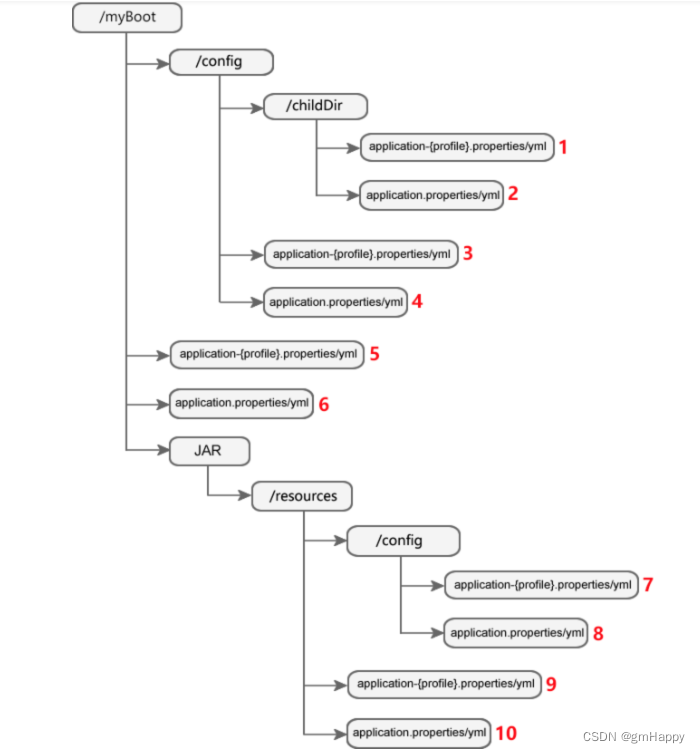
文章目录
- Kafka 原理,数据怎么平分到消费者
- 生产者分区
- 消费者分区
- Flume HDFS Sink 小文件处理
- Flink 与 Spark Streaming 的差异,具体效果
- Spark 背压机制具体实现原理
- Yarn 调度策略
- Spark Streaming消费方式及区别
- Zookeeper 怎么避免脑裂,什么是脑裂
- 讲一讲什么是 CAP 法则?Zookeeper 符合了这个法则的哪两个?
Kafka 原理,数据怎么平分到消费者
这里主要考的是kafka的分区分配策略
生产者分区
若指定分区号,则直接发给对应分区;若没有分区号,则通过key的hashcode对分区数取模;若也没有key则采取Sticky策略,会随机选择一分区,尽可能使用该分区,待该分区batch已满或者已提交,再随机选择一个分区,与当前分区不同。
消费者分区
Kafka的分区分配策略
-
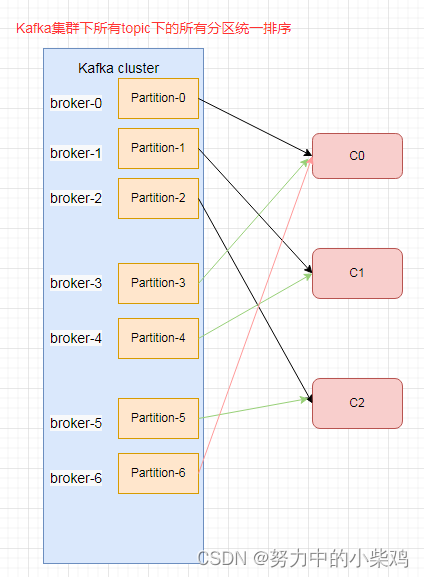
RoundRobin
针对所有topic的partition的。把消费者组订阅的所有topic的所有partition组成一个topicAndPartition列表,按照topicAndPartition的hashcode排序,对消费者组的所有消费者线程按照字母顺序排序,然后通过轮询将topicAndPartition列表中的每一个分区发给每一个消费者消费。
-
Range
是kafka默认分区分配策略。针对每一个topic而言的。首先将分区按分区号排序,然后将消费者按字母顺序排序,单个topic内partition数除以消费者组内的消费者线程数,决定每个消费者线程消费几个分区。如果除不尽前几个消费者会多消费一个分区。

-
Sticky
基础分配方式与RoundRobin一致,但是在重分配时,Sticky会尽可能保证与原分区策略一致。例如三个消费者中的一个挂了,如果是RoundRobin会对所有存活的消费者消费的分区进行重分配,如果是Sticky,则只将宕机节点分配的分区重分配给存活的消费者。

Flume HDFS Sink 小文件处理
源码中如果滚动中的文件如果被监测到正在进行HDFS的副本复制,就会自动产生一个文件,不会等到设置的条件触发再产生文件。源码的判断机制是当前正在复制的块序号是否小于配置文件中读取的最小副本数numBlocks < desiredBlocks。所以要想将这个触发条件关闭,需要使这个不等式恒不成立,我们不能修改hadoop的副本数,而Flume给我们提供了一个参数minBlockReplicas=1,我们只需要将这个参数设为1,就可以实现需求。
Flink 与 Spark Streaming 的差异,具体效果
- 流和微批
- 时间语义
Spark 背压机制具体实现原理
spark1.5之前,如果用户要限制Receiver的接受速率,只能通过配置参数spark.streaming.receiver.maxRate实现,虽然这样可以控制接受速率,防止OOM,但也会引入其他问题,当数据量小的时候,处理速率高于maxRate,这样就会导致资源利用率下降。所以从1.5开始,spark实现了一个新功能,可以通过动态控制接收速率来适配处理速率,即背压机制(spark.streaming.backpressure.enabled,默认false):根据JobSchedule反馈的执行信息来动态调整Receiver的接收速率。如果数据量稳定或数据量较小,则无需开启背压,因为背压机制也需要消耗计算资源。
Yarn 调度策略
-
FIFO调度器
单队列,任务会被放入队列中,先被获取先执行。 -
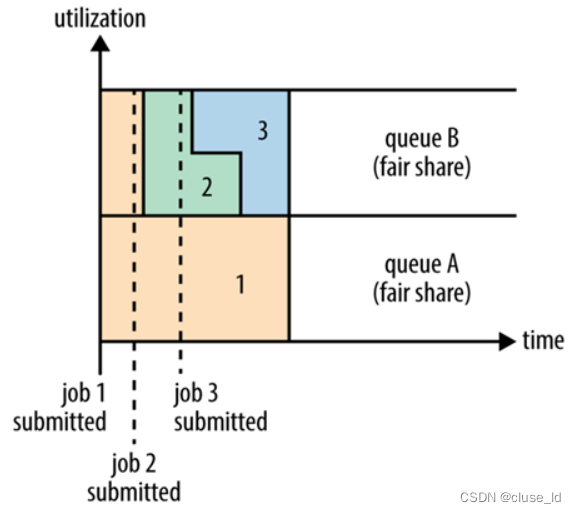
