数据挖掘任务一般分为四大步骤:
1、数据预处理
2、特征选择
3、模型训练与测试
4、模型评估
本文为四大步骤提供接口,使得能够快速进行一个数据挖掘多种任务中,常见的二分类任务。
0. 导包
0.1 忽略警告信息:
import warnings
warnings.filterwarnings("ignore")0.2 导入一些常用的包:
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import numpy as np
import pandas as pd
import seaborn as sns
%matplotlib inline
pd.set_option('display.max_columns', 50) # or 1000
import matplotlib.ticker as mtick
import matplotlib.patches as mpatches
from imblearn.metrics import classification_report_imbalanced
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import make_pipeline as imbalanced_make_pipeline, Pipeline
from imblearn.under_sampling import NearMiss
from sklearn.decomposition import PCA, TruncatedSVD
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.manifold import TSNE
from sklearn.metrics import (accuracy_score, classification_report, f1_score,
precision_recall_curve, precision_score,
recall_score, roc_auc_score, roc_curve, RocCurveDisplay)
from sklearn.model_selection import (GridSearchCV, KFold, RandomizedSearchCV,
ShuffleSplit, StratifiedKFold,
StratifiedShuffleSplit, cross_val_predict,
cross_val_score, learning_curve,
train_test_split)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler, StandardScaler,OneHotEncoder, MinMaxScaler
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
import plotly.express as px 0.3 查看当前工作路径文件:
import os
wd = os.getcwd()
print(os.listdir(wd))数据预处理
1.1 加载数据集
csv_filePath = 'sample.csv'
df = read_csv(csv_filePath)
data_length = len(df)
df.head(5)1.2 查看数据集信息
df.info() # information1.3.1 查看缺失值
null_frame = df.isnull().sum().to_frame().T
null_frame
1.3.2 处理缺失值
# According to the above information, you can freely choose which column to operate on
# Option 1: Attributes that need to fill in missing values
fillna_columns = []
# Option 2: The row with missing values in the specified column needs to be deleted.
dropna_columns = []
# Option 3: delete the column name of the entire column.
dropaxis_columns = []
# run options
for dim in df.isnull().sum().to_frame().T:
# NOTE: The value used to fill in missing values can be found in the above [XXX_df.description()].
if dim in fillna_columns:
df[dim].fillna(value=df[dim].mean(), inplace=True)
# NOTE: Delete rows with missing values
if dim in dropna_columns:
df.dropna(subset=[dim], inplace=True)
# Delete an entire column
if dim in dropaxis_columns:
df.drop([dim], axis=1, inplace=True)1.3.3 再次查看缺失值
df.isnull().sum().to_frame().T1.4 把总数据集划分为特征数据集和目标数据集(只保留特征属性与目标属性相关性大于0.05的特征属性)
y_label = 'result'
features = df.corr().columns[df.corr()[y_label].abs()> .05]
X = X[df.drop(y_label,axis=1).columns]
y = df[y_label]1.5.1 让所有objcet类型变为float类型(字符串转数值类型)
from collections import defaultdict
one_hot_dims = []
for dim in df:
if type(df[dim].tolist()[0])==str :
one_hot_dims.append(dim)
labels = list(df[dim])
uni_labels = set(df[dim])
OrdinalEncoder = defaultdict(list)
for idx, label in enumerate(uni_labels):
OrdinalEncoder[dim].append([label, idx])
for k in OrdinalEncoder:
values = OrdinalEncoder[k]
oe = {}
for v in values:
oe[k] = {v[0]:v[1]}
df = df.replace(oe)
df.head()1.5.2 让所有objcet类型变为one-hot独热编码(字符串转独热编码类型)
def one_hot_and_merge_objectDim(df, object_type_dims):
#Only process object type data
for key in object_type_dims:
if type(df[key].tolist()[0])!=str:
continue
if key not in df.columns:
continue
print(key + ' is done.')
