Python基于词频排序快速挖掘需求大类
作者:虚坏叔叔
博客:https://xuhss.com
早餐店不会开到晚上,想吃的人早就来了!😄
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yOHxu25v-1677813328261)(2007.assets/1.png)]](https://img-blog.csdnimg.cn/ab6bff4cab164e139c8e86f379c00515.png)
一、所有的代码
这是所有的代码
from collections import defaultdict
import jieba.posseg as jp
with open('keyword.txt','r',encoding='utf-8') as file:
keyword_list = file.read().split('\n')
not_flag = set(['w','x','y','z','un','m'])
not_word = set(['的','是','有','啊','呢','么','好'])
keyword_split = dict()
word_count = defaultdict(int)
for keyword in keyword_list:
word_set = set()
for word,flag in jp.cut(keyword):
if flag in not_flag:
continue
if word in not_word:
continue
if word == 'pdf' or word == 'PDF':
continue
word_count[word] += 1
word_set.add(word)
keyword_split[keyword] = word_set
id_keyword_list = defaultdict(list)
id_count = defaultdict(int)
for keyword,word_set in keyword_split.items():
word_sort = dict()
for word in word_set:
word_sort[word] = word_count[word]
word_sort = sorted(word_sort.items(),key=lambda x:x[1],reverse=True)
word_id = ','.join([word for word,count in word_sort[0:3]])
id_keyword_list[word_id] += [keyword]
id_count[word_id] += 1
result = []
id_count = sorted(id_count.items(),key=lambda x:x[1],reverse=True)
for word_id,count in id_count:
if count < 3:
continue
for keyword in id_keyword_list[word_id]:
result.append('%s\t%s' % (keyword,word_id))
result.append('')
with open('result.txt','wb') as file:
file.write('\n'.join(result).encode('utf-8'))
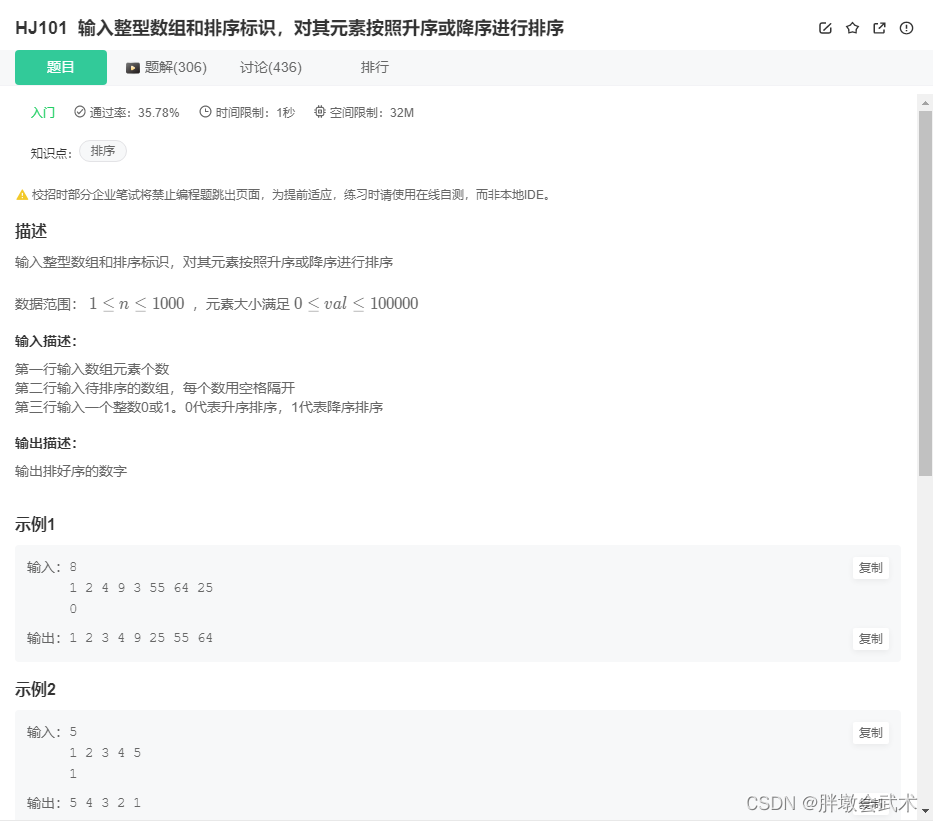
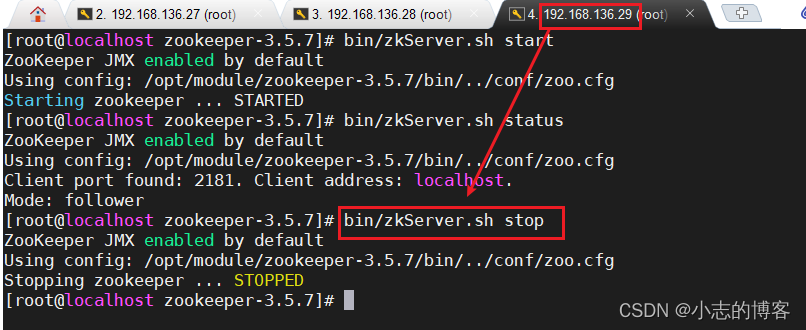
二、实现的效果
keyword.txt如下图:
有50万的关于pdf的关键词数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AKB02rAM-1677813328262)(2007.assets/image-20230303104426170.png)]](https://img-blog.csdnimg.cn/abc6c2e6c94d4072bce72aa336b0a2da.png)
最后的输出result.txt 就是将里面的含有关键词相同的句子统一输出出来:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X7Ir6o4b-1677813328262)(2007.assets/image-20230303104618885.png)]](https://img-blog.csdnimg.cn/7911254f807c4d1ab880ff29b621c19f.png)
这里会将一个句子的3个关键词输出出来 关键词是根据词频排序的。
最后将所有关键词一样的句子组合在一起,就可以知道这些句子表达的意思大致一致
三、代码解读
keyword_list 是从keyword.txt读取到的所有的句子
not_flag 是要排除的标记,不统计这些标记
not_word 是要排除的单词,不统计这些单词
