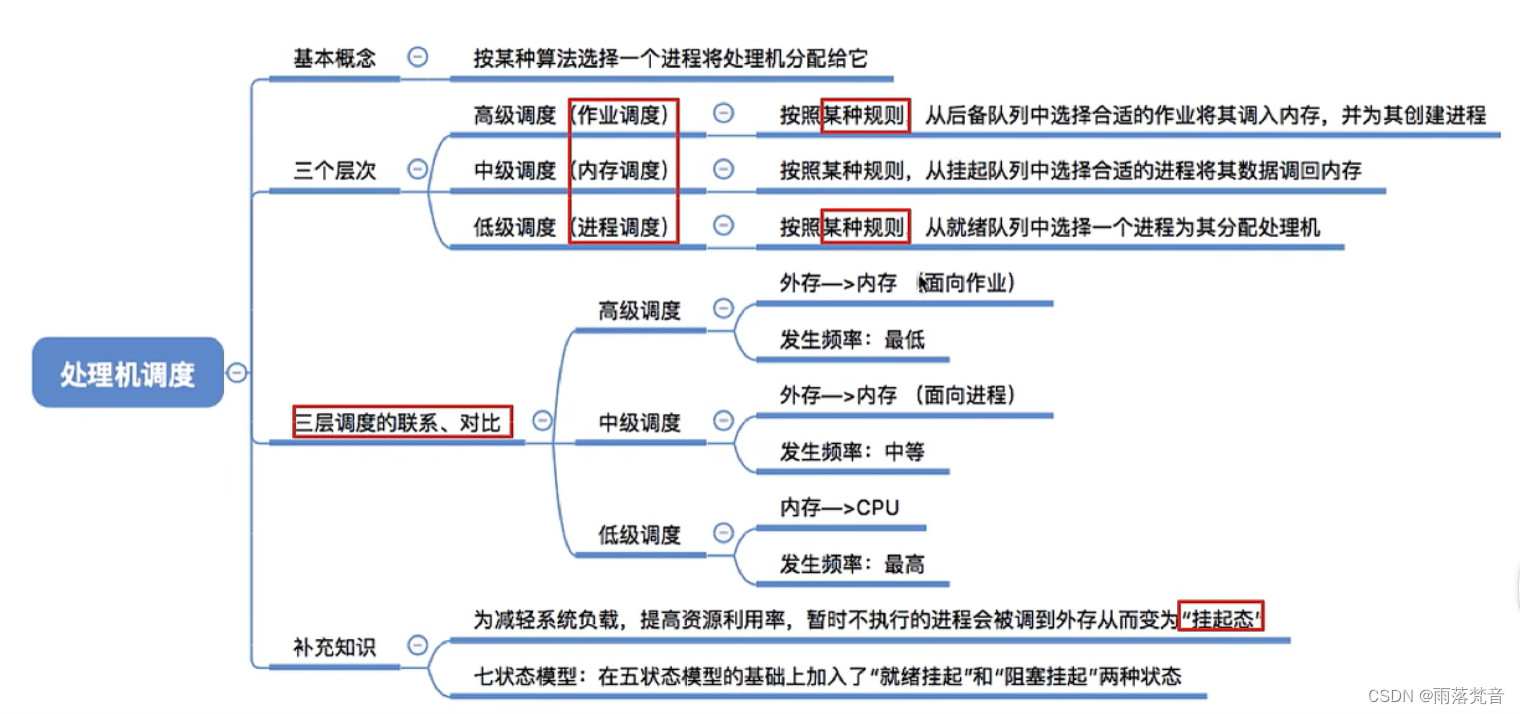
Graph Neural Network(GNN)图神经网络,是一种旨在对图结构数据就行操作的深度学习算法。它可以很自然地表示现实世界中的很多问题,包括社交网络,分子结构和交通网络等。GNN旨在处理此类图结构数据,并对图中的节点和边进行预测或执行任务。
GNN中节点的信息 通过节点和节点之间连接的边 在节点之间传递。其中每个节点都可以从其和它相邻的节点中接收信息并相应地更新自己的信息,这个过程通常会重复多次以使信息充分地沿着边流动和在节点出聚合。然后这些更新的节点可以用于对节点的分类(node classification)、节点之间边的预测(两个节点之间是否存在边)、对于整个图的分类、生成一个新的图(比如VAE或GAN)等等。这些已经应用于化学,社交网络和推荐系统等各个领域。
1.Graph 图
在计算机科学中,图是一种抽象的数据类型,旨在实现数学图论领域中的无向图和有向图概念。图类型的数据结构由一组有限的(可能是可变的)顶点(也称为节点或点)组成,对于无向图,这些顶点在一组无序对内,对于有向图,这些顶点在一组有序对内。这些对被称为边(也称为链接或线),对于有向图,这些对也被称为边,但有时也称为箭头或圆弧。顶点可以是图形结构的一部分,也可以是由整数索引或引用表示的外部实体。

