目录
- MySQL概述
- 数据库相关概念
- MySQL数据库
- 版本
- docker部署单机节点
- sqlmode说明
- 连接mysql
- 数据模型
- 关系型数据库(RDBMS)
- 数据模型
- mysql版本对比
- MySQL 5.5
- MySQL 5.6
- MySQL 5.7
- MySQL 8.0
- SQL
- SQL通用语法
- SQL分类
- DDL
- 数据库操作
- 表操作
- 数据类型
- 数值类型
- 字符串类型
- 日期时间类型
- DML
- 添加数据
- 修改数据
- 删除数据
- DQL
- 查询语法
- 基础查询
- 条件查询
- 条件
- 举例
- 聚合函数
- 分组查询
- 排序查询
- 分页查询
- 执行顺序
- DCL
- 管理用户
- 权限控制
- 图形化界面工具
- 函数
- 字符串函数
- 数值函数
- 日期函数
- 流程函数
- 约束
- 分类
- 外键约束
- 删除/更新行为
- 多表查询
- 多表关系
- 一对多
- 多对多
- 一对一
- 查询分类
- 内连接
- 外连接
- 左外连接
- 右外连接
- 自连接
- 联合查询
- 子查询
- 标量子查询
- 列子查询
- 行子查询
- 表子查询
- 小结
- 事务
- 事务操作
- 控制事务一
- 控制事务二
- 事务四大特性
- 并发事务问题
- 事务隔离级别
MySQL概述
数据库相关概念
而目前主流的关系型数据库管理系统的市场占有率排名如下:
- Oracle:大型的收费数据库,Oracle公司产品,价格昂贵。
- MySQL:开源免费的中小型数据库,后来Sun公司收购了MySQL,而Oracle又收购了Sun公司。
目前Oracle推出了收费版本的MySQL,也提供了免费的社区版本。 - SQL Server:Microsoft 公司推出的收费的中型数据库,C#、.net等语言常用。
- PostgreSQL:开源免费的中小型数据库。
- DB2:IBM公司的大型收费数据库产品。
- SQLLite:嵌入式的微型数据库。Android内置的数据库采用的就是该数据库。
- MariaDB:开源免费的中小型数据库。是MySQL数据库的另外一个分支、另外一个衍生产品,与
- MySQL数据库有很好的兼容性。
不论使用的是上面的哪一个关系型数据库,最终在操作时,都是使用SQL语言来进行统一操作,
因为前面讲到SQL语言,是操作关系型数据库的统一标准 。
MySQL数据库

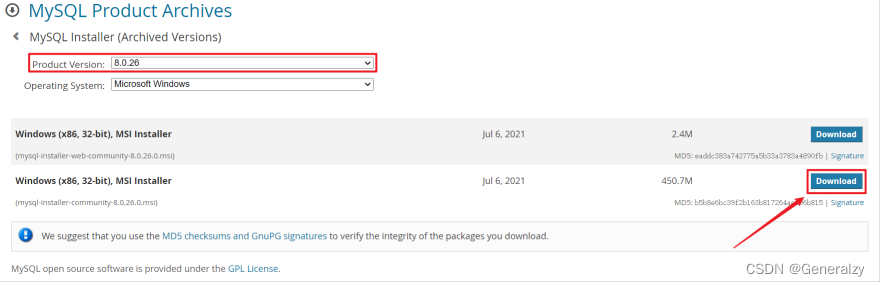
官网:https://www.mysql.com/
下载地址:https://downloads.mysql.com/archives/installer/
版本
- 社区版本(MySQL Community Server)
免费, MySQL不提供任何技术支持 - 商业版本(MySQL Enterprise Edition)
收费,可以使用30天,官方提供技术支持
本文档采用的是MySQL最新的社区版-MySQL Community Server 8.0.26
docker部署单机节点
- 建立目录映射
mkdir -r /mysql/conf/ # 配置文件目录
mkdir -r /mysql/logs/ # 日志目录
mkdir -r /mysql/data/ # 数据目录
- 建立配置文件
vim /mysql/my.cnf
[mysqld]
user=mysql
character-set-server=utf8
default_authentication_plugin=mysql_native_password
secure_file_priv=/var/lib/mysql
expire_logs_days=7
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
max_connections=1000
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
- 创建容器,并后台启动
docker run --restart=always --privileged=true \
-v /mysql/data/:/var/lib/mysql \
-v /mysql/logs/:/var/log/mysql \
-v /mysql/conf/:/etc/mysql \
-v /mysql/my.cnf:/etc/mysql/my.cnf \
-p 3306:3306 --name mysql8 \
-e MYSQL_ROOT_PASSWORD=123456 -d mysql:8.0.26
sqlmode说明
- 查询sql_mode
select @@SESSION.sql_mode
或
select @@SESSION.sql_mode
- sql_mode的值
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中
NO_AUTO_VALUE_ON_ZERO
该值影响自增长列的插入
默认设置下,插入0或NULL代表生成下一个自增长值。如果用户希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。
STRICT_TRANS_TABLES
在该模式下,如果一个值不能插入到一个事务中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告
ERROR_FOR_DIVISION_BY_ZERO
在insert或update过程中,如果数据被零除,则产生错误而非警告。如果未给出该模式,那么数据被零除时Mysql返回NULL
NO_AUTO_CREATE_USER
禁止GRANT创建密码为空的用户
NO_ENGINE_SUBSTITUTION
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常
PIPES_AS_CONCAT
