本质
一、算法
1、哪些是垃圾?
引用计数法:reference count
Python中使用了。
个对象如果没有任何与之关联的引用,即他们的引用计数都不为 0,则说明对象不太可能再被用到,那么这个对象就是可回收对象。
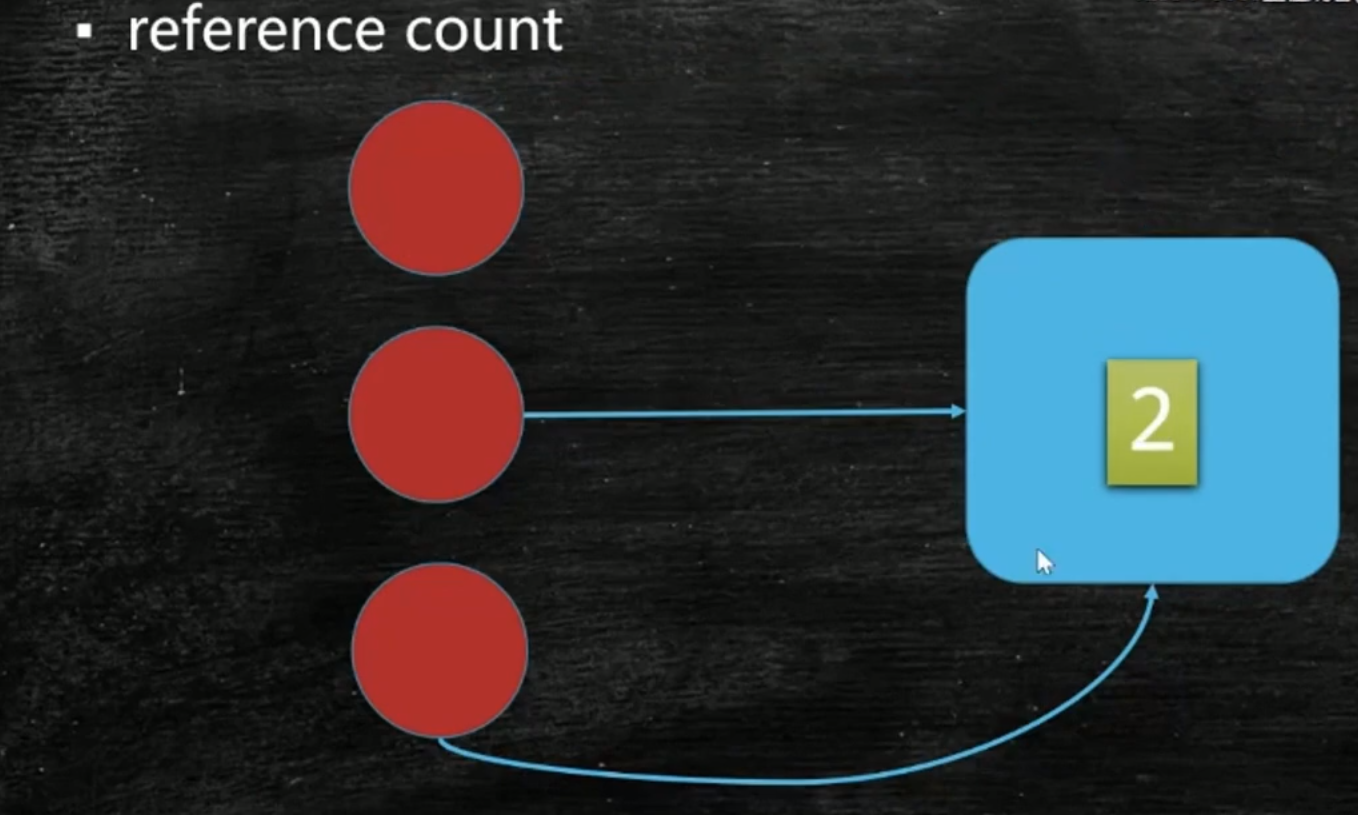
漏洞:循环引用

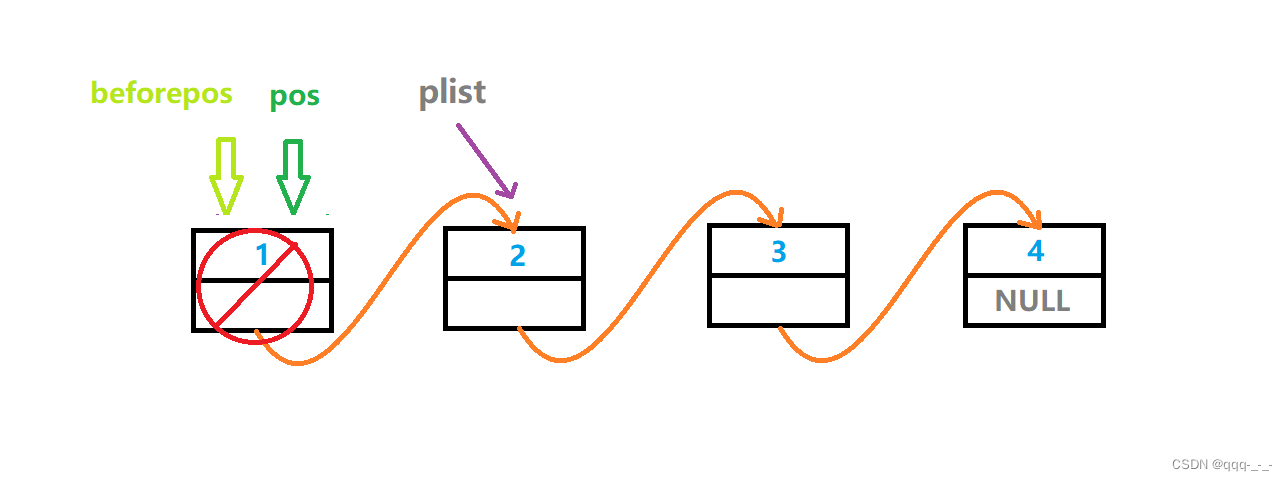
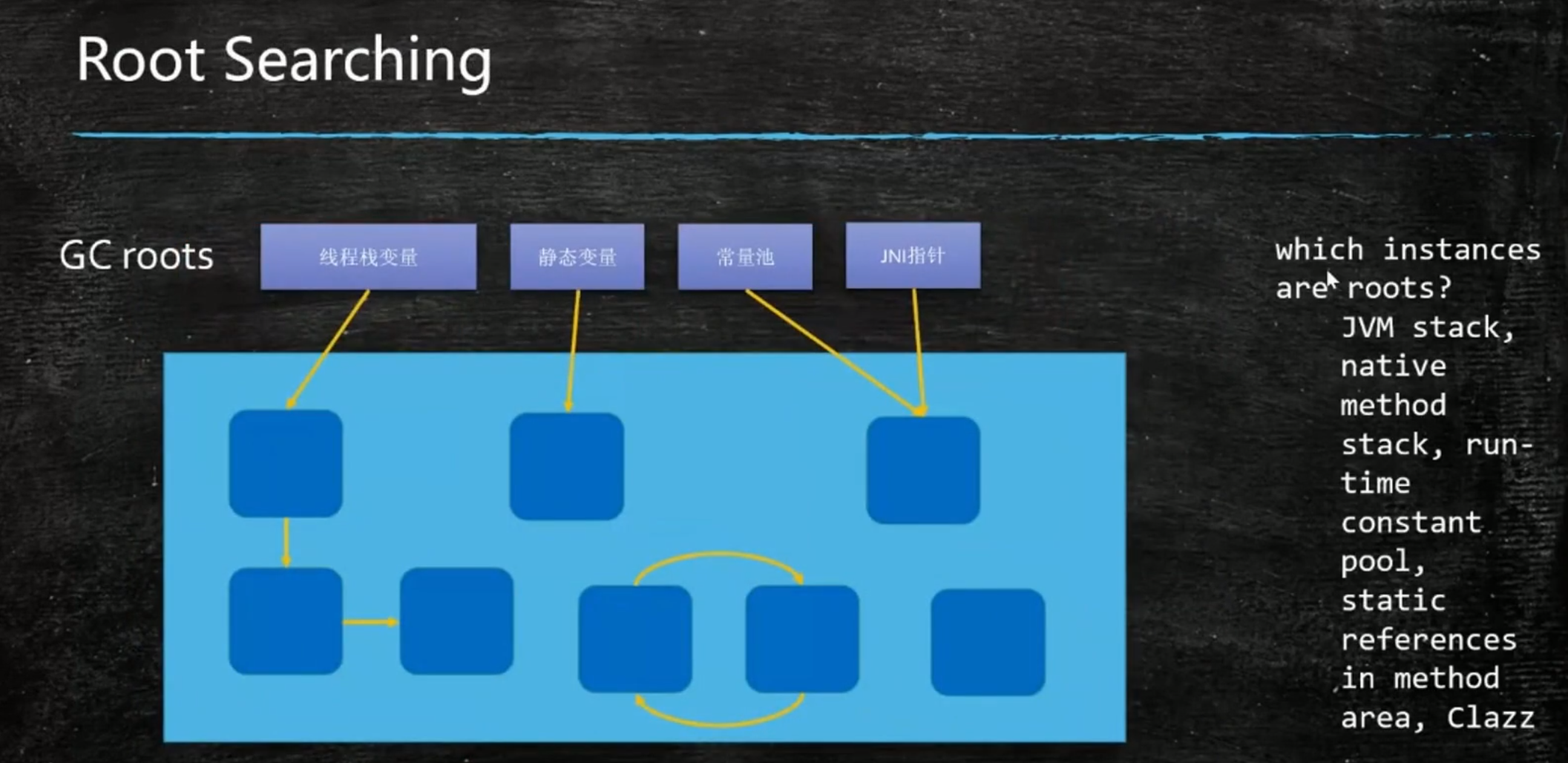
