数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务需要处理大量相同键的数据 。
任务读取大文件,最常见的就是读取压缩的不可分割的大文件。任务需要处理大量相同键的数据,这种情况有以下4种表现形式:
-
数据含有大量无意义的数据,例如空值(NULL)、空字符串等
-
含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要 经过Shuffle阶段的处理,引起数据倾斜
-
数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜
-
两表进行Join,都含有大量相同的倾斜数据键
1、不可拆分大文件引发的数据倾斜
当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会 远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。这种情况也就是Map读取文件的数据倾斜。例如存在这样一张表t_des_info 。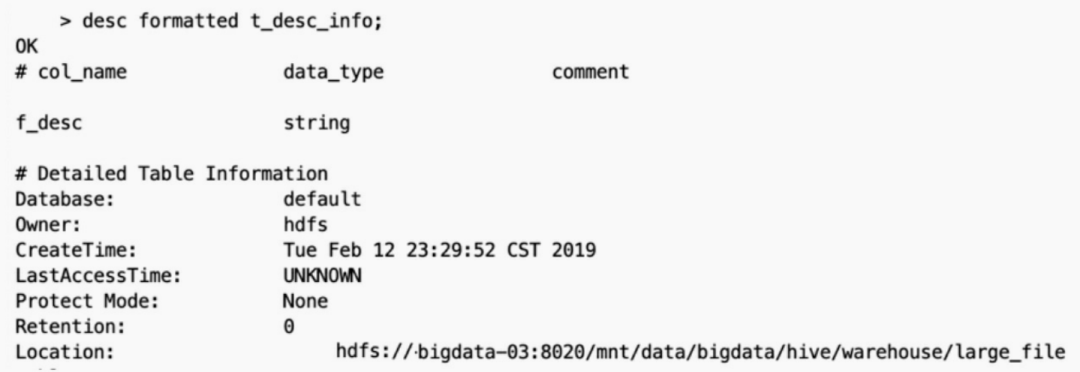 t_des_info表由3个GZIP压缩后的文件组成 。
t_des_info表由3个GZIP压缩后的文件组成 。 其中,
其中,large_file.gz文件约200MB,在计算引擎在运行时,预先设置每 个Map处理的数据量为128MB,但是计算引擎无法切分large_file.gz文件,所 以该文件不会交给两个Map任务去读取,而是有且仅有一个任务在操作 。
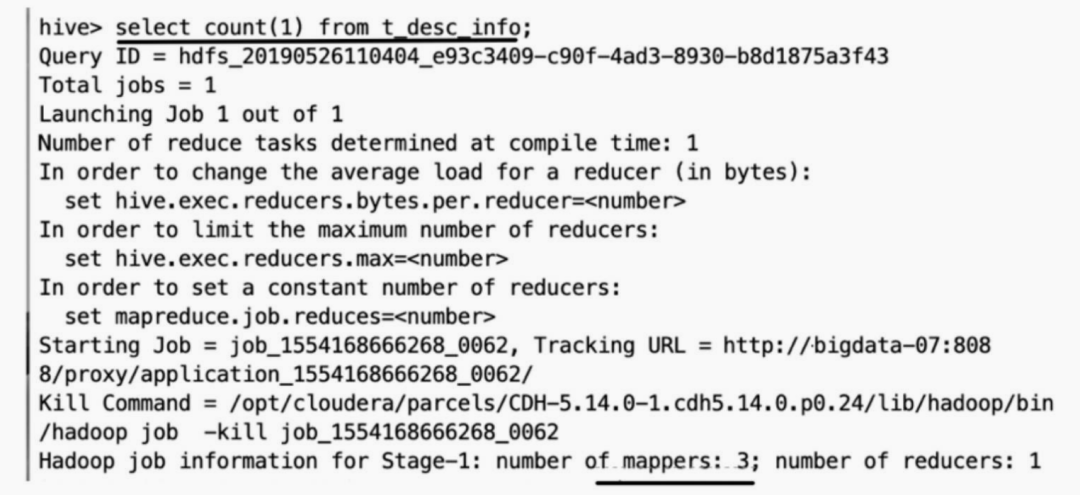
t_des_info表有3个gz文件,任何涉及处理该表的数据都只会使用3个 Map。
 为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时 候可以采用
为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时 候可以采用bzip2和Zip等支持文件分割的压缩算法。
2、业务无关的数据引发的数据倾斜
实际业务中有些大量的NULL值或者一些无意义的数据参与到计算作业 中,这些数据可能来自业务未上报或因数据规范将某类数据进行归一化变成空值或空字符串等形式。这些与业务无关的数据引入导致在进行分组聚合或者在执行表连接时发生数据倾斜。对于这类问题引发的数据倾斜,在计算过 程中排除含有这类“异常”数据即可 。
3、 多维聚合计算数据膨胀引起的数据倾斜
在多维聚合计算时存在这样的场景:select a,b,c,count(1)from T group by a,b,c with rollup。对于上述的SQL,可以拆解成4种类型的键进行分组聚合,它们分别是(a,b,c)、(a,b,null)、(a,null,null) 和(null,null,null)。
如果T表的数据量很大,并且Map端的聚合不能很好地起到数据压缩的 情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢 出的异常。如果T表含有数据倾斜键,会加剧Shuffle过程的数据倾斜 。