# Step1、get new dim(DataFrame)
new_dim = pd.get_dummies(df[key])
# Step2、rename new dim
new_columns = list(new_dim.columns)
rename_columns = {}
for col in new_columns:
rename_columns[col] = str(key) + '_' + str(col)
new_dim.rename(columns=rename_columns, inplace=True)
# Step3、merge new dim to DataSet and drop the old dim
df = df.drop(columns=key)
for dim in new_dim:
df[dim] = new_dim[dim].tolist()
return df
# 一般只对X特征属性进行one_hot处理, 具体的操作具体情况来定
X = one_hot_and_merge_objectDim(X, one_hot_dims)
X.info()1.7 查看数据分布信息
df.describe()1.8 查看目标属性数据分布是否均衡
schem = {}
for x in list(y.unique()):
schem[x] = list(y).count(x)
plt.bar(schem.keys(),schem.values())
plt.show()2. 特征选择
2.1 协方差特征选择图
fig, ax = plt.subplots(figsize=(30, 20))
corr = df.corr()
cmap = sns.diverging_palette(220, 10, as_cmap=True)
mask = np.triu(np.ones_like(corr, dtype=np.bool))
sns.heatmap(corr, annot = True, linewidth=.8, cmap=cmap, mask=mask)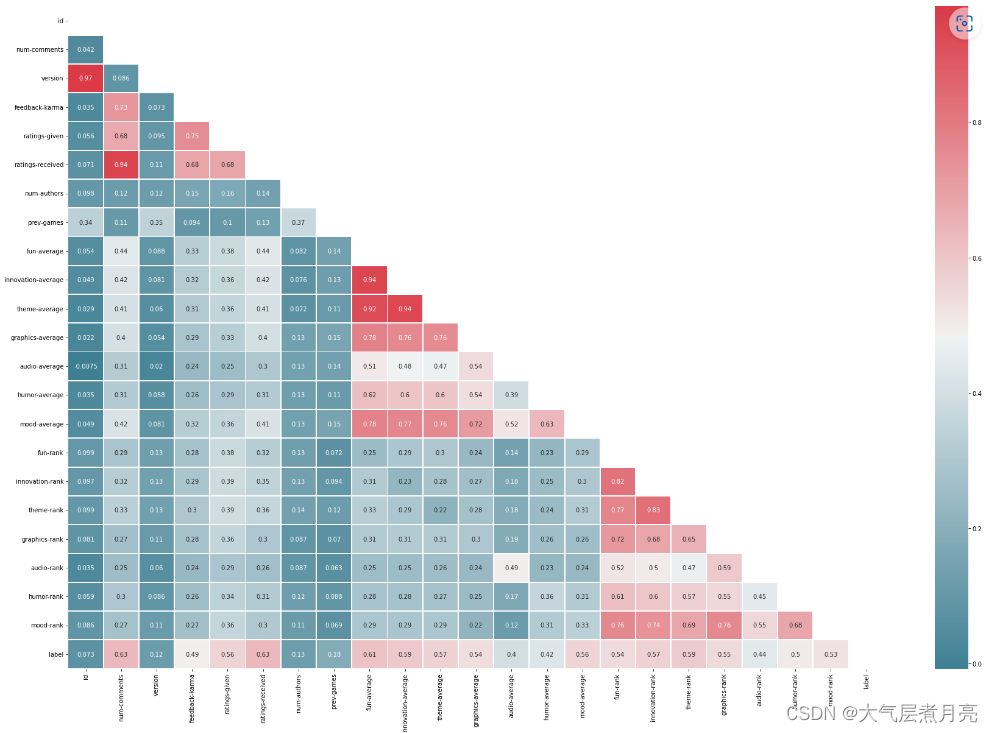
2.2.1 随机森林特征选择图
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.pipeline import Pipeline
rf = RandomForestRegressor(n_estimators=100,max_depth=None)
rf_pipe = Pipeline([('standardize', StandardScaler()), ('rf', rf)])
rf_pipe.fit(X, y)
#根据随机森林模型的拟合结果选择特征
rf = rf_pipe.__getitem__('rf')
importance = rf.feature_importances_
#np.argsort()返回待排序集合从下到大的索引值,[::-1]实现倒序,即最终imp_result内保存的是从大到小的索引值
imp_result = np.argsort(importance)[::-1][:10]
#按重要性从高到低输出属性列名和其重要性
for i in range(len(imp_result)):
print("%2d. %-*s %f" % (i + 1, 30, feat_labels[imp_result[i]], importance[imp_result[i]]))
#对属性列,按属性重要性从高到低进行排序
feat_labels = [feat_labels[i] for i in imp_result]
#绘制特征重要性图像
plt.title('Feature Importance')
plt.bar(range(len(imp_result)), importance[imp_result], color='lightblue', align='center')
plt.xticks(range(len(imp_result)), feat_labels, rotation=90)
plt.xlim([-1, len(imp_result)])
plt.tight_layout()
plt.show()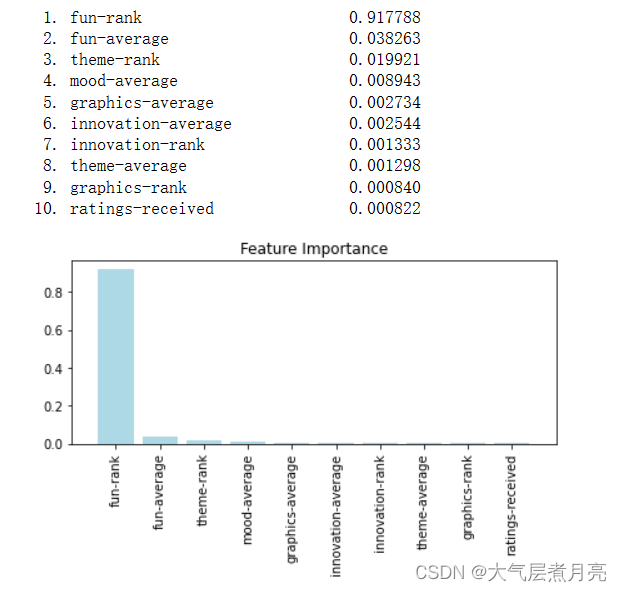
2.2.2 根据随机森林特征重要性保留前k位特征属性
# 根据上图选择要保留几个特征(从最重要开始)
save_featLength = len(feat_labels)
X = X[feat_labels[:save_featLength]]
X3. 模型训练与测试
3.1 划分数据集并预留计算残差函数
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state=1)
model_names = ['LR', 'DTC', 'RF', 'XGB']
