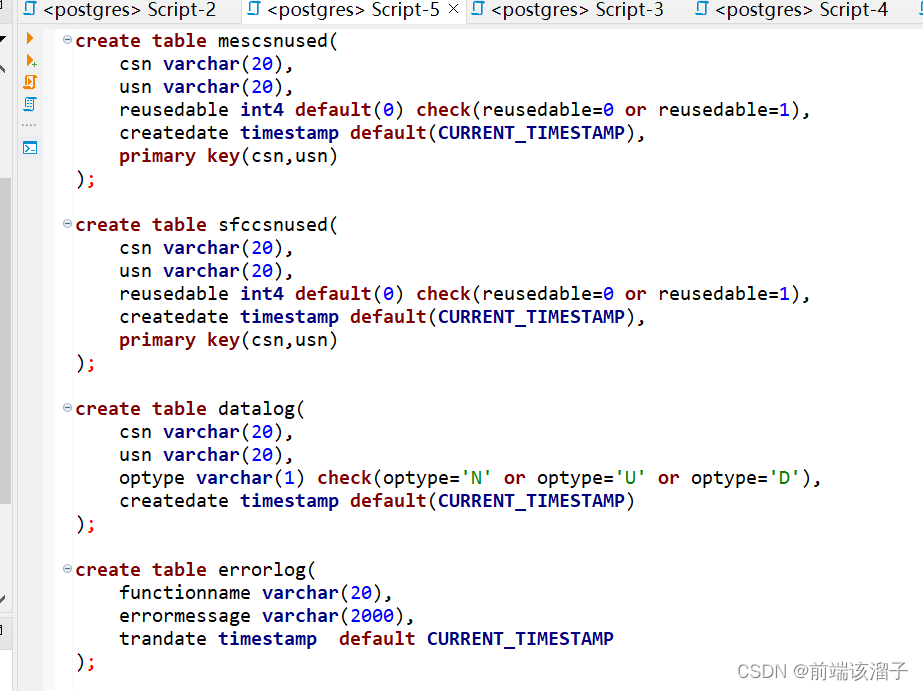
机器学习笔记之狄利克雷过程——基于标量参数作用的推导过程
- 引言
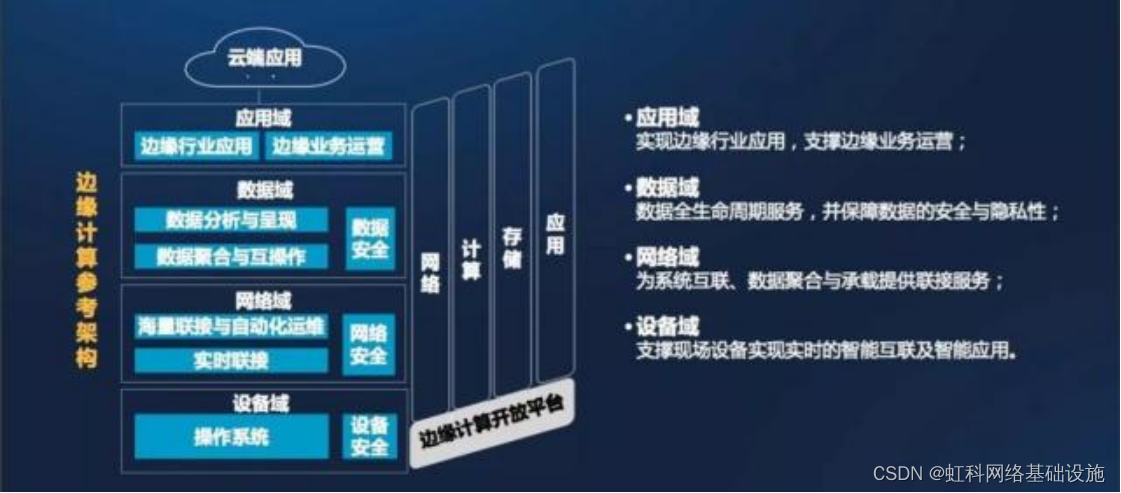
- 回顾:狄利克雷过程——基本介绍
- 狄利克雷过程——定义
- 小插曲:狄利克雷分布的简单性质
- 关于标量参数作用的推导过程
引言
上一节以高斯混合模型为引,简单介绍了狄利克雷过程( Dirichlet Process,DP \text{Dirichlet Process,DP} Dirichlet Process,DP)。本节将通过公式推导描述标量参数 α \alpha α的作用。
回顾:狄利克雷过程——基本介绍
狄利克雷过程本质上是分布的分布。基于给定的样本集合
X
=
{
x
(
i
)
}
i
=
1
N
\mathcal X= \{x^{(i)}\}_{i=1}^N
X={x(i)}i=1N,我们针对每个样本
x
(
i
)
(
i
=
1
,
2
,
⋯
,
N
)
x^{(i)}(i=1,2,\cdots,N)
x(i)(i=1,2,⋯,N)构建一个对应参数
θ
(
i
)
(
i
=
1
,
2
,
⋯
,
N
)
\theta^{(i)}(i=1,2,\cdots,N)
θ(i)(i=1,2,⋯,N)。对应的参数集合
θ
\theta
θ为:
θ
=
{
θ
(
i
)
}
i
=
1
N
\theta = \{\theta^{(i)}\}_{i=1}^N
θ={θ(i)}i=1N
关于狄利克雷过程,它的表达形式表示如下:
G
∼
DP
[
α
,
H
(
θ
)
]
\mathcal G \sim \text{DP}[\alpha,\mathcal H(\theta)]
G∼DP[α,H(θ)]
其中
G
\mathcal G
G是狄利克雷过程产生的样本结果,本身是一个离散分布(
Discrete Distribution
\text{Discrete Distribution}
Discrete Distribution);
H
(
θ
)
\mathcal H(\theta)
H(θ)表示关于参数集合
θ
\theta
θ的概率分布;
α
\alpha
α则是一个调整分布结果
G
\mathcal G
G离散程度的标量参数,且
α
>
0
\alpha > 0
α>0。
关于标量参数 α \alpha α:
- 当 α = 0 \alpha = 0 α=0时,此时的离散分布 G \mathcal G G极度离散,无论如何随机采样,只能映射唯一的离散结果;
- 当 α = ∞ \alpha = \infty α=∞时,此时离散分布 G \mathcal G G在采样过程中,可能存在无穷多种离散结果提供选择,并且每种选择均存在对应的概率值。此时的 G = H ( θ ) \mathcal G = \mathcal H(\theta) G=H(θ)。
下面会用公式推导的方式对上述两种情况进行描述。
狄利克雷过程——定义
根据上面的描述,如果分布
G
\mathcal G
G是一个优秀的离散分布,那么从分布
G
\mathcal G
G中产生的样本
θ
(
i
)
,
θ
(
j
)
(
i
,
j
∈
{
1
,
2
,
⋯
,
N
}
;
i
≠
j
)
\theta^{(i)},\theta^{(j)}(i,j \in \{1,2,\cdots,N\};i \neq j)