将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样是,也和字符串的拼接函数Concat想类似
ANSI_QUOTES
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符
连接mysql
mysql [-h 127.0.0.1] [-P 3306] -u root -p
参数:
-h : MySQL服务所在的主机IP
-P : MySQL服务端口号, 默认3306
-u : MySQL数据库用户名
-p : MySQL数据库用户名对应的密码
[]内为可选参数,如果需要连接远程的MySQL,需要加上这两个参数来指定远程主机IP、端口,如果连接本地的MySQL,则无需指定这两个参数。
数据模型
关系型数据库(RDBMS)
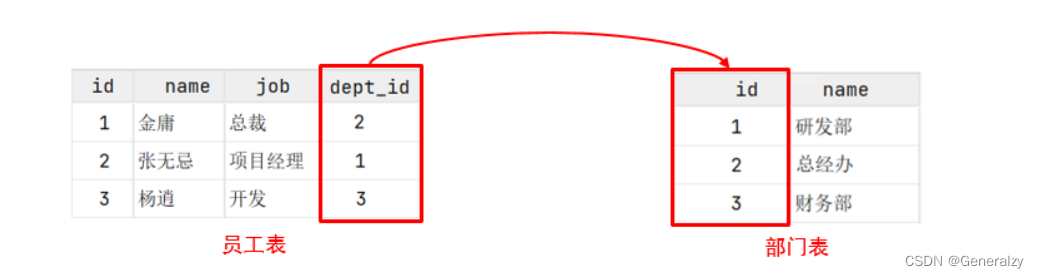
概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
而所谓二维表,指的是由行和列组成的表,如下图(就类似于Excel表格数据,有表头、有列、有行,还可以通过一列关联另外一个表格中的某一列数据)。
MySQL、Oracle、DB2、SQLServer这些都是属于关系型数据库,里面都是基于二维表存储数据的。简单说,基于二维表存储数据的数据库就成为关系型数据库,不是基于二维表存储数据的数据库,就是非关系型数据库。
特点:
- 使用表存储数据,格式统一,便于维护。
- 使用SQL语言操作,标准统一,使用方便。
数据模型
MySQL是关系型数据库,是基于二维表进行数据存储的,具体的结构图下:
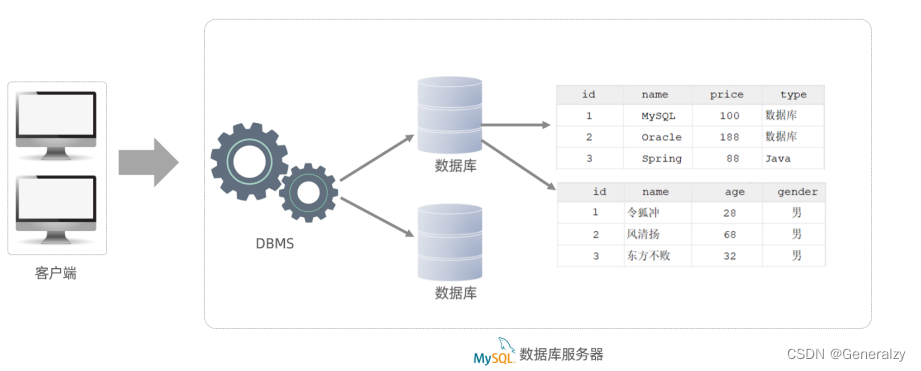
- 可以通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库。
- 可以使用SQL语句,通过数据库管理系统操作数据库,以及操作数据库中的表结构及数据。
- 一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
mysql版本对比
MySQL 的版本实际使用来说,mysql5.6 mysql5.7 mysql8.0 是目前使用最多的版本。
MySQL 5.5
- InnoDB代替MyISAM成为MySQL默认的存储引擎。
- 多核扩展,能更充分地使用多核CPU。
- InnoDB的性能提升,包括支持索引的快速创建,表压缩,I/O子系统的性能提升,PURGE操作从主线程中剥离出来,Buffer Pool可拆分为多个Instances。
- 半同步复制。
- 引入utf8mb4字符集,可用来存储emoji表情。
- 引入metadata locks(元数据锁)。
- 分区表的增强,新增两个分区类型:RANGE COLUMNS和LIST COLUMNS。
- MySQL企业版引入线程池。
- 可配置IO读写线程的数量(innodb_read_io_threads,innodb_write_io_threads)。在此之前,其数量为1,且不可配置。
- 引入innodb_io_capacity选项,用于控制脏页刷新的数量。
MySQL 5.6
- GTID复制。
- 无损复制。
- 延迟复制。
- 基于库级别的并行复制。
- mysqlbinlog可远程备份binlog。
- 对TIME, DATETIME和TIMESTAMP进行了重构,可支持小数秒。DATETIME的空间需求也从之前的8个字节减少到5个字节。
- Online DDL。ALTER操作不再阻塞DML。
- 可传输表空间(transportable tablespaces)。
- 统计信息的持久化。避免主从之间或数据库重启后,同一个SQL的执行计划有差异。
- 全文索引。
- InnoDB Memcached plugin。
- EXPLAIN可用来查看DELETE,INSERT,REPLACE,UPDATE等DML操作的执行计划,在此之前,只支持SELECT操作。
- 分区表的增强,包括最大可用分区数增加至8192,支持分区和非分区表之间的数据交换,操作时显式指定分区。
- Redo Log总大小的限制从之前的4G扩展至512G。
- Undo Log可保存在独立表空间中,因其是随机IO,更适合放到SSD中。但仍然不支持空间的自动回收。
- 可dump和load Buffer pool的状态,避免数据库重启后需要较长的预热时间。
- InnoDB内部的性能提升,包括拆分kernel mutex,引入独立的刷新线程,可设置多个purge线程。
- 优化器性能提升,引入了ICP,MRR,BKA等特性,针对子查询进行了优化。
MySQL 5.7
- 组复制
- InnoDB Cluster
- 多源复制
- 增强半同步(AFTER_SYNC)
- 基于WRITESET的并行复制。
- 在线开启GTID复制。
- 在线设置复制过滤规则。
- 在线修改Buffer pool的大小。
- 在同一长度编码字节内,修改VARCHAR的大小只需修改表的元数据,无需创建临时表。
- 可设置NUMA架构的内存分配策略(innodb_numa_interleave)。
- 透明页压缩(Transparent Page Compression)。
- UNDO表空间的自动回收。
- 查询优化器的重构和增强。
- 可查看当前正在执行的SQL的执行计划(EXPLAIN FOR CONNECTION)。
- 引入了查询改写插件(Query Rewrite Plugin),可在服务端对查询进行改写。
- EXPLAIN FORMAT=JSON会显示成本信息,这样可直观的比较两种执行计划的优劣。
- 引入了虚拟列,类似于Oracle中的函数索引。
- 新实例不再默认创建test数据库及匿名用户。
- 引入ALTER USER命令,可用来修改用户密码,密码的过期策略,及锁定用户等。
- mysql.user表中存储密码的字段从password修改为authentication_string。
- 表空间加密。
