hadoop调优
1 HDFS核心参数
1.1 NameNode内存生产配置
1.1.1 NameNode内存计算
每个文件块大概占用150byte,如果一台服务器128G,能存储的文件块如下
128 (G)* 1024(MB) * 1024(KB) * 1024(Byte) / 150 Byte = 9.1 亿
1.1.2 Hadoop2.x
在Hadoop2.x中,NameNode内存默认2000m,如果服务器内存4G,NameNode内存可以配置3G
在hadoop-env.sh中配置
HADOOP_NAMENODE_OPTS=-Xmx3072m
1.1.3 Hadoop3.x
在Hadoop3.x中,NameNode和DataNode占用的内存都是自动分配的,并且相等
可以自己进行更改

配置hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -
Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS
-Xmx1024m"
1.2 NameNode心跳并发配置
NameNode有一个工作线程池,用来处理不同的DataNode的并发心跳以及客户端并发的元数据操作
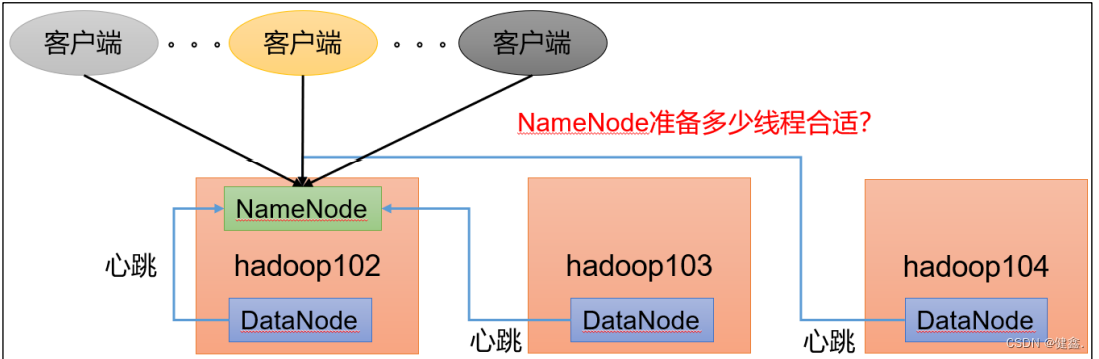
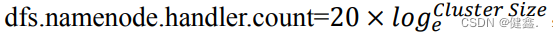
默认值为10
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
1.3 回收站配置
回收站可以蒋删除的文件在不超时的情况下恢复原数据,起到防止误操作、备份的作用
1.3.1 工作机制
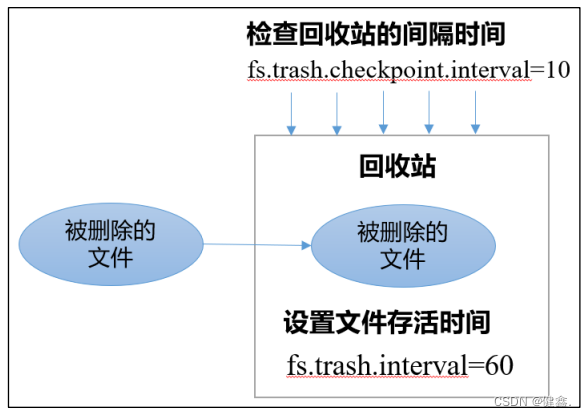
1.3.2 参数说明
- 默认值fs.trash.interval = 0,表示禁用回收站
- fs.trash.checkpoint.interval = 0,检查回收站的间隔时间。该值为0,表示和fs.trash.interval 参数相同
- 要求 fs.trash.checkpoint.interval <= fs.trash.interval。
1.3.3 启动回收站
修改core-site.xml,配置垃圾回收时间为1min
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
通过网站删除的文件不会进入到回收站
经过程序删除的文件不会经过回收站,需要调用moveToTrash()才能进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
在命令行使用hadoop fs -rm命令删除的文件才会走回收站
2 HDFS集群压测
HDFS的读写性能只要收到网络和磁盘的影响
2.1 HDFS写性能
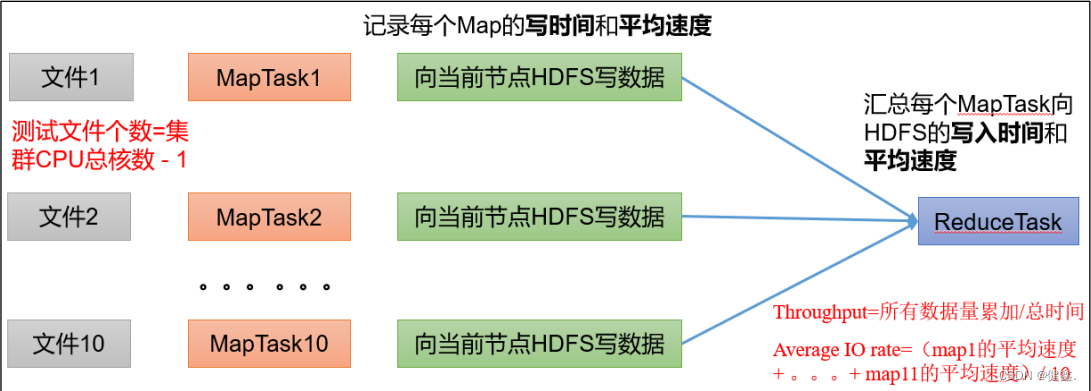
向HDFS写10个128M文件
[jx@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-clientjobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -
fileSize 128MB