θ(i),θ(j)(i,j∈{1,2,⋯,N};i=j)必然存在
θ
(
i
)
=
θ
(
j
)
\theta^{(i)} = \theta^{(j)}
θ(i)=θ(j)的情况发生。
也就是说,
θ
(
i
)
=
θ
(
j
)
\theta^{(i)} = \theta^{(j)}
θ(i)=θ(j)意味着
x
(
i
)
,
x
(
j
)
x^{(i)},x^{(j)}
x(i),x(j)均指向了同一聚类信息。
此时,将不同结果的
θ
(
i
)
\theta^{(i)}
θ(i)收集起来,其结果数量必然
<
N
<N
<N,
θ
\theta
θ结果相同对应的样本子集
X
θ
\mathcal X_{\theta}
Xθ自然就聚类在一起,实现聚类数量
K
<
N
\mathcal K < N
K<N的情况。
关于高斯混合模型的示例,详见狄利克雷过程——基本介绍
重新观察狄利克雷过程
DP
(
α
,
H
)
\text{DP}(\alpha,\mathcal H)
DP(α,H),关于
θ
\theta
θ的概率分布
H
(
θ
)
\mathcal H(\theta)
H(θ)被称作基本测度(
Base Measure
\text{Base Measure}
Base Measure)。从采样的角度观察狄利克雷过程与高斯混合模型,观察它们之间的区别:
作为区分,将
ϕ
\phi
ϕ作为高斯混合模型概率密度函数的参数。
{
G
∼
DP
(
α
,
H
)
x
(
j
)
∼
P
(
X
;
ϕ
)
\begin{cases} \mathcal G \sim \text{DP}(\alpha,\mathcal H) \\ x^{(j)} \sim \mathcal P(\mathcal X;\phi) \end{cases}
{G∼DP(α,H)x(j)∼P(X;ϕ)
能够发现:
-
从高斯混合模型中采样得到的结果是一个样本空间中的样本点;
-
从狄利克雷过程中采样得到的结果是一个完整分布,是一个随机离散型概率测度( Random Discrete Probability Measure \text{Random Discrete Probability Measure} Random Discrete Probability Measure)。
假设 G ( i ) \mathcal G^{(i)} G(i)是从 DP ( α , H ) \text{DP}(\alpha,\mathcal H) DP(α,H)中采样得到的一个样本,那么离散分布 G ( i ) \mathcal G^{(i)} G(i)表示为如下形式:
这里假设G ( i ) \mathcal G^{(i)} G(i)是一个一维的分布
G ( i ) = ( g 1 ( i ) , g 2 ( i ) , ⋯ , g K ( i ) ) ∑ k = 1 K g k ( i ) = 1 \mathcal G^{(i)} = \left(g_1^{(i)},g_2^{(i)},\cdots,g_{\mathcal K}^{(i)}\right) \quad \sum_{k=1}^{\mathcal K} g_k^{(i)} = 1 G(i)=(g1(i),g2(i),⋯,gK(i))k=1∑Kgk(i)=1