- 优化了Performance Schema,其内存使用减少。
- Performance Schema引入了众多instrumentation。常用的有Memory usage instrumentation,可用来查看MySQL的内存使用情况,Metadata Locking Instrumentation,可用来查看MDL的持有情况,Stage Progress instrumentation,可用来查看Online DDL的进度。
- 同一触发事件(INSERT,DELETE,UPDATE),同一触发时间(BEFORE,AFTER),允许创建多个触发器。在此之前,只允许创建一个触发器。
- InnoDB原生支持分区表,在此之前,是通过ha_partition接口来实现的。
- 分区表支持可传输表空间特性。
- 集成了SYS数据库,简化了MySQL的管理及异常问题的定位。
- 原生支持JSON类型,并引入了众多JSON函数。
- 引入了新的逻辑备份工具-mysqlpump,支持表级别的多线程备份。
- 引入了新的客户端工具-mysqlsh,其支持三种语言:JavaScript, Python and SQL。两种API:X DevAPI,AdminAPI,其中,前者可将MySQL作为文档型数据库进行操作,后者用于管理InnoDB Cluster。
- mysql_install_db被mysqld --initialize代替,用来进行实例的初始化。
- 原生支持systemd。
- 引入了super_read_only选项。
- 可设置SELECT操作的超时时长(max_execution_time)。
- 可通过SHUTDOWN命令关闭MySQL实例。
- 引入了innodb_deadlock_detect选项,在高并发场景下,可使用该选项来关闭死锁检测。
- 引入了Optimizer Hints,可在语句级别控制优化器的行为,如是否开启ICP,MRR等,在此之前,只有Index Hints。
- GIS的增强,包括使用Boost.Geometry替代之前的GIS算法,InnoDB开始支持空间索引。
MySQL 8.0
- 引入了原生的,基于InnoDB的数据字典。数据字典表位于mysql库中,对用户不可见,同mysql库的其它系统表一样,保存在数据目录下的mysql.ibd文件中。不再置于mysql目录下。
- Atomic DDL。
- 重构了INFORMATION_SCHEMA,其中,部分表已重构为基于数据字典的视图,在此之前,其为临时表。
- PERFORMANCE_SCHEMA查询性能提升,其已内置多个索引。
- 不可见索引(Invisible index)。
- 降序索引。
- 直方图。
- 公用表表达式(Common table expressions)。
- 窗口函数(Window functions)。
- 角色(Role)。
- 资源组(Resource Groups),可用来控制线程的优先级及其能使用的资源,目前,能被管理的资源只有CPU。
- 引入了innodb_dedicated_server选项,可基于服务器的内存来动态设置innodb_buffer_pool_size,innodb_log_file_size和innodb_flush_method。
- 快速加列(ALGORITHM=INSTANT)。
- JSON字段的部分更新(JSON Partial Updates)。
- 自增主键的持久化。
- 可持久化全局变量(SET PERSIST)。
- 默认字符集由latin1修改为utf8mb4。
- 默认开启UNDO表空间,且支持在线调整数量(innodb_undo_tablespaces)。在MySQL 5.7中,默认不开启,若要开启,只能初始化时设置。
- 备份锁。
- Redo Log的优化,包括允许多个用户线程并发写入log buffer,可动态修改innodb_log_buffer_size的大小。
- 默认的认证插件由mysql_native_password更改为caching_sha2_password。
- 默认的内存临时表由MEMORY引擎更改为TempTable引擎,相比于前者,后者支持以变长方式存储VARCHAR,VARBINARY等变长字段。从MySQL 8.0.13开始,TempTable引擎支持BLOB字段。
- Grant不再隐式创建用户。
- SELECT ... FOR SHARE和SELECT ... FOR UPDATE语句中引入NOWAIT和SKIP LOCKED选项,解决电商场景热点行问题。
- 正则表达式的增强,新增了4个相关函数,REGEXP_INSTR(),REGEXP_LIKE(),REGEXP_REPLACE(),REGEXP_SUBSTR()。
- 查询优化器在制定执行计划时,会考虑数据是否在Buffer Pool中。而在此之前,是假设数据都在磁盘中。
- ha_partition接口从代码层移除,如果要使用分区表,只能使用InnoDB存储引擎。
- 引入了更多细粒度的权限来替代SUPER权限,现在授予SUPER权限会提示warning。
- GROUP BY语句不再隐式排序。
- MySQL 5.7引入的表空间加密特性可对Redo Log和Undo Log进行加密。
- information_schema中的innodb_locks和innodb_lock_waits表被移除,取而代之的是performance_schema中的data_locks和data_lock_waits表。
- 引入performance_schema.variables_info表,记录了参数的来源及修改情况。
- 增加了对于客户端报错信息的统计(performance_schema.events_errors_summary_xxx)。
- 可统计查询的响应时间分布(call sys.ps_statement_avg_latency_histogram())。
- 支持直接修改列名(ALTER TABLE ... RENAME COLUMN old_name TO new_name)。
