Sentence Simplification via Large Language Models 论文精读
- Information
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Sentence Simplification via LLMs
- 4 Experiments
- 4.1 Evaluation Settings
- 4.2 Automatic Evaluation
- 4.3 Human Evaluation
- 4.4 Qualitative Study
- 4.5 Ablation Study
- 5 Conclusion
- References
- 自结[^1]
Information
标题: 使用大型语言模型简化句子
时间: 暂无
会议: 预印本
作者: Yutao Feng1, Jipeng Qiang1, Yun Li1, Yunhao Yuan1, and Yi Zhu1
单位: 1扬州大学信息工程学院
邮箱: 1fyt1600513459@yeah.net, {jpqiang, liyun, yhyuan, zhuyi}@yzu.edu.cn
链接: https://arxiv.org/pdf/2302.11957.pdf
Abstract
句子简化的目的是将复杂的句子改写成简单的句子,同时又保留原有的意思。大型语言模型(LLMs)已经展示了执行各种自然语言处理任务的能力。Q:然而,目前还不清楚LLMs是否可以作为一个高质量的句子简化系统。 在这项工作中,我们通过在多个基准测试集上评估LLM的零镜头/少镜头学习能力来实证分析它们。R:实验结果表明,LLMs比目前最先进的句子简化方法更有效,并且被认为与人类注释者相当。
1 Introduction
句子简化 (SS) 是将句子改写为一种新的形式的任务,该形式更易于阅读和理解,同时保留其含义,可用于增加阅读障碍 (Rello等人,2013),自闭症 (Evans等人,2014) 或低识字技能 (Watanabe等人,2009)。
近年来,神经SS方法利用并行SS数据集来训练序列到序列模型(Wang et al., 2016;Zhang和Lapata, 2017;Zhao等人,2018)或微调预先训练的语言模型(如BART(Lewis等人,2020))(Martin等人,2020;Lu等人,2021年;马丁等人,2022)。然而,很多工作(Woodsend和Lapata, 2011;Xu et al., 2015;Qiang和Wu, 2021)指出,将英语维基百科和简单英语维基百科中的句子进行对齐的公共英语SS基准(WikiLarge Zhang and Lapata(2017))存在缺陷,因为其中存在较大比例的不准确或不充分的简化,导致SS方法的泛化性能较差。
大型语言模型(LLMs)已经证明了它们通过零次/少次学习解决一系列自然语言处理任务的能力(Brown等人,2020年;Thoppilan等人,2022年;乔杜里等人,2022年)。然而,与现有的SS方法相比,LLM在SS任务中的表现仍不清楚。为了解决这一研究空白,我们通过评估LLM在现有SS基准上的表现,对其零次/少次学习能力进行了系统的评估。我们对ChatGPT和最先进的GPT3.5模型(text-davinci-003)的性能进行了实证比较。
据我们所知,这是LLMs对SS任务能力的首次研究,旨在提供一个初步的评估,包括简化提示、多语言简化和简化鲁棒性。主要发现和见解如下:
(1)基于一次学习的GPT3.5或ChatGPT优于最先进的SS方法。我们发现,这些模型在删除非必要信息和添加新信息方面表现出色,而现有的监督SS方法倾向于保留内容而不改变。
(2) ChatGPT是一个支持多种语言的整体模型,是一种综合的多语言文本简化技术。在评估ChatGPT在跨两种语言(葡萄牙语和西班牙语)的简化任务上的性能后,我们发现它大大超过了最好的基线方法。这也证实了LLM可以适用于其他语言。
(3) 通过对LLMs的简化和人类的简化进行人工评估,LLMs的简化被判断为与人类书面简化相当。
此外,本文的结果可通过LLMs访问https://github.com/BrettFyt/SS获得。
2 Related Work