其中 g k ( i ) ( k ∈ { 1 , 2 , ⋯ , K } ) g_k^{(i)}(k \in \{1,2,\cdots,\mathcal K\}) gk(i)(k∈{1,2,⋯,K})表示编号 k k k离散结果的权重/概率信息。即便 α \alpha α取值相同( α s a m e \alpha_{same} αsame),对应产生的随机离散分布 G ( i ) , G ( j ) ( i ≠ j ; G ( i ) , G ( j ) ∼ DP ( α s a m e , H ) ) \mathcal G^{(i)},\mathcal G^{(j)}(i \neq j;\mathcal G^{(i)},\mathcal G^{(j)}\sim \text{DP}(\alpha_{same},\mathcal H)) G(i),G(j)(i=j;G(i),G(j)∼DP(αsame,H))也不相同,它们可能很相似。
因而采样结果G ( i ) \mathcal G^{(i)} G(i)也被称作‘随机测度’( Random Measure ) (\text{Random Measure}) (Random Measure)如果一维的随机离散分布 G ( i ) \mathcal G^{(i)} G(i)表示如下:
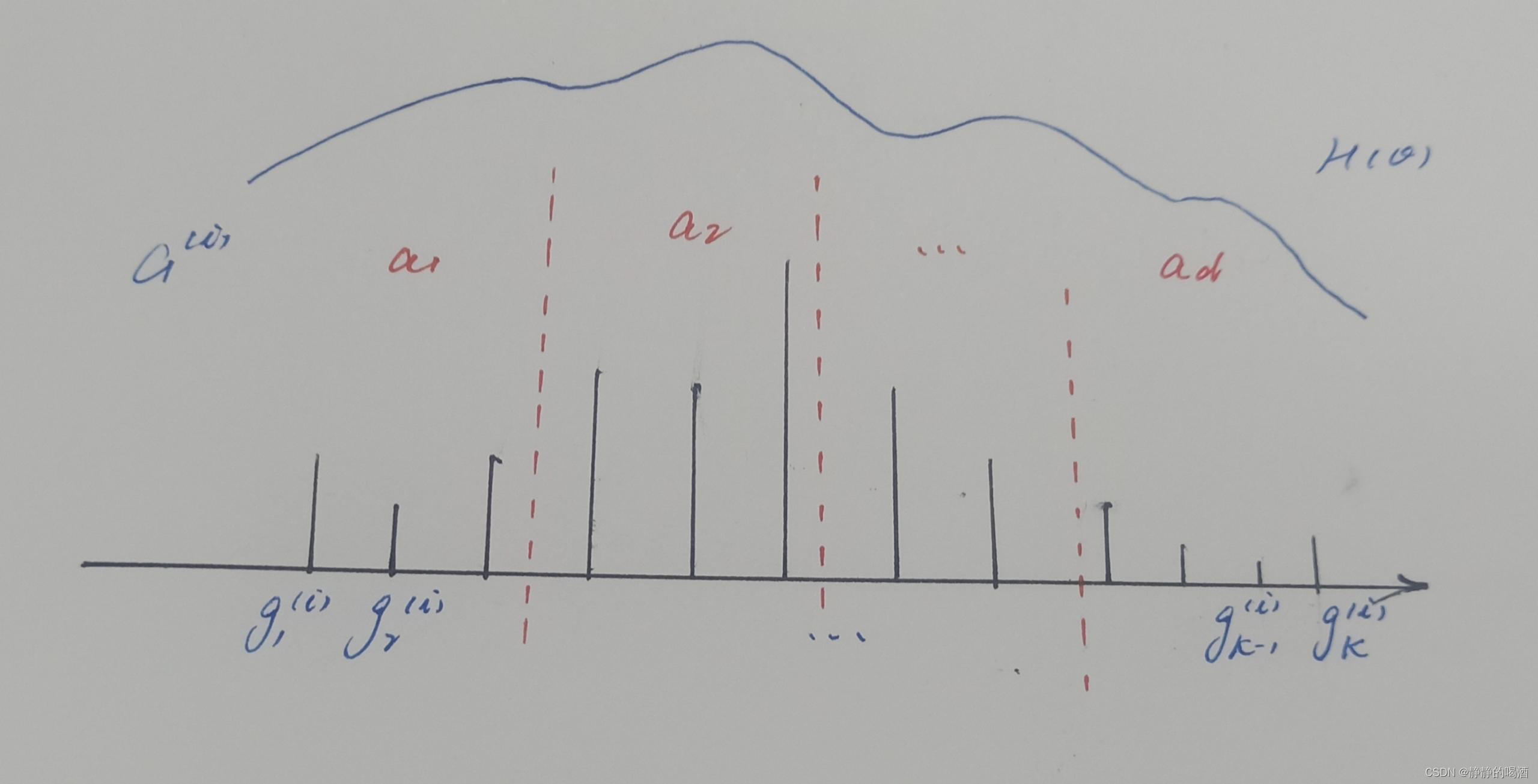
观察该图像: -
图像中的竖线表示离散分布 G ( i ) \mathcal G^{(i)} G(i)内对应的 K \mathcal K K个离散结果的权重/概率信息。竖线越长,选择该离散结果的概率越大;
-
最上面的弧线表示 H ( θ ) \mathcal H(\theta) H(θ)的概率分布,而 G ( i ) \mathcal G^{(i)} G(i)仅仅是基于 H ( θ ) \mathcal H(\theta) H(θ),给定 α \alpha α条件下的一个随机离散测度样本。
-
将该随机离散分布结果划分成 D \mathcal D D个区域: { a 1 , a 2 , ⋯ , a D } \{a_1,a_2,\cdots,a_{\mathcal D}\} {a1,a2,⋯,aD},每个区域内包含若干个权重结果。将这些权重结果的和作为该区域的权重信息。记作 G ( i ) ( a d ) \mathcal G^{(i)}(a_d) G(i)(ad):
G ( i ) ( a d ) = ∑ g k ( i ) ∈ a d g k ( i ) \mathcal G^{(i)}(a_d) = \sum_{g_k^{(i)} \in a_d} g_k^{(i)} G(i)(ad)=gk(i)∈ad∑gk(i)
至此,将 G ( i ) \mathcal G^{(i)} G(i)中的 K \mathcal K K个权重结果划分为 D \mathcal D D个区域,并得到 D \mathcal D D个区域的权重信息:
G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) ∑ d = 1 D G ( i ) ( a d ) = 1 \mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D}) \quad \sum_{d=1}^{\mathcal D} \mathcal G^{(i)}(a_d) = 1 G(i)(a1),G(i)(a2),⋯,G(i)(aD)d=1∑DG(i)(ad)=1
