语音识别技术能够让计算机理解人类的语音,从而支持多种语音交互的场景,如手机应用、人车协同、机器人对话、语音转写等。然而,在这些场景中,语音识别的输入并不总是单一的语言,有时会出现多语言混合的情况。例如,在中文场景中,我们经常会使用一些英文专业术语来表达意思,如“GPS信号弱”、“Java工程师”等,这就给语音识别技术带来了新的挑战。
本次PaddleSpeech发布的中英文语音识别预训练模型Conformer_talcs可以通过PaddleSpeech封装的命令行工具CLI或者Python接口快速使用,开发者们可以基于此搭建自己的智能语音应用,也可以参考示例训练自己的中英文语音识别模型。
示例链接
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/tal_cs/asr1
快速体验
示例音频
https://paddlespeech.bj.bcebos.com/PaddleAudio/ch_zh_mix.wav
使用命令行工具CLI 快速体验语音识别效果,命令如下:
bash
paddlespeech asr --model conformer_talcs --lang zh_en --codeswitch True --input ./ch_zh_mix.wav -v
# 终端输出:今天是monday 明天是tuesdayPython 接口快速体验,代码实现如下:
python
>>> import paddle
>>> from paddlespeech.cli.asr import ASRExecutor
>>> asr_executor = ASRExecutor()
>>> text = asr_executor(
model='conformer_talcs',
lang='zh_en',
sample_rate=16000,
config=None,
ckpt_path=None,
audio_file='./ch_zh_mix.wav',
codeswitch=True,
force_yes=False,
device=paddle.get_device())
>>> print('ASR Result: \n{}'.format(text))
ASR Result:
今天是 monday 明天是tuesday
中英文语音识别技术

中英文语音识别难点
中英文语音识别相较于单语言的语音识别而言,主要难点如下:
数据量少
中英混合数据相较于单语言的数据更少。目前开源的中文语音识别数据集如WenetSpeech(10000小时有监督,2500小时弱监督,10000小时无监督)、英文语音识别数据集Giga Speech(10000小时有监督,33000小时无监督)都达到了万小时级别,但是混合的开源中英文语音识别数据只有SEAME(120小时)和TAL_CSASR(587小时)两个开源数据,混合数据集比单语言数据集会更少。
中英相似发音易混淆
中英文语音识别需要一个单一的模型来学习多种语音,相似但具有不同含义的发音通常会导致模型的复杂度和计算量增加,同时由于它需要区分处理不同语言的类似发音,因此在模型建模时就需要按照不同语言区分不同的建模单元。

PaddleSpeech 中英文语音识别方案
模型选择与介绍
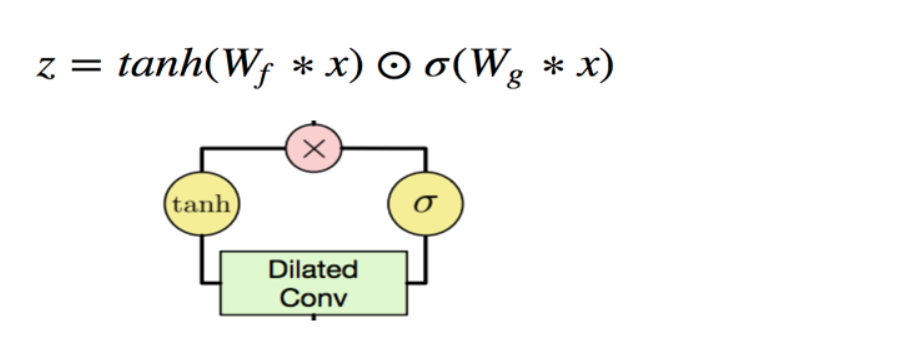
本方案使用了一种端到端语音识别模型Conformer U2模型,其采用了Joint CTC/Attention with Transformer or Conformer的结构。训练时使用CTC 和 Attention Loss 联合优化,并且通过dynamic chunk的训练技巧,使Shared Encoder能够处理任意大小的chunk(即任意长度的语音片段)。其还使用CTC-Prefix Beam Search和Attention Decoder的方式进行解码,得到最终结果,同时实现了流式和非流式的语音识别,支持控制推理延迟。
本次PaddleSpeech开源的预训练模型,是非流式的端到端识别Conformer U2模型,chunk中包含全部上下文信息,需要整句输入进行识别。如果你想训练流式中英文语音识别模型,也可以参考PaddleSpeech的Conformer U2/U2++模型流式语音识别的示例训练自己的流式中英文语音识别模型。
示例链接
https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/wenetspeech/asr1
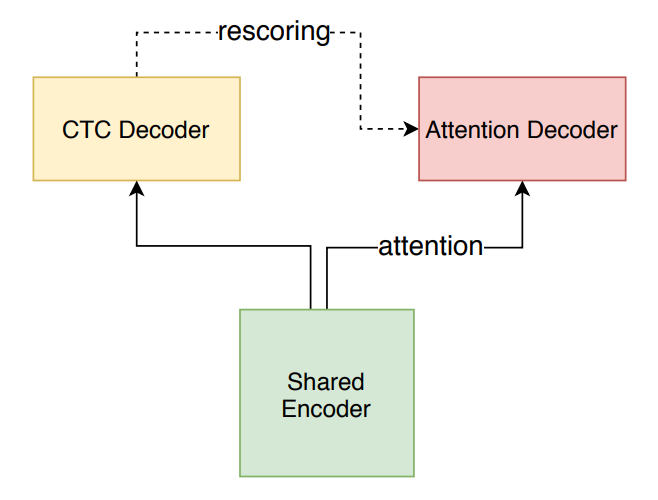
Conformer U2 结构示意图[1]
数据集介绍
本次使用了TAL_CSASR中英混合语音数据集。语音场景为语音授课音频,包括中英混合讲课的情况,总计587小时语音。
数据集下载地址
https://ai.100tal.com/dataset
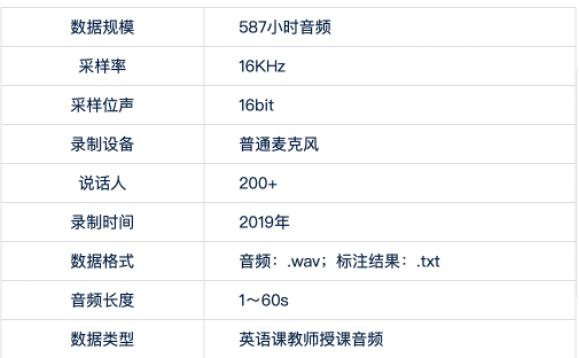
数据集介绍[2]
中英混合语音识别建模单元
在中文语音识别系统中,常采用音素、汉字、词等作为声学模型的建模单元,在英文语音识别系统中则常采用英文音素、国际音标、子词等作为声学模型的建模单元。
本次PaddleSpeech开源的预训练中英文语音识别模型是采用端到端语音识别模型Conformer U2,未接入语言模型,使用了中文字/词加英文子词的建模方法,将中英文分开建模,通过模型推理,直接得到识别后的结果。