根可达性算法:Root Searching
如果在“GC roots”和一个对象之间没有可达路径,则称该对象是不可达的。要注意的是,不可达对象不等价于可回收对象,不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
例:main函数中的成员变量,顺着引用开始找,找不到的都是垃圾
2、什么时候清除?
3、用什么方式清除?
标记清除 Mark-Sweep:
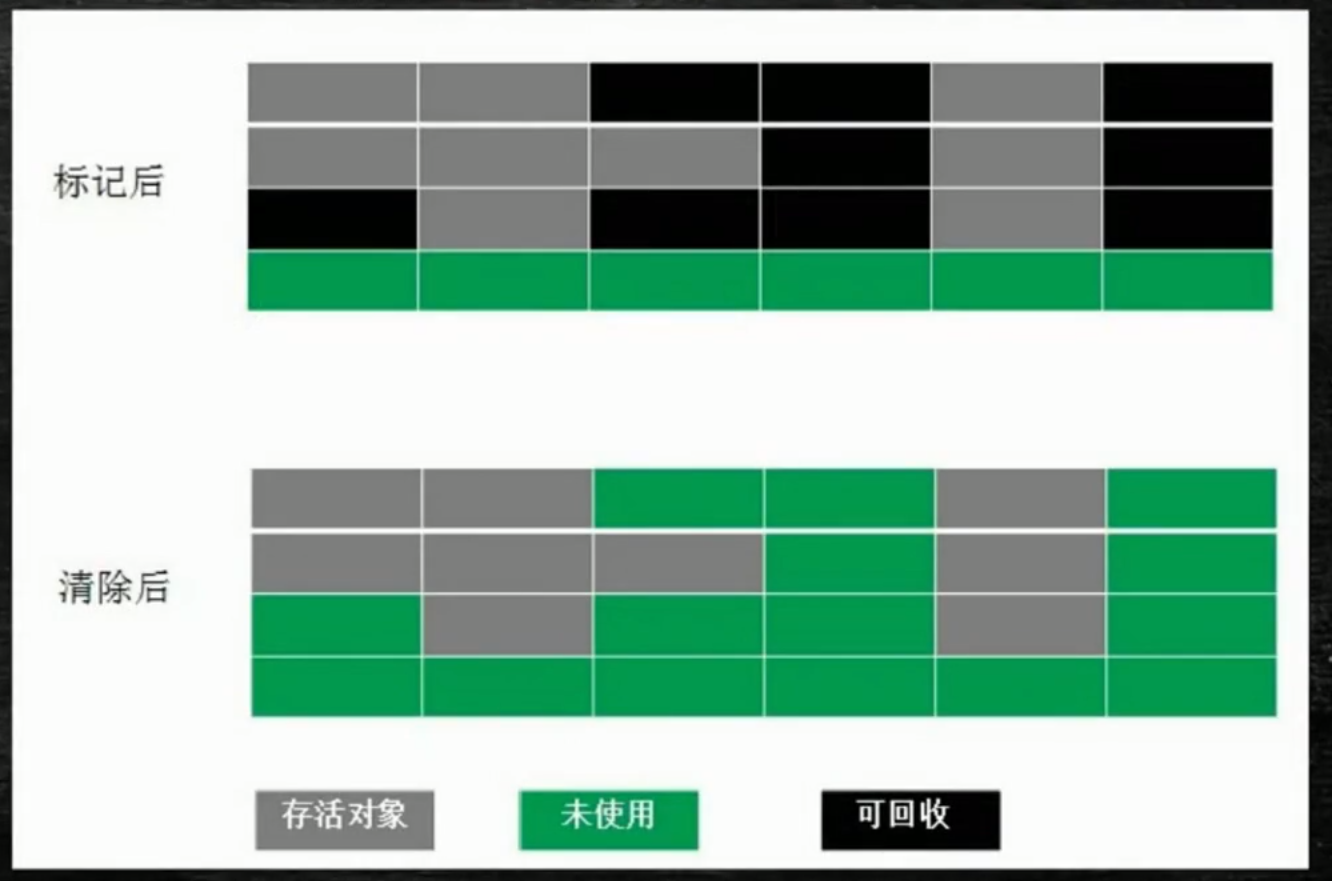