有监督的句子简化方法: 有监督的SS方法通常将SS任务视为单语机器翻译,这需要大量对齐的复杂-简单句子对的平行语料库(Nisioi et al., 2017)。这些方法通常将transformer(Vaswani et al., 2017))作为骨干,然后将不同的子模块集成到其中,如强化学习(Zhang和Lapata, 2017)、外部简化规则数据库(Zhao et al., 2018)、添加新的损失(Nishihara et al., 2019)或词汇复杂性特征(Martin et al., 2020)。另一种方法是训练序列编辑模型,通过预测每个单词的操作来简化句子(Dong et al., 2019)。这些方法严重依赖于公共训练集,即WikiLarge(Zhang and Lapata, 2017)和WikiSmall(Zhu et al., 2010)。然而,最近的研究指出了它们的缺陷,因为它们包含了大量不准确或不充分的简化对(Woodsend和Lapata,2011; Xu等,2015; Qiang和Wu,2021)。
为了缓解这种约束,近年来的研究集中在开发新的并行SS语料库上。通过这种方式,Martin等人(2022)使用句子嵌入建模来度量大约10亿个CCNET(Wenzek等人,2020)句子之间的相似度,并随后构建了一个新的并行SS语料库。Lu等人(2021)利用机器翻译语料库通过巴赫-翻译技术构建SS语料库。与WikiLarge相比,这些语料库有助于提高监督SS方法的性能。
无监督句子简化方法: 无监督句子简化方法利用非对齐的复杂-简单对语料库。其中一种方法是采用风格转换技术,通过引入对抗性和降噪的辅助损失来实现内容缩减和词汇简化(Surya等人,2019年)。但该方法的可控性较差,不能进行句法简化。有些方法只关注词法简化(Qiang等人,2021b,a)。对于管道方法,一个提出的框架使用了基于修订的方法,如词法简化、句子分割和短语删除(Narayan和Gardent, 2016),而另一个框架通过在这些基于修订的方法中添加迭代机制来改进(Kumar等人,2020)。但这些方法在实际应用中存在太多的简化错误。
大型语言模型: LLMs (Brown et al., 2020;Thoppilan等人,2022年;Chowdhery等人,2022)与之前的预训练模型相比有两个不同的特征。首先,LLM在模型参数和训练数据方面具有更大的规模。其次,不像以前的预训练模型需要微调,LLM可以提示零镜头或少镜头来解决任务。目前的工作(Ouyang et al., 2022)表明,经过指令调整的LLM在许多自然语言任务上都优于经过微调的预训练语言模型。但是,目前还没有关于LLM对SS任务能力的研究。
3 Sentence Simplification via LLMs
通过展示LLM的零镜头传输能力,它们也对低资源任务更具吸引力。考虑到句子简化任务缺乏大规模训练语料库,我们将测试LLM在句子简化任务上的性能。
特定的模板模式,通常称为提示,通常用于指导模型预测特别理想的输出或答案格式,而不需要对标记的示例进行专门的培训。利用这种范式转换,我们对OpenAI最大的可用模型GPT3.5 (text-davinci-003)和ChatGPT进行了不同的提示。
简化提示符: 为了设计触发LLMs简化句子能力的提示符,我们测试多个提示符来分析结果。最后,我们精心制作了两个手工说明提示,如表1所示。

表1:候选句子简化提示符。
对于这两个提示符,{Complex Sentence}表示我们需要填充一个复杂句子的空白,而{Outputs}是包含LLM输出的位置。
在第一个提示符(T1)中,我们利用了{Guidance-Complex-Simple}映射,在该映射中,LLMs将复杂的句子简化为简单的句子。在第二个提示符(T2)中,我们构想了{Sentence-Question-Answer}映射方法,将复杂的句子以问题的形式简化。此外,模型的输出是不可预测的。为了实现没有任何多余细节的简化句子的唯一输出,提示T1和T2分别使用了一个专门的引导词,即“Simple:”和“Answer:”,它们通过填空实现SS。在执行多语言SS任务时,我们将这两个提示翻译成特定SS任务中使用的相同语言。
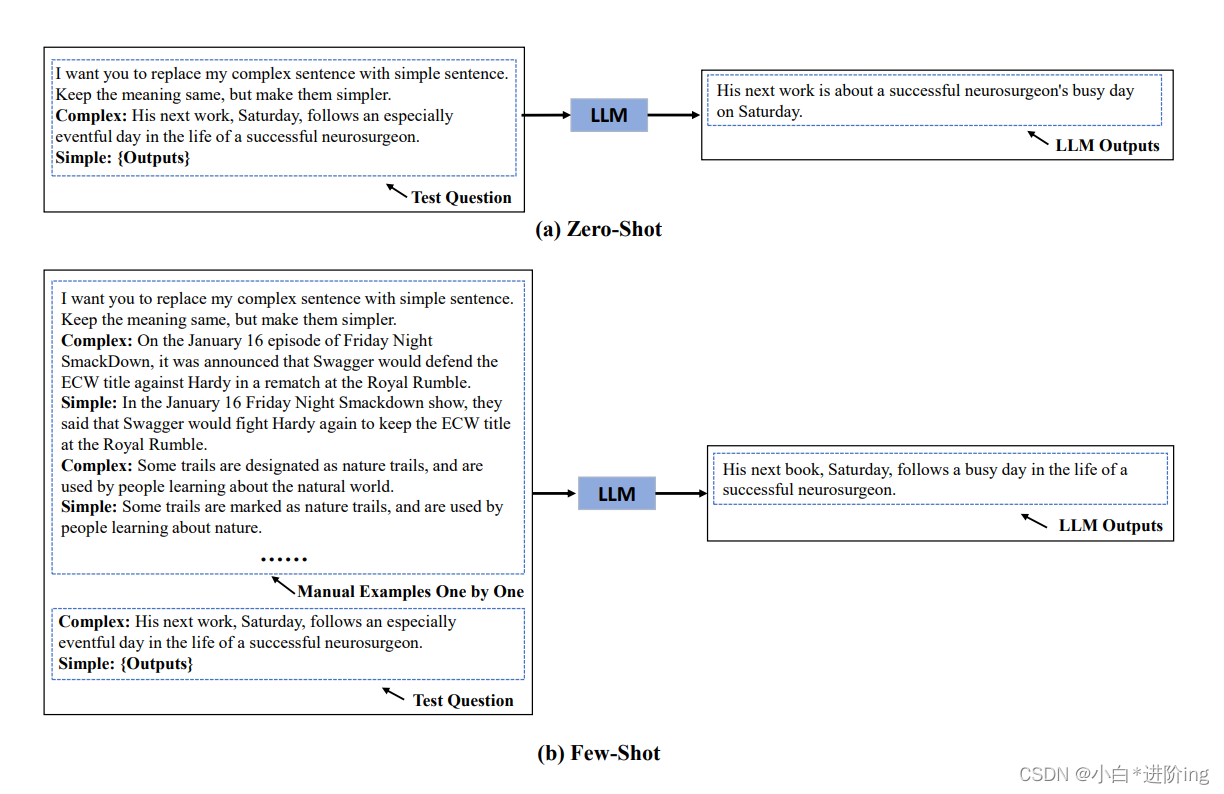
图1 (a)是一个基于LLM的零镜头句子简化示例。(b)是一个基于LLM的少镜头句子简化的例子,它叠加了多个组合。图中的{Outputs}表示LLMs输出简化句。
Zero-shot: 当我们实现Zero-shot SS时,我们只需要一个{Guidance-Complex-Simple}组合或一个{Sentence-Question-Answer}组合即可诱导LLMs直接生成简化句(如图1 (a)所示)。
Few -shot: 对于few -shot SS,我们需要堆叠多个组合来提供简化的例子(如图1 (b)所示)。值得注意的是,我们不需要重复提示T1中的指导,我们只需要在指导下堆叠{Complex-Simple}组合。相反,对于提示符T1,我们需要堆叠整个{Sentence-Question-Answer}组合。