例如,我们使用图来表示社交网络,如下图所示,图中的每个节点代表一个人,每两个节点之间的边则代表了这两个人互相认识,比如Person A 分别和Person B和Person C是好朋友,B又和D是好朋友,但是C和D却互不认识。如果这条边是无向的,可以表示较为平等的关系,比如友谊,同学等;如果是有向的,可以用来表示上下级,或是师生等关系。

2.Graph neural network 图神经网络
图神经网络是一类用于处理可以表示为图的数据的人工神经网络。在A Comprehensive Survey on Graph Neural Networks https://arxiv.org/pdf/1901.00596.pdf 中提出了将图神经网络进一步地分为Recurrent graph neural networks (RecGNNs)递归图神经网络、Convolutional graph neural networks (ConvGNNs)卷积图神经网络、Graph autoencoders (GAEs)图自动编码器 和 Spatial-temporal graph neural networks (STGNNs)时空图神经网络。
2.1 Recurrent graph neural networks (RecGNNs)循环图神经网络:
它是传统图神经网络的一种衍生,具有循环结构。循环图神经网络用来处理一系列图结构的数据,在这个过程中图随着时间而改变。在RecGNN中,图结构和图节点在每个时间步上面更新,并且更新后的信息用于做预测或者完成一些其他任务。循环图神经网络和传统的图神经网络主要区别是循环图神经网络在一个时间步上处理图一次,并且会用之前时间步的信息来更新图。(其实就是递归神经网络和普通网络的区别,然后传入的数据为图结构)。
递归神经网络相关介绍可以参看之前的文章:
https://mp.weixin.qq.com/s/tvvXyCEox-BA-Ox65v1IXQ
2.2 Convolutional graph neural networks (ConvGNNs)卷积图神经网络:
它结合了卷积运算来处理图结构数据。ConvGNN旨在用于具有固定、已知结构的图,其目标是学习节点和边的表示,这种表示对于他们在图中的相对位置不变。
在ConvGNN中,卷积运算应用于图结构和节点特征,以及更新节点和边。被更新的节点和边被传入下一层,在下一层中重复该过程。通过堆叠多层卷积层,ConvGNN可以学习图中节点和边之间越来越复杂的关系。
ConvGNN中的卷积运算被设计为置换不变的,这意味着无论图中节点和边的顺序如何,输出都是相同的。这使得ConvGNN非常适合用于节点分类、连接预测和图生成等任务。这类任务中图的结构是固定的,但是节点特征可能会发生变化。
ConvGNNs已应用于各种现实世界的问题,例如药物探索、蛋白质折叠和社交网络分析。他们特别适合需要从图结构数据中提取局部低维特征的任务,因为卷积运算旨在捕获节点和边之间的局部关系。
一个具体的例子如下图,Graph G为一个图结构数据,它有ABCDE五个节点,这五个节点每个节点有一个自己的特征向量,这里是1x3的一个向量,那么特征矩阵如图中Feature vector X 所示;对于每两个节点之间是否存在边相连,我们用邻接矩阵来表示,如下图中的Adjacency matrix A,因为整个图的边是没有方向的,所以这个图的邻接矩阵为对称矩阵,A -->E 和 E --> A对应的位置为1,而不相关的节点A -->B 则为0,同时这个图中没有一个节点存在self-loop,所以它的邻接矩阵的对角线上的值全为0,A–>A为0;从图中我们还可以发现有些节点与周围的节点产生的联系比较强,而有些节点却很少,我们用度矩阵来表示节点的这种属性,图Degree matrix D中可以看到E它与周围四个点产生了连接所以它的degree为4,而A只与E这一个节点产生连接,所以A的degree为1。