- 用户密码可设置重试策略(Reuse Policy)。
- 移除PASSWORD()函数。这就意味着无法通过“SET PASSWORD ... = PASSWORD('auth_string') ”命令修改用户密码。
- 代码层移除Query Cache模块,故Query Cache相关的变量和操作均不再支持。
- BLOB, TEXT, GEOMETRY和JSON字段允许设置默认值。
- 可通过RESTART命令重启MySQL实例。
SQL
全称 Structured Query Language,结构化查询语言。操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准。
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 注释:
- 单行注释:
--注释内容 或#注释内容 - 多行注释:
/* 注释内容 */
- 单行注释:
SQL分类
SQL语句,根据其功能,主要分为四类:DDL、DML、DQL、DCL。

DDL
Data Definition Language,数据定义语言,用来定义数据库对象(数据库,表,字段) 。
数据库操作
- 查询所有数据库
show databases ;
- 查询当前数据库
select database() ;
- 创建数据库
create database [ if not exists ] 数据库名 [ default charset 字符集 ] [ collate 排序
规则 ] ;
1. 字符集已经在配置文件中写入了utf8,也可以指定为utf8mb4
2. create database itheima default charset utf8mb4;
- 删除数据库
drop database [ if exists ] 数据库名 ;
- 切换数据库
use 数据库名 ;
表操作
- 查询当前数据库所有表(必须先切换到某个数据库下)
show tables;
- 查看指定表结构
desc 表名 ;
- 查询指定表的建表语句
show create table 表名 ;
- 创建表结构(最后一个字段后面没有逗号)
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释 ],
字段2 字段2类型 [COMMENT 字段2注释 ],
字段3 字段3类型 [COMMENT 字段3注释 ],
......
字段n 字段n类型 [COMMENT 字段n注释 ]
) ENGINE=InnoDB DEFAULT CHARSET=utf8 [ COMMENT 表注释 ] ;
create table tb_user(
id int comment '编号',
name varchar(50) comment '姓名',
age int comment '年龄',
gender varchar(1) comment '性别'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 comment '用户表';
- 添加字段
ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
- 修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型 (长度);
- 修改字段名和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];
- 删除字段
ALTER TABLE 表名 DROP 字段名;
- 修改表名
ALTER TABLE 表名 RENAME TO 新表名;
- 删除表
DROP TABLE [ IF EXISTS ] 表名;
- 删除指定表, 并重新创建表
TRUNCATE TABLE 表名;
数据类型
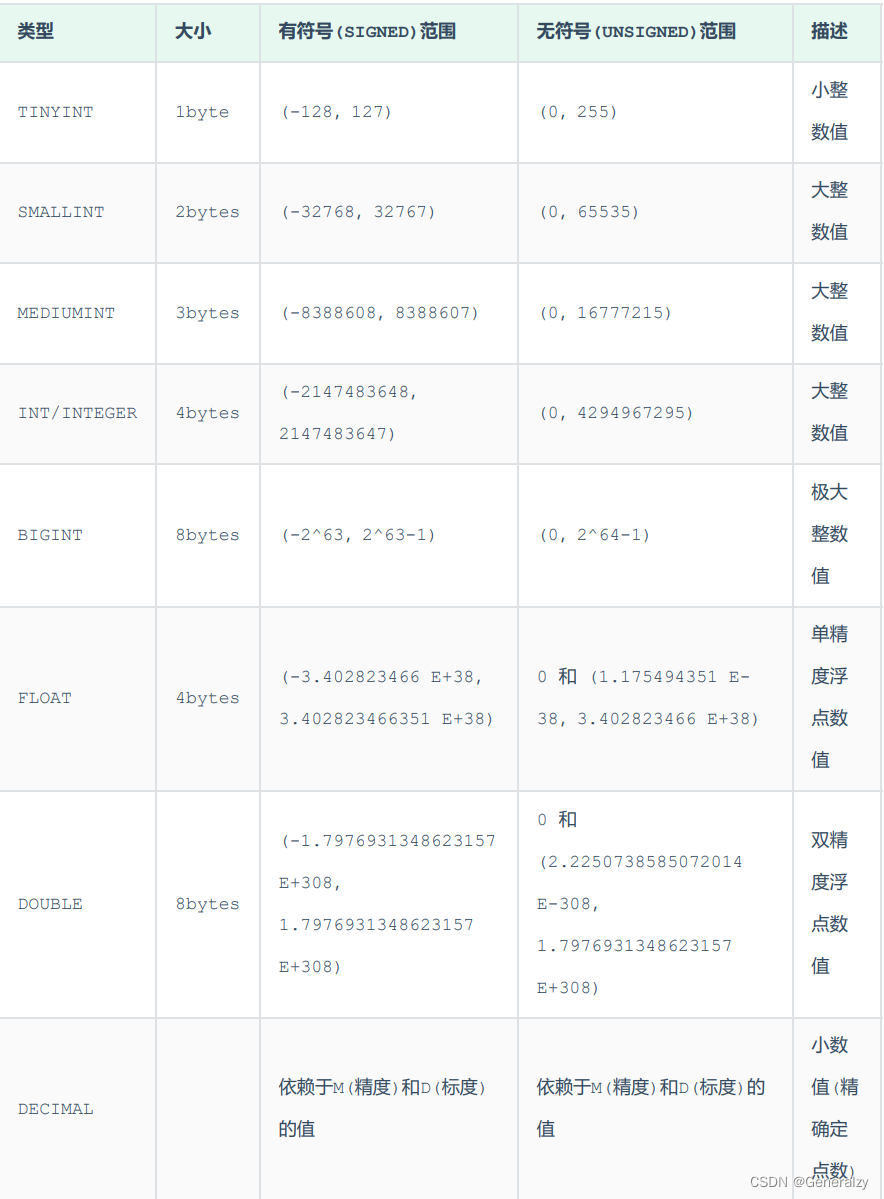
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
1). 年龄字段 -- 不会出现负数, 而且人的年龄不会太大
age tinyint unsigned
2). 分数 -- 总分100分, 最多出现一位小数
score double(4,1)
字符串类型
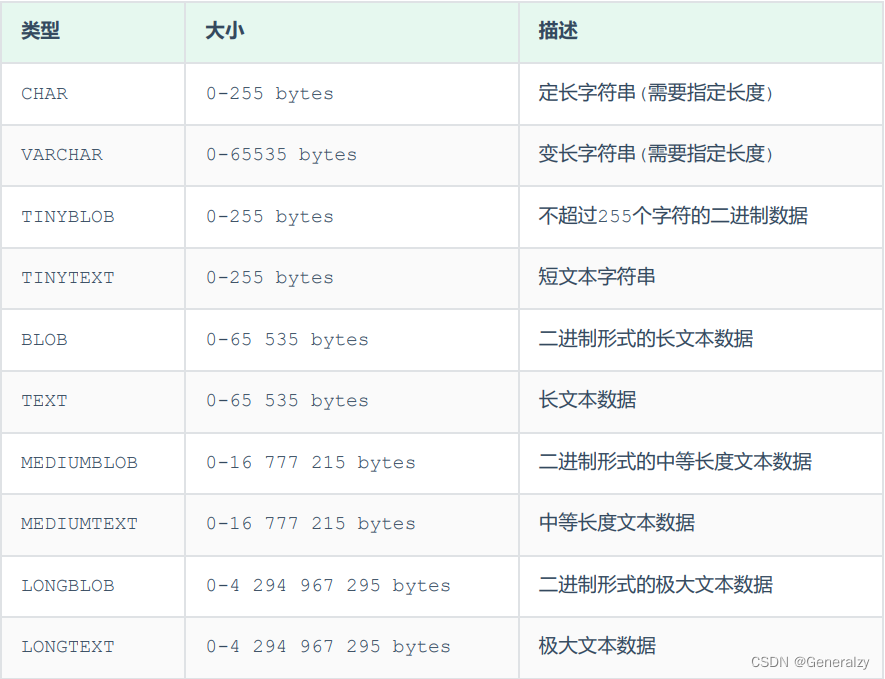
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
日期时间类型
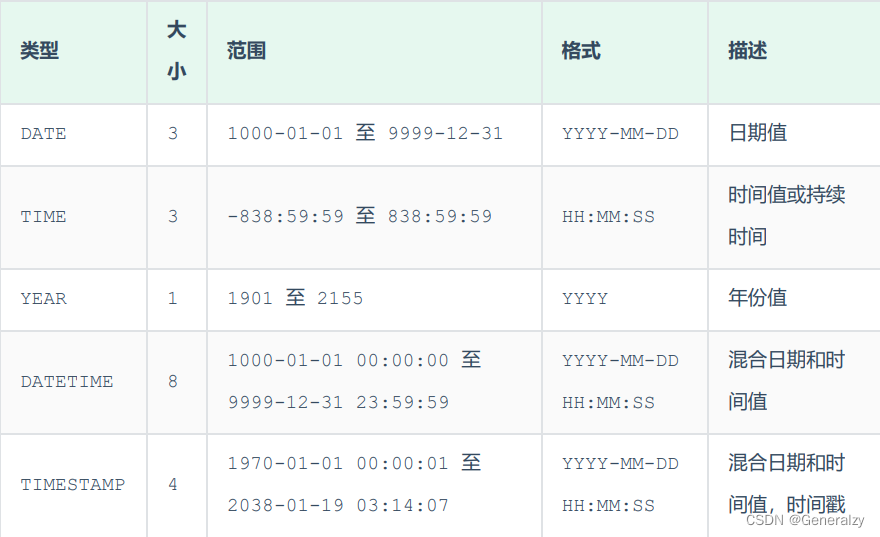
DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
添加数据
- 给指定字段添加
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
- 给全部字段添加
INSERT INTO 表名 VALUES (值1, 值2, ...);
- 批量添加数据
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值
1, 值2, ...) ;
INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...) ;
注意事项:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中。
- 插入的数据大小,应该在字段的规定范围内。
修改数据
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , .... [ WHERE 条件 ] ;
删除数据
DELETE FROM 表名 [ WHERE 条件 ] ;
注意事项:
- DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数
