说明:
-
KVM版本:5.9.1
-
QEMU版本:5.0.0
-
工具:Source Insight 3.5, Visio
1. 概述
让我们先来看看问题的引入,在之前的virtio系列文章中,网络虚拟化的框架如下图所示:

-
Qemu中的virtio-net设备数据包收发,通过用户态访问tap设备完成的;
-
收发过程涉及Guest OS,KVM,Qemu中的virtio-net设备,Host中的网络协议栈等的交互,路径长并且涉及的切换多,带来了性能的损耗;
-
vhost-net的引入,就是将vitio-net后端设备的数据处理模块下沉到Kernel中,从而提高整体的效率;
vhost-net的框架图如下:

-
从图中可以看出,Guest的网络数据交互直接可以通过vhost-net内核模块进行处理,而不再需要从内核态切换回用户态的Qemu进程中进行处理;
-
之前的文章分析过virtio设备与驱动,针对数据传遵循virtio协议,因此vhost-net中需要去实现virtqueue的相关机制;
本文将分析vhost-net的原理,只说重点,进入主题。
2. 数据结构
vhost-net内核模块的层次结构如下图:

-
struct vhost_net:用于描述Vhost-Net设备。它包含几个关键字段:1)struct vhost_dev,通用的vhost设备,可以类比struct device结构体内嵌在其他特定设备的结构体中;2)struct vhost_net_virtqueue,实际上对struct vhost_virtqueue进行了封装,用于网络包的数据传输;3)struct vhost_poll,用于socket的poll,以便在数据包接收与发送时进行任务调度;
-
struct vhost_dev:描述通用的vhost设备,可内嵌在基于vhost机制的其他设备结构体中,比如struct vhost_net,struct vhost_scsi等。关键字段如下:1)vqs指针,指向已经分配好的struct vhost_virtqueue,对应数据传输;2)work_list,任务链表,用于放置需要在vhost_worker内核线程上执行的任务;3)worker,用于指向创建的内核线程,执行任务列表中的任务;
-
struct vhost_virtqueue:用于描述设备对应的virtqueue,这部分内容可以参考之前virtqueue机制分析,本质上是将Qemu中virtqueue处理机制下沉到了Kernel中。关键字段如下:1)struct vhost_poll,用于poll eventfd对应的文件,当不满足处理请求时会添加到eventfd对应的等待队列中,而一旦被唤醒,该结构体中的struct vhost_work(执行函数被初始化为handle_tx_kick,以发送为例)将被放置到内核线程中去执行;
结构体的核心围绕着数据和通知机制,其中数据在vhost_virtqueue中体现,而通知主要是通过vhost_poll来实现,具体的细节下文将进一步描述。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
3. 流程分析
3.1 初始化
vhost-net为内核模块,注册为misc设备,Qemu通过系统调用接口与内核交互,Qemu中的初始化如下图:

-
Qemu中tap设备初始化在net_init_tap中完成,其中net_init_tap_one打开vhost-net设备文件,用于与内核的vhost-net交互;
-
vhost_set_backend_type:设置vhost的后端类型,以及vhost的操作函数集。目前有两种vhost后端,一种是在内核态实现的virtio后端,一种是在用户态中实现的virtio后端;
-
kernel_ops:vhost的内核操作函数集,都是一些回调函数的实现,最终会通过vhost_kernel_call-->ioctl-->vhost-net.ko路径,进行配置;
ioctl系统调用,与驱动交互简单来说可以分为三大类,下边分别介绍几个关键的设置:
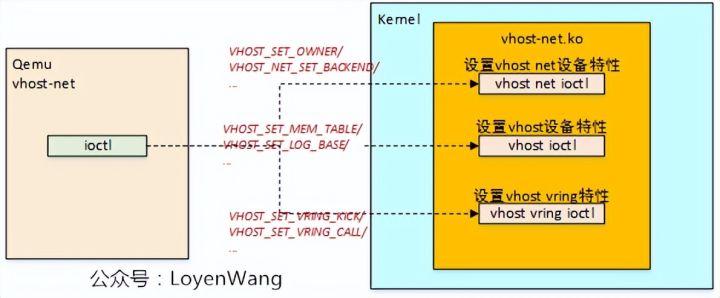
-
vhost net设置
-
VHOST_SET_OWNER:底层会为调用者创建一个内核线程,对应到前文中数据结构中的vhost_worker,同时在vhost_dev结构体中还会保存调用者线程的内存空间数据结构;
-
VHOST_NET_SET_BACKEND:设置vhost-net的后端设备,比如Qemu往内核态传递的tap设备对应的fd,从而让vhost-net直接与tap设备进行通信;
-
vhost dev设置从Guest OS中的虚拟地址到最终的Host上的物理地址映射关系如上图所示,如果在Guest OS中要将数据发送出去,实际上只需要将Qemu中关于Guest OS的物理地址布局信息传递下去,此外再结合VHOST_SET_OWNER时传递的内存空间信息,就可以根据映射关系找到Guest OS中的数据对应到Host之上的物理地址,完成最后搬运即可;
-
VHOST_SET_MEM_TABLE:将Qemu中的虚拟机物理地址布局信息传递给内核,为了解释清楚这个问题,可以回顾一下之前内存虚拟化中的一张图:
-
vhost vring设置
-
VHOST_SET_VRING_KICK:设置vhost-net模块前端virtio驱动发送通知时触发的eventfd,通知机制,最终触发handle_kick函数的执行;
-
VHOST_SET_VRING_CALL:设置vhost-net后端到虚拟机virtio前端的中断通知,参考之前文章中的irqfd机制;
-
此外关于vring的设备还包括vring的大小,地址信息等;
上述的这些设置的流程路径如下,只画出了关键路径:

-
当Guest OS中的virtio-net驱动完成初始化后,会通过vp_set_status来设置状态,以通知后端驱动已经ready,此时会触发VM的退出并进入KVM进行异常处理,最终路由给Qemu;
-
Qemu中的vcpu线程监测异常,当检测到KVM_EXIT_MMIO时,去回调注册该IO区域的读写函数,比如virtio_pci_common_write函数,在该函数中逐级往下最终调用到vhost_net_start函数;
-
在vhost_net_start中最终去通过kernel_ops函数集去设置底层并交互;
初始化完成后,接下来让我们看看数据的发送与接收,为了能将整个流程表达清楚,我会将完整的图拆分成几个步骤来讲述。
3.2 数据发送
1)
发送前的框图如下:
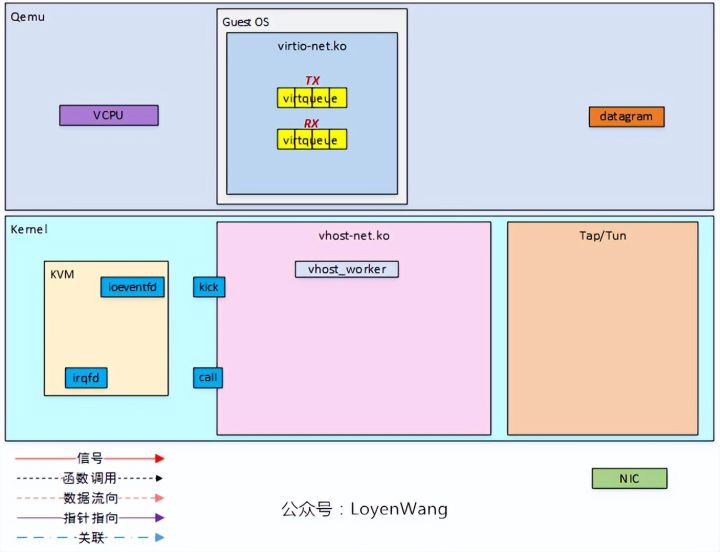
-
Guest OS中的virtio-net驱动中维护两个virtqueue,分别用于发送和接收;
-
图中的datagram表示的是需要发送的数据;
-
KVM模块提供了ioeventfd和irqfd用于通知机制;
-
vhost-net模块中创建好了vhost_worker内核线程,用于处理任务;
2)

-
当数据包准备好之后,通过往kick fd上触发信号,从而唤醒vhost_worker内核线程来调用handle_tx_kick进行数据的发送;
-
当Tap/Tun不具备发送条件时,vhost_worker会poll在socket上,等待Tap/Tun的唤醒,一旦被唤醒后可以调用handle_tx_net发送;
-
最终的handle_tx完成具体的发送;
3)
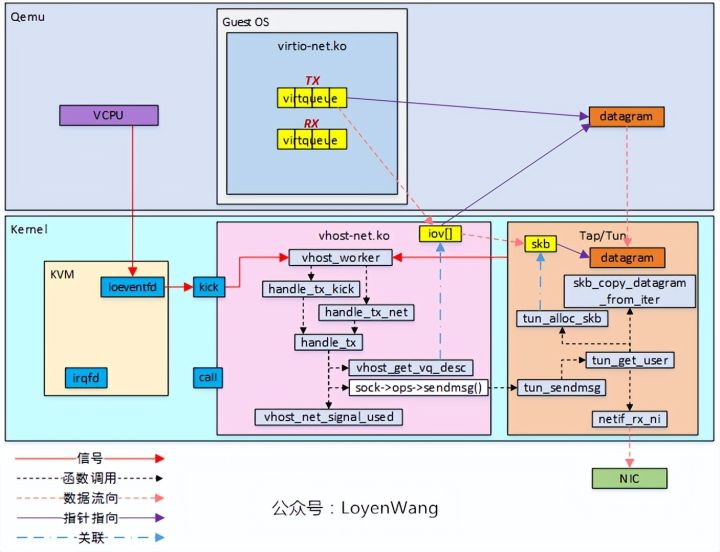
-
vhost_get_vq_desc函数在vritqueue中查找可用的buffer,并将信息存储到iov中,以便更好的访问;
-
sock->ops->sendmsg()函数,实际调用的是tun_sendmsg函数,在该函数中分配了skb结构体,并将iov[]中的信息传递过来,最终如图中所示完成数据的拷贝和发送,通过NIC发送出去;
4)