缺陷:内存碎片化,泄漏
拷贝 Copying:
漏洞:浪费内存
标记整理 Mark-Compact:
漏洞:性能低
分代算法:

堆内存逻辑分区

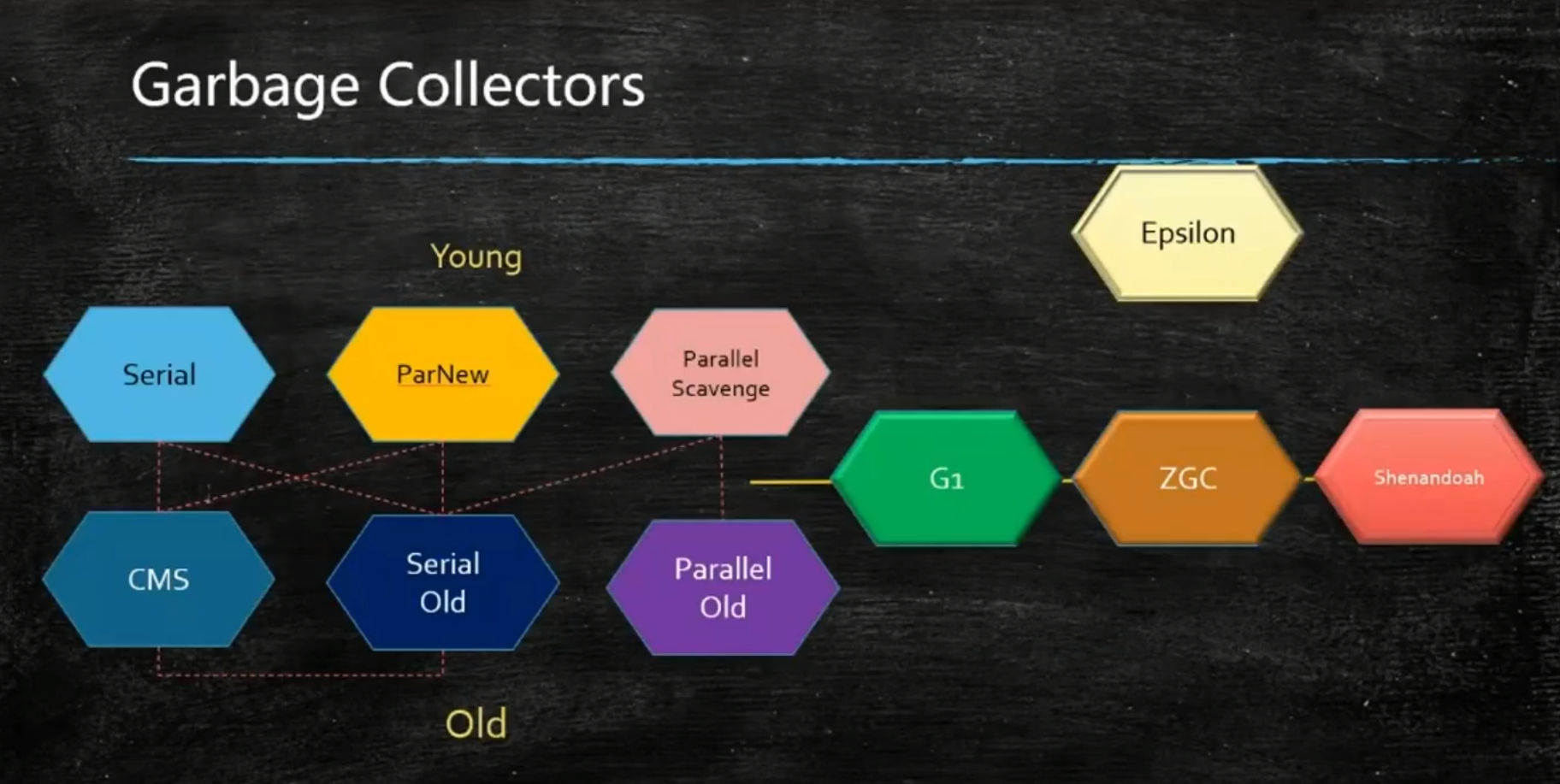
二、垃圾收集器
三种算法都有毛病,三种的综合应用,诞生了各种各样的垃圾回收器
MinGC YGC
MaGC FullGC
垃圾收集器随着内存大小的不断增长而演进
内存分代:
JDK1.8之前使用分代模型