那么这些节点是如何互相影响的呢,也就是每个节点的特征如何通过边来影响到周围节点的特征的,这个过程简易地表示为下图。通过将邻接矩阵和特征矩阵进行叉乘,在邻接矩阵中,A只与E产生连接,所以相乘后,A从临近节点得到的特征全部来自于E节点。对于B,它和D、E相连,那它从临近节点得到的特征来自于D和E,这里来自D和E的权重均为1,也就是B受D和E的特征影响一样。

对于上面这个过程,我们可以看到一些不合理的地方,例如缺少了来自节点自身的特征,对于上图中得到的A结果矩阵也应该包括节点A的特征才合理,而不是只包含了来自于E节点的特征。
对于这个问题,我们可以通过向邻接矩阵A添加一个单位矩阵I来解决,得到新的邻接矩阵Ã。

当lambda=1(来自自身的特征和来自相连节点的特征一样重要),Ã = A + I。注意到这里我们可以将lambda作为一个可以训练的参数,现在这里给lambda赋值为1,得到新的邻接矩阵Ã,在新的邻接矩阵中就有self-loop了。

另外一个问题是,我们从相连的节点中的到特征不应该是简单的直接相加,比如对于B节点,直接相加从D和E节点的特征以形成自己的特征不合理,假如我们使用直接求和的方式,那么对于Degree很大的节点,也就是和周围节点连接比较强的时候,会造成该节点得到的值很大,而deree很低的节点得到的矩阵中值却很小,并且会在后期产生梯度爆炸或者消失。所以,或许我们可以采取求均值,或者使用更好的方法。此外神经网络似乎对输入数据的规模很敏感。因此,我们需要对这些向量进行归一化以消除潜在问题。
对于矩阵缩放,通常乘上一个对角矩阵。在这个例子中,我们试图去采取对特征求和再求均值,更为数学的表达就是说,根据节点的degree来缩放向量矩阵X。对于单个节点,如果与它连接的节点越多,那么每个节点对它造成的影响越小,如果它只与一个节点相连,那么与它相连的那个节点就会对这个节点造成较大的影响。这个就像,当你心里只在乎一个人的时候,那个这个人就很容易影响到你的心理状态,当你拥有大爱,心怀的是全地球上的居民,那么单个人对你的影响就小。
如下图中,新的邻接矩阵中包含self-loop,那么对于这个新的graph中的每一个节点的degree都加1,然后取倒数,就是与之相连的节点对该节点的平均权重。例如,节点A它与自身和E相连,那么degree为2,所以对于求和得到的矩阵需要除以2,对于E,它的degree为5,那么对于它的求和得到的矩阵需要除以5。

因此,通过将新的邻接矩阵和特征矩阵相乘的结果 与 新的度矩阵的逆矩阵相乘,得到所有相邻的特征向量(包括它自己)的平均。

上图中的邻接矩阵Ã为对称矩阵,这意味着它的行数和列数相同,上图的过程仅是对矩阵中的每一行进行了处理,那么直观地来说应该对每一列也做相同地处理。那么上图的过程中就需要再乘一个矩阵进行列变换,公式由原来的的 D ̃^(-1) A ̃X 变为 D ̃^(-1) A ̃D ̃^(-1) X ,示意图如下图所示:

这种新的缩放给我们加权均值。我们这里现在在做的是放更多的权重在那些有更低的degree的节点上,以减少拥有高degree节点的影响。这个加权均值的想法是,我们假设低degree的节点对他们的对它们相连的节点有更大的影响,而高degree节点产生低的影响,因为它们将影响分散给太多的邻居了。就像退休在家的父母,当他们渐渐地脱离了与集体的连接,家人变成了他们主要的连接点,所以他们会花较多的时间在家人身上,家人也因此会比之前更受影响,这个影响的性质取决于退休父母的属性(特征),比如乐观积极,会照顾家人,又或是爱攀比,爱面子,三天两头折腾子女等等。
虽然对行和列都进行了处理,也就是对于邻接矩阵的左右两边都乘以了 D ̃^(-1) ,这个过程相当于归一化了两次,所以我们这里应该使用 D ̃^(-1/2) 如下图,而不是D ̃^(-1),即公式 D ̃^(-1/2) A ̃D ̃^(-1/2) X 。

