文章目录
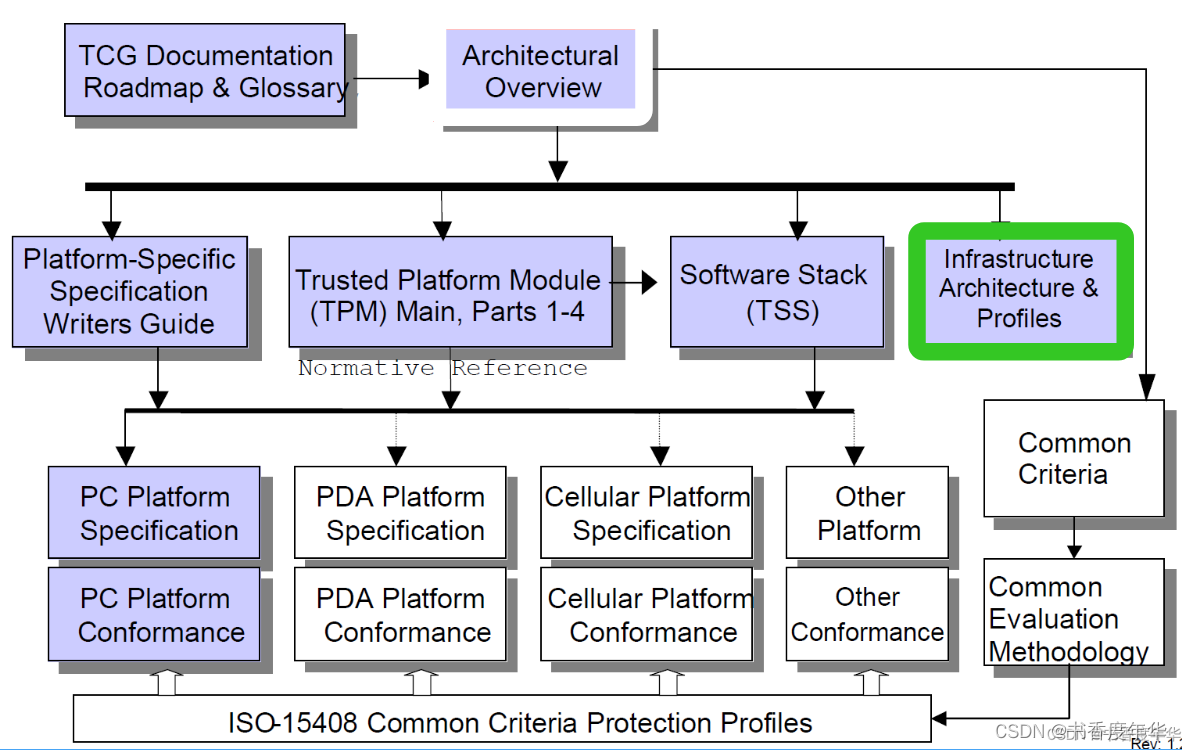
- 1. 哈希表与解决哈希冲突的方法
- 2. C++实现除留余数法拉链法哈希
1. 哈希表与解决哈希冲突的方法
散列表(Hash Table),又称哈希表。是一种数据结构。
特点:数据元素的关键字与其存储地址直接相关。
关键字通过散列函数(哈希函数)来实现。
如果不同的关键字通过哈希函数映射到相同的位置,此时这种情况称为哈希冲突。
哈希冲突的解决方法:
- 拉链法:把所有的冲突的元素以链表的形式挂起来