accs = []
reds = []
def get_residuals(y_truth, y_pred):
cc=(y_truth-y_pred)
ccp=cc**2
loss=sum(ccp)
return cc,ccp,loss3.2 逻辑回归模型分类
logr = LogisticRegression()
logr.fit(X_train, y_train)
logr_pred = logr.predict(X_test)
logr_proba = logr.predict_proba(X_test)
print("LogisticRegression:")
print("训练集分数:{:.2f}%".format(logr.score(X_train,y_train)*100))
print("验证集分数:{:.2f}%".format(logr.score(X_test,y_test)*100))
print('残差:{}'.format(get_residuals(y_test, logr_pred)[-1]))
accs.append(logr.score(X_test,y_test)*100)
reds.append(get_residuals(y_test, logr_pred)[-1])3.3 决策树分类
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
dt_pred = dt.predict(X_test)
dt_proba = dt.predict_proba(X_test)
print("DecisionTreeClassifier:")
print("训练集分数:{:.2f}%".format(dt.score(X_train,y_train)*100))
print("验证集分数:{:.2f}%".format(dt.score(X_test,y_test)*100))
print('残差:{}'.format(get_residuals(y_test, dt_pred)[-1]))
accs.append(dt.score(X_test,y_test)*100)
reds.append(get_residuals(y_test, dt_pred)[-1])3.4 随机森林分类
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
rf_pred = rf.predict(X_test)
rf_proba = rf.predict_proba(X_test)
print("RandomForestClassifier:")
print("训练集分数:{:.2f}%".format(rf.score(X_train,y_train)*100))
print("验证集分数:{:.2f}%".format(rf.score(X_test,y_test)*100))
print('残差:{}'.format(get_residuals(y_test, rf_pred)[-1]))
accs.append(rf.score(X_test,y_test)*100)
reds.append(get_residuals(y_test, rf_pred)[-1])3.5 XGBoost分类
XGB = XGBClassifier()
XGB.fit(X_train, y_train)
XGB_pred = XGB.predict(X_test)
XGB_proba = XGB.predict_proba(X_test)
print("XGBClassifier:")
print("训练集分数:{:.2f}%".format(XGB.score(X_train,y_train)*100))
print("验证集分数:{:.2f}%".format(XGB.score(X_test,y_test)*100))
print('残差:{}'.format(get_residuals(y_test, XGB_pred)[-1]))
accs.append(XGB.score(X_test,y_test)*100)
reds.append(get_residuals(y_test, XGB_pred)[-1])4. 模型评估
4.1 使用ROC评估曲线
def metrics_scoring_table(y_model,y_true, model_name, y_proba=[0]):
prec = precision_score(y_true, y_model)
accu = accuracy_score( y_true, y_model)
recall = recall_score(y_true, y_model)
f1 = f1_score(y_true, y_model)
#roc = roc_auc_score(y_true, y_proba[:, 1])
df_score = pd.DataFrame(data= {
