弱网优化
1、Serializable原理
通常我们使用Java的序列化与反序列化时,只需要将类实现Serializable接口即可,剩下的事情就交给了jdk。今天我们就来探究一下,Java序列化是怎么实现的,然后探讨一下几个常见的集合类,他们是如何处理序列化带来的问题的。
1.1 分析过程
几个待思考的问题
为什么序列化一个对象时,仅需要实现Serializable接口就可以了。
通常我们序列化一个类时,为什么推荐的做法是要实现一个静态final成员变量serialVersionUID。
序列化机制是怎么忽略transient关键字的, static变量也不会被序列化。
接下来我们就带着问题,在源码中找寻答案吧。
1.2 Serializable接口
先看Serializable接口,源码很简单,一个空的接口,没有方法也没有成员变量。但是注释非常详细,很清楚的描述了Serializable怎么用、能做什么,很值得一看,我们捡几个重点的翻译一下,
/**
* Serializability of a class is enabled by the class implementing the
* java.io.Serializable interface. Classes that do not implement this
* interface will not have any of their state serialized or
* deserialized. All subtypes of a serializable class are themselves
* serializable. The serialization interface has no methods or fields
* and serves only to identify the semantics of being serializable.
*/复制代码类的可序列化性通过实现java.io.Serializable接口开启。未实现序列化接口的类不能序列化,所有实现了序列化的子类都可以被序列化。Serializable接口没有方法和属性,只是一个识别类可被序列化的标志。
/**
* Classes that require special handling during the serialization and
* deserialization process must implement special methods with these exact
* signatures:
*
* <PRE> * private void writeObject(java.io.ObjectOutputStream out)
* throws IOException
* private void readObject(java.io.ObjectInputStream in)
* throws IOException, ClassNotFoundException;
* private void readObjectNoData()
* throws ObjectStreamException;
*</PRE>*/
复制代码在序列化过程中,如果类想要做一些特殊处理,可以通过实现以下方法writeObject(), readObject(), readObjectNoData(),其中,
writeObject方法负责为其特定类写入对象的状态,以便相应的readObject()方法可以还原它。
readObject()方法负责从流中读取并恢复类字段。
如果某个超类不支持序列化,但又不希望使用默认值怎么办?writeReplace() 方法可以使对象被写入流之前,用一个对象来替换自己。
readResolve()通常在单例模式中使用,对象从流中被读出时,可以用一个对象替换另一个对象。
1.3 ObjectOutputStream
//我们要序列化对象的方法实现一般都是在这个函数中
public final void writeObject(Object obj) throws IOException {
...
try {
//写入的具体实现方法
writeObject0(obj, false);
} catch (IOException ex) {
...
throw ex;
}
}
private void writeObject0(Object obj, boolean unshared) throws IOException {
...省略
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
//获取到ObjectStreamClass,这个类很重要
//在它的构造函数初始化时会调用获取类属性的函数
//最终会调用getDefaultSerialFields这个方法
//在其中通过flag过滤掉类的某一个为transient或static的属性(解释了问题3)
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
//其中主要的写入逻辑如下
//String, Array, Enum本身处理了序列化
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
//重点在这里,通过`instanceof`判断对象是否为`Serializable`
//这也就是普通自己定义的类如果没有实现`Serializable`
//在序列化的时候会抛出异常的原因(解释了问题1)
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
...
}
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
...
try {
desc.checkSerialize();
//写入二进制文件,普通对象开头的魔数0x73
bout.writeByte(TC_OBJECT);
//写入对应的类的描述符,见底下源码
writeClassDesc(desc, false);
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj);
} else {
writeSerialData(obj, desc);
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
private void writeClassDesc(ObjectStreamClass desc, boolean unshared)
throws IOException
{
//句柄
int handle;
//null描述
if (desc == null) {
writeNull();
//类对象引用句柄
//如果流中已经存在句柄,则直接拿来用,提高序列化效率
} else if (!unshared && (handle = handles.lookup(desc)) != -1) {
writeHandle(handle);
//动态代理类描述符
} else if (desc.isProxy()) {
writeProxyDesc(desc, unshared);
//普通类描述符
} else {
//该方法会调用desc.writeNonProxy(this)如下
writeNonProxyDesc(desc, unshared);
}
}
