本节目录
- 1.如何理解区域划分
- 2.为什么一个变量可以存储两个不同的值?
- 3.深入理解虚拟地址空间
- 为什么要有地址空间?
- 4.理解什么是挂起?
1.虚拟地址空间究竟是什么?
2.映射关系的维护是谁做的?
1.如何理解区域划分
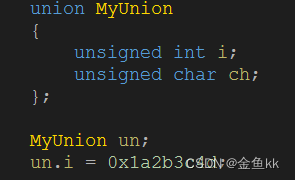
所谓的区域划分,本质是在一个范围里定义start和end。
struct destop
{
int start;
int end;
};
struct destop one = { 1, 50 };
struct destop two = { 51, 100 };
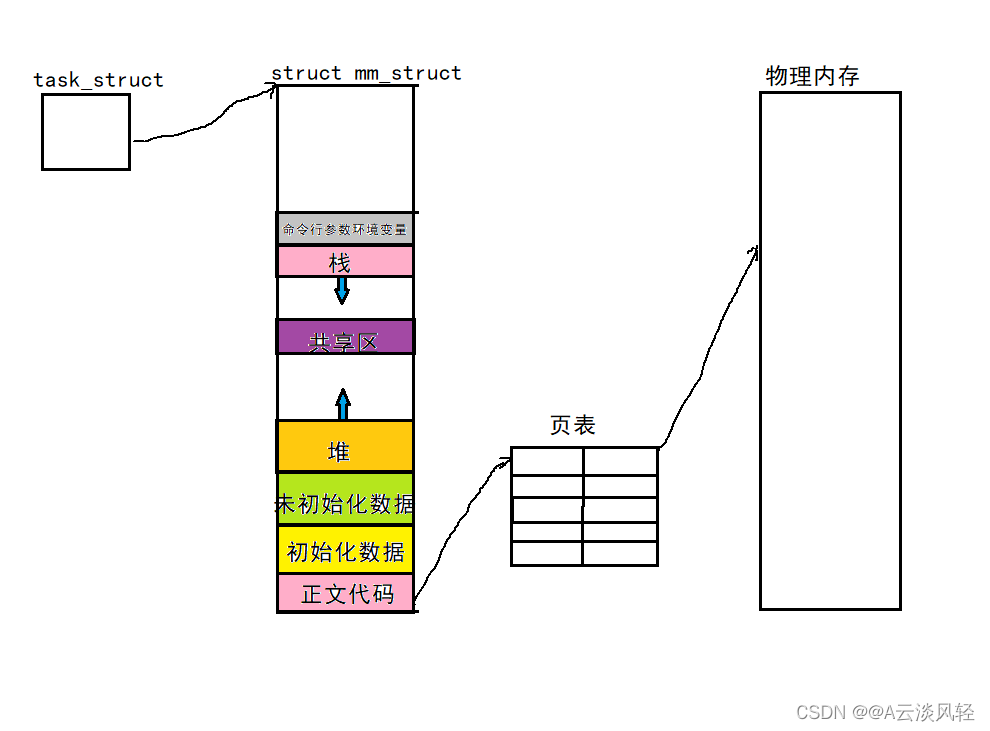
虚拟地址空间是一种内核数据结构,它里面至少要有对各个区域的划分。
struct addr_room
{
int code_start;
int code_end;
int init_start;
int init_end;
int uninit_start;
int uninit_end;
int heap_start;
int heap_end;
int stack_start;
int stack_end;
//... 其他的属性
};
地址空间和页表(用户级)是每个进程都私有一份。(页表是一种数据结构,它内部有映射关系,也有权限的管理,+MMU)
只要保证每一个进程的页表映射的是物理内存的不同区域,就能做到进程之间不会互相干扰,进而保证进程的独立性。
2.为什么一个变量可以存储两个不同的值?