新生代采用复制算法,老年代使用标记清除和标记整理算法。
Serial + Serial Old:
针对几兆-几十兆
STW:a stop-the-world,copying collector which uses a single GC thread
Serial单线程STW垃圾回收 年青代 老年代
Parallel Scavenge + Parallel Old:(ps+po):jdk1.8默认垃圾回收器

几十兆-上百兆1G
Parallel并行多线程
Concurrent GC:
GC线程和业务线程同时运行
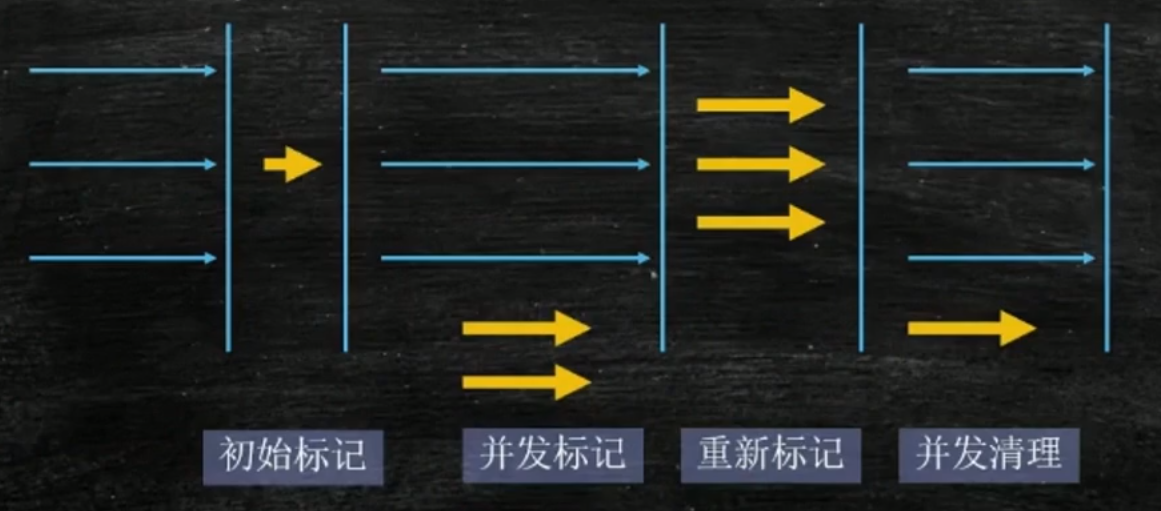
初始标记(需要STW):只需要找到根root上的对象
并发标记:业务GC并行(一定会有标错)
重新标记(需要STW):清理上一步标错的
并发清理:清除上一步标错的
三色标记法算法:

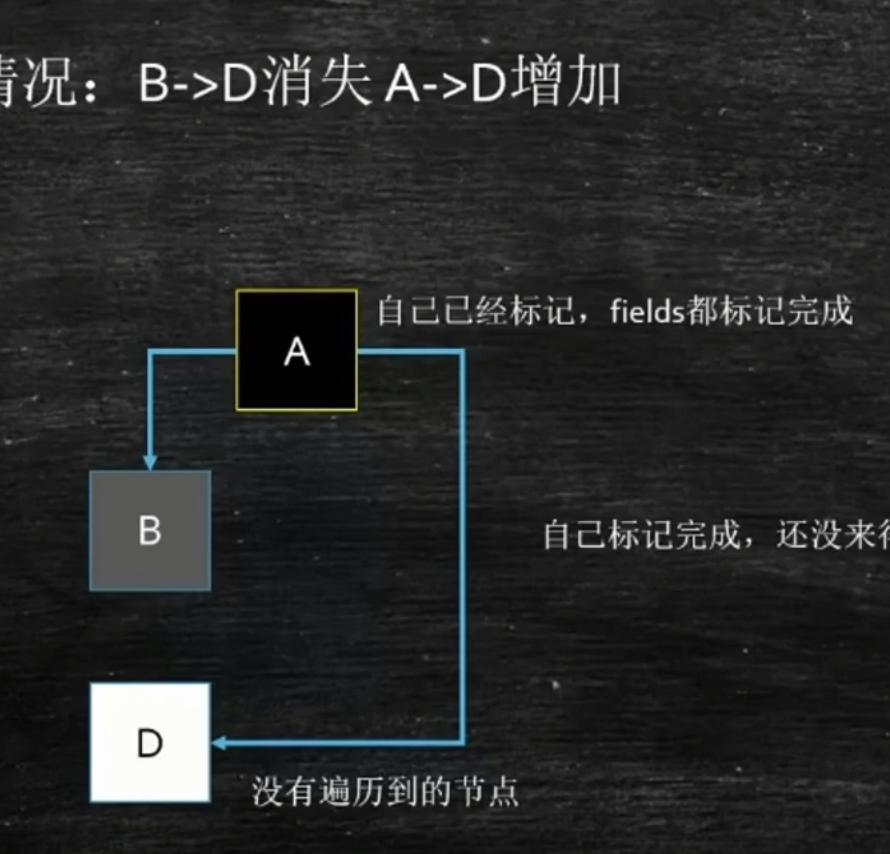
ParNew+CMS:(1.5,1.6,1.7)
几十G