void writeNonProxy(ObjectOutputStream out) throws IOException {
out.writeUTF(name);
//写入serialVersionUID
out.writeLong(getSerialVersionUID());
...
}
public long getSerialVersionUID() {
// 如果没有定义serialVersionUID
// 序列化机制就会调用一个函数根据类内部的属性等计算出一个hash值
// 这也是为什么不推荐序列化的时候不自己定义serialVersionUID的原因
// 因为这个hash值是根据类的变化而变化的
// 如果你新增了一个属性,那么之前那些被序列化后的二进制文件将不能反序列化回来,Java会抛出异常
// (解释了问题2)
if (suid == null) {
suid = AccessController.doPrivileged(
new PrivilegedAction<Long>() {
public Long run() {
return computeDefaultSUID(cl);
}
}
);
}
//已经定义了SerialVersionUID,直接获取
return suid.longValue();
}
//分析到这里,要插一个我对序列化后二进制文件的一点个人见解,见下面复制代码1.4 序列化后二进制文件的一点解读
如果我们要序列化一个List<PhoneItem>, 其中PhoneItem如下,
classPhoneItemimplementsSerializable {
String phoneNumber;
}
复制代码构造List的代码省略,假设我们序列化了一个size为5的List,查看二进制文件大概如下所示,
7372 xxxxxxxx7371 xxxxxxxx7371 xxxxxxxx7371 xxxxxxxx7371 xxxxxxxx复制代码通过刚才的源码解读,开头的魔数0x73表示普通对象,72表示类的描述符号,71表示类描述符为引用类型。管中窥豹可知一点薄见,在解析二进制文件的时候,就是通过匹配魔数 (magic number) 开头方式,从而转换成Java对象的。当在序列化过程中,如果流中已经有同样的对象,那么之后的序列化可以直接获取该类对象句柄,变为引用类型,从而提高序列化效率。
//通过writeSerialData调用走到真正解析类的方法中,有没有复写writeObject处理的逻辑不太一样
//这里以默认没有复写writeObject为例,最后会调用defaultWriteFields方法
private void defaultWriteFields(Object obj, ObjectStreamClass desc)
throws IOException
{
...
int primDataSize = desc.getPrimDataSize();
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
desc.getPrimFieldValues(obj, primVals);
//写入属性大小
bout.write(primVals, 0, primDataSize, false);
ObjectStreamField[]fields = desc.getFields(false);
Object[]objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
desc.getObjFieldValues(obj, objVals);
for (int i = 0; i < objVals.length; i++) {
...
try {
//遍历写入属性类型和属性大小
writeObject0(objVals[i],
fields[numPrimFields + i].isUnshared());
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
}
复制代码由于反序列化过程和序列化过程类似,这里不再赘述。
1.5 常见的集合类的序列化问题
1.5.1 HashMap
Java要求被反序列化后的对象要与被序列化之前的对象保持一致,但因为hashmap的key是通过hash计算的。反序列化后计算得到的值可能不一致(反序列化在不同的jvm环境下执行)。所以HashMap需要重写序列化实现的过程,避免出现这种不一致的情况。
具体操作是将要自定义处理的属性定义为transient,然后复写writeObject,在其中做特殊处理
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
//写入hash桶的容量
s.writeInt(buckets);
//写入k-v的大小
s.writeInt(size);
//遍历写入不为空的k-v
internalWriteEntries(s);
}
复制代码1.5.2 ArrayList
因为在ArrayList中的数组容量基本上都会比实际的元素的数大, 为了避免序列化没有元素的数组而重写writeObject和readObject
privatevoidwriteObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
...
s.defaultWriteObject();
// 写入arraylist当前的大小
s.writeInt(size);
// 按照相同顺序写入元素
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
...
}
复制代码2、Parcelable
Parcelable是Android为我们提供的序列化的接口,Parcelable相对于Serializable的使用相对复杂一些,但Parcelable的效率相对Serializable也高很多,这一直是Google工程师引以为傲的,有时间的可以看一下Parcelable和Serializable的效率对比号称快10倍的效率
Parcelable接口的实现类是可以通过Parcel写入和恢复数据的,并且必须要有一个非空的静态变量 CREATOR, 而且还给了一个例子,这样我们写起来就比较简单了,但是简单的使用并不是我们的最终目的
通过查看Android源码中Parcelable可以看出,Parcelable实现过程主要分为序列化,反序列化,描述三个过程,下面分别介绍下这三个过程
2.1 Parcel的简介
在介绍之前我们需要先了解Parcel是什么?Parcel翻译过来是打包的意思,其实就是包装了我们需要传输的数据,然后在Binder中传输,也就是用于跨进程传输数据
简单来说,Parcel提供了一套机制,可以将序列化之后的数据写入到一个共享内存中,其他进程通过Parcel可以从这块共享内存中读出字节流,并反序列化成对象,下图是这个过程的模型。
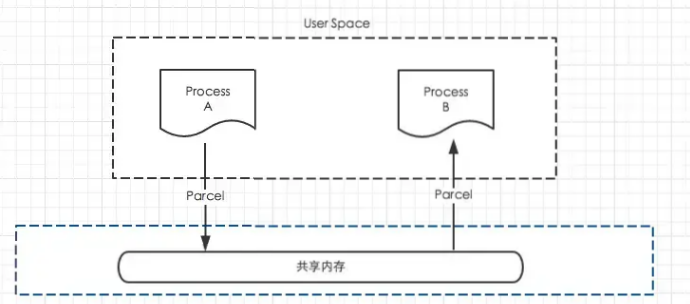
Parcel可以包含原始数据类型(用各种对应的方法写入,比如writeInt(),writeFloat()等),可以包含Parcelable对象,它还包含了一个活动的IBinder对象的引用,这个引用导致另一端接收到一个指向这个IBinder的代理IBinder。
Parcelable通过Parcel实现了read和write的方法,从而实现序列化和反序列化。可以看出包含了各种各样的read和write方法,最终都是通过native方法实现

