等
- 高内聚、低耦合用到极致
- 即便不使用DDD,但是其中的一些架构思想(统一语言Ubiquitous Language、防腐层ACL、依赖注入DI、事件驱动EDA等)还是很值得借鉴的
在学习DDD的过程中你或许会发现DDD中提到的架构思想正是我们平时开发时常用的方式,只不过DDD中给出了一个专有的称呼,那并不奇怪,大家的目的都是一样的,那就是更好的软件的设计,我们都在为了这同一个目的不断进行摸索,如果发现我们的方式和DDD有重叠,那说明我们也许走在正确的道路上,殊途同归…
但是DDD的使用还是具有相当高的门槛的:
- DDD中的术语多到爆炸,对于刚接触DDD的小白并不友好
- 相较于MVC分层架构(如SpringMVC),DDD并没有较成熟的代码实现框架
- 相较于MVC各层代码职责分明,DDD中分层设计(洋葱架构、整洁架构、清晰架构等)、对象及接口设计有一定上手难度
- DDD中关于限界上下文的划分并没有绝对的标准(事件风暴、用例场景分析、全凭经验等)
现阶段我的结论就是:
- 我不会轻易使用DDD,但我会借鉴DDD中的架构思想
- 可以在团队内部先选择个别内部项目使用DDD,熟悉DDD思想并逐步积累DDD架构落地经验
- 客户方有明确要求使用DDD开发方式的我会使用