2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb
09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05
2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
Number of files : 生成的MapTask的数量
Total MBytes processed : 单个map处理文件的大小
Throughput mb/sec:单个mapTask的吞吐量
计算方式:处理总文件的大小 / 每个mapTask写数据的时间累加
集群整体的吞吐量 : 生成的mapTask数量 * 单个mapTask的吞吐量
Average IO rate mb/sec:平均每个mapTask的吞吐量
如果测试速度远小于网络,可以考虑增加固态硬盘或者增加磁盘个数
3 HDFS多目录配置
3. 1 NameNode多目录配置
为了提高HDFS的可靠性和性能,可以在NameNode上配置多个目录来存储NameNode的元数据信息。每个目录存放内容相同,增加了可靠性
配置NameNode多目录的步骤:
- 创建多个目录:在NameNode所在的机器上创建多个目录用于存储NameNode元数据信息。可以在本地磁盘、网络存储设备或者分布式文件系统上创建这些目录。
- 设置hdfs-site.xml文件:在hdfs-site.xml文件中添加以下配置:
<property>
<name>dfs.namenode.name.dir</name>
<value>/path/to/first/directory,/path/to/second/directory</value>
</property>
其中,/path/to/first/directory和/path/to/second/directory是创建的多个目录的路径,多个目录之间用逗号分隔。
-
将元数据信息复制到新目录:在NameNode启动之前,需要将原来的元数据信息复制到新目录中。可以使用命令
hdfs dfsadmin -refreshNodes来刷新NameNode节点,并将元数据信息复制到新目录中。 -
启动NameNode:启动NameNode后,它将自动读取hdfs-site.xml文件中的配置,并将元数据信息存储到多个目录中。
3.2 DataNode多目录配置
DataNode 可以配置成多个目录,每个目录存储的数据不一样
配置DataNode多目录的步骤:
- 创建多个目录:在DataNode所在的机器上创建多个目录用于存储数据块。可以在本地磁盘、网络存储设备或者分布式文件系统上创建这些目录。
- 设置hdfs-site.xml文件:在hdfs-site.xml文件中添加以下配置:
phpCopy code<property>
<name>dfs.datanode.data.dir</name>
<value>/path/to/first/directory,/path/to/second/directory</value>
</property>
其中,/path/to/first/directory和/path/to/second/directory是创建的多个目录的路径,多个目录之间用逗号分隔。
- 启动DataNode:启动DataNode后,它将自动读取hdfs-site.xml文件中的配置,并将数据块存储到多个目录中。