2.2 Parcelable的三大过程介绍(序列化、反序列化、描述)
到这里,基本上关系都理清了,也明白简单的介绍和原理了,接下来在实现Parcelable之前,介绍下实现Parcelable的三大流程
首先写一个类实现Parcelable接口,会让我们实现两个方法

2.2.1 描述
其中describeContents就是负责文件描述,首先看一下源码的解读

通过上面的描述可以看出,只针对一些特殊的需要描述信息的对象,需要返回1,其他情况返回0就可以
2.2.2 序列化
我们通过writeToParcel方法实现序列化,writeToParcel返回了Parcel,所以我们可以直接调用Parcel中的write方法,基本的write方法都有,对象和集合比较特殊下面单独讲,基本的数据类型除了boolean其他都有,Boolean可以使用int或byte存储
2.2.3 反序列化
反序列化需要定义一个CREATOR的变量,上面也说了具体的做法,这里可以直接复制Android给的例子中的,也可以自己定义一个(名字千万不能改),通过匿名内部类实现Parcelable中的Creator的接口
2.3 Parcelable的实现和使用
根据上面三个过程的介绍,Parcelable就写完了,就可以直接在Intent中传输了,可以自己写两个Activity传输一下数据试一下,其中一个putExtra另一个getParcelableExtra即可
这里实现Parcelable也很简单:
1.写一个类实现Parcelable然后alt+enter 添加Parcelable所需的代码块,AndroidStudio会自动帮我们实现(这里需要注意如果其中包含对象或集合需要把对象也实现Parcelable)

2.4 Parcelable中对象和集合的处理
如果实现Parcelable接口的对象中包含对象或者集合,那么其中的对象也要实现Parcelable接口
写入和读取集合有两种方式:
一种是写入类的相关信息,然后通过类加载器去读取, –> writeList | readList
二是不用类相关信息,创建时传入相关类的CREATOR来创建 –> writeTypeList | readTypeList | createTypedArrayList
第二种效率高一些,但一定要注意如果有集合定义的时候一定要初始化
like this –>
public ArrayList authors = new ArrayList<>();
2.5 Parcelable和Serializable的区别和比较
Parcelable和Serializable都是实现序列化并且都可以用于Intent间传递数据,Serializable是Java的实现方式,可能会频繁的IO操作,所以消耗比较大,但是实现方式简单 Parcelable是Android提供的方式,效率比较高,但是实现起来复杂一些 , 二者的选取规则是:内存序列化上选择Parcelable, 存储到设备或者网络传输上选择Serializable(当然Parcelable也可以但是稍显复杂)
3、http与https原理详解
3.1 概述
早期以信息发布为主的Web 1.0时代,HTTP已可以满足绝大部分需要。证书费用、服务器的计算资源都比较昂贵,作为HTTP安全扩展的HTTPS,通常只应用在登录、交易等少数环境中。但随着越来越多的重要业务往线上转移,网站对用户隐私和安全性也越来越重视。对于防止恶意监听、中间人攻击、恶意劫持篡改,HTTPS是目前较为可行的方案,全站HTTPS逐渐成为主流网站的选择。
3.2 HTTP简介
HTTP(HyperText Transfer Protocol,超文本传输协议),是一种无状态 (stateless) 协议,提供了一组规则和标准,从而让信息能够在互联网上进行传播。在HTTP中,客户端通过Socket创建一个TCP/IP连接,并连接到服务器,完成信息交换后,就会关闭TCP连接。(后来通过Connection: Keep-Alive实现长连接)
3.2.1 HTTP消息组成
请求行或响应行
HTTP头部
HTML实体,包括请求实体和响应实体 HTTP请求结构,响应结构如图所示:

HTTP头部
HTTP头部由一系列的键值对组成,允许客户端向服务器端发送一些附加信息或者客户端自身的信息,如:accept、accept-encoding、cookie等。http头后面必须有一个空行
请求行
请求行由方法、URL、HTTP版本组成。