对于这两种提示符,我们在{Simplified Sentence(s)}部分提供了简化的示例,用于少数镜头设置。由于句子简化形式的多样性,我们还测试了多个人工简化引用的方法。通过这种方式,我们可以将提示中的句子更改为句子,以适应手工引用的上下文。实际上,使用多个简化引用会导致LLM生成多个简化候选对象。为了解决这个问题,我们选择为每个复杂句子选择第一个简化的候选句子,这在我们的实验中产生了相对优越的结果(章节4.5)。
4 Experiments
4.1 Evaluation Settings
数据集: 对于英语(我们注为“En”)SS任务,我们选择了TURKCORPUS(所谓的维基大测试集)(Xu等人,2016)和ASSET(Alva-Manchego等人,2020)作为多引用SS数据集来评估LLMs的性能。turk语料库和ASSET都是英语SS最常用的评价数据集,包括2000个有效句子和359个测试句子。土耳其语料库(TURKCORPUS)使用亚马逊机械土耳其语(Amazon Mechanical Turk)为每个复杂句子提供8个人工简化版本。ASSET是turk语料库的一个改进版本,专注于词汇意译、句子分割、压缩等多重简化操作,其中每个复杂句子都有10个人工简化版本的句子。
为了评估LLM的多语言泛化效果,我们选择了葡萄牙语(我们标记为“Pt”)和西班牙语(我们标记为“Es”)的多语(SS)任务评估。对于葡萄牙语,我们使用葡萄牙语版本的ASSET作为我们的测试集,包含359个葡萄牙语复句,这也用于评估MUSS方法(Martin et al., 2022)1。对于西班牙语,我们选择了SIMPLEXT语料库(Saggion et al., 2015)进行评估。SIMPLEXT是一个高质量的1对1西班牙语SS测试集,包含复杂的1416个句子。专家为有学习障碍的人手工简化了它。我们从这两个数据集中随机选取100个句子进行评估,并将提示T1翻译成葡萄牙语和西班牙语(如表4所示)。

基线: 为了评估英语SS任务,我们将LLM方法与有监督和无监督SS方法进行了比较。对于有监督的SS方法,我们选择了三种经典方法(PBMT-R(Wubben et al., 2012)、DressLS(Zhang and Lapata, 2017)、DMASS-DCSS(Zhao et al., 2018)、ACCESS(Martin et al., 2020))和最新的先进方法MUSS-S(Martin et al., 2022)。对于无监督SS方法,我们比较了三种方法(UNTS(Surya et al., 2019)、BTTS10(Kumar et al., 2020)、MUSS-Unsup(Martin et al., 2022)),其中MUSS-US被认为是最先进的无监督SS方法。为了评估多语言SS任务,我们还选择了MUSS-US(Martin et al., 2022),这种方法可以完成最近的多语言SS任务,进行比较。
评价指标: 为了评价句子简化方法,SARI(Xu et al., 2016)是研究中的主要指标。SARI(越高越好)将生成的句子与引用句子进行比较,并返回三个操作(保存、添加和删除)的n-gram F1得分的算术平均值,其中1≤n≤4。
我们还报告了Flesch-Kincaid Grade Level (FKGL)(Kincaid et al., 1975)来评估生成的句子的可读性。FKGL(越低越好)是衡量可读性的经典算法,它通过计算理解文本所需的年龄来反映文本的可读性。与最近的研究一样(Martin等人,2020年),我们没有引用BLEU(Papineni等人,2002年),因为最近的研究表明,BLEU与句子简洁性没有很好的相关性(Sulem等人,2018年)。由于FKGL不适用于西班牙语,我们改用FRES(Kincaid et al., 1975)。
在实验中,我们使用标准简化评价包EASSE2来计算SARI和FKGL指标。我们使用Lu等人(2021)的脚本计算FRES。
其他细节: 我们选择了最新可用的LLMs GPT3.5(text-davinci-003)和ChatGPT,通过访问OpenAI的网站4进行评估,GPT3.5需要付费。我们将text-davinci-003的最大长度设置为1024。此外,在英语少镜头实验中,我们随机选择了来自土耳其语料库和资产有效集的句子作为简化例子。由于SIMPLEXT的有效集合中的复杂-简单对是1对1的关系,所以我们只对其他语言使用一个简化引用。
4.2 Automatic Evaluation
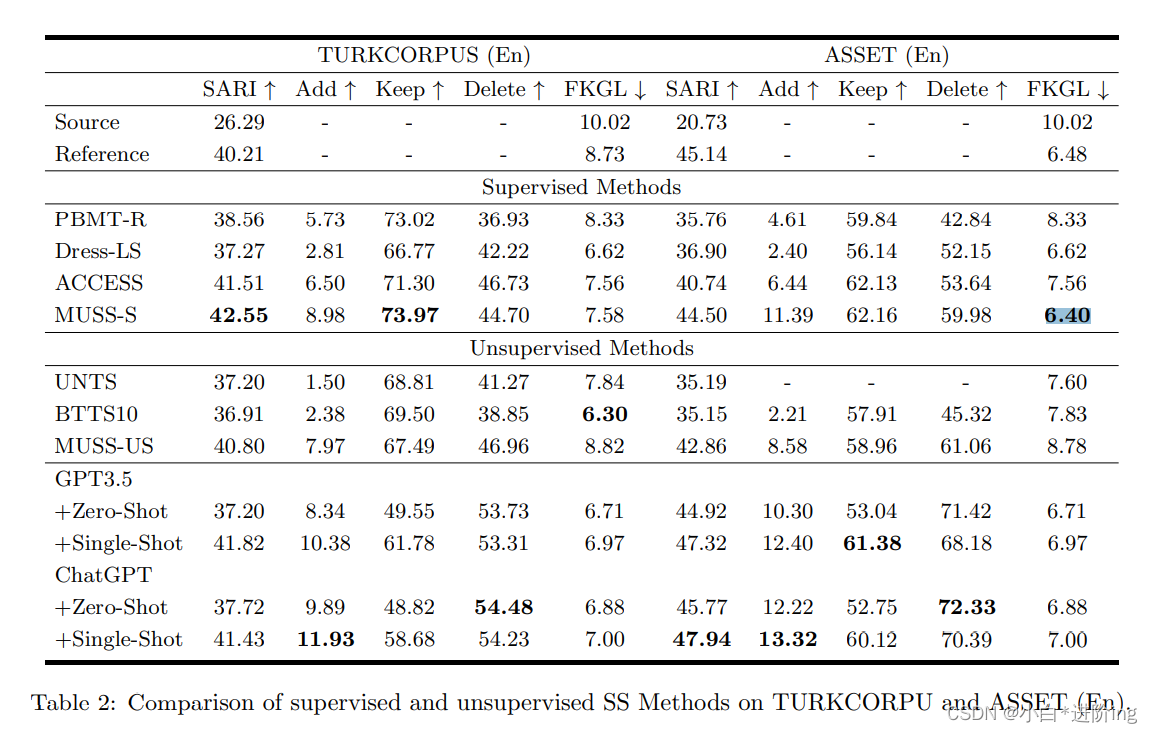
表2显示了所有SS方法的结果。由于GPT3.5和ChatGPT都是由InstractGPT开发而来,所以它们在SS任务中性能相似。总体而言,ChatGPT在单次学习下的ASSET(En)表现优于GPT3.5, SARI得分更高。这一成就使ChatGPT超越了MUSS-S,并将自己确立为ASSET(En)的卓越新标准,实现了前所未有的最先进的性能提高3.44 SARI。然而,与ChatGPT相比,GPT3.5和MUSS-S在turk语料库上表现出更强的性能。