虽然被划分成了 D \mathcal D D个区域,但每个区域的权重信息 G ( i ) ( a d ) ( d ∈ { 1 , 2 , ⋯ , D } ) \mathcal G^{(i)}(a_d)(d \in \{1,2,\cdots,\mathcal D\}) G(i)(ad)(d∈{1,2,⋯,D})依然是一个随机变量,并且 G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) \mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D}) G(i)(a1),G(i)(a2),⋯,G(i)(aD)同样是一个离散的概率分布。那么该分布需要服从的概率性质是 狄利克雷分布( Dirichlet Distribution \text{Dirichlet Distribution} Dirichlet Distribution)
[ G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) ] ∼ Dir [ α H ( a 1 ) , α H ( a 2 ) , ⋯ , α H ( a D ) ] [\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})] \sim \text{Dir} \left[\alpha \mathcal H(a_1),\alpha \mathcal H(a_2),\cdots,\alpha \mathcal H(a_{\mathcal D})\right] [G(i)(a1),G(i)(a2),⋯,G(i)(aD)]∼Dir[αH(a1),αH(a2),⋯,αH(aD)]
其中 H ( a j ) ( j ∈ { 1 , 2 , ⋯ , D } ) \mathcal H(a_j)(j \in \{1,2,\cdots,\mathcal D\}) H(aj)(j∈{1,2,⋯,D})表示被划分的 a j a_j aj区域中的基本测度; α \alpha α与 H ( a j ) \mathcal H(a_j) H(aj)的乘积 α H ( a j ) \alpha\mathcal H(a_j) αH(aj)(标量)表示狄利克雷分布在 a j a_j aj区域中的参数信息。
小插曲:狄利克雷分布的简单性质
假设随机变量集合
X
\mathcal X
X包含
p
p
p个随机变量:
X
∈
R
p
\mathcal X \in \mathbb R^p
X∈Rp,并且概率分布
P
(
X
)
=
P
(
x
1
,
x
2
,
⋯
,
x
p
)
\mathcal P(\mathcal X) = \mathcal P(x_1,x_2,\cdots,x_p)
P(X)=P(x1,x2,⋯,xp)服从狄利克雷分布:
P
(
x
1
,
x
2
,
⋯
,
x
p
)
∼
Dir
(
α
1
,
α
2
,
⋯
,
α
p
)
\mathcal P(x_1,x_2,\cdots,x_p) \sim \text{Dir}(\alpha_1,\alpha_2,\cdots,\alpha_p)
P(x1,x2,⋯,xp)∼Dir(α1,α2,⋯,αp)
其中
α
i
(
i
=
1
,
2
,
⋯
,
p
)
\alpha_i(i=1,2,\cdots,p)
αi(i=1,2,⋯,p)表示各随机变量
x
i
(
i
=
1
,
2
,
⋯
,
p
)
x_i(i=1,2,\cdots,p)
xi(i=1,2,⋯,p)对应的参数。关于随机变量
x
i
x_i
