DAGA : 基于生成方法的低资源标记任务数据增强 精读笔记
文章目录
- DAGA : 基于生成方法的低资源标记任务数据增强 精读笔记
- 1 Introduction
- 2 Background
- Name Entity Recognition
- Part-of-Speech (POS) Tagging
- Target Based Sentiment Analysis
- 3 Proposed Method
- 3.1 Labeled Sentence Linearization
- 3.2 Language Modeling
- 3.3 Generation
- 3.4 Post-Processing
- 3.5 Conditional Generation
- 4 Experiments
- 4.1 Basic Models
- Language Model
- Sequence Tagging Model
- 4.2 Supervised Experiments
- 4.2.1 Named Entity Recognition
- 4.2.2 Part of Speech Tagging
- 4.2.3 Target Based Sentiment Analysis
- 4.3 Semi-supervised Experiments
- 5 A Closer Look at Synthetic Data
- Conclusion
这篇文章之前已经仔细读过一遍,也写过 阅读笔记,但是回想起来还有很多细节没有注意到,学了一些相关知识之后回来再看一遍
1 Introduction
为解决大量注释数据的需求,在计算机视觉和语音领域中,数据增强技术被广泛用于生成合成数据。计算机视觉与语音的数据增强技术中使用的旋转、裁剪、遮蔽等人工规则虽然能应用于转换原始数据,但在语言领域,这些规则不再适用。原因是在语言领域中,上述人工规则带来的小失真可能会完全改变句子的含义。
在语言领域,以下几类数据增强方法取得了一定效果
- 回译法
- 同义词替换;随机交换、删除、插入;使用VAE或预训练语言模型(主要用于翻译和分类任务)
- 弱标记器注释;对齐的双语语料库诱导注释;同义词替换(可用于序列标记任务)
但是对于低资源条件下的序列标记任务,上述方法仍存在着不少问题
- 弱标记器需要域内知识和域内数据,否则可能出现域移位问题
- 双语语料库很可能不适用于低资源语言
- 同义词替换依赖的额外知识对低资源语言很可能不适用
本文针对序列标记任务,研究基于生成方法的数据扩充。方法具体步骤如下图:

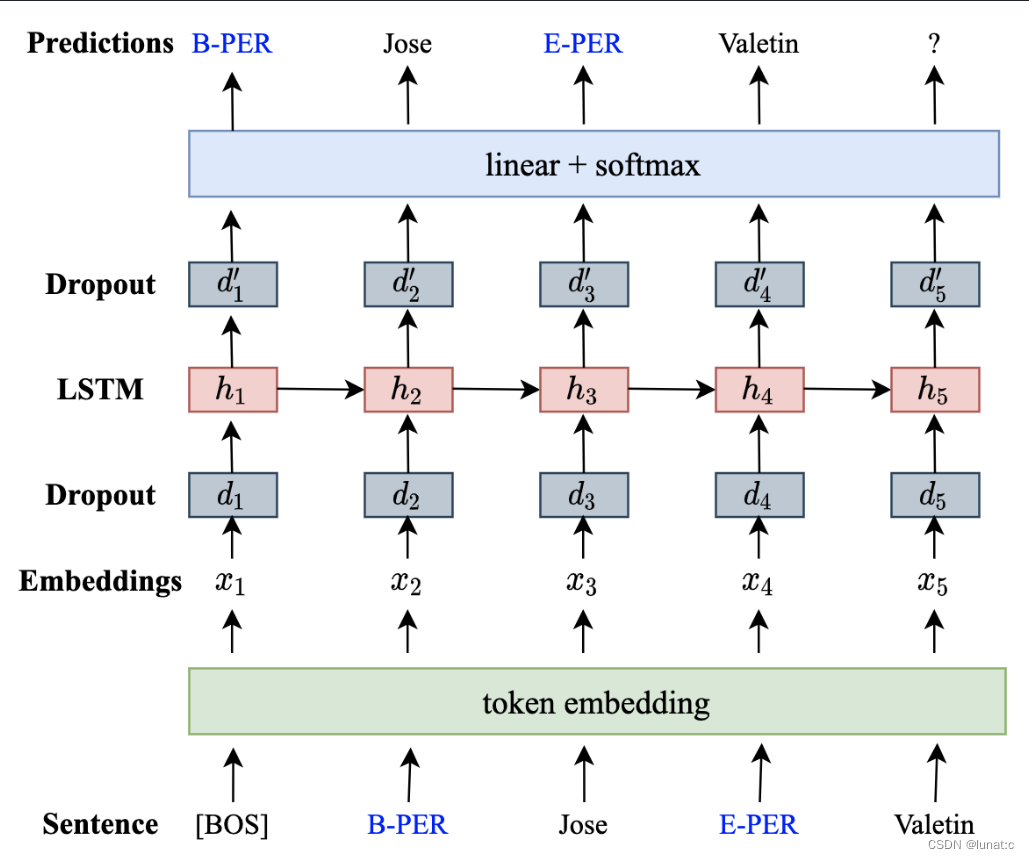
方法先将句子与标记线性化,然后使用线性化的数据训练语言模型(LM),随后使用模型生成合成标记数据。
这个方法有以下特点:
- 统一了句子生成和语言模型标记的过程,即生成数据时,单词与标记同时生成
- 不需要额外资源,但是可以灵活利用未标记数据和知识库等资源
2 Background
Name Entity Recognition
命名实体:文中的人名、组织、地点等
命名实体识别:定位文中的命名实体并分类
难点:NER训练数据量有限
Part-of-Speech (POS) Tagging
词性标注:为给定句子中的每一个词分配一个语法标记
难点:在低资源语言和罕见词上准确率显著降低
Target Based Sentiment Analysis
基于目标的情绪分析:检测句子中的观点目标,预测在目标上的情绪极性
3 Proposed Method
3.1 Labeled Sentence Linearization
方法:句子与标签线性混合,把标签插入到相应的单词前,将标签视为单词的修饰词
目的:使语言模型可以学习源数据中单词和标签的分布
3.2 Language Modeling
方法:RNNLM网络结构:嵌入层、丢弃层、LSTM层、丢弃层、线性层加归一化函数激活
3.3 Generation
方法:输入[BOS]符号,然后使语言模型按照概率自动生成后续序列
3.4 Post-Processing
方法:
- 删除没有标记的句子
- 删除所有单词为[unk]的句子
- 删除标签前缀顺序不合理的句子
- 删除包含相同单词序列但是标签不同的句子