keyword_split 是句子对应到他的所有单词的字典,key是句子,value是他的所有单词的集合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I4YUd95w-1677813328263)(2007.assets/image-20230303110731460.png)]](https://img-blog.csdnimg.cn/20e7763906b54839b9221e2f956c6406.png)
word_count 是所有的拆分后的单词的次数的字典,key是单词,value是单词出现的次数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PyubuemM-1677813328263)(2007.assets/image-20230303110716066.png)]](https://img-blog.csdnimg.cn/22d99b034b934de98c03adaba1420a93.png)
id_keyword_list 是一个字典,它的key是一个字符串 value是列表
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iVKE3Mip-1677813328263)(2007.assets/image-20230303111114690.png)]](https://img-blog.csdnimg.cn/34999402c8e349468f51a016d6b40637.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6IvIdGpN-1677813328264)(2007.assets/image-20230303111153304.png)]](https://img-blog.csdnimg.cn/5ef8c1896c7a4fd38812d009fc13bf73.png)
id_count 是一个字典,它的key是一个字符串,value是int
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SpjPT46B-1677813328264)(2007.assets/image-20230303111135264.png)]](https://img-blog.csdnimg.cn/48f23b3b6c2740d9b5a9528f96e6c59c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wmi3xeVR-1677813328264)(2007.assets/image-20230303110951802.png)]](https://img-blog.csdnimg.cn/4e6189533e4741cdb21fda01a48f29d9.png)
最后对id_count处理 将结果输出出来
id_count = sorted(id_count.items(), key=lambda x: x[1], reverse=True)
for word_id, count in id_count:
if count < 3:
continue
for keyword in id_keyword_list[word_id]:
result.append('%s\t%s' % (keyword, word_id))
result.append('')
四、代码和配套文件下载地址
https://download.csdn.net/download/huangbangqing12/87526844
总结
- 本文主要介绍jieba的基础用法。
- 如果觉得文章对你有用处,记得
点赞收藏转发一波哦,博主也支持为铁粉丝制作专属动态壁纸哦~
💬 往期优质文章分享
- C++ QT结合FFmpeg实战开发视频播放器-01环境的安装和项目部署
- 解决QT问题:运行qmake:Project ERROR: Cannot run compiler ‘cl‘. Output:
- 解决安装QT后MSVC2015 64bit配置无编译器和调试器问题
- Qt中的套件提示no complier set in kit和no debugger,出现黄色感叹号问题解决(MSVC2017)
- Python+selenium 自动化 - 实现自动导入、上传外部文件(不弹出windows窗口)
🚀 优质教程分享 🚀
- 🎄如果感觉文章看完了不过瘾,可以来我的其他 专栏 看一下哦~
- 🎄比如以下几个专栏:Python实战微信订餐小程序、Python量化交易实战、C++ QT实战类项目 和 算法学习专栏
- 🎄可以学习更多的关于C++/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| ❤️ C++ QT结合FFmpeg实战开发视频播放器❤️ | 难度偏高 | 分享学习QT成品的视频播放器源码,需要有扎实的C++知识! |
| 💚 游戏爱好者九万人社区💚 | 互助/吹水 | 九万人游戏爱好者社区,聊天互助,白嫖奖品 |
| 💙 Python零基础到入门 💙 | Python初学者 | 针对没有经过系统学习的小伙伴,核心目的就是让我们能够快速学习Python的知识以达到入门 |
🚀 资料白嫖,温馨提示 🚀
关注下面卡片即刻获取更多编程知识,包括各种语言学习资料,上千套PPT模板和各种游戏源码素材等等资料。更多内容可自行查看哦!