- 待有一天DDD真正成熟了(成为业内标准了)或者 我们自己在使用DDD尝到甜头了,再大面积切换DDD
接下来开始本文的重点,依次介绍DDD的相关概念。
二、 统一语言Ubiquitous Language
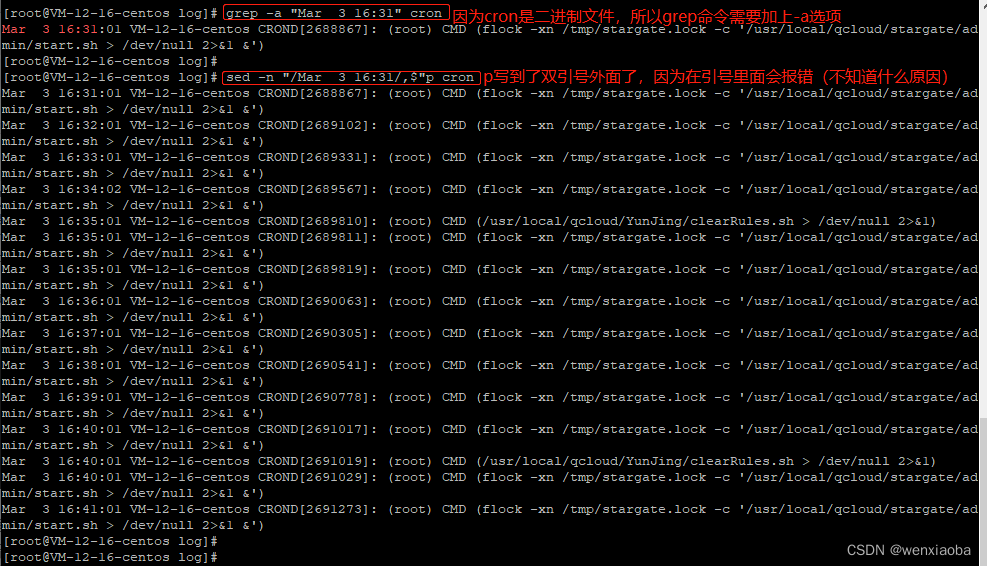
业务和软件实现间统一语言,即从业务需求中提炼出统一语言(统一的词汇表),在业务方(或 领域专家)和开发团队间达成一致的理解。需给出领域术语的英文单词描述,之后设计与编码需使用该统一词汇。如此业务方、开发团队间通过统一语言进行沟通,降低了彼此的沟通成本,也加深了团队对领域的理解,看到代码中的术语也可以做到见名识义。无论是否使用DDD,在开发团队间及内部实行统一语言都是非常有益处的。
关于统一语言的具体实践可参见下图:
三、 三个阶段(战略、战术、实现)
领域驱动设计可整体划分为3个阶段:
阶段1:战略设计阶段
- 划分 子域
- 核心域:决定产品和公司核心竞争力的子域,它是业务成功的主要因素和公司的核心竞争力。
- 通用域:没有太多个性化的诉求,同时被多个子域使用的通用功能的子域。
- 支撑域:既不包含决定产品和公司核心竞争力的功能,也不包含通用功能的子域。
- 核心领域即为重要的领域,通用域、支撑域名起到辅助核心领域的作用
- 核心领域可由更好的团队开发、付出更高的成本,通用域、支撑域可适当降低标准(或者 购买通用服务、外包等)