据。 - DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即
可)。 - 当进行删除全部数据操作时,datagrip会提示我们,询问是否确认删除,我们直接点击
Execute即可。
DQL
- DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。
- 查询关键字: SELECT
- 在一个正常的业务系统中,查询操作的频次是要远高于增删改的,而且在查询的过程中,可能还会涉及到条件、排序、分页等操作。
查询语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
- 基本查询(不带任何条件)
- 条件查询(WHERE)
- 聚合函数(count、max、min、avg、sum)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
基础查询
- 查询多个字段
SELECT 字段1, 字段2, 字段3 ... FROM 表名 ;
SELECT * FROM 表名 ;
- 字段设置别名
SELECT 字段1 [ AS 别名1 ] , 字段2 [ AS 别名2 ] ... FROM 表名; (推荐)
SELECT 字段1 [ 别名1 ] , 字段2 [ 别名2 ] ... FROM 表名;
- 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表 ;
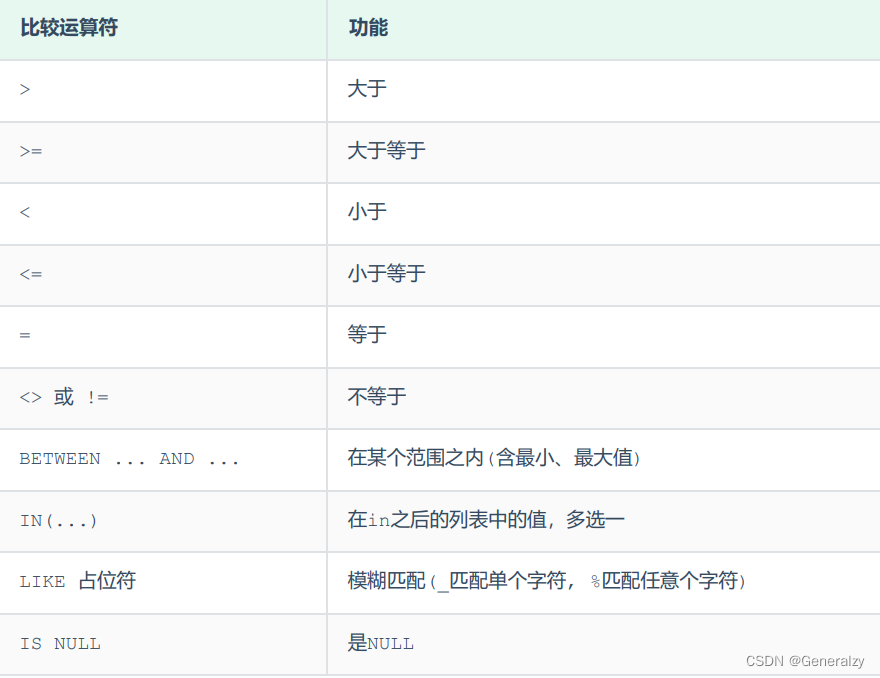
条件
常用的比较运算符如下:
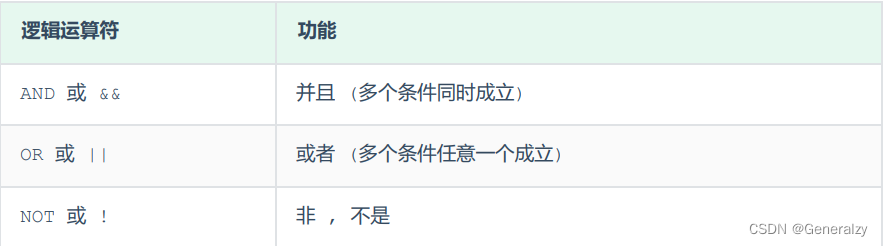
常用的逻辑运算符如下:
举例
1. 查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
select * from emp where age >= 15 && age <= 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age between 15 and 20;
2. 查询年龄等于18 或 20 或 40 的员工信息
select * from emp where age = 18 or age = 20 or age =40;
select * from emp where age in(18,20,40);
3. 查询姓名为两个字的员工信息 _ %
select * from emp where name like '__';
4. 查询身份证号最后一位是X的员工信息
select * from emp where idcard like '%X';
select * from emp where idcard like '_________________X';
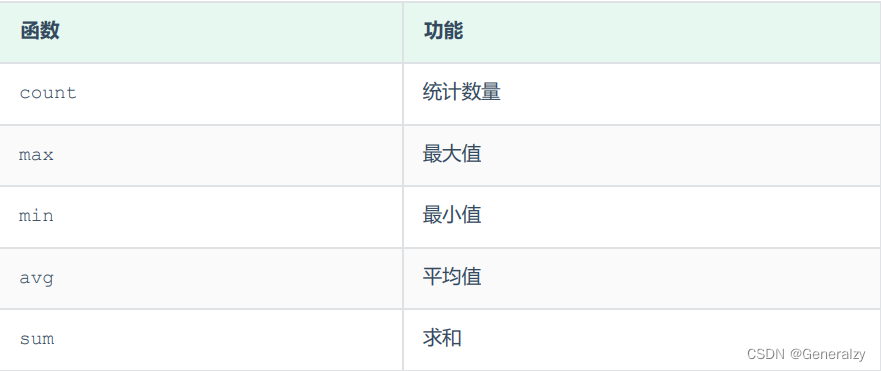
聚合函数
将一列数据作为一个整体,进行纵向计算 。
常见的聚合函数:
语法:
# NULL值是不参与所有聚合函数运算的。
SELECT 聚合函数(字段列表) FROM 表名 ;
案例:
1. 统计该企业员工数量
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数
# 对于count聚合函数,统计符合条件的总记录数,还可以通过 count(数字/字符串)的形式进行统计
查询
select count(1) from emp;
2. 统计西安地区员工的年龄平均数
select avg(age) from emp where workaddress="西安";
分组查询
语法:
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名1,分组字段名2... [ HAVING 分组
后过滤条件 ];
where与having区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组
之后对结果进行过滤。 - 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意事项:
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序: where > 聚合函数 > having 。
- 支持多字段分组, 具体语法为 : group by columnA,columnB
案例:
1. 根据性别分组 , 统计男性员工 和 女性员工的数量
select gender,count(*) as count from emp GROUP BY gender;
2. 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
select workaddress, count(*) as address_count from emp where age < 45 group by
workaddress having address_count >= 3;
3. 统计各个工作地址上班的男性及女性员工的数量
select workaddress,gender,count(*) from emp GROUP BY workaddress,gender;
排序查询
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
排序方式
- ASC : 升序(默认值)
- DESC: 降序
案例:
1. 对性别和年龄排序
select * from emp ORDER BY gender,age ASC;
分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数
注意事项:
- • 起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