"model" : model_name,
"accuracy score": accu,
"precision score": prec,
"recall score": recall,
"f1-score": f1,
#"ROC-AUC": roc
},
index = [0]
)
return df_score
def roc_curve_plot(Y_pred, Y_true, Y_pred_pobablities, model_name):
Y_pp = Y_pred_pobablities[:, 1]
fpr, tpr, threshold1 = roc_curve(Y_true, Y_pp )
fig, ax = plt.subplots(nrows=1, ncols= 1, figsize = (7,5), constrained_layout = True)
ax.plot(fpr, tpr, label='ROC Score: {:.5f}'.format(roc_auc_score(Y_true, Y_pp)))
ax.set_title(f"{model_name} ROC Curve ", fontdict = {"fontsize": 18})
ax.set_xlabel("False Positive Rate", fontdict = {"fontsize": 15} )
ax.set_ylabel("True Positive Rate", fontdict = {"fontsize": 15})
ax.legend(loc = 4, fontsize = 14 )
plt.show()
def roc_summary_plot(Y_true, Y_probability = [], model_name = []):
for i in range(len(Y_probability)):
fpr, tpr, threshold1 = roc_curve(Y_true,Y_probability[i][:,1] )
plt.style.use("seaborn-white")
plt.figure( num = 1, figsize = (12, 9))
plt.title("ROC scores summary", fontsize = 18)
plt.xlabel("False Positive Rate" , fontdict = {"fontsize": 15})
plt.ylabel("True Positive Rate" , fontdict = {"fontsize": 15})
plt.plot(fpr, tpr, label='{0} ROC Score: {1}'.format(model_name[i] ,round(roc_auc_score(Y_true, Y_probability[i][:,1] ) ,2)))
plt.legend(loc = 4, fontsize =13)
plt.show()roc_summary_plot(Y_test, [logr_Y_proba, dt_Y_proba, rf_Y_proba, XGB_Y_proba],
["LogisticRegression", "DecisionTree" ,"Random Forest", "XGBClassifier"])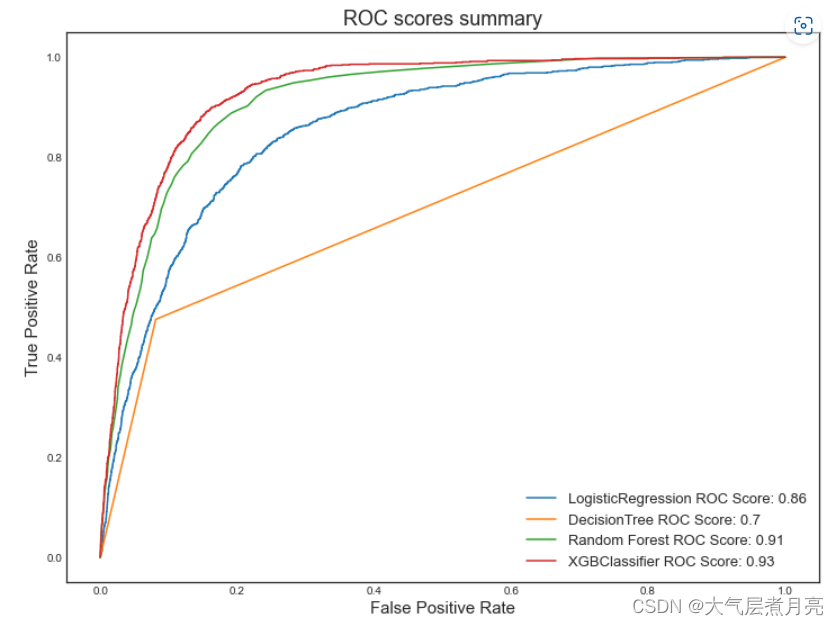
score_1 = metrics_scoring_table(logr_Y_pred,Y_test, logr_Y_proba ,"LogisticRegression")
score_2 = metrics_scoring_table(dt_Y_pred,Y_test, dt_Y_proba ,"Decision Tree")
score_3 = metrics_scoring_table(rf_Y_pred,Y_test, rf_Y_proba ,"RandomForest")
score_4 = metrics_scoring_table(XGB_Y_pred,Y_test, XGB_Y_proba ,"XGBClassifier")
score = pd.concat([score_1,score_2,score_3,score_4], axis=0)
score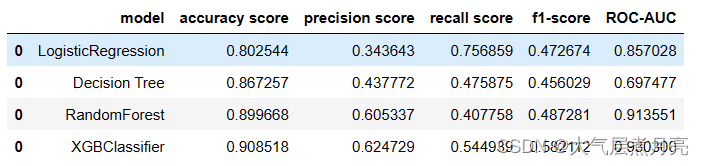
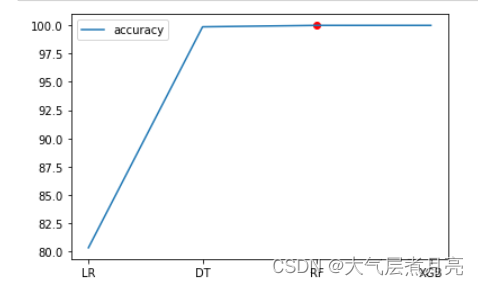
4.2 残差评估
plt.plot(model_names, accs, label='accuracy')
plt.scatter(model_names[-2],accs[-2],c='r')
# plt.plot(model_names, np.array(reds)/500,c='r', label='residuals')
plt.legend()
plt.show()