- 划分 限界上下文
- 针对各自子领域 划分 限界上下文Bounded Context、上下文映射Context Map
- 后续可映射到 微服务的划分、服务间的依赖调用
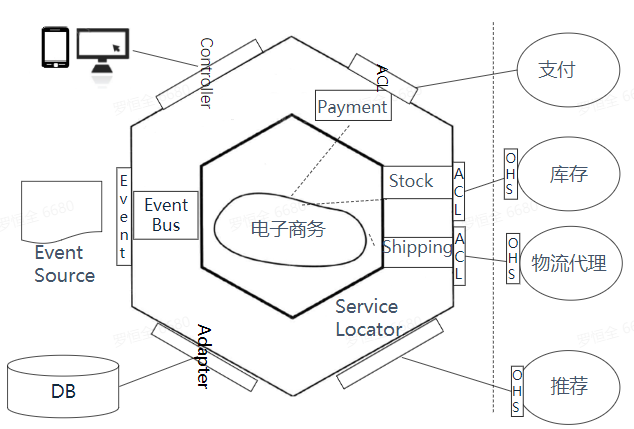
- 设计 六边形架构
- 每个限界上线文即对应一个六边形
- 上线文映射即为六边形间的交互(上下游、ACL、OHS、EDA等)
- 六边形中心为核心业务逻辑,外层即为技术实现
注:以下三张图示仅作为图例形式展示,并不存在对应关系。
子域及限界上下文划分如下图:

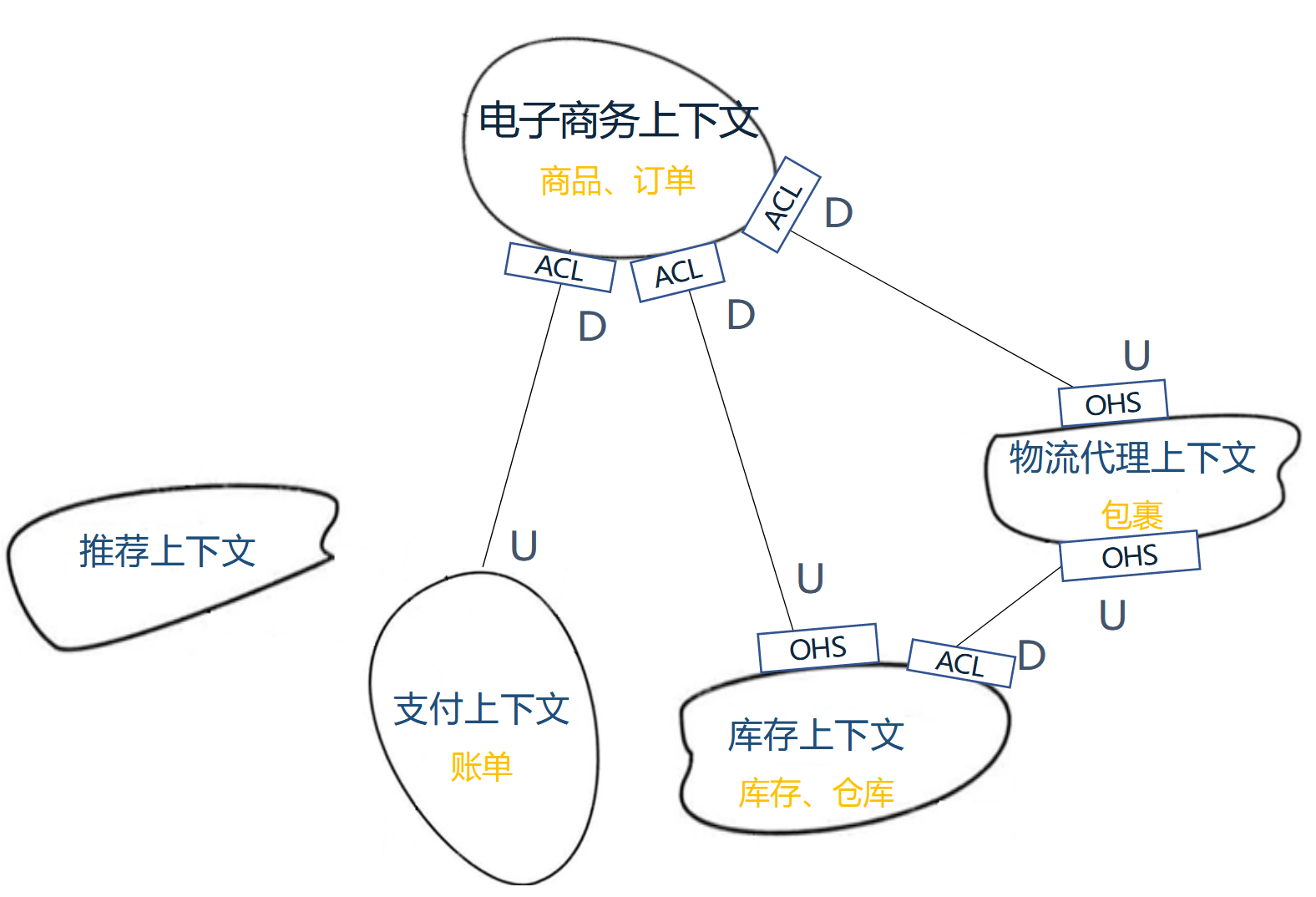
限界上下文映射如下图:
一个限界上下文对应的六边形架构如下图:
阶段2:战术设计阶段
- 针对单个限界上下文进行战术设计
- 战术阶段围绕领域模型进行设计
- 常用的领域模型:聚合、聚合根、实体、值对象、领域事件、领域服务、应用服务、仓库、ACL等
- 可结合类图进行设计
阶段3:技术实现阶段
- 使用DDD分层架构,隔离业务逻辑和技术实现,确保最核心的领域层不依赖其他层,反过来让领域之外的代码依赖领域代码,降低了技术升级带来的影响。
- 可自定义DDD领域模型接口(不同领域模型实现对应的接口) 。
