在for循环中,接着开thread,开完就start,当时有个困惑,就是比如开的一个thread的这个start执行完,但是这个for循环还没执行完,那程序会跑到for循环的后面逻辑吗?
比如下面13行for循环开始开第一个first_thread,并且first_thread也在start,然后这个start结束了,但是for循环还没结束 ,那么程序的逻辑会跑到19行吗?不会的,因为主进程还在for循环跑,线程跑完了,它应该就结束了,它不是主进程。所以会等着for循环执行完,才执行19行。从最后的执行结果就可以看出是等待for循环结束了才执行19行。
import time
from threading import Thread
def count(x, y):
c = 0
while c < 3:
c += 1
x += x
y += y
if __name__ == '__main__':
counts = []
for x in range(10):
thread = Thread(target=count, args=(1, 1))
time.sleep(3)
print('one')
counts.append(thread)
thread.start()
for thread in counts:
print('two')
thread.join()
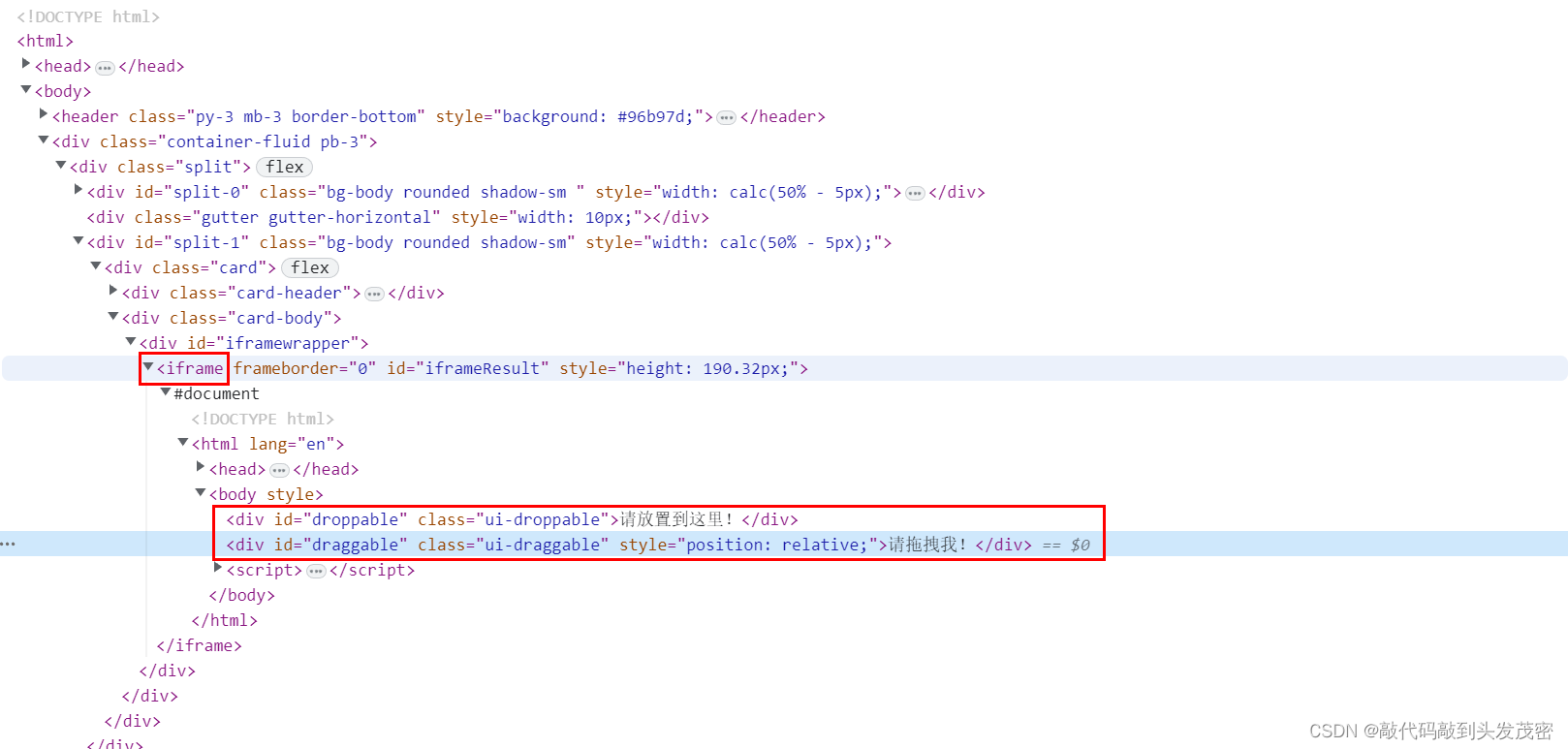