首先我们观察下面一段代码:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int g_val = 0;
6 int main()
7 {
8 pid_t id = fork();
9 if(id <0)
10 {
11 perror("fork");
12 return 0;
13 }
14 else if(id == 0)
15 {
16 printf("child[%d]:%d,%p\n",getpid(),g_val,&g_val);
17 }
18 else
19 {
20 printf("parent[%d]:%d,%p\n",getpid(),g_val,&g_val);
21 }
22 return 0;
23 }
运行结果:
[jyf@VM-12-14-centos lesson9]$ ./a.out
parent[4479]:0,0x601050
child[4480]:0,0x601050
我们发现变量值和变量地址是一模一样的,很好理解呀,因为子进程是以父进程为模板,父进程并没有对变量值做任何修改。
我们在将代码进行修改:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int g_val = 0;
6 int main()
7 {
8 pid_t id = fork();
9 if(id <0)
10 {
11 perror("fork");
12 return 0;
13 }
14 else if(id == 0)
15 { //子进程肯定先跑完,也就是子进程先修改,完成之后,父进程在读取
16 g_val = 100;
17 printf("child[%d]:%d,%p\n",getpid(),g_val,&g_val);
18 }
19 else //parent
20 {
21 sleep(3);
22 printf("parent[%d]:%d,%p\n",getpid(),g_val,&g_val);
23 }
24 sleep(1);
25 return 0;
26 }
运行结果:
[jyf@VM-12-14-centos lesson9]$ ./a.out
child[6691]:100,0x601058
parent[6690]:0,0x601058
我们发现父子进程,输出的变量地址是一样的,但变量的值不同。
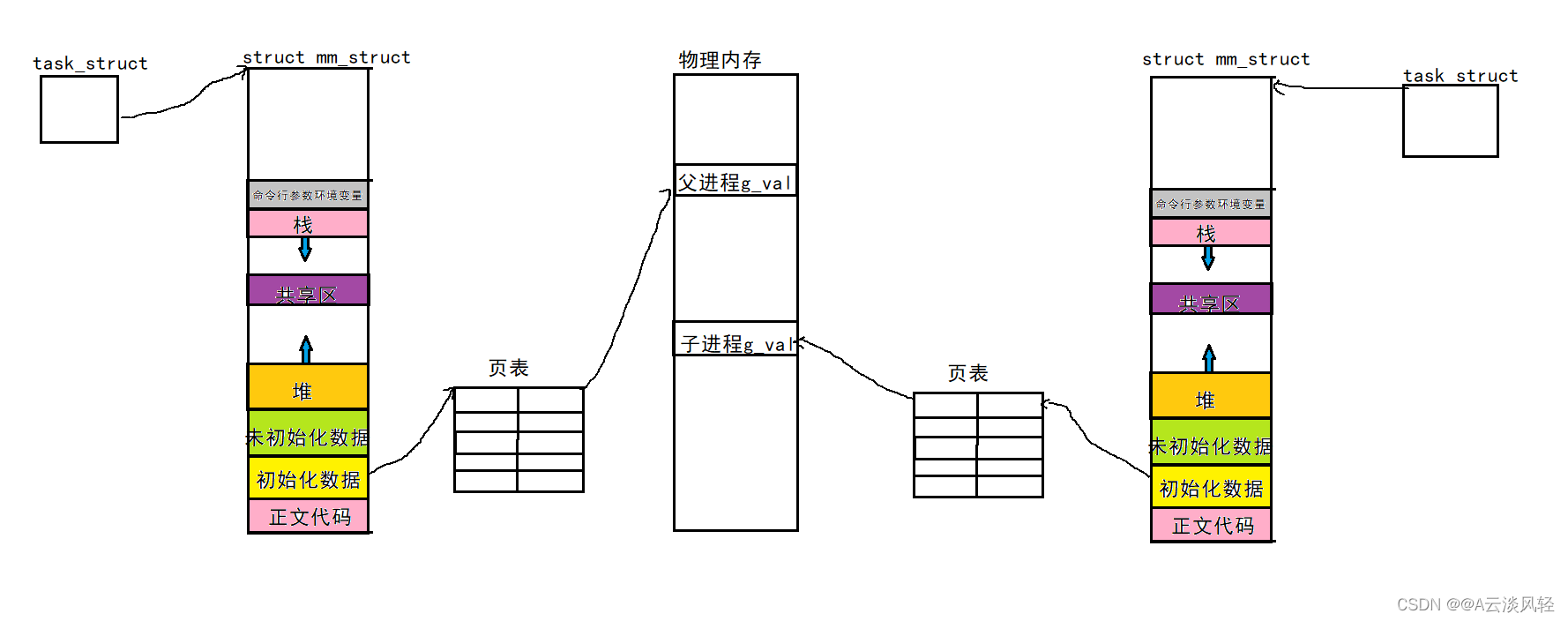
一个变量可以存储两个不同的值吗?答案是否定的。输出的变量值不同说明它们绝对不是同一个变量,但输出的地址相同,说明它们不是物理地址,在Linux环境下,它叫做虚拟地址,我们在C/C++下,看到的都是虚拟地址,物理地址用户一概看不到,由OS统一管理,将虚拟地址映射成物理地址。进程地址空间是一种内核的数据结构,每一个进程都私有一份进程地址空间和页表,只要保证进程虚拟地址通过页表映射的是物理内存的不同区域,就能做到进程之间不会互相干扰,保证进程的独立性。所以父子进程的g_val的虚拟地址是一样的,当子进程修改g_val的值,通过页表映射到物理内存的不同区域,就出现了类似一个变量内存储两个不同的值的现象。
如此pid_t id = fork(); 中的id值为什么可以有两个返回值相信大家都能理解了。
3.深入理解虚拟地址空间
一些Linux指令:readelf -s 可执行文件, 用于查看可执行程序中的符号表。
objdump -f 可执行文件,用于查看可执行程序中文件头相关信息,一个反汇编工具。
[jyf@VM-12-14-centos lesson9]$ objdump -f a.out
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x0000000000400560
当我们的程序通过编译形成可执行程序的时候,,还没有加载到内存的时候,请问我们程序的内部有地址吗?