- 实现领域模型:聚合根、实体、值对象、领域事件、领域服务、应用服务、仓库、ACL等
- 合理使用DDD架构模式:DDD分层、防腐层ACL、开发主机服务OHS、事件驱动架构EDA、命令查询职责分离CQRS等。
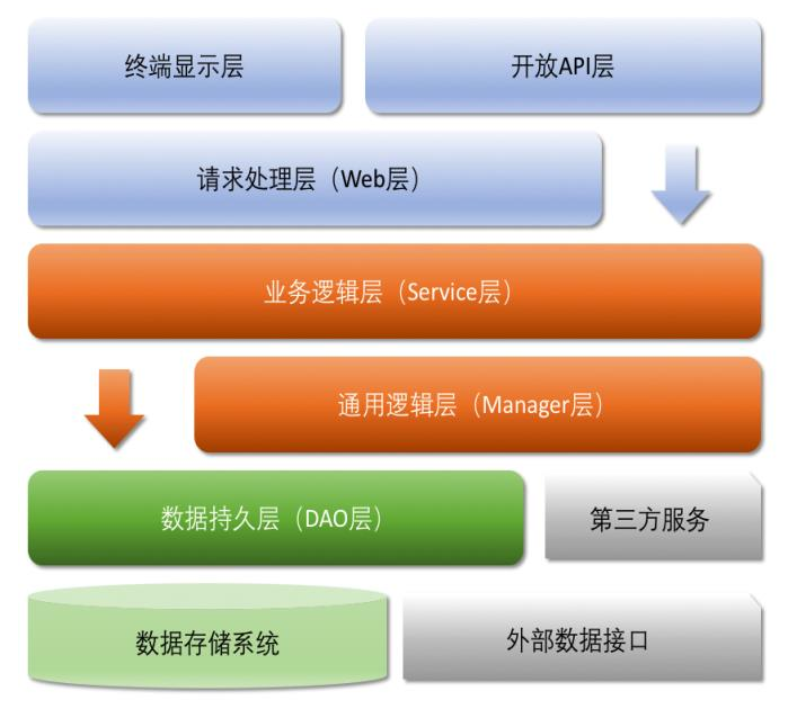
关于DDD分层架构可参见六边形架构、洋葱架构、整洁架构、清晰架构的思想,下图为清晰架构分层:
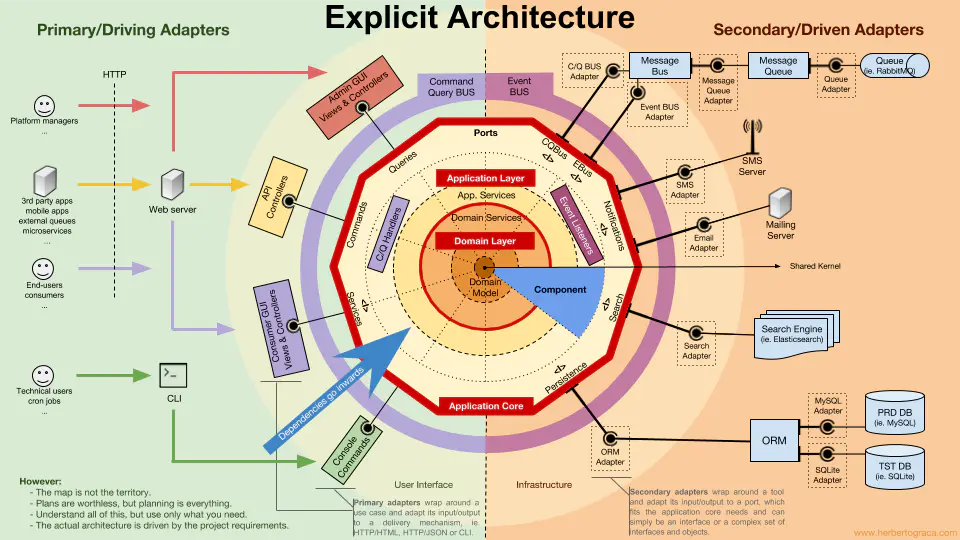
具体落到代码上分层架构可参见下图:
注:
D3S(DDD with SpringBoot)为本作者使用DDD过程中开发的框架,后续完善后会公开源码。

综上,
战略设计阶段:宏观划分各领域 → 领域内划分限界上下文,定义上下文之间的关系
战术设计阶段:针对每个限界上下文进行分析,识别领域模型,定义合适的领域模型
技术实现阶段:通过分层架构实现编码,并验证领域模型的合理性,必要时重新回到前面步骤重构领域模型。
四、限界上下文Bounded Context
可以将Bounded Conext拆开来理解,
上下文Context,可推想到语义上下文,例如下面中的这两个“我去”:
小明走路低头看手机,不小心踩进了水坑里,生气地说了一句:“我去!”
