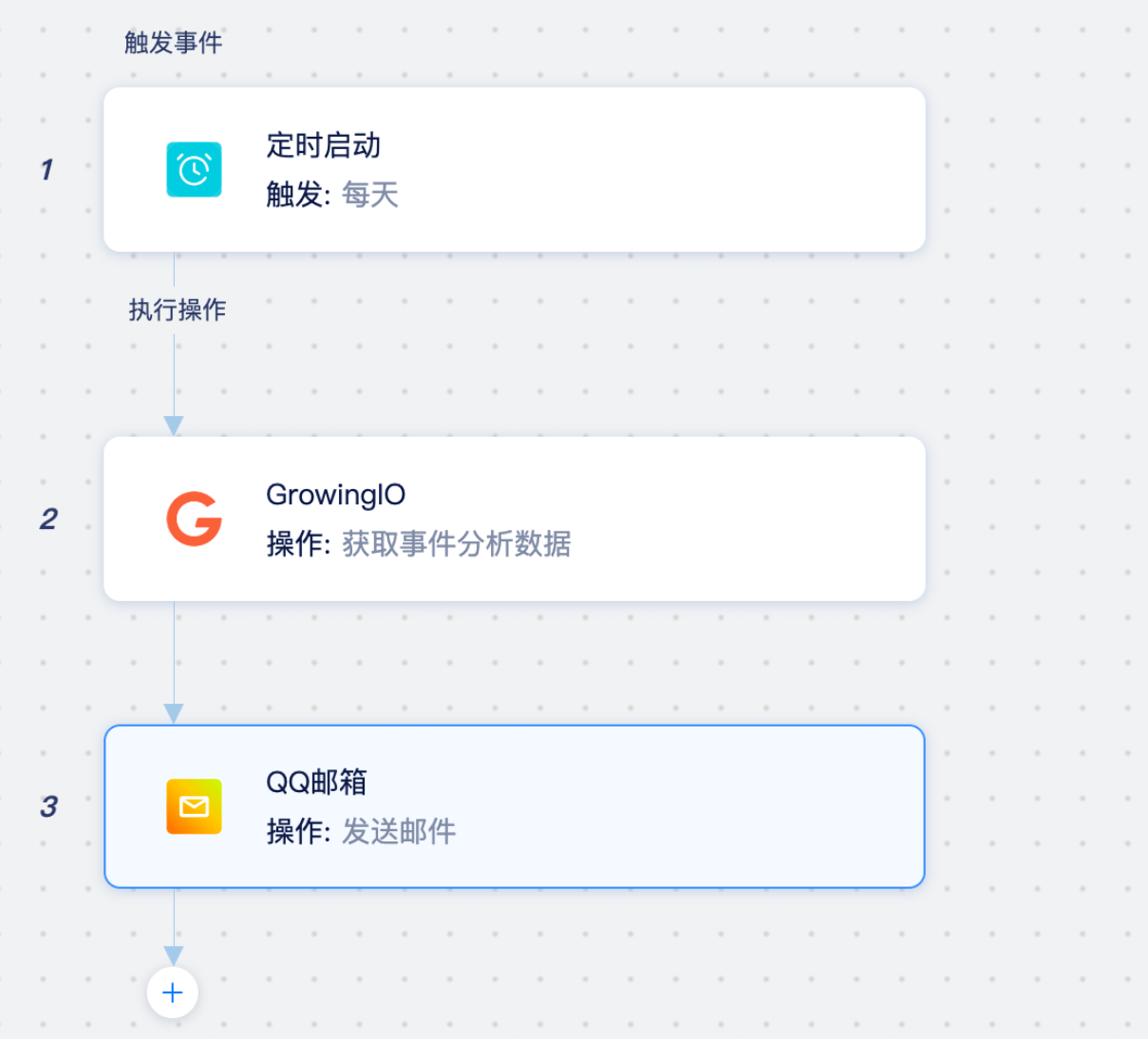
这篇文章使用了对比学习进行了聚类,一种端到端的离线聚类模型。
主要流程
Feature model
比较主流的句向量编码器SBERT。本文主要使用两个损失函数去微调SBERT的参数。使得SBERT的生成的特征表示具有以下两个特点:
- 簇间距离拉大(inter-cluster)
- 簇内距离缩小(intra-cluster)
对于数据 x x x, 编码: e = Φ ( x ) e = \Phi(x) e=Φ(x)
微调完成之后,将得到的 Feature Matrix ,使用K-means进行聚类。典型的离线聚类(outline-cluster)
cluster head
聚类头主要是用这篇paper的思想。
使用 SBERT 对数据进行编码得到 Feature Matrix,然后利用K-means算法进行聚类。得到K(数据集 簇类的数量)个聚类中心。并将他们设置成簇类头的初始参数。
每个前向传播会使用特征向量
x
x
x 和聚类中心参数
μ
\mu
μ,结合t-student分布生成一个概率矩阵Q:
q
i
,
k
=
(
1
+
∣
∣
e
i
−
μ
k
∣
∣
2
2
/
α
)
−
α
+
1
2
∑
k
′
=
1
K
(
1
+
∣
∣
e
i
−
μ
k
′
∣
∣
2
2
/
α
)
−
α
+
1
2
q_{i, k} = \frac{(1+||e_i-\mu_k||_2^2 / \alpha)^{-\frac{\alpha+1}{2}}}{\sum_{k'=1}^{K} (1+||e_i-\mu_{k'}||_2^2 / \alpha)^{-\frac{\alpha+1}{2}}}
qi,k=∑k′=1K(1+∣∣ei−μk′∣∣22/α)−2α+1(1+∣∣ei−μk∣∣22/α)−2α+1
其中,
α
\alpha
α是超参数,
q
i
,
k
q_{i, k}
qi,k 表示数据
x
i
x_i
xi属于 簇
k
k
k的概率。
然后再使用一个辅助函数,生成一个目标概率分布,这个函数的特点是将Q中每一行数值比较大的元素变得更大一点,相当于是将置信度比较高的数据着重学习一下。
辅助概率分布P:
p
i
,
k
=
q
j
k
2
/
f
k
∑
k
′
q
j
k
2
/
f
k
′
p_{i, k} = \frac{q_{jk}^2/f_k}{\sum_{k'} q_{jk}^2/f_{k'}}
pi,k=∑k′qjk2/fk′qjk2/fk
其中,
f
k
=
∑
i
=
1
M
q
i
k
f_k = \sum_{i=1}^{M}q_{ik}
fk=∑i=1Mqik,
M
M
M 是batch size 的大小。
最后使用KL散度损失函数,使Q的分布不断向P的分布靠近。
这种做法有三种好处:
- 提高聚类的纯度
- 注重使用置信度高的数据
- 归一化每个之心的损失贡献,防止大簇扭曲数据的特征分布空间。(对这一点我存在质疑,当面对长尾数据集的时候,归一化每个质心的损失贡献会不会起到反作用?)
Contrastive head