- • 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- • 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
案例:
1. 查询第1页员工数据, 每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10;
2. 查询年龄为20,21,22,23岁的员工信息。
select * from emp where gender = '女' and age in(20,21,22,23);
3. 查询性别为男,且年龄在20-40 岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,
年龄相同按入职时间升序排序
select * from emp where gender = '男' and age between 20 and 40 order by age asc ,
entrydate asc limit 5 ;
执行顺序

DCL
DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。
管理用户
- 查询用户
select * from mysql.user;

其中 Host代表当前用户访问的主机, 如果为localhost, 仅代表只能够在当前本机访问,是不可以远程访问的。
User代表的是访问该数据库的用户名。在MySQL中需要通过Host和User来唯一标识一个用户。
- 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
- 修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;
- 删除用户
DROP USER '用户名'@'主机名' ;
注意事项:
- 在MySQL中需要通过用户名@主机名的方式,来唯一标识一个用户。
- 主机名可以使用 % 通配。
- 这类SQL开发人员操作的比较少,主要是DBA( Database Administrator 数据库
管理员)使用。
案例:
1. 创建用户itcast,限制为本地登录,密码为123456
create user 'itcast'@'localhost' identified by '123456';
2. 删除 itcast@localhost 用户
drop user 'itcast'@'localhost';
权限控制
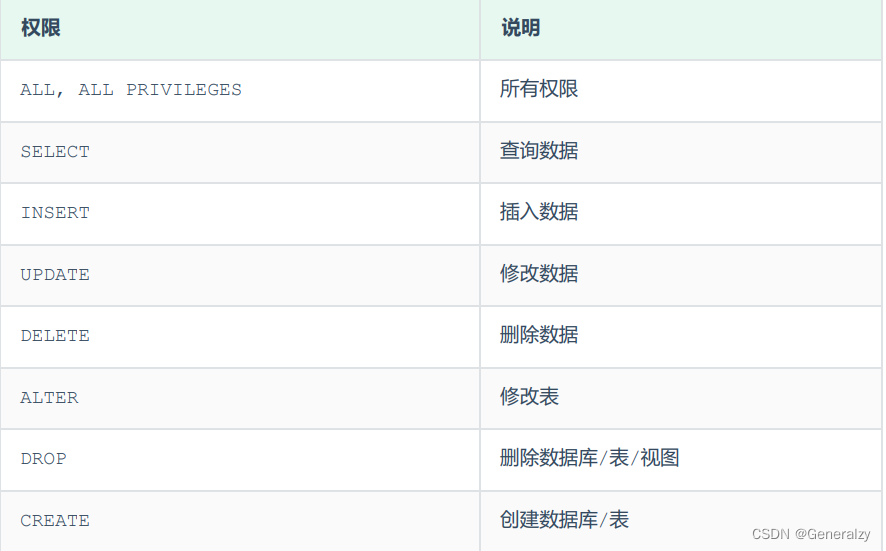
上述只是简单罗列了常见的几种权限描述,其他权限描述及含义,可以直接参考官方文档。
- 查询权限
SHOW GRANTS FOR '用户名'@'主机名' ;
- 授予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
- 撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
注意事项:
- • 多个权限之间,使用逗号分隔
- • 授权时, 数据库名和表名可以使用 * 进行通配,代表所有。
案例:
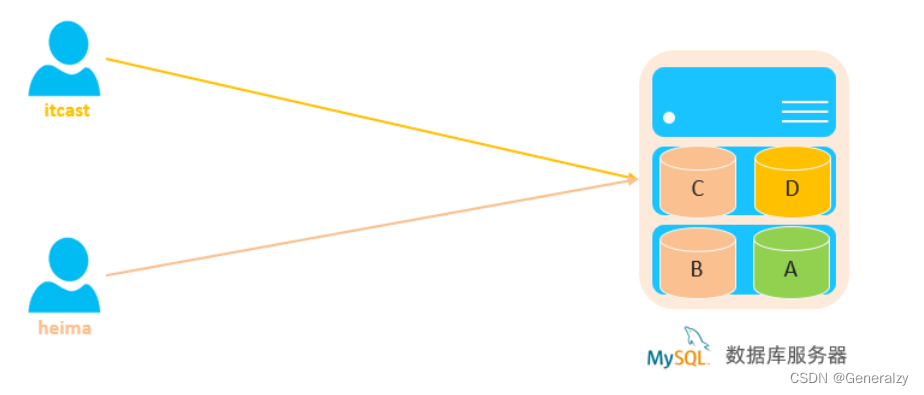
1. 授予 'heima'@'%' 用户itcast数据库所有表的所有操作权限
grant all on itcast.* to 'heima'@'%';
图形化界面工具
函数
MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。
字符串函数
MySQL中内置了很多字符串函数,常用的几个如下:
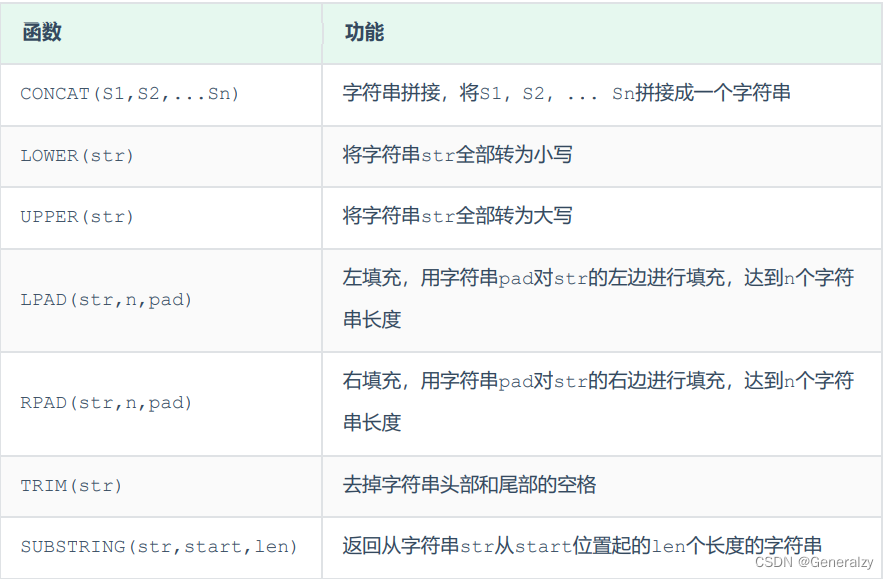
案例:
1. concat : 字符串拼接
select concat('Hello' , ' MySQL');
2. lower : 全部转小写
select lower('Hello');
3. upper :全部转大写
select UPPER(NAME) from emp;
4. 企业员工的工号,统一为5位数,目前不足5位数的全部在前面补0。
update emp set workno = lpad(workno, 5, '0');
数值函数
常见的数值函数如下:
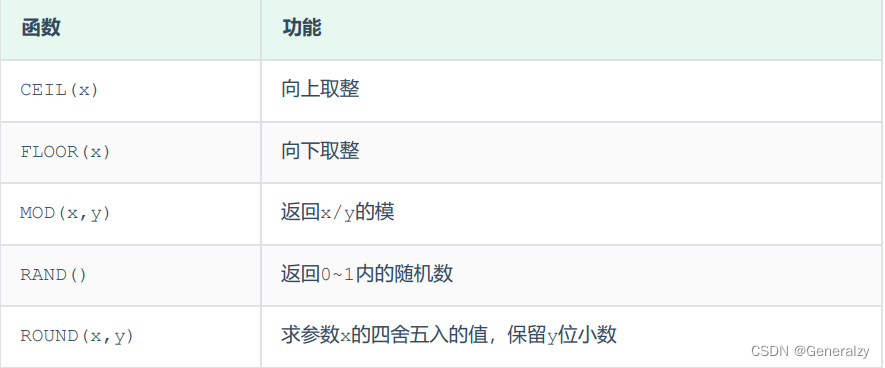
案例:
1. 生成验证码
select lpad(round(rand()*1000000 , 0), 6, '0');
日期函数
常见的日期函数如下:
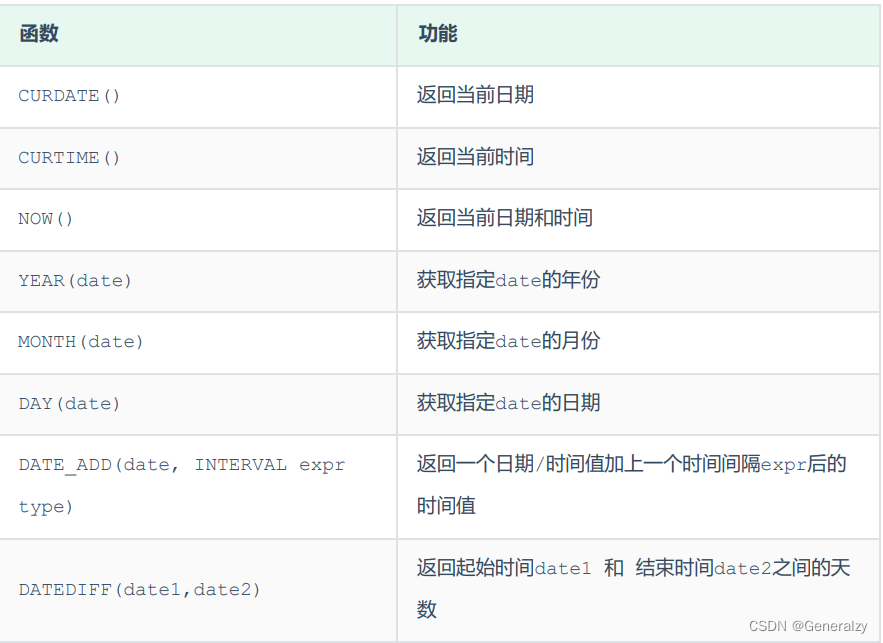
案例:
1. 查询所有员工的入职天数,并根据入职天数倒序排序。
select name, datediff(curdate(), entrydate) as 'entrydays' from emp order by entrydays desc;
流程函数
流程函数也是很常用的一类函数,可以在SQL语句中实现条件筛选,从而提高语句的效率。
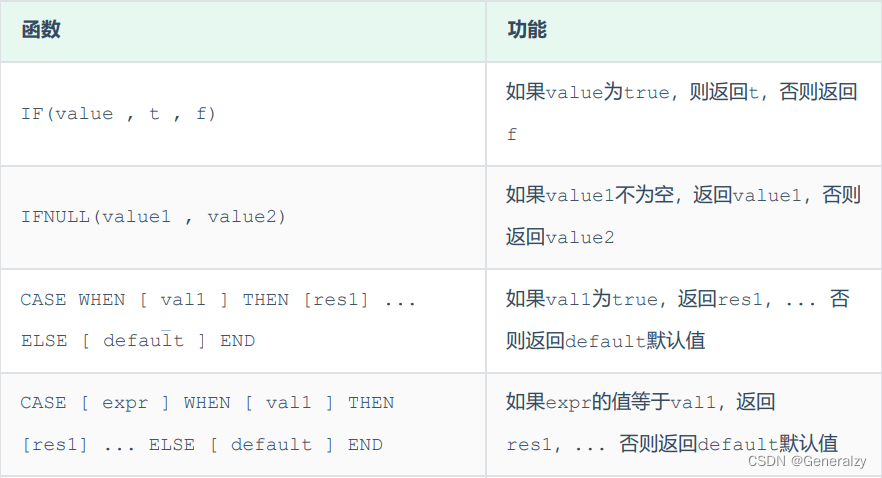
案例:
1. 查询emp表的员工姓名和工作地址 (北京/上海 ----> 一线城市 , 其他 ----> 二线城市)
select
name,
( case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end ) as '工作地址'
from emp;
约束
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确、有效性和完整性。
CREATE TABLE 表名(
字段1 字段1类型 字段1约束... [ COMMENT 字段1注释 ],
字段2 字段2类型 字段2约束... [COMMENT 字段2注释 ],
字段3 字段3类型 字段3约束... [COMMENT 字段3注释 ],
......