目的:删除明显不合理不正确的生成数据
3.5 Conditional Generation
方法:在序列的开头加上条件标记[labeled]、[unlabeled]和[KB],KB标记表示与知识库匹配的数据。
目的:充分利用可用的未标记数据和知识库,允许语言模型学习序列之间的共享信息。同时在生成时
4 Experiments
4.1 Basic Models
Language Model
语言模型的参数设置:
- LSTM隐藏层状态:512
- 嵌入层:300
- 丢弃层丢弃率:0.5
- 损失函数:随机梯度下降
- 学习率:初始为1,如果开发集的混淆度没有改善,学习率下降1/2
- 批量大小:32
- 最大轮数:30
- 早停:如果混淆度连续三轮没有改善,停止训练
Sequence Tagging Model
标注模型的参数设置:
- LSTM隐藏层状态:512
- 丢弃层丢弃率:0.5
- 损失函数:随机梯度下降
- 学习率:初始为1,如果开发集的混淆度没有改善,学习率下降1/2;如果学习率降至1e-5以下,停止训练
- 批量大小:32
- 最大轮数:100
- 早停:如果混淆度连续三轮没有改善,停止训练
4.2 Supervised Experiments
在三个标记任务上评估,使用随机删除作基线,其中训练数据中5%的单词和相应标签被随机删除。
具体方法如下表
| 方法描述 | |
|---|---|
| gold | 只用源数据 |
| gen | 本文方法,使用语言模型生成合成数据,并对源数据进行过采样 |
| rd | 通过随机删除生成合成数据,并以gen方法相同的比例对源数据进行过采样 |
| rd* | 与rd相近,但是源数据和合成数据等比例采样 |
4.2.1 Named Entity Recognition
数据集:使用四种语言对CoNLL2002/2003 NER数据进行评估,同时对泰语、越南语的NER数据进行了评估。
实验设置:为了在所有数据上评估本文方法,对所有语言采样1k、2k、4k、6k和8k语句,以验证方法在低资源设置下的鲁棒性。对于语言模型生成的每1000个句子,测量前一批中出现的新标记的百分比,如果比例超过99%,停止数据生成,然后进行数据处理并添加到源数据中用于标记训练。对于rd和gen方法,通过在训练集中重复4次打乱次序来对源数据进行过采样。
结果和分析:
对所有语言都显示出一致的性能改进。特别是对于较小的采样集,我们的方法显示出更显著的性能改进。
标签前置 VS 后置:在进行句子线性化时有两种策略:在相应单词前或单词后插入标记。在实验中测试,发现在单词前插入标记的方式在NER任务中表现优于在单词后插入标记。一个可能的原因是,修饰词在名词前充当修饰的模式在语言模型中更常见,这种方式与修饰名词的方式一致,故表现更优。
4.2.2 Part of Speech Tagging
略
4.2.3 Target Based Sentiment Analysis
略
4.3 Semi-supervised Experiments
主要在测试方法对知识库和未标注数据的使用能力,此处不再赘述
5 A Closer Look at Synthetic Data
通过观察这种方法生成的合成数据的特点,总结其提高序列标记性能的原因:
多样性:源数据中,“Sandrine”总是与“Testud”成对出现,但在生成数据中,可以看到生成了新的名称,如“Sandrine Nixon”、“Sandrin Okuda”和“Sandrinne Neuumann”。同时句子中的位置被更换为不同的地点,这使得模型可以学习实体的上下文关系,而非简单地把“Sandrine Testud”记为人名,将“France”记为地点。

有效利用未标记数据:在源数据中并未出现“Alabama”一词。这个词来源于未标记数据,而语言模型发现该词出现位置与其他位置词较为相似,故生成合成数据时,语言模型通过上下文信息对该词进行了使用,甚至使用该词创建了不存在于任何训练数据中的新实体“Bank of Alabama”。
Conclusion
本文证明了语言模型可以用于为序列标记任务生成高质量的合成数据。生成的数据因为不在源数据上修改,引入了更多的多样性,减少过拟合。该方法在各种标记任务上特别是在低资源条件下表现出了很好的性能改进。