xi的期望结果
E
[
x
i
]
\mathbb E[x_i]
E[xi]与方差结果
Var
[
x
i
]
\text{Var}[x_i]
Var[xi]分别表示为:
{
E
[
x
i
]
=
α
i
∑
k
=
1
p
α
k
Var
[
x
i
]
=
α
i
⋅
(
∑
k
=
1
p
α
k
−
α
i
)
(
∑
k
=
1
p
α
k
)
2
⋅
(
1
+
∑
k
=
1
p
α
k
)
\begin{cases} \begin{aligned} \mathbb E[x_i] & = \frac{\alpha_i}{\sum_{k=1}^p \alpha_k} \\ \text{Var}[x_i] & = \frac{\alpha_i \cdot \left(\sum_{k=1}^p \alpha_k - \alpha_i\right)}{\left(\sum_{k=1}^p \alpha_k\right)^2 \cdot \left(1 + \sum_{k=1}^p \alpha_k\right)} \end{aligned} \end{cases}
⎩
⎨
⎧E[xi]Var[xi]=∑k=1pαkαi=(∑k=1pαk)2⋅(1+∑k=1pαk)αi⋅(∑k=1pαk−αi)
关于标量参数作用的推导过程
终上,简单总结狄利克雷过程的定义:
- 某一随机离散测度样本
G
(
i
)
\mathcal G^{(i)}
G(i)服从标量参数
α
\alpha
α、基本测度分布为
H
\mathcal H
H的狄利克雷分布:
G ( i ) ∼ DP ( α , H ) \mathcal G^{(i)} \sim \text{DP}(\alpha,\mathcal H) G(i)∼DP(α,H) - 假设将该分布样本
G
(
i
)
=
[
g
1
(
i
)
,
g
2
(
i
)
,
⋯
,
g
K
(
i
)
]
T
\mathcal G^{(i)} = [g_1^{(i)},g_2^{(i)},\cdots,g_{\mathcal K}^{(i)}]^T
G(i)=[g1(i),g2(i),⋯,gK(i)]T划分成
D
\mathcal D
D个区域
(
a
1
,
a
2
,
⋯
,
a
D
)
(a_1,a_2,\cdots,a_{\mathcal D})
(a1,a2,⋯,aD),并将每个区域中的权重信息求和,从而构成的新的分布:
[ g 1 ( i ) , g 2 ( i ) , ⋯ , g K ( i ) ] T ⏟ Old Distribution ⇒ [ G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) ] T ⏟ New Distribution \underbrace{[g_1^{(i)},g_2^{(i)},\cdots,g_{\mathcal K}^{(i)}]^T}_{\text{Old Distribution}} \Rightarrow \underbrace{[\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})]^T}_{\text{New Distribution}} Old Distribution [g1(i),g2(i),⋯,gK(i)]T⇒New Distribution [G(i)(a1),G(i)(a2),⋯,G(i)(aD)]T - 这个新分布服从对应参数为
α
⋅
H