另外join的方法:“This blocks the calling thread until the thread whose join() method is called terminates -- either normally or through an unhandled exception or until the optional timeout occurs.”,我们也看到,一旦线程执行完,其会自动终止,那么couts中记录的每个thread的变量是有一些属性,这些属性记录线程是否执行完,如下图:
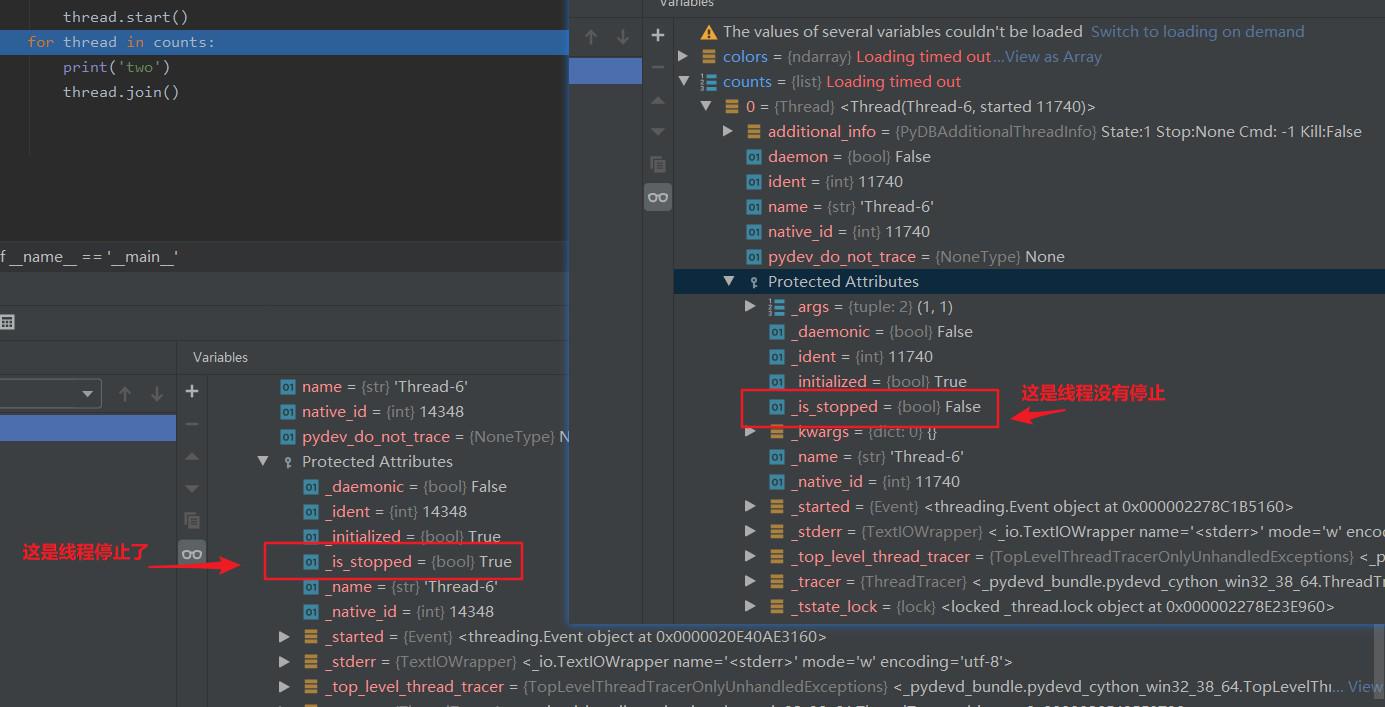
所以我之前的困惑是,既然线程执行完,那么counts中记录的变量应该就失效了,对应的其变量调用join()方法应该也调用不了,这么理解其实是错误的。正确的是这些变量还有效,只不过其start()方法已经执行完了。
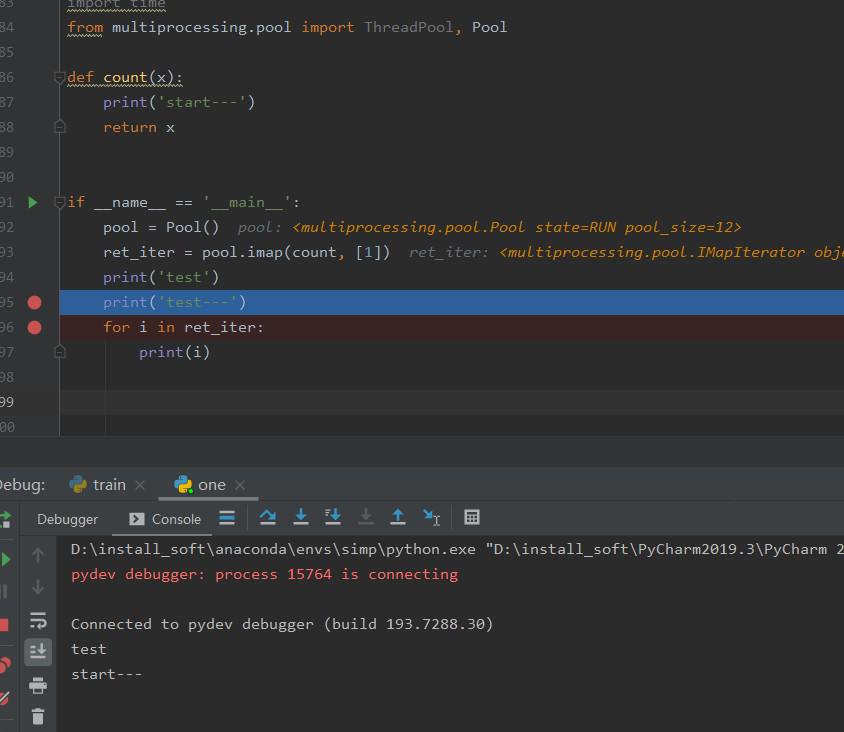
另外Pool.imap一旦定义了,这个方法会返回一个迭代器,不管这个迭代器有没有在后面使用,只有执行这句的下一句其imap已经开了进程在跑,其结果会写到内存中,需注意内存溢出。
from multiprocessing.pool import ThreadPool, Pool
def count(x):
print('start---')