响应行
响应行由HTTP版本、状态码、信息提示符组成。

3.3 HTTP2.0和HTTP1.X相比的新特性
新的二进制格式,HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
多路复用,即每一个请求都是是用作连接共享机制的。一个请求对应一个id,这样一个连接上可以有多个请求,每个连接的请求可以随机的混杂在一起,接收方可以根据请求的id将请求再归属到各自不同的服务端请求里面。
header压缩,HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
服务端推送,同SPDY一样,HTTP2.0也具有server push功能。
3.4 HTTP安全问题
通信使用明文(不加密),内容可能会被窃听
不验证通信方的身份,因此有可能遭遇伪装
无法证明报文的完整性,所以有可能已遭篡改
3.5 HTTPS协议
HTTPS 是最流行的 HTTP 安全形式。使用 HTTPS 时,所有的 HTTP 请求和响应数据在发送到网络之前,都要进行加密。 HTTPS 在 HTTP 下面提供了一个传输级的密码安全层——可以使用 SSL,也可以使用其后继者——传输层安全(TLS)。

相关术语
密钥:改变密码行为的数字化参数。
对称密钥加密系统:编、解码使用相同密钥的算法。
不对称密钥加密系统:编、解码使用不同密钥的算法。
公开密钥加密系统:一种能够使数百万计算机便捷地发送机密报文的系统。
数字签名:用来验证报文未被伪造或篡改的校验和。
数字证书:由一个可信的组织验证和签发的识别信息。
密钥协商算法:解决动态密钥分配、存储、传输等问题
3.5.1 TLS/SSL协议
TLS/SSL协议包含以下一些关键步骤:
传输的数据必须具有机密性和完整性,一般采用对称加密算法和HMAC算法,这两个算法需要一系列的密钥块(key_block),比如对称加密算法的密钥、HMAC算法的密钥,如果是AES-128-CBC-PKCS#7加密标准,还需要初始化向量。
所有的加密块都由主密钥(Master Secret)生成,主密钥就是第1章中讲解的会话密钥,使用密码衍生算法将主密钥转换为多个密码快。
主密钥来自预备主密钥(Premaster Secret),预备主密钥采用同样的密码衍生算法转换为主密钥,预备主密钥采用RSA或者DH(ECDH)算法协商而来。不管采用哪种密钥协商算法,服务器必须有一对密钥(可以是RSA或者ECDSA密钥),公钥发给客户端,私钥自己保留。不同的密钥协商算法,服务器密钥对的作用也是不同的。
通过这些关键步骤,好像TLS/SSL协议的任务已经结束,但这种方案会遇到中间人攻击,这是TLS/SSL协议无法解决的问题,必须结合PKI的技术进行解决,PKI的核心是证书,证书背后的密码学算法是数字签名技术。对于客户端来说,需要校验证书,确保接收到的服务器公钥是经过认证的,不存在伪造,也就是客户端需要对服务器的身份进行验证。
TLS/SSL协议核心就三大步骤:认证、密钥协商、数据加密。
3.5.2 RSA握手

握手阶段分成五步:
客户端给出协议版本号、生成的随机数(Client random),以及客户端支持的加密方法。
服务端确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数。
客户端确认数字证书有效,然后生成一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给服务器。
服务器使用自己的私钥,获取客户端发来的随机数(Premaster secret)。
双方根据约定的加密方法,使用前面的三个随机数,生成会话密钥(session key),用来加密接下来的对话过程。
握手阶段有三点需要注意:
生成对话密钥一共需要三个随机数。
握手之后的对话使用对话密钥(session key)加密(对称加密),服务器的公钥和私钥只用于加密和解密对话密钥(session key)(非对称加密),无其他作用。
服务器公钥放在服务器的数字证书之中。
3.5.3 DH握手

RSA整个握手阶段都不加密,都是明文的。因此,如果有人窃听通信,他可以知道双方选择的加密方法,以及三个随机数中的两个。整个通话的安全,只取决于第三个随机数(Premaster secret)能不能被破解。为了足够安全,我们可以考虑把握手阶段的算法从默认的RSA算法,改为 Diffie-Hellman算法(简称DH算法)。采用DH算法后,Premaster secret不需要传递,双方只要交换各自的参数,就可以算出这个随机数。
4、protobuffer
protobuffer是一种语言无关、平台无关的数据协议,优点在于压缩性好,可扩展,标准化,常用于数据传输、持久化存储等。