综上所述,一个2层的GCN的前向模型的公式如下:

其中:

网络层的数量决定了可以获取的最远的节点特征,例如,只有一层GCN,那么每个节点仅可以获得来自它相邻节点的特征。收集信息的过程是相互独立的,同时适用于所有节点。当在第一层上堆叠另外一层时,我们重复之前的步骤收集信息,但是这次,相连节点的信息早已经有了它们自身相连的节点的信息。所以层数即为每个节点可以跳跃到的最远的节点数。也可以认为节点应该从网络中获取信息的距离。我们可以为层配置适当的数量。通常我们不希望距离太远,根据六度分隔理论(Six Degrees of Separation)当一个节点一直向外层走了6步时,那么它将可以得到来自整个图的信息,这会使得整个模型没有意义。

那我们需要多少层呢,一般两三层就行了。
这个例子来自下面连接:
https://ai.plainenglish.io/graph-convolutional-networks-gcn-baf337d5cb6b
2.3 Graph autoencoders (GAEs)图自动编码器:
图自动编码器(Graph Autoencoder,GAE)是一种用于图结构数据的无监督学习模型,主要用于将图结构数据压缩成低维向量表示并进行重构。
在GAE中,目标是学习可用于重建原始图的图表示。GAE由两个主要成分组成:一个编码器和一个解码器。编码将图中的节点和边映射到低维表示,解码器将低维表示还原到原始的图结构。
GAE中的encoder(编码器)和decoder(解码器)通常为神经网络,并且对这些神经网络进行训练以最小化原始图和重建图之间的重建误差。通过训练GAE,编码器学习图形的低维表示,捕捉节点和边之间最重要的关系。
GAEs 已经应用于各种现实世界的问题,例如图分类,图重构和图生成等。下图是一个图重构的例子。

自动编码是一种人工神经网络用于对无标签数据学习有效的编码。一个自动编码器学习两个函数:一个编码函数转换输入数据,一个解码函数从被编码的表现中重建输入的数据。
变体的存在是为了强制学习到表示具有有用的属性。例如regularized autoencoders正则自编码器(稀疏、去噪和收缩),可以有效学习后续分类任务的表示,以及变分自动编码器,作为生成模型来应用。自编码器应用于许多问题,包括人脸识别、特征检测、异常检测和获取单词的含义。自动编码器也是生成模型,可以随机生成与输入数据(训练数据)相似的数据。
数学原理
自编码器由下列成分定义:
两个集合:解码消息空间 χ;编码消息空间Ζ。χ和Ζ均几乎总是欧拉空间,也就是 χ=R^m, Z=R^n,对于任意给定m,n (R为实数集)。
两个参数化函数族:编码族Ε_ϕ: χ→ Ζ , 被 ϕ 参数化;解码族 D_θ: Ζ→ χ ,被 θ 参数化。
对于任意的 x ϵ χ,我们通常写 z=Ε_ϕ (x) ,并将其称为code,潜在变量,潜在表示(隐层表示),本真向量等。相反的,对于任何 z ∈ Ζ ,我们通常写 x^‘=D_θ (z) ,并把它称为(解码)信息。
通常,编码和解码被定义为多层感知器。例如,一层MLP编码器 Ε_ϕ 为:
Ε_ϕ (Χ)= σ(Wx+b)
其中 σ 为element-wise激活函数,例如sigmoid函数或者rectified linear unit(整流线性单元), W 是一个叫做权重的矩阵,b为一个向量,称为bias (偏置,类似于线性拟合那个截距b)。
训练一个自动编码器
一个自动编码器,它自身是一个简单的两个function组成的数组。为了判断它的性能,我们需要一个任务。该任务被定义为在χ上的参考概率分布 μ_ref 和一个重建质量函数d: χ×χ→[0,∞],例如d(x,x’) 测量x’距离x有多远。综上,我们可以为自编码器定义损失函数为:
L(θ,ϕ)≔ Ε_(x~μ_ref ) [d(x,D_θ (E_ϕ (x)))
对于给定的任务(μ_ref,d)的最优自动编码器是