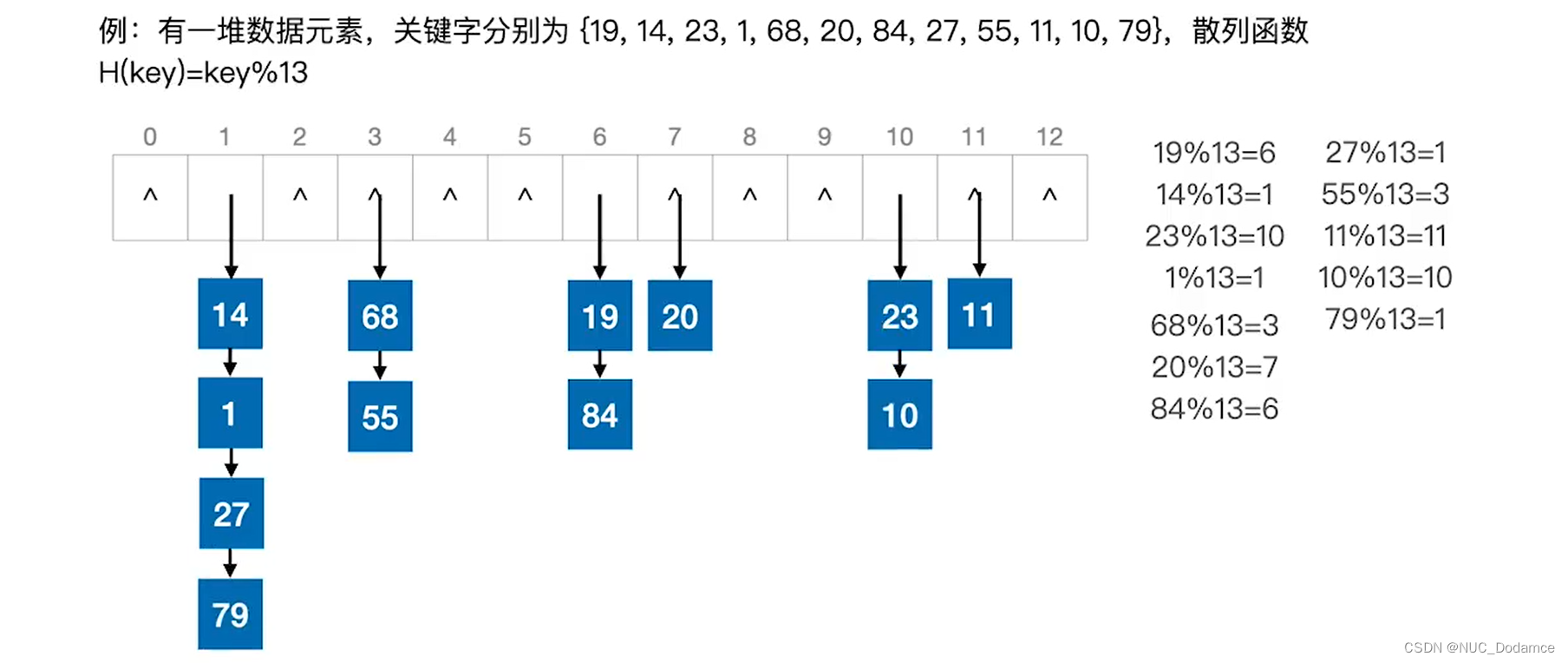
上图的平均成功查找长度:
这里规定如果数组对应位置阿伟空链表,这里为比较0次
-
ASL(成功):1/12(1 * 6+2 * 4+3 * 1+4 * 1)=1.75
-
ASL(失败):失败查找次数/哈希表长度
(0+4+0 + 2+0 + 0 + 2 + 1+0+0 + 2 + 1+0)/13=0.92
可以注意到,ASL查找失败的分子就是哈希表上的有效节点个数
装填因子(负载因子)=表中记录数/散列表长度
装填因子直接影响查找效率.