试验结果对比
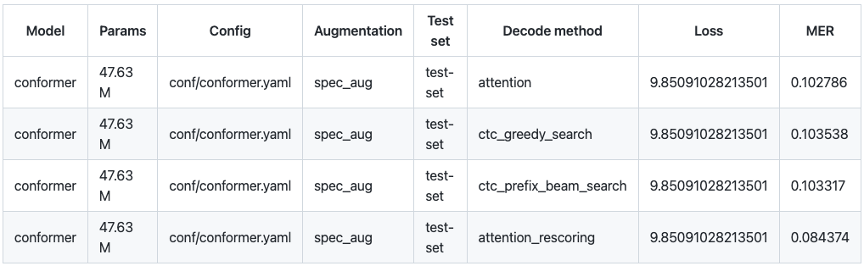
由于本项目使用的是中英文混合数据集,所以我们选择混合错误率(MER,Mix Error Rate)作为评价指标,中文部分计算字错误率(CER,Character Error Rate),英文部分计算词错误率(Word Error Rate)。测试数据集选择TAL_CSASR中已经划分好的测试集。由于不同的解码方式识别的效果不同,这里我们使用 Attention、CTC Greedy Search、CTC Prefix Beam Search、Attention Rescoring 四种解码方式进行试验,解码效果最佳为Attention Rescoring,混合错误率MER为0.084,折算为我们常说的语音识别正确率91.6%。
进一步优化与效果提升
当前中英文语音识别方案的效果还有进一步提升的空间,比如在Conformer U2 模型后面加入Language Model,通过语言模型学习中英文语言信息,PaddleSpeech中提供了基于N-Gram的语言模型训练方案。此外,可以在训练过程中加入Language ID,使用token级别或者帧级别的语言ID标注信息,可以进一步提高中英文语音识别的效果。如果你有更大的中英文混合数据集或者是场景相关的数据集,可以通过微调或者进一步训练,提高在业务场景中的识别效果。

PaddleSpeech 语音识别技术介绍
除了中英文混合的Conformer U2模型以外,飞桨语音模型库PaddleSpeech中包含了多种语音识别模型,能力涵盖了声学模型、语言模型、解码器等多个环节,支持多种语言。目前PaddleSpeech已经支持的语音识别声学模型包括DeepSpeech2、Transfromer、Conformer U2/U2 ++,支持中文和英文的单语言识别以及中英文混合识别;支持CTC前束搜索(CTC Prefix Beam Search)、CTC贪心搜索(CTC Greedy Search)、注意力重打分(Attention Rescoring)等多种解码方式;支持 N-Gram语言模型、有监督多语言大模型Whisper、无监督预训练大模型wav2vec2;同时还支持服务一键部署,可以快速封装流式语音识别和非流式语音识别服务。通过PaddleSpeech提供的命令行工具CLI和Python接口可以快速体验上述功能。
通过PaddleSpeech精品项目合集,可以在线体验PaddleSpeech的优秀项目,上面更有PaddleSpeech核心开发者精心打造的《飞桨PaddleSpeech语音技术课程》,帮助开发者们快速入门。
项目传送门
https://aistudio.baidu.com/aistudio/projectdetail/4692119?contributionType=1

如果您想了解更多有关PaddleSpeech的内容,欢迎前往PaddleSpeech主页学习更多用法,Star 关注,获取PaddleSpeech最新资讯。
PaddleSpeech地址
https://github.com/PaddlePaddle/PaddleSpeech

引用
[1] 模型结构图
https://arxiv.org/pdf/2012.05481.pdf
[2] 数据集介绍
https://ai.100tal.com/dataset
拓展阅读
提速300%,PaddleSpeech 语音识别高性能部署方案重磅来袭
定制音库成本骤降98%,PaddleSpeech小样本语音合成方案重磅来袭

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~