字段n 字段n类型 字段n约束... [COMMENT 字段n注释 ]
) ENGINE=InnoDB DEFAULT CHARSET=utf8 [ COMMENT 表注释 ] ;
分类
约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
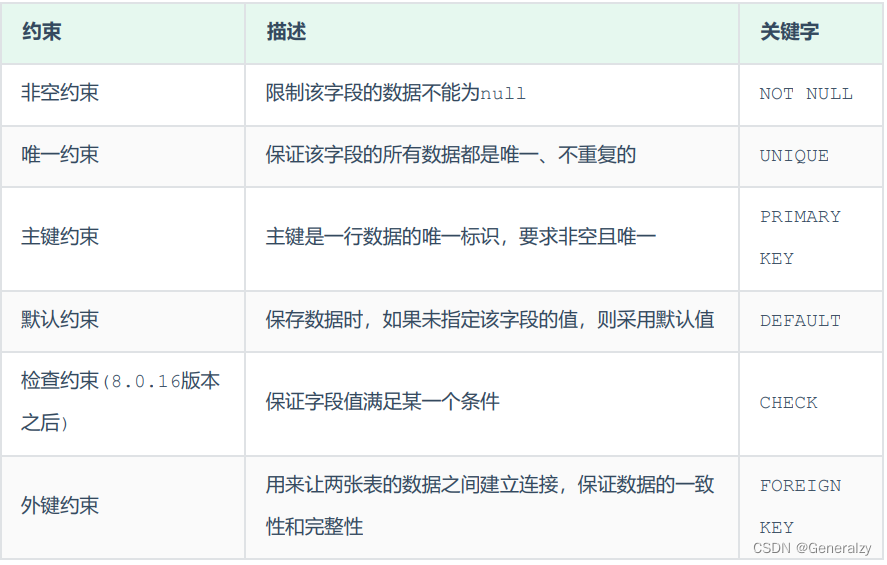
案例:
CREATE TABLE tb_user(
id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识',
name varchar(10) NOT NULL UNIQUE COMMENT '姓名' ,
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
status char(1) default '1' COMMENT '状态',
gender char(1) COMMENT '性别'
);
外键约束
外键:用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
语法:
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名)
);
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
案例:
1. 为emp表的dept_id字段添加外键约束,关联dept表的主键id。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
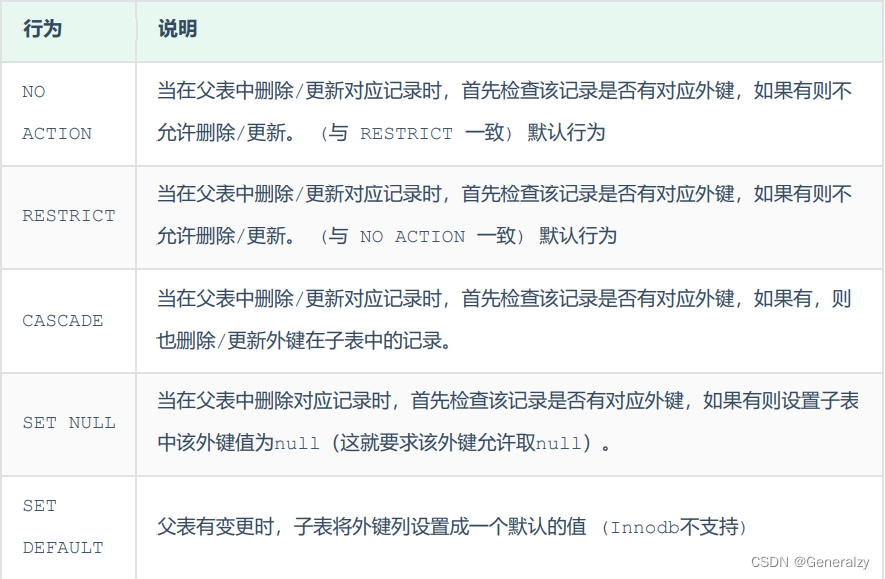
删除/更新行为
添加了外键之后,再删除父表数据时产生的约束行为,称为删除/更新行为。具体的删除/更新行
为有以下几种:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
案例:
1. 将外键关联fk_emp_dept_id的行为改为CASCADE
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
多表查询
多表关系
基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一:GORM又将1对1分为了
has one和belong to
一对多
- 一个部门有多个员工,一个班级有多个学生。
- 在多的一方建立外键,指向一的一方的主键
constraint fk_userid foreign key (userid) references tb_class(id)
多对多
- 一个学生有多个课程,一个课程有多个学生。
- 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
create table student_course(
id int auto_increment comment '主键' primary key,
studentid int not null comment '学生ID',
courseid int not null comment '课程ID',
constraint fk_courseid foreign key (courseid) references course (id),
constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
一对一
- 一个学生只有一个学生详情
- 在任意一方加入外键(这样就会产生
belongto和hasone),关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
constraint fk_userid foreign key (userid) references tb_user(id)
查询分类
- 连接查询
- 内连接:相当于查询A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
- 子查询
内连接

SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ; (推荐)
外连接
左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
自连接
SELECT 字段列表 FROM 表A 别名A [INNER] JOIN 表A 别名B ON 条件 ... ;
联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A ...