4.1 实现原理
4.1.1 protobuffer协议
1.压缩性好(相比于同样跨平台、跨语言的json)
去除字段定义,分隔符(引号,冒号,逗号)
压缩数字,因为日常经常使用到的比较小的数字,实际有效的字节数没有4个字节
采用TLV的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
varint和zigzag算法:对数字进行压缩
protobuffer协议去除字段定义,分隔符
2.可拓展
protobuffer并不是一个自解析的协议(json自解析key),需要pb的meta数据解析,牺牲了可读性,但在大规模的数据处理是可以接受的。可拓展性在于protobuffer中追加定义,新旧版本是可以兼容的,但是定义是严格有序的。
3.标准化
protobuffer生态提供了完整的工具链,protobuffer提供官方的生成golang/java等实现插件,这样protobuffer字节码的各语言版本的序列化、反序列化是标准化的,也包括插件生成代码封装。以及标准化的常用工具,比如doc-gen、grpc-gen、grpc-gateway-gen等工具。
4.1.2 典型应用
gRPC
protobuffer封装
需要注意:
1.pb结构封装的字段标序是不能更改的,否则解析错乱;
2.pb结构尽量把必选类型,比如int、bool放在filedNum<=16;可得到更好的varint压缩效果;
3.grpc-client使用时,req是指针类型,务必不要重复复制,尽量new request,否则编码时会错乱;
4.2 protobuffer 编码原理
protobuffer(以下简称为PB)两个重要的优势在于高效的序列化/反序列化和低空间占用,而这两大优势是以其高效的编码方式为基础的。PB底层以二进制形式存储,比binary struct方式更加紧凑,一般来讲空间利用率也比binary struct更高,是以Key-Value的形式存储【图1】。
PB示例结构如下:
//示例protobuf结构
message Layer1
{
optional uint32 layer1_varint = 1;
optional Layer2 layer1_message = 2;
}
message Layer2
{
optional uint32 layer2_varint = 1;
optional Layer3 layer2_message = 2;
}
message Layer3
{
optional uint32 layer3_varint = 1;
optional bytes layer3_bytes = 2;
optional float layer3_float = 3;
optional sint32 layer3_sint32 = 4;
}
复制代码
PB将常用类型按存储特性分为数种Wire Type【图 2】, Wire Type不同,编码方式不同。根据Wire Type(占3bits)和field number生成Key。
Key计算方式如下,并以Varint编码方式序列化【参考下面Varint编码】,所以理论上[1, 15]范围内的field, Key编码后占用一个字节, [16,)的Key编码后会占用一个字节以上,所以尽量避免在一个结构里面定义过多的field。如果碰到需要定义这么多field的情况,可以采用嵌套方式定义。
//Key的计算方式
Key = field_number << 3 | Wire_Type
复制代码Type | Value | Meaning | Contain |
Varint | 0 | varint | int32,int64,sint32,sint64,uint32,uint64,bool,enum |
Fixed64 | 1 | 64-bit | fixed64,sfixed64,double,float |
LengthDelimited | 2 | length-delimi | string,message,bytes,repeated |
StartGroup | 3 | start group | groups(deprecated) |
EndGroup | 4 | end group | groups(deprecated) |
Fixed32 | 5 | 32-bit | fixed32,float |
4.2.1 Varint编码
inline uint8* WriteVarint32ToArray(uint32 value, uint8* target) {
while (value >= 0x80) {
*target = static_cast<uint8>(value | 0x80);
value >>= 7;
++target;
}
*target = static_cast<uint8>(value);
return target + 1;
}
复制代码Layer1 obj;
obj.set_layer1_varint(12345);复制代码Varint编码只用每个字节的低7bit存储数据,最高位0x80用做标识,清空:最后一个字节,置位:还有数据。以上述操作为例,设uint32类型为12345,其序列化过程如下:

该字段的field_number = 1, wire_type = 0, 则key = 1 << 3 | 0 = 0x20。那么在内存中, 其序列为应该为0x20B960,占3Bytes。对比直接用struct存储会占4Bytes;如果struct是用 uint64呢,将占8Bytes,而PB占用内存仍是3Bytes。
下表是PB数值范围与其字节数对应关系。实际应用中,我们用到的数大概率是比较小的,而且可能 动态范围比较大(有时需要用64位存储),对比struct的内存占用,PB优势很明显。
数值范围 | 占用字节数 |
0-127 | 2 |
128-16383 | 3 |
16384-2097151 | 4 |
2097152-268435455 | 5 |
4.2.2 ZigZag编码
ZigZag编码是对Varint编码的补充与优化。负数在内存中以前补码形式存在,但不管是负数的原码还是补码,最高位都是1;那么问题来了,如果以上述Varint编码方式,所有负数序列化以后都会以最大化占用内存(32位占用6Bytes, 64位占用11Btyes)。所以,细心的同学会发现,对于有符号数的表示有两种类型,int32和sint32。对,sint32就是对这种负数序列化优化的变种。
inline uint32 WireFormatLite::ZigZagEncode32(int32 n) {
// Note: the right-shift must be arithmetic
return (static_cast<uint32>(n) << 1) ^ (n >> 31);
}
复制代码sint32 | uint32 |
0 | 0 |
-1 | 1 |
1 | 2 |
-2 | 3 |
… | … |
2147483647 | 4294967294 |
-2147483648 | 4294967295 |
对于sint32类型的数据,在varint编码之前,会先进行zigzag编码,上图是其映射关系。编码后,较小的负数,可以映射为较小的正数,从而实现根据其信息量决定其序列化后占用的内存大小。
所以聪明的同学们已经知道该如何选择了,对于有符合数尽量选择sint32,而不是int32,不管从空间和时间上,都是更优的选择
4.2.3 length-delimi编码
length-delimi编码方式比较简单,是建立在varint编码基础上的,主要是针对message、bytes、repeated等类型,与TLV格式类似。先以varint编码写入tag即Key,再以varint编码写入长度,最后把内容memcpy到内存中。
inline uint8* WriteBytesToArray(int field_number,
const string& value,
uint8* target) {
target = WriteTagToArray(field_number, WIRETYPE_LENGTH_DELIMITED, target);
return io::CodedOutputStream::WriteStringWithSizeToArray(value, target);
}
uint8* WriteStringWithSizeToArray(const string& str,
uint8* target) {
GOOGLE_DCHECK_LE(str.size(), kuint32max);
target = WriteVarint32ToArray(str.size(), target);
return WriteStringToArray(str, target);
}
复制代码4.2.4 fixed编码
fixed编码很简单,主要针对类型有fixed32、fixed64、double、float。由于长度固定,只需要Key + Value即可。对于浮点型会先强制转换成相对应的整形,反序列化时则反之。
inline uint32 EncodeFloat(float value){
union {float f; uint32 i;};
f = value;
return i;
}
inline uint64 EncodeDouble(double value){
union {double f; uint64 i;};
f = value;
return i;
}
inlinevoidWireFormatLite::WriteFloatNoTag(float value,
io::CodedOutputStream* output){
output->WriteLittleEndian32(EncodeFloat(value));
}
inlinevoidWireFormatLite::WriteDoubleNoTag(double value,
io::CodedOutputStream* output){
output->WriteLittleEndian64(EncodeDouble(value));
}
复制代码4.2.5 整个编码流程