在考察简化操作的试算分数后,我们得出LLMs具有比其他SS方法更好的删除分数。这表明LLMs - SS方法具有删除复杂句子片段的倾向。因此,我们认为这种现象(LLMs在土耳其语料库上表现出不如MUSS-S)源于ASSET (En)中的简化句不如土耳其语料库中的简化句复杂。ASSET (En)的简化参考文献进行了各种简化操作,而TURKCORPUS大多坚持原始结构(Alva-Manchego et al., 2020)。但是,如果我们给出一个简化的例子,LLMs会平衡复杂句的删除和保留。对于加法操作,GPT3.5和ChatGPT都表现出了很高的评分能力,因为它们拥有从丰富的数据集中获得的大量知识。
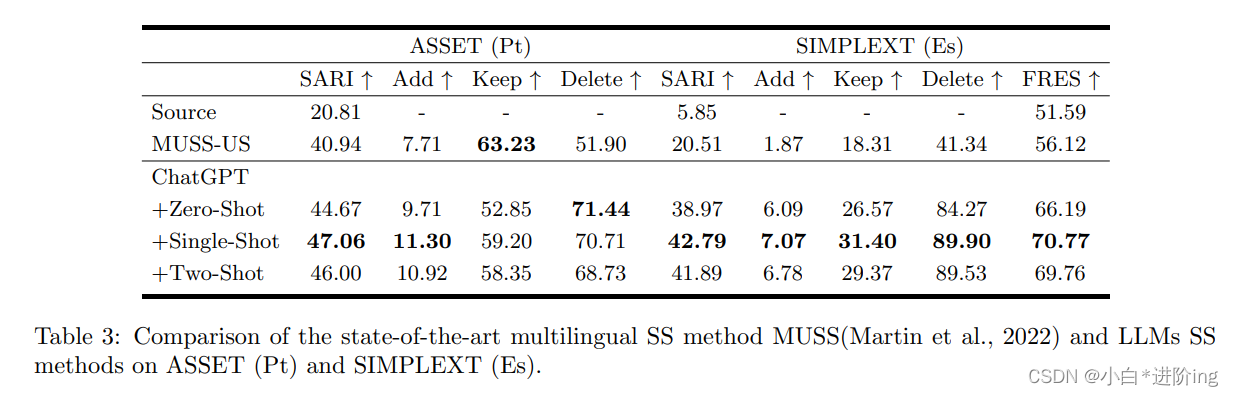
葡萄牙语和西班牙语简化: 结果如表3所示。很明显,ChatGPT在葡萄牙语和西班牙语测试集上都优于MUSS-US的SS结果。首先,由于MUSS-US的无监督性质,我们比较了零镜头方法与ChatGPT。ChatGPT的Zero-Shot方法在两种语言中都显著超过了MUSS-US,分别是+3.73 SARI和+18.46 SARI。此外,在单次射击领域,ChatGPT在ASSET (Pt)上的SARI得分为46.00,在SIMPLEXT上的SARI得分为41.89,分别显著高于MUSS 5分和21分。特别是,在西班牙数据集SIMPLEXT中,ChatGPT在少概率和零概率场景中都远远领先于MUSS-US。上述研究结果表明,ChatGPT在多种语言间具有较强的泛化能力,在多语言SS性能方面超过了MUSS。

4.3 Human Evaluation
由于自动度量可能不足以评估句子生成,因此我们报告了人工评估的结果。在实验中,我们只选择最先进的方法和评估参考。
首先,我们遵循Kumar等人(2020)和Dong等人(2019)建立的评价指标。我们以五分制(1是最差的,5是最好的)来衡量充分性(在简化的句子中保留了原句子的多少含义?)、简洁性(系统输出的句子比原句子更简单吗?)、流畅性(输出的句子语法或格式良好吗?)此外,我们还测量了裁判的主观选择(将简化的句子从1号排名到3号),以关注实际使用,而不是评价标准。
我们从ASSET (En)中随机选取100个复杂句子,然后随机排列由MUSS-S、ChatGPT生成的句子,以及从参考文件中随机选取的简化句子。然后,我们请三名非英语为母语、中等水平的人根据上述指标对句子进行评估。
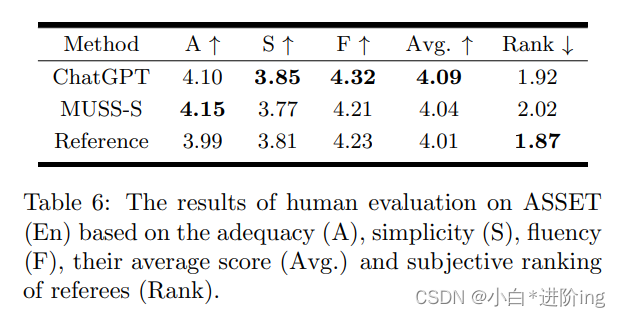
结果如表6所示。如4.2节所述,由于ASSET (En)数据集和ChatGPT倾向于去除复杂句中多余的元素,因此充分性度量在人的评价方面落后于MUSS。相反,由于这一属性,ChatGPT在简单性和流畅性指标上优于MUSS。对于人类的偏好而言,最主要的选择是ChatGPT和参考句子,因为它们的排名更高。这意味着,与MUSS-S相比,ChatGPT更符合个体对简单性的倾向。这说明ChatGPT的SS性能在人的评价方面超过了MUSS,与人的书面简化相当。
4.4 Qualitative Study
直观分析LLM的句子简化能力。表5给出了GPT3.5和ChatGPT组装单镜头英语句子简化示例。
该方法在保留复合句主义的同时,显著降低了复合句的语言复杂度。LLM在词汇简化方面做得很好,例如,用“be”简单地代替“represent”,用“vision”简单地代替“visual acuity”,用“went to”简单地代替“advanced to”,等等。在句法简化方面,LLMs注重使用更简单、更简洁的句法,如将复杂结构“专注于实践教学”简化为“专注于教学”,将状语从句“ordered”的形式转变为两个并列从句“ordered”的形式等。综上所述,我们从这些例子中得出结论,GPT3.5和ChatGPT只能使用一个手动SS例子来进行词汇化简和句法化简,这些化简操作与参考句相似。
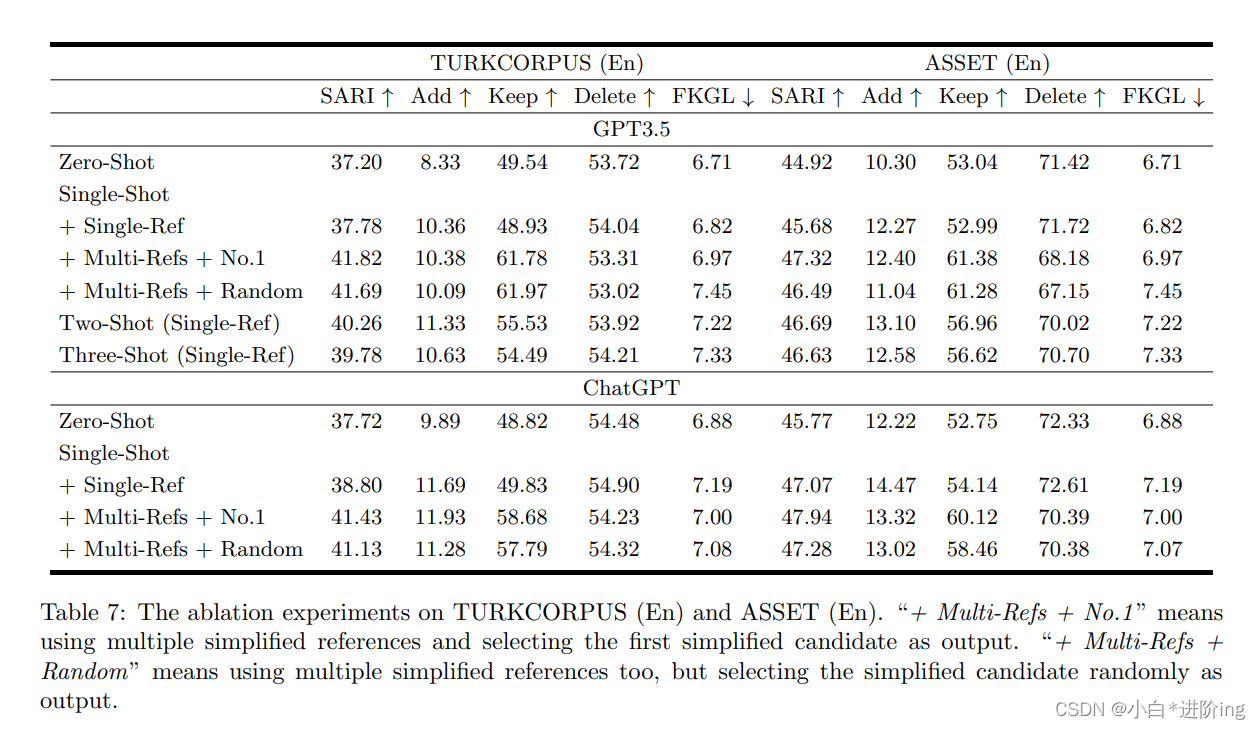
4.5 Ablation Study
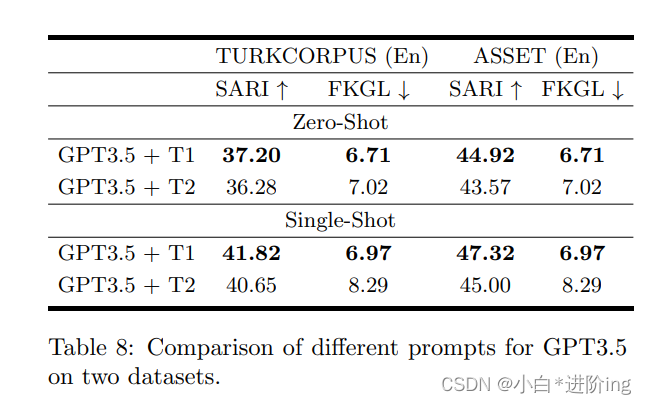
Prompt 研究: 我们比较了SS任务不同提示符之间的性能差异(如表1所示)。由于GPT3.5和ChatGPT的SS性能非常接近,所以我们选择GPT3.5作为提示实验的骨干。不同Prompts的性能比较如表8所示。