对上述的情况我们会很自然地想到拆解上面的SQL语句,将rollup拆解成如下多个普通类型分组聚合的组合。
select a, b, c, count(1) from T group by a, b, c;
select a, b, null, count(1) from T group by a, b;
select a, null, null, count(1) from T group by a;
select null, null, null, count(1) from T; 这是很笨拙的方法,如果分组聚合的列远不止3个列,那么需要拆解的 SQL语句会更多。在Hive中可以通过参数 (hive.new.job.grouping.set.cardinality)配置的方式自动控制作业的拆解,该 参数默认值是30。该参数表示针对grouping sets/rollups/cubes这类多维聚合的 操作,如果最后拆解的键组合(上面例子的组合是4)大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列 有较大的倾斜,可以适当调小该值 。
4、无法削减中间结果的数据量引发的数据倾斜
在一些操作中无法削减中间结果,例如使用collect_list聚合函数,存在如下SQL:
SELECT
s_age,
collect_list(s_score) list_score
FROM
student_tb_txt
GROUP BY
s_age 在student_tb_txt表中,s_age有数据倾斜,但如果数据量大到一定的数 量,会导致处理倾斜的Reduce任务产生内存溢出的异常。针对这种场景,即 使开启hive.groupby.skewindata配置参数,也不会起到优化的作业,反而会拖累整个作业的运行。
启用该配置参数会将作业拆解成两个作业,第一个作业会尽可能将 Map 的数据平均分配到Reduce阶段,并在这个阶段实现数据的预聚合,以减少第二个作业处理的数据量;第二个作业在第一个作业处理的数据基础上进行结果的聚合。
hive.groupby.skewindata的核心作用在于生成的第一个作业能够有效减少数量。但是对于collect_list这类要求全量操作所有数据的中间结果的函数来说,明显起不到作用,反而因为引入新的作业增加了磁盘和网络I/O的负担,而导致性能变得更为低下 。
解决这类问题,最直接的方式就是调整Reduce所执行的内存大小,使用 mapreduce.reduce.memory.mb这个参数(如果是Map任务内存瓶颈可以调整 mapreduce.map.memory.mb)。但还存在一个问题,如果Hive的客户端连接 的HIveServer2一次性需要返回处理的数据很大,超过了启动HiveServer2设置的Java堆(Xmx),也会导致HiveServer2服务内存溢出。
5、两个Hive数据表连接时引发的数据倾斜
两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在 Shuffle阶段必然会引起数据倾斜 。
遇到这种情况,Hive的通常做法还是启用两个作业,第一个作业处理没有倾斜的数据,第二个作业将倾斜的数据存到分布式缓存中,分发到各个 Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。