目录
- 1、文章贡献
- 2、算法推导
- 3、寻找分裂点算法
- 3.1 精确贪心算法
- 3.2 近似算法
- 4、稀疏感知算法
- 5、特征维度的并行化
- 6、XGBoost VS GBDT
- 7、XGBoost局限

半年前看了这篇XGBoost的原文,网上解读很多,于是迟迟没有将其中的精髓记录下来,准备重点记一记,以免日后遗忘。
1、文章贡献
在原有GBDT的基础上提出了XGBoost,一种高效的极端梯度提升树模型,其属于boosting算法的一种,利用加法模型和前向分布算法将多个弱学习器集成为强学习器实现优化。
主要改进点
- 损失函数泰勒二阶展开考虑更多信息,目标函数加入正则项防止过拟合。
- 近似算法代替精确贪心算法,利用加权分位数对特征进行分桶操作,通过遍历桶来提高效率。
- 稀疏感知算法处理缺失数据提升速度。
2、算法推导
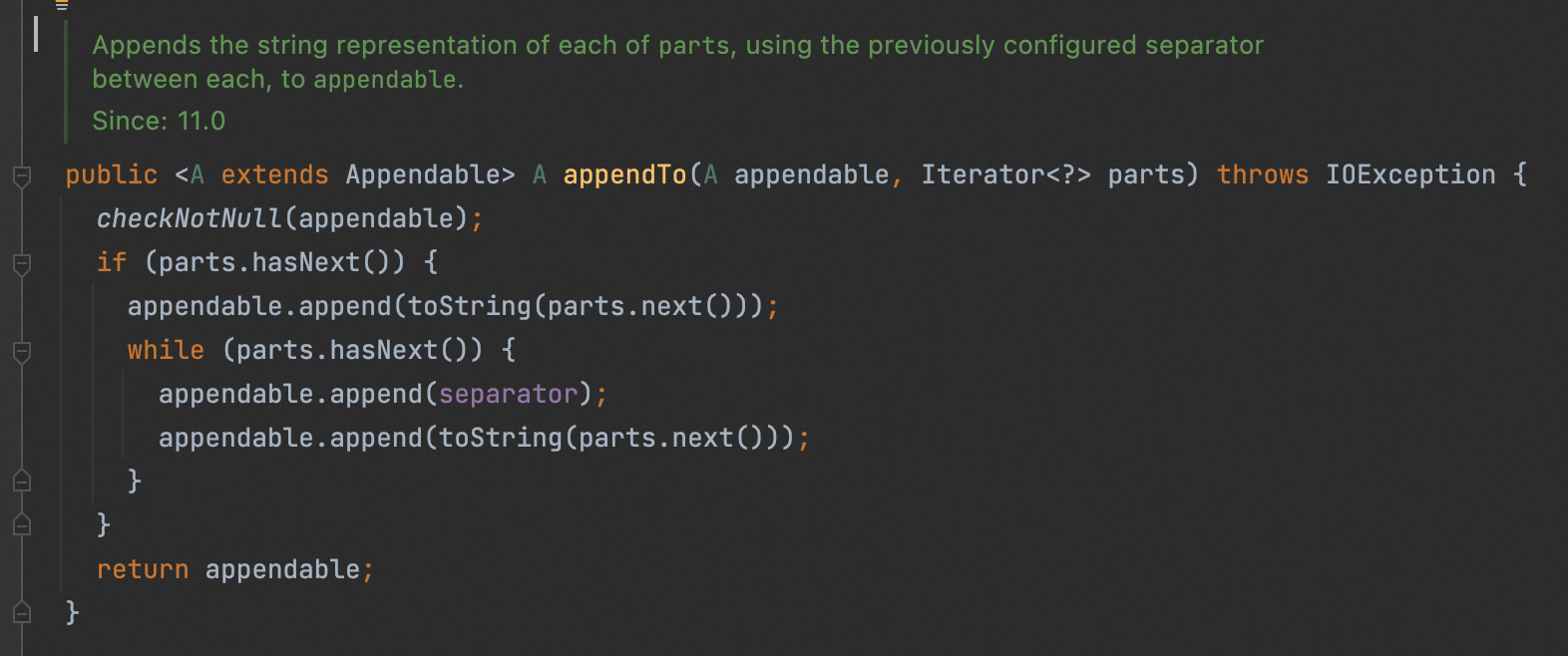
- 定义一个简单的目标函数L,其中l是可微的凸损失函数,Ω是正则项防止过拟合(包括了对叶子节点数和节点值的惩罚)
- 采用前向分布算法将第t颗树的优化表示成t-1颗已经训练好的树加上当前需要优化的基学习器
- 进行泰勒二阶展开(其中gi是一阶偏导数,hi是二阶偏导数)
- 常数项对优化并没有什么用处,将其剔除
- 按样本遍历改成按叶子结点遍历进行合并
- 找到最优权值wj
- 使目标函数最优
- 计算分裂前后的增益
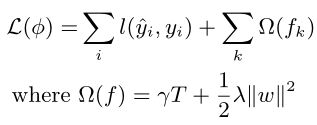
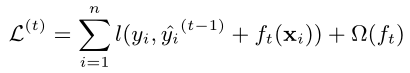
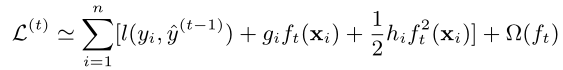
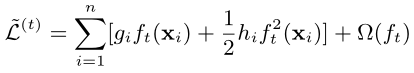
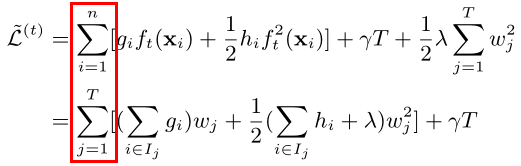
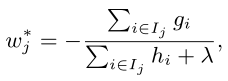
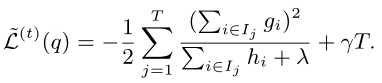
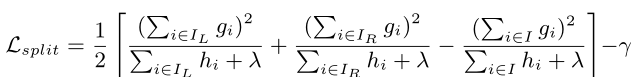
3、寻找分裂点算法
3.1 精确贪心算法
-贪婪地枚举所有可能的特征分裂点,对各节点特征进行预排序,计算分裂增益,最大增益处即为最优分裂点。
- 优点:能找到全局最优解
- 缺点:当数据量很大时无法全部放入内存