(
a
d
)
\alpha \cdot \mathcal H(a_d)
α⋅H(ad)的狄利克雷分布:
[ G ( i ) ( a 1 ) , G ( i ) ( a 2 ) , ⋯ , G ( i ) ( a D ) ] ∼ Dir [ α H ( a 1 ) , α H ( a 2 ) , ⋯ , α H ( a D ) ] [\mathcal G^{(i)}(a_1),\mathcal G^{(i)}(a_2),\cdots,\mathcal G^{(i)}(a_{\mathcal D})] \sim \text{Dir} \left[\alpha \mathcal H(a_1),\alpha \mathcal H(a_2),\cdots,\alpha \mathcal H(a_{\mathcal D})\right] [G(i)(a1),G(i)(a2),⋯,G(i)(aD)]∼Dir[αH(a1),αH(a2),⋯,αH(aD)]
此时的随机变量是 G ( i ) ( a d ) ( d = 1 , 2 , ⋯ , D ) \mathcal G^{(i)}(a_d)(d=1,2,\cdots,\mathcal D) G(i)(ad)(d=1,2,⋯,D),计算该随机变量的期望和方差结果:
其中α \alpha α是标量,并且不含d d d,可将其提到∑ d = 1 D \sum_{d=1}^{\mathcal D} ∑d=1D前面.并且∑ d = 1 D H ( a d ) = 1 \sum_{d=1}^{\mathcal D} \mathcal H(a_d) = 1 ∑d=1DH(ad)=1是已知项。
E [ G ( i ) ( a d ) ] = α H ( a d ) ∑ d = 1 D α H ( a d ) = α H ( a d ) α ∑ d = 1 D H ( a d ) = H ( a d ) \begin{aligned} \mathbb E[\mathcal G^{(i)}(a_d)] & = \frac{\alpha \mathcal H(a_d)}{\sum_{d=1}^{\mathcal D} \alpha \mathcal H(a_d)} \\ & = \frac{\alpha \mathcal H(a_d)}{\alpha \sum_{d=1}^{\mathcal D} \mathcal H(a_d)} \\ & = \mathcal H(a_d) \end{aligned} E[G(i)(ad)]=∑d=1DαH(ad)αH(ad)=α∑d=1DH(ad)αH(ad)=H(ad)
可以发现,分布样本
G
(
i
)
\mathcal G^{(i)}
G(i)在
a
d
a_d
ad划分区域中的期望结果就是区域
a
d
a_d
ad的基本测度;并且这个期望结果
E
[
G
(
i
)
(
a
d
)
]
\mathbb E[\mathcal G^{(i)}(a_d)]
E[G(i)(ad)]与标量参数
α
\alpha
α无关。
仅需要将‘基本测度’
H
\mathcal H
H看成一个概率密度函数(输出的是概率结果),
H
(
a
d
)
=
H
[
∑
g
k
(
i
)
∈
a
d
g
k
(
i
)
]
\mathcal H(a_d) = \mathcal H \left[\sum_{g_k^{(i)} \in a_d} g_k^{(i)}\right]
H(ad)=H[∑gk(i)∈adgk(i)].