4.3 protobuf解码过程
上面已经介绍了编码原理,那么解码的流程也就很简单了。解码是一个递归的过程,先通过Varint解码过程读出Key, 取出field_number字段,如果不存在于message中,就放到UnKnownField中。如果是认识的field_number,则根据wire_type做具体的解析。对于普通类型(如整形,bytes, fixed类型等)就直接写入Field中,如果是嵌套类型(一般特指嵌套的Message),则递归调用整个解析过程。解析完一个继续解析下一个,直到buffer结束。

5、gzip压缩方案
5.1 gzip介绍
gzip是GNU zip的缩写,它是一个GNU自由软件的文件压缩程序,也经常用来表示gzip这种文件格式。软件的作者是Jean-loup Gailly和Mark Adler。1992年10月31日第一次公开发布,版本号是0.1,目前的稳定版本是1.2.4。
Gzip主要用于Unix系统的文件压缩。我们在Linux中经常会用到后缀为.gz的文件,它们就是GZIP格式的。现今已经成为Internet 上使用非常普遍的一种数据压缩格式,或者说一种文件格式。 当应用Gzip压缩到一个纯文本文件时,效果是非常明显的,经过GZIP压缩后页面大小可以变为原来的40%甚至更小,这取决于文件中的内容。
HTTP协议上的GZIP编码是一种用来改进WEB应用程序性能的技术。web开发中可以通过gzip压缩页面来降低网站的流量,而gzip并不会对cpu造成大量的占用,略微上升,也是几个百分点而已,但是对于页面却能压缩30%以上,非常划算。
利用Apache中的Gzip模块,我们可以使用Gzip压缩算法来对Apache服务器发布的网页内容进行压缩后再传输到客户端浏览器。这样经过压缩后实际上降低了网络传输的字节数(节约传输的网络I/o),最明显的好处就是可以加快网页加载的速度。
网页加载速度加快的好处不言而喻,除了节省流量,改善用户的浏览体验外,另一个潜在的好处是Gzip与搜索引擎的抓取工具有着更好的关系。例如 Google就可以通过直接读取gzip文件来比普通手工抓取更快地检索网页。在Google网站管理员工具(Google Webmaster Tools)中你可以看到,sitemap.xml.gz 是直接作为Sitemap被提交的。
而这些好处并不仅仅限于静态内容,PHP动态页面和其他动态生成的内容均可以通过使用Apache压缩模块压缩,加上其他的性能调整机制和相应的服务器端缓存规则,这可以大大提高网站的性能。因此,对于部署在Linux服务器上的PHP程序,在服务器支持的情况下,我们建议你开启使用Gzip Web压缩。
5.2 Web服务器处理HTTP压缩的过程如下:
Web服务器接收到浏览器的HTTP请求后,检查浏览器是否支持HTTP压缩(Accept-Encoding 信息);
如果浏览器支持HTTP压缩,Web服务器检查请求文件的后缀名;
如果请求文件是HTML、CSS等静态文件,Web服务器到压缩缓冲目录中检查是否已经存在请求文件的最新压缩文件;
如果请求文件的压缩文件不存在,Web服务器向浏览器返回未压缩的请求文件,并在压缩缓冲目录中存放请求文件的压缩文件;
如果请求文件的最新压缩文件已经存在,则直接返回请求文件的压缩文件;
如果请求文件是动态文件,Web服务器动态压缩内容并返回浏览器,压缩内容不存放到压缩缓存目录中。
下面是两个演示图:
未使用Gzip:

开启使用Gzip后:

5.3 启用apache的gzip功能
Apache上利用Gzip压缩算法进行压缩的模块有两种:mod_gzip 和mod_deflate。要使用Gzip Web压缩,请首先确定你的服务器开启了对这两个组件之一的支持。
虽然使用Gzip同时也需要客户端浏览器的支持,不过不用担心,目前大部分浏览器都已经支持Gzip了,如IE、Mozilla Firefox、Opera、Chrome等。
通过查看HTTP头,我们可以快速判断使用的客户端浏览器是否支持接受gzip压缩。若发送的HTTP头中出现以下信息,则表明你的浏览器支持接受相应的gzip压缩:
Accept-Encoding: gzip 支持mod_gzipAccept-Encoding: deflate 支持mod_deflate
Accept-Encoding: gzip,deflate 同时支持mod_gzip 和mod_deflate复制代码如firebug查看:

Accept-Encoding: gzip,deflate 是同时支持mod_gzip 和mod_deflate
如果服务器开启了对Gzip组件的支持,那么我们就可以在http.conf或.htaccess里面进行定制,下面是一个.htaccess配置的简单实例:
mod_gzip 的配置:
# mod_gzip:
<ifModule mod_gzip.c>
mod_gzip_on Yes
mod_gzip_dechunk Yes
mod_gzip_item_include file .(html?|txt|css|js|php|pl)$
mod_gzip_item_include handler ^cgi-script$
mod_gzip_item_include mime ^text/.*
mod_gzip_item_include mime ^application/x-javascript.*
mod_gzip_item_exclude rspheader ^Content-Encoding:.*gzip.*
<ifModule>
复制代码mod_deflate的配置实例:
打开打开apache 配置文件httpd.conf
将#LoadModule deflate_module modules/mod_deflate.so去除开头的#号
# mod_deflate:
<ifmodule mod_deflate.c>
DeflateCompressionLevel 6 #压缩率, 6是建议值.
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE text/javascript
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/rss+xml
AddOutputFilterByType DEFLATE application/atom_xml
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE application/x-httpd-php
AddOutputFilterByType DEFLATE image/svg+xml
</ifmodule>
复制代码里面的文件MIME类型可以根据自己情况添加,至于PDF 、图片、音乐文档之类的这些本身都已经高度压缩格式,重复压缩的作用不大,反而可能会因为增加CPU的处理时间及浏览器的渲染问题而降低性能。所以就没必要再通过Gzip压缩。通过以上设置后再查看返回的HTTP头,出现以下信息则表明返回的数据已经过压缩。即网站程序所配置的Gzip压缩已生效。
Content-Encoding: gzip
复制代码firebug查看:

注意:
1)不管使用mod_gzip 还是mod_deflate,此处返回的信息都一样。因为它们都是实现的gzip压缩方式。
2)CompressionLevel 9是指压缩程度的等级(设置压缩比率),取值范围在从1到9,9是最高等级。据了解,这样做最高可以减少8成大小的传输量(看档案内容而定),最少也能够节省一半。 CompressionLevel 预设可以采用 6 这个数值,以维持耗用处理器效能与网页压缩质量的平衡. 不建议设置太高,如果设置很高,虽然有很高的压缩率,但是占用更多的CPU资源. 3) 对已经是压缩过的图片格式如jpg,音乐档案如mp3、压缩文件如zip之类的,就没必要再压缩了。
5.4 mod_gzip 和mod_deflate的主要区别是什么?使用哪个更好呢?
第一个区别是安装它们的Apache Web服务器版本的差异:
Apache 1.x系列没有内建网页压缩技术,所以才去用额外的第三方mod_gzip 模块来执行压缩。而Apache 2.x官方在开发的时候,就把网页压缩考虑进去,内建了mod_deflate 这个模块,用以取代mod_gzip。虽然两者都是使用的Gzip压缩算法,它们的运作原理是类似的。
第二个区别是压缩质量:
mod_deflate 压缩速度略快而mod_gzip 的压缩比略高。一般默认情况下,mod_gzip 会比mod_deflate 多出4%~6%的压缩量。
那么,为什么使用mod_deflate?
第三个区别是对服务器资源的占用:
一般来说mod_gzip 对服务器CPU的占用要高一些。mod_deflate 是专门为确保服务器的性能而使用的一个压缩模块,mod_deflate 需要较少的资源来压缩文件。这意味着在高流量的服务器,使用mod_deflate 可能会比mod_gzip 加载速度更快。
不太明白?简而言之,如果你的网站,每天不到1000独立访客,想要加快网页的加载速度,就使用mod_gzip。虽然会额外耗费一些服务器资源, 但也是值得的。如果你的网站每天超过1000独立访客,并且使用的是共享的虚拟主机,所分配系统资源有限的话,使用mod_deflate 将会是更好的选择。
另外,从Apache 2.0.45开始,mod_deflate 可使用DeflateCompressionLevel 指令来设置压缩级别。该指令的值可为1(压缩速度最快,最低的压缩质量)至9(最慢的压缩速度,压缩率最高)之间的整数,其默认值为6(压缩速度和压缩质 量较为平衡的值)。这个简单的变化更是使得mod_deflate 可以轻松媲美mod_gzip 的压缩。
P.S. 对于没有启用以上两种Gzip模块的虚拟空间,还可以退而求其次使用php的zlib函数库(同样需要查看服务器是否支持)来压缩文件,只是这种方法使用起来比较麻烦,而且一般会比较耗费服务器资源,请根据情况慎重使用。
5.5 zlib.output_compression和ob_gzhandler编码方式压缩
服务器不支持mod_gzip、mod_deflate模块,若想通过GZIP压缩网页内容,可以考虑两种方式,开启zlib.output_compression或者通过ob_gzhandler编码的方式。
1)zlib.output_compression是在对网页内容压缩的同时发送数据至客户端。
2)ob_gzhandler是等待网页内容压缩完毕后才进行发送,相比之下前者效率更高,但需要注意的是,两者不能同时使用,只能选其一,否则将出现错误。
两者的实现方式做简单描述:
5.5.1 zlib.output_compression实现方式
在默认情况下,zlib.output_compression是关闭:
; Transparent output compression using the zlib library; Valid values for this option are 'off', 'on', or a specific buffer size; to be used for compression (default is 4KB); Note: Resulting chunk size may vary due to nature of compression. PHP; outputs chunks that are few hundreds bytes each as a result of; compression. If you prefer a larger chunk size for better; performance, enable output_buffering in addition.; Note: You need to use zlib.output_handler instead of the standard; output_handler, or otherwise the output will be corrupted.; http://php.net/zlib.output-compressionzlib.output_compression = Off
; http://php.net/zlib.output-compression-level;zlib.output_compression_level = -1复制代码如需开启需编辑php.ini文件,加入以下内容:
zlib.output_compression = Onzlib.output_compression_level = 6复制代码可以通过phpinfo()函数检测结果。
当zlib.output_compression的Local Value和MasterValue的值同为On时,表示已经生效,这时候访问的PHP页面(包括伪静态页面)已经GZIP压缩了,通过Firebug或者在线网页GZIP压缩检测工具可检测到压缩的效果。
5.5.2 ob_gzhandler的实现方式
如果需要使用ob_gzhandler,则需关闭zlib.output_compression,把php.ini文件内容更改为:
zlib.output_compression = Offzlib.output_compression_level = -1复制代码通过在PHP文件中插入相关代码实现GZIP压缩P压缩:
if (extension_loaded('zlib')) {
if ( !headers_sent() AND isset($_SERVER['HTTP_ACCEPT_ENCODING']) &&
strpos($_SERVER['HTTP_ACCEPT_ENCODING'], 'gzip') !== FALSE)
//页面没有输出且浏览器可以接受GZIP的页面
{
ob_start('ob_gzhandler');
}
}
//待压缩的内容echo$context;
ob_end_flush();
复制代码如何浏览器提示:内容编码错误,应该是:
使用ob_start('ob_gzhandler')时候前面已经有内容输出,检查前面内容以及require include调用文件的内容。若无法找到可以在调用其它文件前使用ob_start(),调用之后使用 ob_end_clean () 来清除输出的内容:
if (extension_loaded('zlib')) {
if ( !headers_sent() ANDisset($_SERVER['HTTP_ACCEPT_ENCODING']) &&
strpos($_SERVER['HTTP_ACCEPT_ENCODING'], 'gzip') !== FALSE)
//页面没有输出且浏览器可以接受GZIP的页面
{
ob_end_clean ();
ob_start('ob_gzhandler');
}
}
复制代码或者我们使用gzencode来压缩:
<?php$encoding = 'gzip';
$content = '123456789';
ob_end_clean ();
header('Content-Encoding: '.$encoding);
$result = gzencode($content);
echo$result;
exit;
复制代码不管是zlib.output_compression还是ob_gzhandler,都仅能对PHP文件进行GZIP压缩,对于HTML、CSS、JS等静态文件只能通过调用PHP的方式实现。
最后想说的是,现在主流的浏览器默认使用的是HTTP1.1协议,基本都支持GZIP压缩,对于IE而言,假如你没有选中其菜单栏工具-》Internet 选项-》高级-》HTTP 1.1 设置-》使用 HTTP 1.1,那么,你将感受不到网页压缩后的速度提升所带来的快感!