哈希冲突越严重,效率越低。最理想情况下,不会发生哈希冲突,此时查找效率为O(1)
这个与选择的哈希函数有关,常见的哈希函数如下:
1. 除留余数:H(key) = key % p (p选择不大于m但接近m的质数)
2. 直接定址法:H(key) = key || H(key) = a*key + b,其中,a和b是常数。
这种方法计算最简单,且不会产生冲突。
它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
3. 数字分析法:选取数码分布较为均匀的若干位作为散列地址
4. 平方取中法:取关键字的平方值的中间几位作为散列地址。
- 开放地址法:如果发生冲突后,将冲突的元素按照一定规则放到哈希表其他地方。
这里的规则如下:
-
线性探测法:发生冲突时,每次往后探测相邻的下一个单元是否为空
需要注意:线性探测法在查找时如果这个位置没有数据,也算一次比较。
线性探测法很容易造成关键字、非关键字的“聚集(堆积)”现象,严重影响查找效率
-
平方探测法:发生冲突时,每次向前/后探测的单元个数按照平方依次递增。
d = 02,12,-12,22,-22, …, k2, -k2时,称为平方探测法,又称二次探测法
比起线性探测法更不易产生“聚集(堆积)”问题.
如果使用平方探测法:散列表长度m必须是一个可以表示成4j+3的素数,才能探测到所有位置
-
伪随机序列方式:定义一个伪随机序列,每次冲突时探测距离和伪随机序列相同。
- 再散列方式:(再哈希法)除了原始的散列函数H(key)之外,多准备几个散列函数,当散列函数冲突时,用下一个散列函数计算一个新地址,直到不冲突为止。
综上影响哈希效率的因素如下:
- 哈希函数
- 处理哈希冲突的方式
- 装填因子
2. C++实现除留余数法拉链法哈希
#include <iostream>
#include <vector>
#include <string>
template <class Key, class Value>
struct HashData
{
std::pair<Key, Value> _kv;
HashData<Key, Value> *_next;
HashData(const std::pair<Key, Value> &data) : _kv(data), _next(nullptr) {}
};
// 泛型仿函数
template <class Key>
struct HashKey
{
// 默认仿函数将key转化为可以使用除留余数法的整数型,如果转化失败,需要用户自己提供转化函数
int operator()(const Key &key) { return key; }
};
// 特化字符串类型的转化方式
template <>
struct HashKey<std::string>
{
int operator()(const std::string &Str)
{
int Sum = 0;
for (int i = 0; i < Str.size(); i++)
{
Sum += ((i + 1) * Str[i]); // 尽量避免冲突
}
return Sum;
}
};
template <class Key, class Value, class HashFuc = HashKey<Key>>
class Hash
{
typedef HashData<Key, Value> HashData;
private:
std::vector<HashData *> _table;
size_t _size; // 哈希表中的元素个数
public:
Hash()
{
_size = 0;
_table.resize(4);
for (size_t i = 0; i < _table.size(); i++)
{
_table[i] = nullptr;
}
}
~Hash()
{
for (size_t i = 0; i < _table.size(); i++)
{
HashData *node = _table[i];
if (node != nullptr)
{
HashData *next = node->_next;
delete node;
node = next;
}
_table[i] = nullptr;
}
}
bool insert(const std::pair<Key, Value> &value)
{
HashFuc kot;
HashData *node = _findPos(value);
if (node != nullptr)
{
// 不允许相同值出现
return false;
}
else
{
if (_size == _table.size())
{
// 装填因子为1,扩大哈希表,提高哈希效率
std::vector<HashData *> buff;
buff.resize(_table.size() * 2);
// 重新计算映射关系
for (size_t i = 0; i < _table.size(); i++)