小明妈妈问他去不去大姨家,小明回答:“我去。”
都是“我去”但是表示的是不同的意思,需要结合这句话的上线文来理解。
上线文亦可关联到领域(业务场景)上下文,例如下面中的这两个“商品”:
茶城的“商品”
汽车4S店的“商品”
同样的“商品”在不同的领域上下文可以是完全不相同的东西,例如茶叶、汽车,
甚至在同一领域的不同阶段,对应同一事物的的关注点也可能不尽相同,
例如4S点销售人员关注汽车的价格、配置等,而售后维修人员关注汽车的保养周期、零配件等。
所以需要通过领域下文来区分领域模型的含义及相应的关注点。
边界Bounded,即领域的边界,上下文的边界,如售前和售后、订单和商品等。边界的终极奥义就是高内聚低耦合,边界内高内聚,不同边界间低耦合(限界上下文仅通过聚合根暴露引用)。边界划分即是一种分而治之的手段,隔离关注点,边界内自治(边界内维持领域模型的一致性和完整性),降低了系统的实现复杂度,各自边界内仅需关注各自的核心业务,边界间通过预先定义好的接口进行交互。
内聚:度量 一个模块内部各个元素 彼此结合的紧密程度。
耦合:度量 模块之间 互相连接的紧密程度。
关于限界上线文的划分,可以从如下三个层面展开:
- 业务边界(领域逻辑层面)
- 具体的业务逻辑边界
- 例如妇产科、儿科、麻醉科等,又或者 人力资源、财务、生产等
- 工作边界(团队合作层面)
- 康威定律,组织结构决定软件结构
- 例如公司开发团队分为商品部、订单部、售后部,那这个三个维度就可以独立为单独的限界上线文。
- 康威定律,组织结构决定软件结构
- 应用边界(技术实现层面) - 出于以下维度可考虑将其独立为单独的限界上下文
- 性能要求(高并发、实时…)
- 功能重用(或者 通用功能)
- 第三方服务集成
- 遗留系统
五、上下文映射Context Map
领域驱动设计通过上下文映射Context Map来表达限界上下文间的协作(依赖、调用、通信)关系。可以参考微服务架构下,服务很难独立存在,往往需要多个微服务间协同工作,协同即产生服务间的相关依赖调用,上下文映射即对应服务间的依赖关系。两个限界上下文间的关系是有方向的:
上游Upstream:上游影响下游(可参考河流上游产生的变化会影响到下游,如上游水质不好必定污染下游)。
下游Downstream:下游依赖上游,可理解为下游向上游发起调用。
如果限界上下文间的依赖(服务间通信)不可避免,可以通过如下几种方式降低上下文间的耦合:
防腐层Anti-Corruption Layer