一般来说,提示T1对零射和单射SS的疗效都优于提示T2。具体来说,在TURKCORPUS的SARI度量方面,T1比T2有大约1个点的优势。类似地,在ASSET上,Zero-Shot和Single-Shot的T1比T2分别高出1.5和2.0个点。
Few-shot 研究: 为了进一步分析GPT3.5和ChatGPT SS方法在多参考或单参考下的性能,我们在本节中进行了更多实验。我们的实验结果显示在表7中。当与采用单个引用的fewshot方法并置时 (如图2所示),该方法展示了对于复杂句子的LLM的保留操作的实质性改进,从而在LLM的删除和保留操作之间取得平衡 (如图3所示)。此外,在第一个简化候选者的选择被删除的情况下 (称为 “多参考随机”),SS的性能将会降低,从而表明整个方法的有效性,以及LLM在存在多个引用的情况下提供最可行的简化作为优先级的倾向。
值得注意的是,随着镜头数量的增加 (指句子简化示例的计数增加),性能的提高将会减少回报。这一事实适用于英语和其他语言 (如表3所示)。
5 Conclusion
本文研究了LLMs (GPT3.5和ChatGPT)对SS任务的性能。由于GPT3.5和ChatGPT都是InstractGPT的衍生物,它们在SS任务中的表现是相当的。在基准测试实验中,LLMs在多语言SS任务领域的表现优于当前最先进的SS方法。此外,通过人力和定性评价,判断LLM的简化与人的简化句子是同等的。F:在我们接下来的努力中,我们的目标是设计更精细的SS方法,建立在LLMs的基础上,同时也深入研究LLMs提供的各种熟练程度。
References
Fernando Alva-Manchego, Louis Martin, Antoine Bordes, Carolina Scarton, Benoˆıt Sagot, and Lucia Specia. ASSET: A dataset for tuning and evaluation of sentence simplification models with multiple rewriting transformations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4668–4679, July 2020. 4.1, 4.2
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell等。语言模型是少数的学习者。关键词:神经网络,信息处理,神经网络1、2
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann等。Palm:使用路径扩展语言建模。预印本arXiv:2204.02311, 2022。1、2
Yue Dong, Zichao Li, Mehdi Rezagholizadeh, and Jackie Chi Kit Cheung. EditNTS: An neural programmer-interpreter model for sentence simplification through explicit editing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3393–3402, 2019. 2, 4.3
Richard Evans, Constantin Or˘asan, and Iustin Dornescu. An evaluation of syntactic simplification rules for people with autism. In Proceedings of the 3rd Workshop on Predicting and Improving Text Readability for Target Reader Populations (PITR), pages 131–140, 2014. 1
J Peter Kincaid, Robert P Fishburne Jr, Richard L Rogers, and Brad S Chissom. Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel. Technical report, Naval Technical Training Command Millington TN Research Branch, 1975. 4.1
Dhruv Kumar, Lili Mou, Lukasz Golab, and Olga Vechtomova. Iterative edit-based unsupervised sentence simplification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7918–7928, Online, July 2020. Association for Computational Linguistics. 2, 4.1, 4.3