. 寻找最优自动编码器的过程可以通过如何数学优化技术来完成,但是该技术通常为梯度下降。这个搜索的过程称为训练自动编码器。在大多数情况下,参考分布只是对于给定数据集 {x_1,…,x_N}⊂χ 的经验分布,因此:

并且质量函数为L2loss:

然后最优自动编码器的问题就变为最小二乘优化:


一个自动编码器由两个主要部分组成:一个编码器将消息映射到code,解码器又将code重建为message。一个最优自动编码器应该表现得尽可能接近完美的重建,尽可能完美地被定义为重构质量函数 d。
最简单的方法来完美地执行复制任务就是重复信号。为了抑制这种行为,code空间 Ζ 通常比message 空间 χ 少一些维度。
这种自动编码器被叫做undercomplete欠完成,它可以被理解为压缩message或者减少它的维度。
在一个理想欠完全自动编码器的极限,每个可能的在code空间的code z 用于编码一个真实出现在 μ_ref 分布的message x ,并且解码器也同样是完美的:D_θ (E_ϕ (x))=x。理想的自动编码器可以用于生成messages 和真实的message相同。
如果code 空间Z的维度大于或等于message空间 χ ,或者隐藏单元被给定足够空间,一个自动编码器可以学习恒等函数,并变得无效的。然而,实验结果发现overcomplete自动编码器可能仍然学习到有用的特征。
在理想设置中,可以基于要建模的数据分布的复杂度来设置code维度和模型容量。一个标准的方法是对基本的自动编码器进行修改。(比如下面的各种变体)
该自动编码器可以有多种变体。下图就是它的各种变体,然后从上面链接的网站上可以看到。
https://en.wikipedia.org/wiki/Autoencoder#Variational_autoencoder_(VAE)

2.4 Spatial-temporal graph neural networks (STGNNs)时空图神经网络:
时空图神经网络是一种图神经网络,旨在处理具有空间和时间依赖性的图结构数据。与传统的图神经网络仅考虑节点和图的关系不同,STGNN还考虑了不同时间步长的节点之间的关系。
STGNN通常实现为递归神经网络,其中网络在每个时间步的隐藏状态根据前一个时刻的隐藏状态和当前图结构进行更新。通过考虑节点之间的时间依赖性,STGNN可以随时间捕获数据中的复杂模式和趋势。
STGNN 可以将图神经网络与循环神经网络的优势结合起来,从而有效地利用时空图数据中的空间和时间信息。STGNN 主要有两个部分:空间卷积神经网络 (Spatial GNN) 和时间递归神经网络 (Temporal RNN)。
空间卷积神经网络 (Spatial GNN) 是用于对时空图中的节点进行空间上的特征提取和表示的神经网络。该模型在考虑节点之间的空间关系时,可以使用常规的图卷积神经网络。但由于节点的特征和位置在时间上是变化的,因此需要在此基础上扩展模型来处理时序性。
时间递归神经网络 (Temporal RNN) 是用于处理时空图中的时间序列信息的神经网络。该模型在处理时间序列信息时,通常采用递归神经网络 (Recurrent Neural Networks, RNNs) 或长短时记忆网络 (Long Short-Term Memory, LSTM) 等,以捕捉时间上的依赖性。
STGNN已应用于各种现实问题中,例如交通预测,气候建模和金融市场分析。它们特别适合需要分析具有空间和时间依赖性的图结构数据任务,例如预测网络随时间的演变或分析随时间变化的实体之间的关系。
举个例子,下面示意图中的输入视频同时包含了姿势的空间和时间信息。因此,隐藏层中的节点表示取决于空间和时间方向上的相邻节点。

上图为ST-GCNS应用的一个示意图,比STGNN多了卷积运算,ST-GCN在一个时空图上面工作,它不是分别在时间和空间上进行独立的卷积运算,而是对附近的节点同时在时间和空间上进行卷积运算,如下图所示:

更为详细的内容可以打开下面连接查看:
https://medium.com/axinc-ai/st-gcn-a-machine-learning-model-for-detecting-human-actions-from-skeletons-46a95b31b5db




![Mysql全解[基础篇]](https://img-blog.csdnimg.cn/066c4d9a092f4ebc8c80ce145c024fd4.png)