防腐层即隔离层的意思,加入新的一层将核心业务和易变的、不稳定的依赖(其他上线文、其他服务、底层技术平台、第三方服务等)进行隔离,保证核心业务层的稳定。核心业务即为领域层,防腐层即为领域层内定义的接口(后文称为ACL接口),领域层通过这些ACL接口访问其他上下文、其他服务等,接口定义不变,则核心领域逻辑实现不变。而ACL接口的实现在基础设施层完成,基础设施层实现ACL接口,与具体的持久化(Mysql、Redis等)、Rpc(Rest、gRPC、Dubbo等)、Mq(RabbitMq、Kafka等)、第三方平台等打交道。
开放主机服务Open Host Service
开放主机服务(后文简称文OHS)就是定义公开的服务协议(通信的方式、传递消息的格式)。OHS可视为一种承诺,保证开放的服务不会轻易发生变化。公开的服务应该力求标准化,例如采用Rest、gRPC等。
发布者-订阅者
即多个限界上线文(或者 微服务间)采用消息中间件进行通信,通信过程中传递的消息即对应领域事件DomainEvent,需要事先约定好事件的的格式与数据。一个限界上下发布事件,其他多个限界上线文订阅事件,发布者和订阅者通过消息中间件进行解耦,通常用于异步非实时的业务场景。
共享内核Shared Kernel
若多个上线文间依赖共同的子集,可将该共同的子集抽取为多个上线文间的共享内核。分离出来的共享内核应该由上游团队进行维护,需要处理好与下游的团队协作。共享内核可以作为单独的Maven模块,发布到Maven私服上,由需要的下游团队进行依赖,又或者同一个服务内部存在多个限界上下文,则可在服务内部以 模块 或者 包 的形式单独维护共享内核。
关于限界上下文之间的映射关系,更多说明如下:
- 防腐层(Anticorruption Layer):一个上下文通过一些适配和转换与另一个上下文交互。
- 开放主机服务(Open Host Service):定义一种协议来让其他上下文来对本上下文进行访问。
- 发布语言(Published Language):通常与OHS一起使用,用于定义开放主机的协议。
- 共享内核(Shared Kernel):两个上下文依赖部分共享的模型。
- 客户方-供应方开发(Customer-Supplier Development):上下文之间有组织的上下游依赖。
- 遵奉者(Conformist):下游上下文只能盲目依赖上游上下文。
- 合作关系(Partnership):两个上下文紧密合作的关系,一荣俱荣,一损俱损。
- 大泥球(Big Ball of Mud):混杂在一起的上下文关系,边界不清晰。
- 另谋他路(SeparateWay):两个完全没有任何联系的上下文。
六、领域模型大杂烩
| 名称 | 定义 |
|---|---|
| 实体Entiy | 实体一般对应业务对象, 具有唯一ID、属性(值对象)和业务行为。 |