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, 2020. 1
Xinyu Lu, Jipeng Qiang, Yun Li, Yunhao Yuan, and Yi Zhu. An unsupervised method for building sentence simplification corpora in multiple languages. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 227–237, 2021. 1, 2, 4.1
Louis Martin, ´Eric de la Clergerie, Benoˆıt Sagot, and Antoine Bordes. Controllable sentence simplification. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 4689–4698, Marseille, France, May 2020. 1, 2, 4.1
Louis Martin, Angela Fan, Eric´ de la Clergerie, Antoine Bordes, and Benoˆıt Sagot. MUSS: Multilingual unsupervised sentence simplification by mining paraphrases. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1651–1664, Marseille, France, June 2022. 1, 2, 4.1, 3
Shashi Narayan and Claire Gardent. Unsupervised sentence simplification using deep semantics. In Proceedings of the 9th International Natural Language Generation conference, pages 111–120, 2016. 2
Daiki Nishihara, Tomoyuki Kajiwara, and Yuki Arase. Controllable text simplification with lexical con straint loss. In Proceedings of the 57th Annual Meeting ofthe Association for Computational Linguistics: Student Research Workshop, pages 260–266, 2019. 2
Sergiu Nisioi, Sanja ˇStajner, Simone Paolo Ponzetto, and Liviu P. Dinu. Exploring neural text simplification models. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 85–91, 2017. 2
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022. 2
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. 4.1
Jipeng Qiang and Xindong Wu. Unsupervised statistical text simplification. IEEETransactions on Knowledge and Data Engineering, 33(4):1802–1806, 2021. doi: 10.1109/TKDE.2019.2947679. 1, 2
Jipeng Qiang, Yun Li, Yi Zhu, Yunhao Yuan, Yang Shi, and Xindong Wu. Lsbert: Lexical simplification based on bert. IEEE/ACMTransactions on Audio, Speech, and Language Processing, 29:3064–3076, 2021a. 2