3.3 磁盘间数据均衡
在HDFS中,数据块默认会被存储在集群中的不同DataNode上,以提高数据的可靠性和性能。但是,由于不同DataNode的磁盘容量和使用情况不同,可能会导致磁盘空间不平衡的问题,进而影响HDFS的性能。为了解决这个问题,可以使用Hadoop提供的数据均衡工具来平衡不同DataNode的磁盘空间使用情况。
下面是使用数据均衡工具来平衡不同DataNode的磁盘空间使用情况的步骤:
- 启用数据均衡工具:在hdfs-site.xml文件中添加以下配置,启用数据均衡工具:
<property>
<name>dfs.balancer.enabled</name>
<value>true</value>
</property>
- 配置数据均衡工具:可以在命令行中使用hdfs balancer命令配置数据均衡工具。例如,可以使用以下命令来配置数据均衡工具,使得每个DataNode的磁盘空间使用率不超过90%:
Copy code
hdfs balancer -threshold 90
- 运行数据均衡工具:可以在命令行中使用hdfs balancer命令来运行数据均衡工具。例如,可以使用以下命令来运行数据均衡工具:
Copy code
hdfs balancer
数据均衡工具将自动检测集群中的不同DataNode的磁盘空间使用情况,并移动数据块来平衡磁盘空间使用情况。
4 HDFS集群的扩容
4.1 添加白名单
HDFS白名单是指在HDFS中配置一组允许访问HDFS文件系统的IP地址列表,其他IP地址将被禁止访问。这种配置可以增强HDFS集群的安全性,防止未经授权的访问。
HDFS白名单的配置可以通过以下步骤实现:
-
编辑hdfs-site.xml文件,添加以下配置:
code<property> <name>dfs.hosts</name> <value>/etc/hadoop/conf/dfs.hosts</value> </property> -
在dfs.hosts文件中列出允许访问HDFS文件系统的IP地址列表,格式如下:
hadoop102 hadoop103 hadoop104 -
重启HDFS服务,使配置生效。
在HDFS白名单配置生效后,只有列出的IP地址可以访问HDFS文件系统,其他IP地址将被禁止访问。需要注意的是,dfs.hosts文件必须在所有的DataNode节点和NameNode节点上都存在,否则HDFS将无法启动。
4.2服务器间数据均衡
数据均衡是指在分布式存储系统中,通过重新分配存储节点之间的数据块来平衡不同节点之间的数据负载,以提高存储系统的性能和可靠性。Hadoop自带了数据均衡机制,当某个节点的数据负载过高或过低时,会自动将数据块从一个节点移动到另一个节点以实现负载均衡。
以下是Hadoop中常用的数据均衡方法:
- 周期性数据均衡:Hadoop默认情况下会每隔一段时间(默认为一周)对数据进行均衡。当数据节点之间的负载差异超过一定的阈值时,Hadoop会自动启动数据均衡过程。
- 手动数据均衡:管理员也可以手动启动数据均衡过程,可以通过hadoop dfsadmin -balancer命令来手动触发数据均衡。该命令将重新分配数据块,使得所有节点之间的负载均衡。
- 配置数据均衡策略:Hadoop中还提供了配置数据均衡策略的方法。例如,可以配置阈值,当负载差异超过阈值时触发数据均衡;可以配置最大移动数据块数量,以避免数据均衡过程过于耗时等。