-
数据发送完毕后,通过irqfd机制通知vcpu;
3.3 数据接收
数据的接收是发送的逆过程,流程一致:
1)
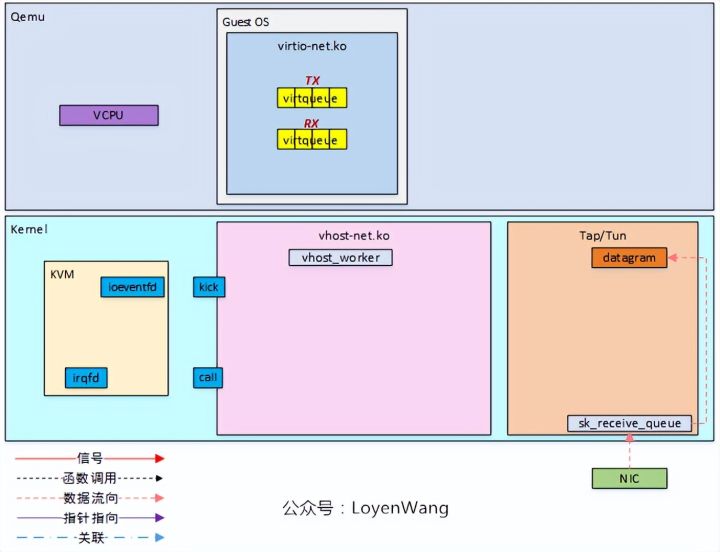
-
初始化部分与发送过程一致;
-
Tap/Tun驱动从NIC接收到数据包,准备发送给vhost-net;
2)

-
vhost-net中的vhost_worker线程也poll在两个fd之上,与发送端类似;
-
kick fd上触发信号时最终调用handle_rx_kick函数,Tap/Tun对应的socket上触发信号时,调用handle_rx_net函数;
-
最终通过handle_rx来完成实际的接收;
3)
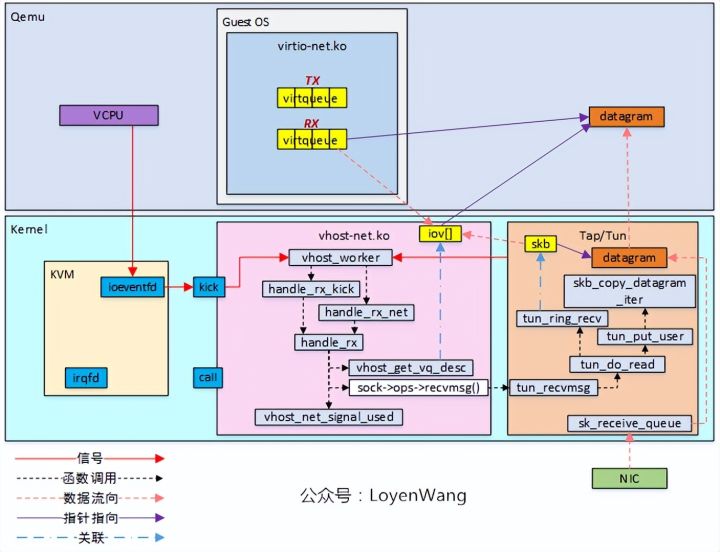
-
接收过程中,vhost_get_vq_desc获取virtqueue中的可用buffer,并将信息存储到iov[]中;
-
sock->ops->recvmsg()函数实际指向tun_recvmsg函数,在该函数中最终完成数据的传递;
4)
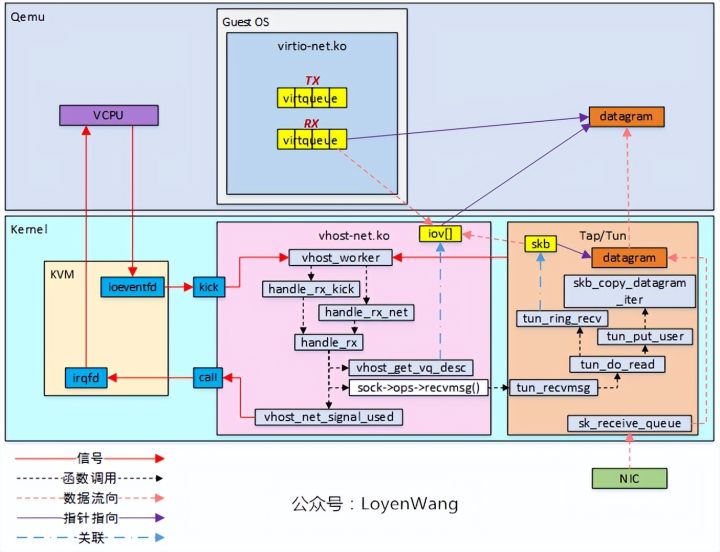
-
数据接收完成后,通过irqfd机制通过vcpu,从而在Guest OS中进行处理;