3.2 近似算法
根据特征分布策略确定候选分裂点,将对应特征放入相应的桶中,对桶中特征的一、二阶导分贝累加,找到最大增益。
- 定义一个秩函数rk,表示特征值k小于z的比例
- 目标是找到候选分裂点满足
其中ε是一个近似因子,相当于每个特征桶里样本数的比重都限制在一个特定的值内- 而将二阶导hi作为加权分位数的权重原因在于,对原始目标函数进行化简后,hi表示权重位置
- 算法流程如下
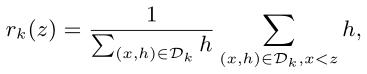
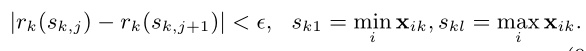
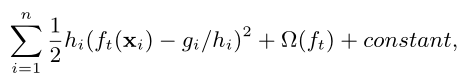

在近似算法中分为两种策略:全局策略与局部策略
- 全局策略是说,学习每棵树之前一旦根节点用了某种分裂形式,那么后面每一层分裂的时候都采用这种切分方法。
- 局部策略刚好相反,每次分裂重新提出候选分裂点,适用于构建更深的树。
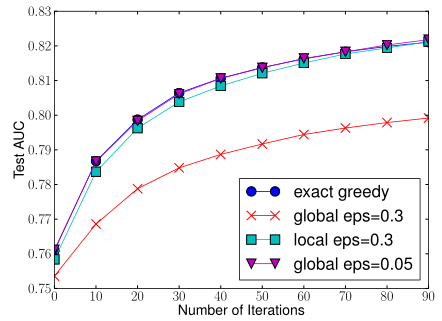
- 不同策略下AUC值变化情况
在分桶数量相近的情况下局部策略的精确度更高(绿色方块);全局策略在分桶数更多的时候可以达到和精确贪心算法相似的精度,但此时的计算复杂度没有减少太多。
4、稀疏感知算法
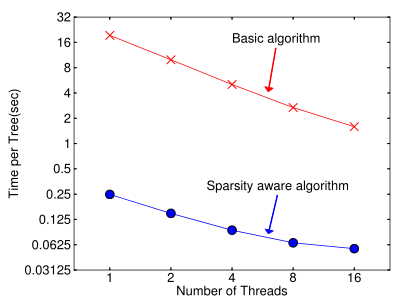
- XGBoost在处理稀疏问题上只考虑对没有缺失的数据进行遍历,对于缺失数据,会分别计算将其归到左节点和右节点的增益,然后默认分类到增益大的一边继续分裂。算法流程如下:
在处理缺失值上跟普通算法相比快了近50倍

5、特征维度的并行化
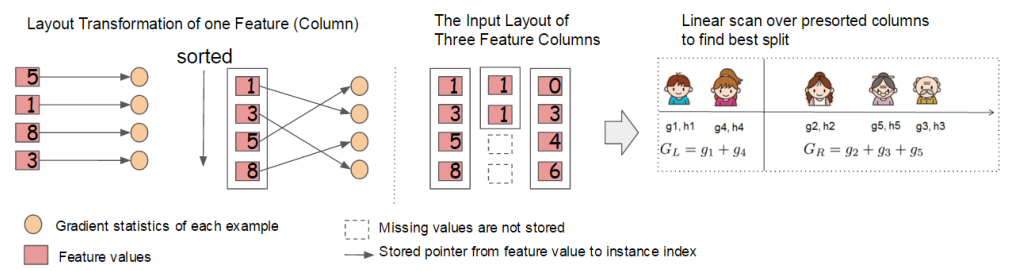
XGBoost在对每个特征进行预排序后会把特征相关的信息存储到分块的结构中,通过线性扫描每个特征块来获取信息,同时找不同的分裂点,实现并行化。
6、XGBoost VS GBDT
- GBDT采用CART为基分类器;XGBoost还支持线性分类器。
- GBDT只使用了泰勒一阶导信息;XGBoost使用了泰勒二阶导展开。
- XGBoost目标函数多了正则项防止过拟合。
- XGBoost在处理稀疏问题上使用稀疏感知算法,效率大大提升。
- XGBoost支持特征维度的并行化,提升算法效率。
7、XGBoost局限
在寻找最优分裂点算法中需要预排序以及遍历数据集,分块存储虽然可以方便访问,但是比较消耗内存和时间。(改进:LightGBM)