| 值对象Value Object | 值对象主要为属性的集合(对应一个 或 多个属性),对实体Entity的状态、特征进行语义化的描述(不是单纯的编程语言类型如string、long,而是语义的UserName、PhoneNo、ID等),通常在值对象构造函数参数列表中接收多个属性如constructor(attr1, attr2)并对多个属性进行基本的验证(非空、格式、长度等),值对象通常作为实体Entity的属性。 |
| 聚合Aggregate | 聚合是多个实体、值对象的逻辑边界,这些实体和值对象在业务和逻辑上紧密关联。 |
| 聚合根Aggregate Root | 聚合内仅选择一个实体Entity作为聚合根,聚合内仅允许通过聚合根暴露访问,聚合根是聚合内数据访问、数据修改和持久化的基本单元,聚合根需保证聚合内业务的完整性和一致性。 |
| 领域原语Domain Primitive | 类似于值对象ValueObject,强调将 1)隐性的概念、隐性的上下文 => 显性化、 2)封装多对象行为。 |
| 领域事件Domain Event | 表示领域中发生的重要事件(如采用事件风暴方法则对应事件风暴中的领域事件),事件发生后通常会导致进一步的业务操作,或者在系统其他地方引起反应。 |
| 领域服务Domain Service | 领域服务没有任何属性或数据,只有一个领域行为或动作,不适合放在任何实体内的逻辑行为即可封装为领域服务。 |
| 应用服务Application Service | 通常对应具体的业务场景,通过编排聚合(聚合根)、领域服务、资源库、领域事件、ACL来完成 |
| 资源库Repository | 负责聚合的加载、添加、修改、删除,领域模型的持久化抽象,定义在领域层且仅和领域对象打交道,不依赖具体ORM框架。 |
| 工厂Factory | 工厂负责复杂聚合对象的创建 |
| 数据转换器 DataAssembler DataMapper DataConvertor | 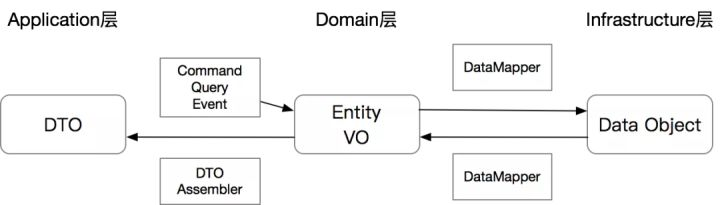 |
| 防腐层ACL 端口Port 网关Gateway 外观Facade | 接口隔离层 |
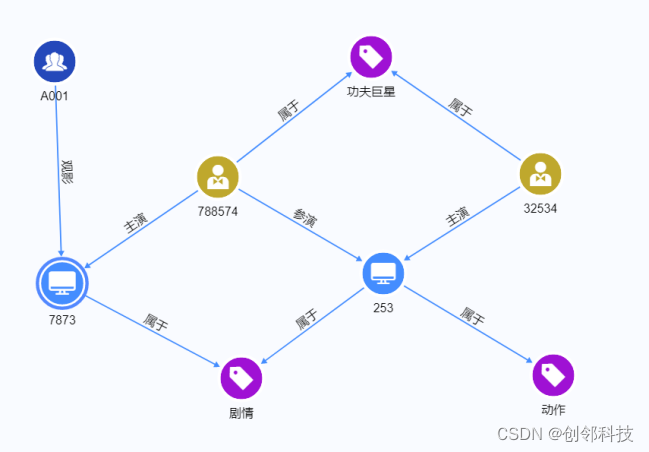
七、微服务、限界上下文、聚合等的关系
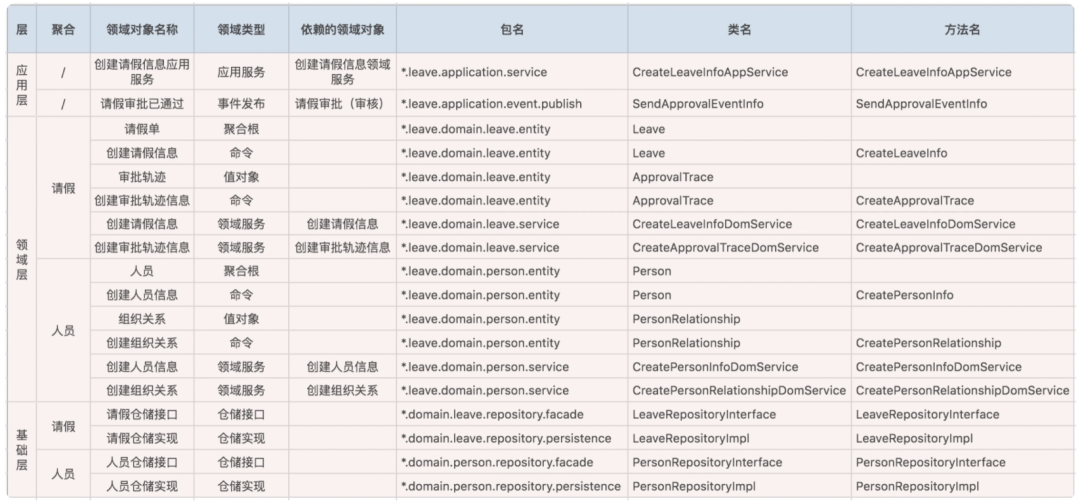
关于微服务、限界上下文、聚合等的关系可见下图:
关于跨实体、跨聚合、跨限界上下文的业务编排可参见如下说明:
-
同一限界上线文内
- 业务逻辑 跨多个实体,通过 领域服务实现
- 业务逻辑 跨多个聚合,通过 应用服务编排、领域事件来实现 不同限界上下文
- 业务逻辑 跨多个限界上线文,通过 应用服务编排 ACL、领域事件来实现