Jipeng Qiang, Xinyu Lu, Yun Li, Yunhao Yuan, and Xindong Wu. Chinese lexical simplification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:1819–1828, 2021b. 2
Luz Rello, Clara Bayarri, Azuki G´orriz, Ricardo BaezaYates, Saurabh Gupta, Gaurang Kanvinde, Horacio Saggion, Stefan Bott, Roberto Carlini, and Vasile Topac. Dyswebxia 2.0! more accessible text for people with dyslexia. In Proceedings of the 10th International Cross-Disciplinary Conference on Web Accessibility, pages 1–2, 2013. 1
Horacio Saggion, Sanja Staˇ jner, Stefan Bott, Simon Mille, Luz Rello, and Biljana Drndarevic. Making it simplext: Implementation and evaluation of a text simplification system for spanish. ACM Transactions on Accessible Computing (TACCESS), 6(4):1– 36, 2015. 4.1
Elior Sulem, Omri Abend, and Ari Rappoport. BLEU is not suitable for the evaluation of text simplification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 738–744, Brussels, Belgium, OctoberNovember 2018. Association for Computational Linguistics. 4.1
Sai Surya, Abhijit Mishra, Anirban Laha, Parag Jain, and Karthik Sankaranarayanan. Unsupervised neural text simplification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2058–2068, Florence, Italy, July 2019. Association for Computational Linguistics. 2, 4.1
Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022. 1, 2
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. 2
Tong Wang, Ping Chen, John Rochford, and Jipeng Qiang. Text simplification using neural machine translation. Proceedings of the AAAI Conference on Artificial Intelligence, 30(1), Mar. 2016. 1
Willian Massami Watanabe, Arnaldo Candido Junior, Vin´ıcius Rodriguez Uzˆeda, Renata Pontin de Mattos Fortes, Thiago Alexandre Salgueiro Pardo, and Sandra Maria Alu´ısio. Facilita: reading assistance for low-literacy readers. In Proceedings of the 27th ACM international conference on Design of communication, pages 29–36, 2009. 1
Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzm´an, Armand Joulin, and Edouard Grave. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the Twelfth Language Resources and Evaluation Conference, 2020. 2 Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzm´an, Armand Joulin, and Edouard Grave. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the Twelfth Language Resources and Evaluation Conference, 2020. 2
Kristian Woodsend and Mirella Lapata. Learning to simplify sentences with quasi-synchronous grammar and integer programming. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 409–420, 2011. 1, 2
SanderWubben, Antal van den Bosch, and Emiel Krahmer. Sentence simplification by monolingual machine translation. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1015–1024, 2012. 4.1
Wei Xu, Chris Callison-Burch, and Courtney Napoles. Problems in current text simplification research: New data can help. Transactions of the Association for Computational Linguistics, 3:283–297, 2015. 1, 2
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze Chen, and Chris Callison-Burch. Optimizing statistical machine translation for text simplification. Transactions of the Association for Computational Linguistics, 4:401–415, 2016. 4.1
Xingxing Zhang and Mirella Lapata. Sentence simplification with deep reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 584–594, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. 1, 2, 4.1
Sanqiang Zhao, Rui Meng, Daqing He, Andi Saptono, and Bambang Parmanto. Integrating transformer and paraphrase rules for sentence simplification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3164–3173, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. 1, 2, 4.1
Zhemin Zhu, Delphine Bernhard, and Iryna Gurevych. A monolingual tree-based translation model for sentence simplification. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pages 1353–1361, 2010. 2
自结1
本文主要是利用chatgpt和gpt3.5首次用在文本简化方面,经过人工评估和相关的评估指标详细研究之后发现,这两种表现性能都非常好,甚至可以与人工简化相媲美,但是chatgpt更倾向于使句子的单词和语法更简单,从而删除替换句子在不必要的成分,gpt3.5更倾向于保留句子的基本含义。而且这种能力也可以适应多语言应用,具有很强的泛化能力,简化的句子倾向于按照句子最简程度依次排列,所以一般第一个简化结果就是最好的。同时,作者也发现,随着学习简化示例的增加,简化的性能也会打折扣。由此可见,对于few-shot的设计也是非常重要的。作者也打算研究更精细的方法,进行进一步的研究。
扬州大学研一在读学生,本篇笔记仅以帮助自己更好理解论文,也方便日后复查学习。 ↩︎