公平调度器
见面分一半。多队列,不会预分资源。当单任务提交时,若无其他任务运行,则独享所有资源。其他队列有任务时,与其他队列平分资源。当本队列有任务时,与本队列任务平分本队列资源。队列内部也可以设置调度策略公平(默认)或者FIFO
-
容量调度器
对资源进行预分,设置A队列执行大任务,B队列执行小任务。大任务一般占用资源较多,A分配80%资源,B分配20%资源。各队列使用FIFO调度。要点:预分队列,预分资源。
Spark Streaming消费方式及区别
- Receiver方式
这种方式使用的是Kafka的高阶API被动的接收Kafka的数据。Spark会启动Executor专门负责接收kafka的数据,并将接收的数据保存在Executor的内存中(当数据量激增时,可能会导致Executor节点的OOM,从而丢失数据)等待计算任务的拉取。这种情况下,如果Spark出错,很可能导致数据丢失,所以Receiver会开启WAL机制,在Receiver接收Kafka的数据时会同时将数据写入hdfs的预写日志中。 - Direct方式
这种方式是Executor主动拉取kafka中的数据。通过周期性访问kafka来获取每个topic+partitoin的最小offset。处理数据的job启动后,就会直接从kafka中获取对应offset范围的数据。
区别:Receiver是使用Kafka高阶API被动的接收Kafka的数据,offset由Kafka维护,采用WAL实现可靠性;Direct是使用Kafka简单API主动拉取由自己维护的offset范围的数据,由Kafka实现可靠性,性能更高。另外设置多个Receiver只能增加获取kafka数据的线程,对处理RDD的线程没有影响,只能通过多个stream进行unio实现。而Direct只需要创建有多个
Zookeeper 怎么避免脑裂,什么是脑裂
脑裂是master-slaves结构中,某个时刻有两个master对外提供服务。例如有俩个机房,一个机房3个zk节点,另一个机房2个zk节点,集群中只有一个master对外提供读写服务。某个时刻两个机房间的连接断开了,每一个机房都选举产生了一个master分别对外提供读写。当两个机房间的连接恢复后,集群又合并到一起去,此时数据该如何合并,数据冲突如何解决等问题出现。这就是脑裂。
zk中避免脑裂的方式是过半选举机制。集群从配置文件中读取到集群总节点数,若选举投票时某个节点的票数大于集群总结点数的一半时,成功选举了,反之继续选举流程。
讲一讲什么是 CAP 法则?Zookeeper 符合了这个法则的哪两个?
CAP原则,又称CAP定理,指的是一个分布式系统中,一致性,可用性,分区容错性三者不可兼得。
一致性(consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
可用性(Available):对任何非失败节点都应该在有限的时间内给出请求的回应。返回结果必须在合理的时间以内,这个合理的时间是根据业务来定的,如果超过业务规定的返回时间这个系统也就不满足可用性
分区容错性(Partition Tolerance):分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
当有数据写入一个多节点集群中时,如果在节点同步时连接断开,那么必然会有节点未同步成功。而此时如果要保证可用性,那么各节点间的数据会不一致,不满足一致性。而如果满足一致性,即停止对外提供服务直到数据同步完成,那么就不满足可用性了。所以一致性和可用性通常是不能同时满足的。
事实上作为分布式系统,分区容错性是必须的,而一致性和可用性是处于对立面的,所以分布式系统一般是采用CP或者AP组合。zookeeper采用的是CP,主要表现在leader选举时不对外提供服务。