CMS方案:incremental Update的非常隐蔽的问题:并发标记,产生漏标
CMS的remark阶段,必须从头扫描一遍


内存不分代:
Epsilon:(jdk11诞生)
什么都不干,仅作记录,作用:1、开发JVM的人做debug用;2、内存超级大根本用不完可以使用
G1:(1.7诞生但不成熟,1.8可使用)
逻辑上分代,物理上不分代
G1的内存区域不是固定的E或者O
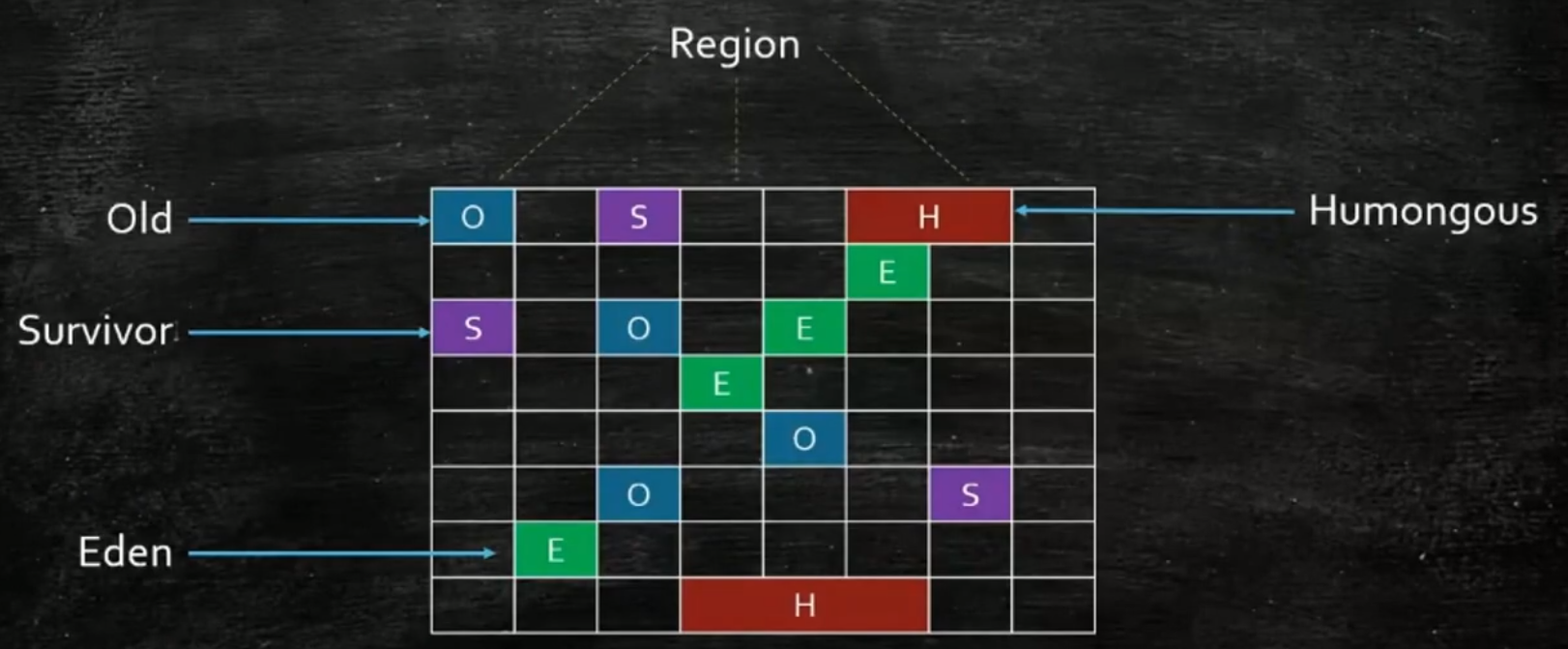
分区算法:部分回收(每个区大小为1-32,2的倍数)
一边清理一部分区域,一边占用一部分区域,特别大的对象放Humongous区域,也不够了开始FullGC
毛病:一次回收需要回收整个逻辑上的年青代(STW时间过长)
ZGC:zero paused GC(jdk11引入)
甲骨文官方支持

颜色算法:Colored Pointer+Load Barrier
分区更灵活(1M、2M、8M等),逻辑上不再分代,每100ms触发一次GC,每次找到特别满的区域进行清除
Shenandoash (jdk12引入):
开源领域贡献