需要注意的是,数据均衡会占用网络带宽和磁盘IO资源,并且在数据均衡过程中,Hadoop集群的性能可能会受到影响。因此,在进行数据均衡时,需要根据集群的负载情况和运行时间进行调度和计划,以确保数据均衡过程对Hadoop集群的影响最小。
由于 HDFS 需要启动单独的 Rebalance Server 来执行 Rebalance 操作,所以尽量 不要在 NameNode 上执行 start-balancer.sh,而是找一台比较空闲的机器。
4.3 黑名单退役服务器
,黑名单退役服务器是指已经从集群中移除的服务器或节点。通常,当一个服务器或节点出现故障或需要升级时,管理员会将其加入黑名单并从集群中移除。这样可以避免故障节点对整个集群造成影响,同时也可以保证集群的稳定性和高可用性。
对于黑名单退役服务器中的数据,Hadoop提供了多种方式来处理:
- 数据重复存储:管理员可以通过配置副本数来实现数据的冗余存储。如果黑名单退役服务器上的数据已经有副本存储在其他服务器上,那么数据不会丢失。Hadoop会自动将数据块复制到其他服务器上,以保证数据的可靠性和可用性。
- 数据迁移:如果黑名单退役服务器上的数据没有副本存储在其他服务器上,那么管理员需要手动将数据迁移到其他服务器上。可以使用hadoop fs -get命令将数据下载到本地,然后使用hadoop fs -put命令将数据上传到其他服务器。
- 数据删除:如果黑名单退役服务器上的数据已经没有用处,可以使用hadoop fs -rm命令将其删除。删除数据之前需要进行备份,以免误删造成数据丢失。
5 HDFS 存储优化
5.1 纠删码
5.1.1 纠删码原理
HDFS纠删码是一种数据保护机制,通过在数据块之间添加冗余信息来提高数据的可靠性和可用性。在HDFS中,将原始数据分割成多个数据块,并在这些数据块之间添加冗余信息以保护数据的完整性。
与传统的数据备份方式相比,纠删码具有更高的存储效率和更好的可靠性。它可以将原始数据切分成多个数据块,然后通过添加冗余信息来保护数据的完整性。与备份方式相比,纠删码可以在保护数据的同时减少数据存储的成本。
HDFS纠删码可以提高数据的可靠性和可用性,同时也可以减少数据存储的成本。但是,它也会增加数据处理的复杂度和计算成本。在使用HDFS纠删码时,需要根据具体应用场景进行选择,并合理配置纠删码参数以达到最佳的性能和效果。
5.1.2 纠删码策略
RS-3-2-1024k::使用 RS 编码,每 3 个数据单元,生成 2 个校验单元,共 5 个单元,只要有任意的 3 个单元存在,就可以得到原始数据
RS-10-4-1024k:使用 RS 编码,每 10 个数据单元(cell),生成 4 个校验单元,共 14 个单元,只要有任意的 10 个单元存在),就可以得到原始数据
XOR-2-1-1024k:使用 XOR 编码(速度比 RS 编码快),每 2 个数据单元,生成 1 个校 验单元,共 3 个单元,只要有任意的 2 个单元存在,就可以得到原始数据
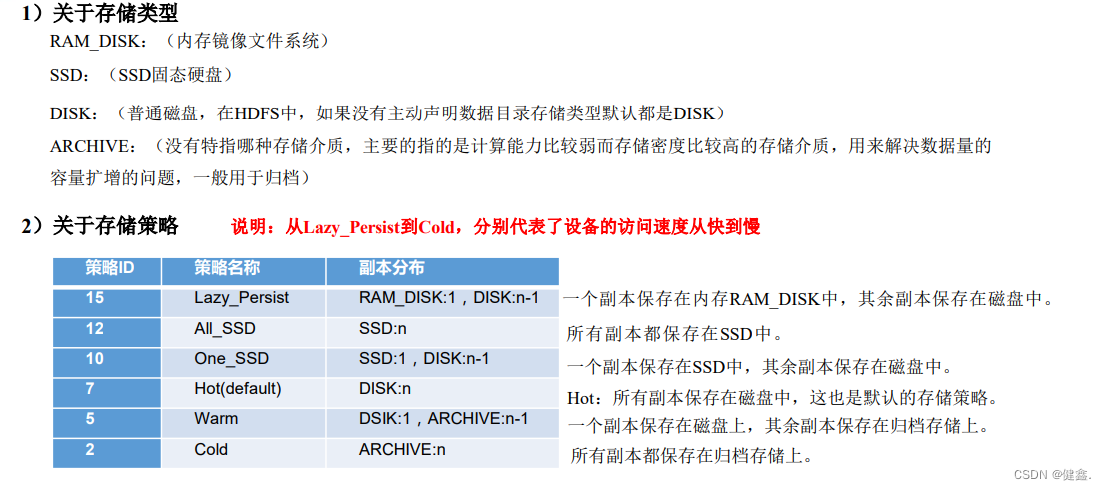
5.2 异构存储(冷热数据分离)
HDFS异构存储是指在HDFS中使用不同类型的存储介质来存储数据,例如硬盘、固态硬盘、闪存、内存等。异构存储可以提高存储系统的性能和可用性,同时也可以降低存储成本。