6. 偏移量管理
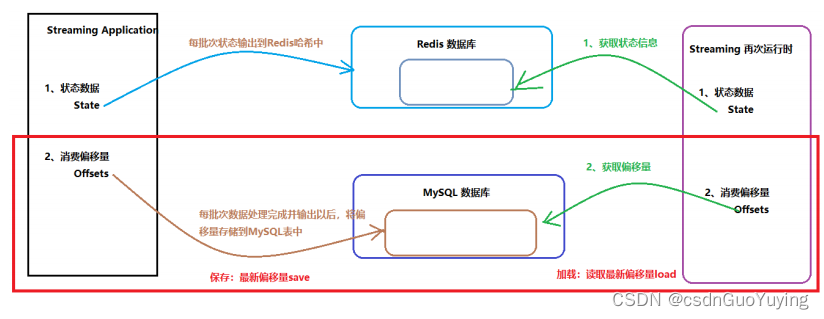
针对前面实现【百度热搜排行榜Top10】实时状态统计应用来说,当应用关闭以后,再次启动(Restart)执行,并没有继续从上次消费偏移量读取数据和获取以前状态信息,而是从最新偏移量(Latest Offset)开始的消费,肯定不符合实际需求,有两种解决方式:
方式一:Checkpoint 恢复
- 当流式应用再次启动时,从Checkpoint 检查点目录恢复,可以读取上次消费偏移量信息和状态相关数据,继续实时处理数据。
- 文档:http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#checkpointing
方式二:手动管理偏移量
- 用户编程管理每批次消费数据的偏移量,当再次启动应用时,读取上次消费偏移量信息,继续实时处理数据。
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html#storing-offsets
在实际生产项目中,常常使用第二种方式【手动管理偏移量】,将偏移量存储到MySQL、Redis或Zookeeper中,接下来讲解两种方式实现,都需要掌握。
6.1 重构代码
实际项目开发中,为了代码重构复用和代码简洁性,将【从数据源读取数据、实时处理及结果输出】封装到方法【processData】中,类的结构如下:

Streaming流式应用模板完整代码:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
/**
* SparkStreaming流式应用模板Template,将从数据源读取数据、实时处理及结果输出封装到方法中。
*/
object StreamingTemplate {
/**
* 抽象一个函数:专门从数据源读取流式数据,经过状态操作分析数据,最终将数据输出
* @param ssc 流式上下文StreamingContext实例对象
*/
def processData(ssc: StreamingContext): Unit ={
// TODO: 1. 从Kafka Topic实时消费数据
val kafkaDStream: DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array("search-log-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0002",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用消费者新API获取数据
KafkaUtils.createDirectStream(ssc, locationStrategy, consumerStrategy)
}
// TODO: 2. 词频统计,实时累加统计
// 2.1 对数据进行ETL和聚合操作
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
val reduceRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter{ record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map{record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
// 返回
reduceRDD
}
// 2.2 使用mapWithState函数状态更新, 针对每条数据进行更新状态
val spec: StateSpec[String, Int, Int, (String, Int)] = StateSpec.function(
// (KeyType, Option[ValueType], State[StateType]) => MappedType
(keyword: String, countOption: Option[Int], state: State[Int]) => {
// a. 获取当前批次中搜索词搜索次数
val currentState: Int = countOption.getOrElse(0)
// b. 从以前状态中获取搜索词搜索次数
val previousState = state.getOption().getOrElse(0)
// c. 搜索词总的搜索次数
val latestState = currentState + previousState
// d. 更行状态
state.update(latestState)
// e. 返回最新省份销售订单额
(keyword, latestState)
}
)
// 调用mapWithState函数进行实时累加状态统计
val stateDStream: DStream[(String, Int)] = reduceDStream.mapWithState(spec)
// TODO: 3. 统计结果打印至控制台
stateDStream.foreachRDD{(rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"BatchTime: $batchTime")
println("-------------------------------------------")
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition{_.foreach(println)}
}
}
}
// 应用程序入口
def main(args: Array[String]): Unit = {
// TODO: 构建流式上下文实例对象StreamingContext
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO: 设置消费最大数量
.set("spark.streaming.kafka.maxRatePerPartition", "10000")
// b. 传递SparkConf和BatchInterval创建流式上下对象
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回实例对象
context
}
// TODO: 从数据源端消费数据,实时处理分析及最后输出
processData(ssc)
// TODO: 启动流式应用,等待终止(人为或程序异常)
ssc.start()
ssc.awaitTermination() // 流式应用启动以后,一直等待终止,否则一直运行
// 无论是否异常最终关闭流式应用(优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
如果流式应用业务复杂,可以将其单独抽取方法,对DStream数据进行处理分析。
6.2 Checkpoint 恢复
针对Spark Streaming状态应用程序,设置Checkpoint检查点目录,其中存储两种类型数据:
第一类:元数据(Metadata checkpointing),保存定义了 Streaming 计算逻辑
- 应用程序的配置(Configuration): The configuration that was used to create the streaming application;
- DStream操作(DStream operations):The set of DStream operations that define the streaming application;
- 没有完成批处理(Incomplete batches):Batches whose jobs are queued but have not completed yet;
第二类:数据(Data checkpointing),保存已生成的RDDs至可靠的存储
- 通常有状态的数据横跨多个batch流的时候,需要做checkpoint
Metadata Checkpointing 用来恢复 Driver;Data Checkpointing用来容错stateful的数据处理失败的场景 。
当我们再次运行Streaming Application时,只要从Checkpoint 检查点目录恢复,构建StreamingContext应用,就可以继续从上次消费偏移量消费数据。
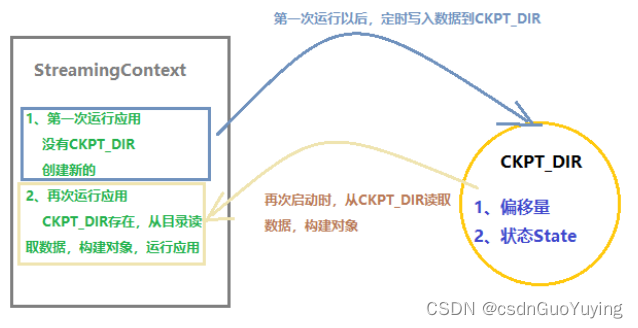
使用StreamingContext中【getActiveOrCreate】方法构建StreamingContext实例对象,方法声明如下:

若Application为首次重启,将创建一个新的StreamingContext实例;如果Application从失败中重启,从checkpoint目录导入checkpoint数据来重新创建StreamingContext实例。伪代码如下:

修改上述案例代码:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
/**
* SparkStreaming实现状态累计实时统计:DStream#mapWithState,当流式应用停止以后,再次启动时:
* - 其一:继续上次消费Kafka数据偏移量消费数据:MetaData
* - 其二:继续上次应用停止的状态累加更新状态:State
*/
object StreamingStateCkpt {
// 检查点目录
val CKPT_DIR: String = s"datas/streaming/state-ckpt-10002"
/**
* 抽象一个函数:专门从数据源读取流式数据,经过状态操作分析数据,最终将数据输出
* @param ssc 流式上下文StreamingContext实例对象
*/
def processData(ssc: StreamingContext): Unit ={
// 1. 从Kafka Topic实时消费数据
val kafkaDStream: DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array("search-log-topic")
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.itcast.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_streaming_0002",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用消费者新API获取数据
KafkaUtils.createDirectStream(ssc, locationStrategy, consumerStrategy)
}
// 2. 词频统计,实时累加统计
// 2.1 对数据进行ETL和聚合操作
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform{ rdd =>
val reduceRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter{ record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map{record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
// 返回
reduceRDD
}
// 2.2 使用mapWithState函数状态更新, 针对每条数据进行更新状态
val spec: StateSpec[String, Int, Int, (String, Int)] = StateSpec.function(
// (KeyType, Option[ValueType], State[StateType]) => MappedType
(keyword: String, countOption: Option[Int], state: State[Int]) => {
// a. 获取当前批次中搜索词搜索次数
val currentState: Int = countOption.getOrElse(0)
// b. 从以前状态中获取搜索词搜索次数
val previousState = state.getOption().getOrElse(0)
// c. 搜索词总的搜索次数
val latestState = currentState + previousState
// d. 更行状态
state.update(latestState)
// e. 返回最新省份销售订单额
(keyword, latestState)
}
)
// 调用mapWithState函数进行实时累加状态统计
val stateDStream: DStream[(String, Int)] = reduceDStream.mapWithState(spec)
// 3. 统计结果打印至控制台
stateDStream.foreachRDD{(rdd, time) =>
val batchTime: String = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"BatchTime: $batchTime")
println("-------------------------------------------")
if(!rdd.isEmpty()){
rdd.coalesce(1).foreachPartition{_.foreach(println)}
}
}
}
// 应用程序入口
def main(args: Array[String]): Unit = {
// TODO: 构建流式上下文实例对象StreamingContext
/*
def getActiveOrCreate(
checkpointPath: String,
creatingFunc: () => StreamingContext,
hadoopConf: Configuration = SparkHadoopUtil.get.conf,
createOnError: Boolean = false
): StreamingContext
*/
val ssc: StreamingContext = StreamingContext.getActiveOrCreate(
CKPT_DIR, // 检查点目录,第一次运行时没有,构建新的,调用如下方法
// TODO: 第一次运行应用时,一切都是新的,需要创建和指定;非第一次一切都是检查点目录数据恢复
() => {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// TODO: 设置消费最大数量
.set("spark.streaming.kafka.maxRatePerPartition", "10000")
// b. 传递SparkConf和BatchInterval创建流式上下对象
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 设置检查点目录
context.checkpoint(CKPT_DIR)
// d. 读取数据、处理数据和输出数据
processData(context)
// e. 返回StreamingContext对象
context
}
)
// 启动流式应用,等待终止(人为或程序异常)
ssc.start()
ssc.awaitTermination() // 流式应用启动以后,一直等待终止,否则一直运行
// 无论是否异常最终关闭流式应用(优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
当Streaming Application再次运行时,从Checkpoint检查点目录恢复时,有时有问题,比如修改程序,再次从运行时,可能出现类型转换异常,如下所示:
ERROR Utils: Exception encountered
java.lang.ClassCastException: cannot assign instance of cn.itcast.spark.ckpt.StreamingCkptState$$anonfun$streamingProcess$1 to field
org.apache.spark.streaming.dstream.ForEachDStream.org$apache$spark$streaming$dstream$ForEachDStream$$
foreachFunc of type scala.Function2 in instance of org.apache.spark.streaming.dstream.ForEachDStream
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2133)
at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1305)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2024)
原因在于修改DStream转换操作,在检查点目录中存储的数据没有此类的相关代码,所以保存ClassCastException异常。
此时无法从检查点读取偏移量信息和转态信息,所以SparkStreaming中Checkpoint功能,属于鸡肋,食之无味,弃之可惜。解决方案:
- 1)、针对状态信息:当应用启动时,从外部存储系统读取最新状态,比如从MySQL表读取,或者从Redis读取;
- 2)、针对偏移量数据:自己管理偏移量,将偏移量存储到MySQL表、Zookeeper、HBase或Redis;