可执行程序在编译的时候,内部其实就已经有地址了。
地址空间不要仅仅理解为OS要遵守的,编译器也要遵守。即编译器在编译代码的时候,就已经给我们形成了各个区域,代码区,数据区等等,并且,采用Linux一样的编制方式,给每一个变量,每一个代码都进行了编址,故,程序在编译的时候,每一个字段早已经具有了一个虚拟地址!!!
程序内部的地址,依旧用的是编译器编译好的虚拟地址,当程序加载到内存的时候,每行代码,每个变量便具有了一个外部的物理地址。
所以CPU读取到指令的时候,指令内部的地址是虚拟地址。可见,每一个变量,每一个函数都有地址,编译器给的,同样它们也一定被加载到物理内存中。
为什么要有地址空间?
1.凡是非法访问或者映射,OS都会识别到,并终止这个进程。这样可以做到有效保护内存。
我们知道地址空间和页表都是OS创建并维护的,是不是就意味着凡是使用地址空间和页表进行映射,也一定要在OS的监管之下进行访问,也便保护了物理内存中的所有合法数据,包括各个进程,以及内核的相关有效数据。
2.因为有地址空间和页表的存在,是不是我们的物理内存可以对未来的数据进行任意位置的加载?
当然可以。
这样物理内存的分配和进程的管理就可以做到没有关系,这样内存管理模块和进程管理模块就完成了解耦合。
从这我们可知,空间配置器配置的地址是虚拟地址,我们在C/C++中new/malloc申请空间的时候,本质是在虚拟地址空间进行申请。
如果我申请了物理空间,但我不立马使用,是不是空间的浪费呢?是的。
本质上,因为地址空间的存在,所以上层申请空间,其实是在地址空间上进行申请,物理内存甚至一个字节都不给你!!!而当你真正进行物理地址空间的访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(是由OS自动帮你完成的,用户包括进程完全0感知),然后在让你进行内存的访问。这种延迟分配的策略,来提高整机的效率,几乎内存的有效使用是100%的。这也就是**缺页中断技术。**也就是说,你申请空间,系统已经给你分配了虚拟地址空间,但还没有给你分配物理地址,这种技术叫做缺页中断技术。
3.因为在物理内存上,理论可以任意位置加载,所以物理内存中几乎所有数据和代码都是乱序的。
但是,因为页表的存在,它可以将页表中的虚拟地址和物理地址进行映射,那么可见在进程的视角下,所有的内存分布,都可以是有序的。
地址空间加页表的存在可以将内存分布有序化。
地址空间是操作系统给进程画的大饼。进程要访问物理内存中的数据和代码,可能此时并不在物理内存中。同样的也可以让不同的进程映射不同的物理内存区域,是不是很容易做到,进程独立性的实现。(进程的独立性可以通过地址空间+页表实现)
因为地址空间的存在,每一个进程都认为自己拥有4GB(32)空间,并且各个区域都是有序的,进而可以通过页表映射到物理内存不同区域,来实现进程的独立性。每一个进程都不知道,也不需要知道其他进程的存在。
4.理解什么是挂起?
我们将我们的代码和数据加载到内存中,加载本质是创建进程,那么是不是非得立马把所有的程序的代码和数据加载到内存中,并创建内核数据结构和建立相关映射关系?答案是否定的。
在最极端的情况下,甚至只有内核结构(task_struct结构体、地址空间、页表,)被创建出来了,映射关系一个都没有。
此时进程的状态就叫做新建状态。当真正调度这个进程的时候,才将进程的代码和数据加载到内存中,设置好映射关系。
理论上,可以实现对进程的分批加载,那是不是可以分批换出呢?当然可以。甚至,这个进程短时间内不会被执行,比如正在等待某种非CPU资源,阻塞了,进程的代码和数据被换出,此时的状态叫做挂起!!!
我们知道页表映射的时候,可不仅仅是内存,磁盘中的位置也是可以映射的嗷,所以在执行换出操作时,不一定需要将内存中数据刷新到磁盘中,可以直接释放掉,只需要将页表的映射关系中的位置改到磁盘中对应的数据位置即可。
今天就到这里吧,我们下次再见!