这一块的工作相对来说多一点,会涉及到数据增强。
一个数据
x
i
x_i
xi,经过两种数据增强得到
x
i
a
,
x
i
b
x_i^{a}, x_i^b
xia,xib,在经过编码得到
z
i
{
a
,
b
}
=
Φ
(
x
i
{
a
,
b
}
)
z_i^{\{a, b\}} = \Phi(x_i^{\{a, b\}})
zi{a,b}=Φ(xi{a,b})。这篇论文采用了基于上下文的文本增强方式,并和反译法和增删词法做了比较。并说明对于自己的模型,基于上下文方式的文本增强效果更好。
聚类头的就够很简单:一个三层的非线性MLP。
具体的学习方式就是对比学习的基本范式:
l
^
i
a
=
−
log
exp
(
s
(
z
i
a
,
z
i
b
)
/
τ
I
)
∑
j
=
1
M
[
exp
(
s
(
z
i
a
,
z
j
a
)
/
τ
I
)
+
exp
(
s
(
z
i
a
,
z
j
b
)
/
τ
I
)
]
l
^
i
b
=
−
log
exp
(
s
(
z
i
a
,
z
i
b
)
/
τ
I
)
∑
j
=
1
M
[
exp
(
s
(
z
i
b
,
z
j
a
)
/
τ
I
)
+
exp
(
s
(
z
i
b
,
z
j
b
)
/
τ
I
]
\hat{l}_i^a = -\log \frac{\exp(s(z_i^a, z_i^b)/\tau_I)}{\sum_{j=1}^{M} [\exp(s(z_i^a, z_j^a)/\tau_I) + \exp(s(z_i^a, z_j^b)/\tau_I) ]} \\ \hat{l}_i^b = -\log \frac{\exp(s(z_i^a, z_i^b)/\tau_I)}{\sum_{j=1}^{M} [\exp(s(z_i^b, z_j^a)/\tau_I) + \exp(s(z_i^b, z_j^b)/\tau_I ]}
l^ia=−log∑j=1M[exp(s(zia,zja)/τI)+exp(s(zia,zjb)/τI)]exp(s(zia,zib)/τI)l^ib=−log∑j=1M[exp(s(zib,zja)/τI)+exp(s(zib,zjb)/τI]exp(s(zia,zib)/τI)
总的损失函数:
L
i
n
s
=
1
2
M
∑
i
=
1
N
(
l
^
i
a
+
l
^
i
b
)
L_{ins} = \frac{1}{2M} \sum_{i=1}^{N} (\hat{l}_i^a + \hat{l}_i^b)
Lins=2M1i=1∑N(l^ia+l^ib)
其中,
τ
I
\tau_I
τI 是温度参数,
M
M
M 是batch size的大小,
s
(
⋅
)
s(\cdot)
s(⋅) 是相似性度量,具体表达为:
s
(
z
i
,
z
j
)
=
z
i
T
z
j
/
∣
∣
z
i
∣
∣
2
⋅
∣
∣
z
j
∣
∣
2
s(z_i, z_j) = z_i^Tz_j / ||z_i||_2 \cdot ||z_j||_2
s(zi,zj)=ziTzj/∣∣zi∣∣2⋅∣∣zj∣∣2。
结果展示

效果显而易见。