UNION [ ALL ]
SELECT 字段列表 FROM 表B ....;
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all会将全部的数据直接合并在一起,union会对合并之后的数据去重。
案例:
1. 将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
select * from emp where salary < 5000
union all
select * from emp where age > 50;
# union all查询出来的结果,仅仅进行简单的合并,并未去重。
# 使用union去重
select * from emp where salary < 5000
union
select * from emp where age > 50;
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报
错。
子查询
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
根据子查询结果不同,分为:
- A. 标量子查询(子查询结果为单个值)
- B. 列子查询(子查询结果为一列)
- C. 行子查询(子查询结果为一行)
- D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
- A. WHERE之后
- B. FROM之后
- C. SELECT之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= <> > >= < <=
案例:
1. 查询 "销售部" 的所有员工信息
1.1 查询 "销售部" 部门ID
select id from dept where name = '销售部';
1.2 根据 "销售部" 部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');
等效于:
select emp.* from emp LEFT JOIN dept on emp.dept_id = dept.id WHERE dept.`name` ="销售部";
列子查询
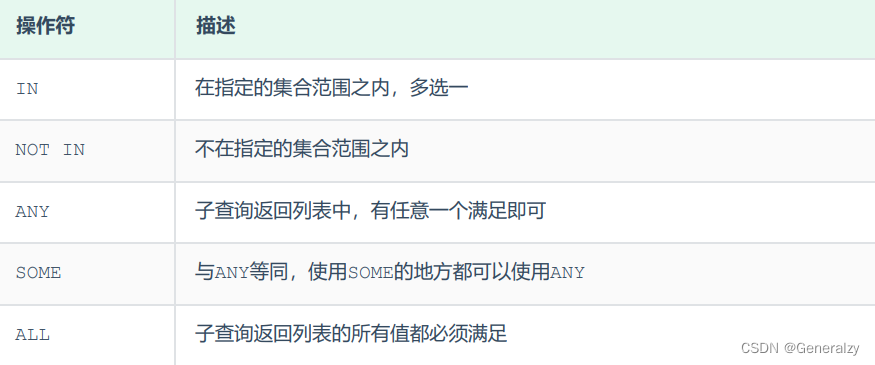
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
案例:
1. 查询 "销售部" 和 "市场部" 的所有员工信息
1.1 查询 "销售部" 和 "市场部" 的部门ID
select id from dept where name = '销售部' or name = '市场部';
1.2 根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or
name = '市场部');
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
1. 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
1.1 查询 "张无忌" 的薪资及直属领导
select salary, managerid from emp where name = '张无忌';
1.2 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp
where name = '张无忌');
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
1. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
1.1 查询 "鹿杖客" , "宋远桥" 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
1.2 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name =
'鹿杖客' or name = '宋远桥' );
小结
SQL写法也有很多,只要能满足我们的需求,查询出符合条件的记录即可。
事务
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务操作
控制事务一
- 查看/设置事务提交方式
SELECT @@autocommit ;
# 取消自动提交
SET @@autocommit = 0 ;
- 提交,回滚事务
COMMIT;
ROLLBACK;
控制事务二
- 开启事务
START TRANSACTION 或 BEGIN ;
- 提交,回滚事务
COMMIT;
ROLLBACK;
案例:
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;
事务四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立
环境下运行。 - 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务问题
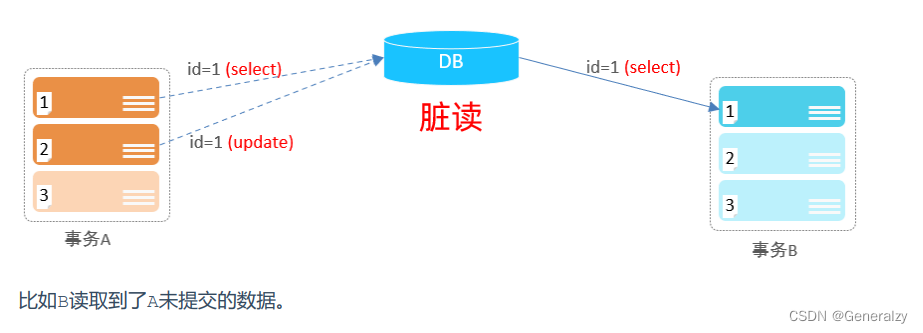
- 脏读:一个事务读到另外一个事务还没有提交的数据。
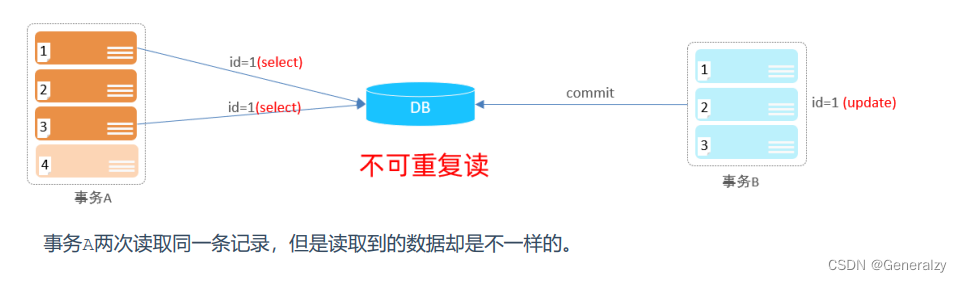
- 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
- 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据
已经存在,好像出现了 “幻影”。
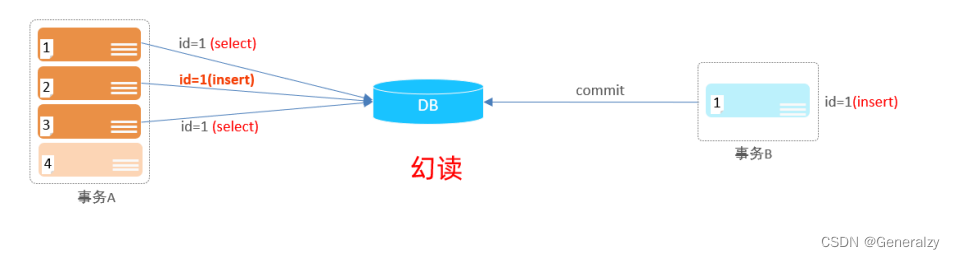
事务隔离级别
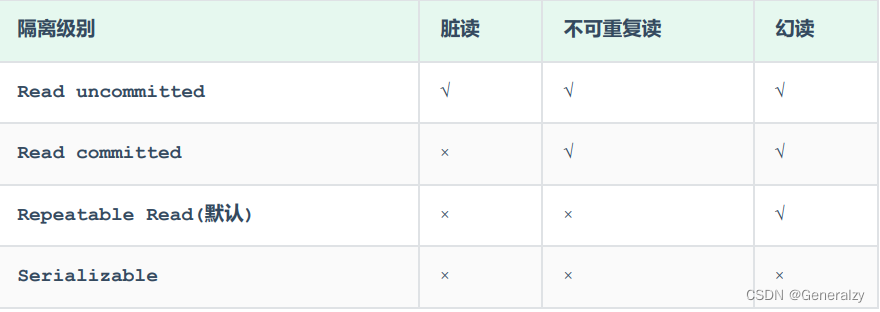
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。主要有以下几种:
- 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
- 设置事务隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }
事务隔离级别越高,数据越安全,但是性能越低。