return x
if __name__ == '__main__':
pool = Pool()
ret_iter = pool.imap(count, [1])
print('test')
print('test---')
for i in ret_iter:
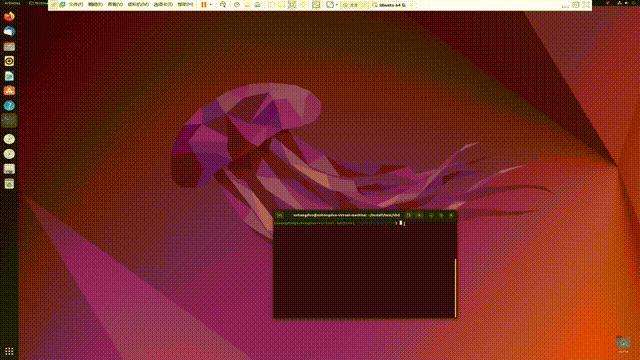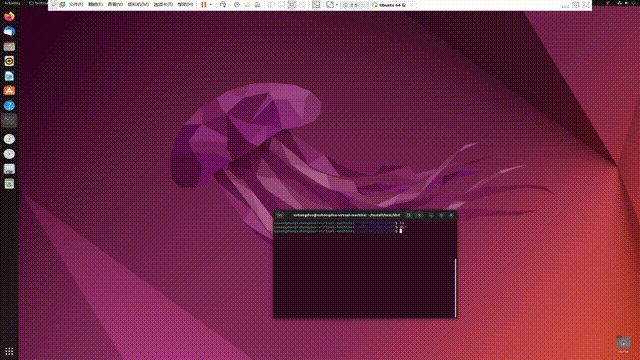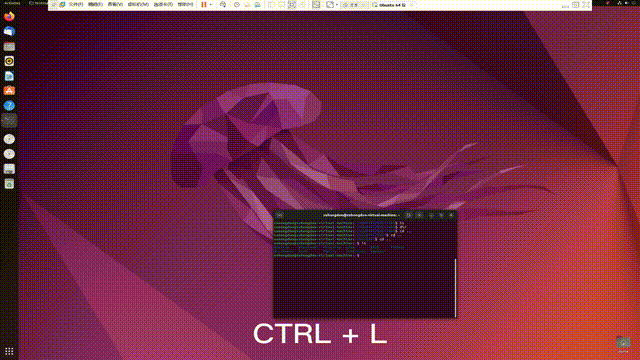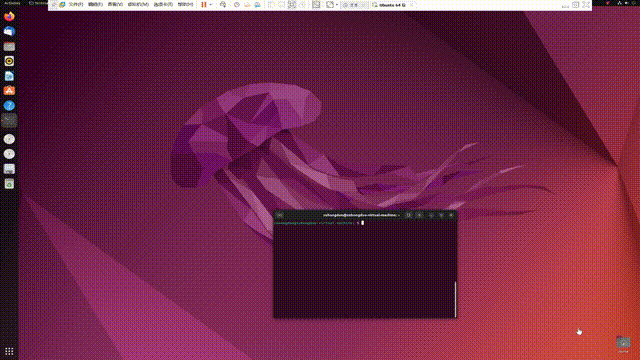
print(i)从下图打的断点可以看出,其已经在开进程跑了,不过如果直接跑,不debug,那么可能打印顺序不对,因为开的进程跑的速度问题
参考:
https://blog.csdn.net/qq_26460841/article/details/110420572
https://blog.csdn.net/weixin_39765280/article/details/111629605?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-111629605-blog-110420572.pc_relevant_aa&spm=1001.2101.3001.4242.1&utm_relevant_index=3