继续观察它的方差结果
Var
[
G
(
i
)
(
a
d
)
]
\text{Var}\left[\mathcal G^{(i)}(a_d)\right]
Var[G(i)(ad)]:
套公式~
Var
[
G
(
i
)
(
a
d
)
]
=
α
H
(
a
d
)
⋅
[
α
⋅
∑
d
=
1
D
H
(
a
d
)
−
α
H
(
a
d
)
]
[
α
⋅
∑
d
=
1
D
H
(
a
d
)
]
2
⋅
[
α
⋅
∑
d
=
1
D
H
(
a
d
)
+
1
]
=
α
H
(
a
d
)
⋅
[
α
−
α
H
(
a
d
)
]
α
2
⋅
(
α
+
1
)
=
H
(
a
d
)
[
1
−
H
(
a
d
)
]
α
+
1
\begin{aligned} \text{Var}\left[\mathcal G^{(i)}(a_d)\right] & = \frac{\alpha \mathcal H(a_d) \cdot \left[\alpha \cdot \sum_{d=1}^{\mathcal D} \mathcal H(a_d) - \alpha \mathcal H(a_d)\right]}{\left[\alpha \cdot \sum_{d=1}^{\mathcal D} \mathcal H(a_d)\right]^2 \cdot \left[\alpha \cdot \sum_{d=1}^{\mathcal D} \mathcal H(a_d) + 1 \right]} \\ & = \frac{\alpha \mathcal H(a_d) \cdot \left[\alpha - \alpha \mathcal H(a_d)\right]}{\alpha^2 \cdot \left(\alpha + 1 \right)} \\ & = \frac{\mathcal H(a_d) [1 - \mathcal H(a_d)]}{\alpha + 1} \end{aligned}
Var[G(i)(ad)]=[α⋅∑d=1DH(ad)]2⋅[α⋅∑d=1DH(ad)+1]αH(ad)⋅[α⋅∑d=1DH(ad)−αH(ad)]=α2⋅(α+1)αH(ad)⋅[α−αH(ad)]=α+1H(ad)[1−H(ad)]
-
首先观察当 标量参数 α → ∞ \alpha \to \infty α→∞ 的情况下,此时无论是哪个区域 a d ( d = 1 , 2 , ⋯ , D ) a_d(d=1,2,\cdots,\mathcal D) ad(d=1,2,⋯,D),它对应 G ( i ) ( a d ) \mathcal G^{(i)}(a_d) G(i)(ad)的方差结果均为 0 0 0,这意味着任意区域下下的随机测度 G ( i ) ( a d ) \mathcal G^{(i)}(a_d) G(i)(ad)均不存在方差噪声。它精准地等于 a d a_d ad区域的基本测度 H ( a d ) \mathcal H(a_d) H(ad):
即没有方差噪声地、精确地指向了期望的位置。
Var [ G ( i ) ( a d ) ] = 0 ⇔ G ( i ) ( a d ) = H ( a d ) \text{Var} \left[\mathcal G^{(i)}(a_d)\right] = 0 \Leftrightarrow \mathcal G^{(i)}(a_d) = \mathcal H(a_d) Var[G(i)(ad)]=0⇔G(i)(ad)=H(ad) -
相反,当 标量参数 α = 0 \alpha = 0 α=0 的情况下, Var [ G ( i ) ( a d ) ] = H ( a d ) [ 1 − H ( a d ) ] \text{Var} \left[\mathcal G^{(i)}(a_d)\right] = \mathcal H(a_d) [1 - \mathcal H(a_d)] Var[G(i)(ad)]=H(ad)[1−H(ad)]。此时该方差是伯努利分布的方差结果。这意味着随机测度 G ( i ) ( a d ) \mathcal G^{(i)}(a_d) G(i)(ad)服从伯努利分布。
而伯努利分布就是最简单的离散分布描述。当 α = 0 \alpha = 0 α=0时,关于随机测度 G ( i ) \mathcal G^{(i)} G(i)内部某个权重 g k ( i ) g_k^{(i)} gk(i)与某一区域 a d a_d ad之间只有两种描述情况:
- g k ( i ) g_k^{(i)} gk(i)属于 a d a_d ad区域中的权重信息;
- g k ( i ) g_k^{(i)} gk(i)不属于 a d a_d ad区域中的权重信息;
下一节将从随机测度 G ( i ) \mathcal G^{(i)} G(i)生成过程的角度观察标量参数与分布离散程度的关系
相关参考:
徐亦达机器学习:Dirichlet-Process-part 2