{
HashData *ptr = _table[i];
while (ptr != nullptr)
{
HashData *next = ptr->_next;
size_t new_pos = kot(ptr->_kv.first) % buff.size();
ptr->_next = buff[new_pos];
buff[new_pos] = ptr;
ptr = next;
}
}
_table.swap(buff);
}
size_t pos = kot(value.first) % _table.size();
// 头插法
HashData *data = new HashData(value);
data->_next = _table[pos];
_table[pos] = data;
_size += 1;
return true;
}
}
bool erase(const Key &key)
{
HashFuc kot;
size_t pos = kot(key.first) % _table.size();
HashData *node = _table[pos];
HashData *prev = nullptr;
while (node != nullptr)
{
if (node->_kv.first != key)
{
prev = node;
node = node->_next;
}
}
if (node != nullptr)
{
if (prev == nullptr)
{
// 头删
_table[pos] = node->_next;
delete node;
}
else
{
prev->_next = node->_next;
delete node;
}
return true;
}
else
{
// 无此元素
return false;
}
}
void disPlay()
{
for (size_t i = 0; i < _table.size(); i++)
{
HashData *node = _table[i];
while (node != nullptr)
{
std::cout << node->_kv.first << ":" << node->_kv.second << " | ";
node = node->_next;
}
std::cout << "\n";
}
}
Value operator[](const Key &key)
{
HashData *find = _findPos(std::make_pair(key, Value()));
if (find != nullptr)
{
return find->_kv.second;
}
else
{
// 没有找到这个元素,直接插入到哈希表中
insert(std::make_pair(key, Value()));
return Value();
}
}
private:
HashData *_findPos(const std::pair<Key, Value> &value)
{
HashFuc kot;
size_t pos = kot(value.first) % _table.size();
HashData *cur = _table[pos];
while (cur != nullptr)
{
if (cur->_kv.first == value.first)
{
break;
}
cur = cur->_next;
}
return cur;
}
};
#include "Hash.h"
using namespace std;
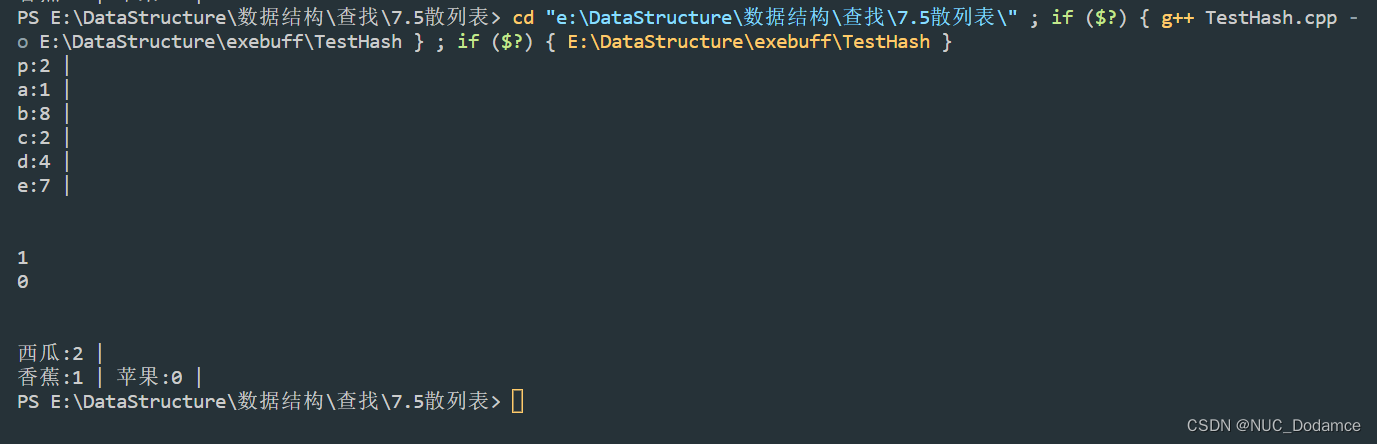
void test1()
{
Hash<char, int> hash;
hash.insert({'a', 1});
hash.insert({'c', 2});
hash.insert({'d', 4});
hash.insert({'e', 7});
hash.insert({'b', 8});
hash.insert({'p', 2});
hash.disPlay();
cout << hash['a'] << endl;
cout << hash['z'] << endl;
}
void test2()
{
vector<string> Array = {"苹果", "香蕉", "西瓜", "香蕉", "香蕉", "西瓜", "西瓜", "苹果"};
Hash<string, int> Hash;
for (int i = 0; i < Array.size(); i++)
{
Hash.insert(make_pair(Array[i], i));
}
Hash.disPlay();
}
int main(int argc, char const *argv[])
{
test1();
test2();
return 0;
}
运行结果