目录
前言:
哈希表介绍
哈希冲突
闭散列
开散列(哈希桶)
模拟实现哈希桶中插入和获取方法
代码实现
HashMap介绍
手撕源码
HashSet介绍
手撕源码
小结:
前言:
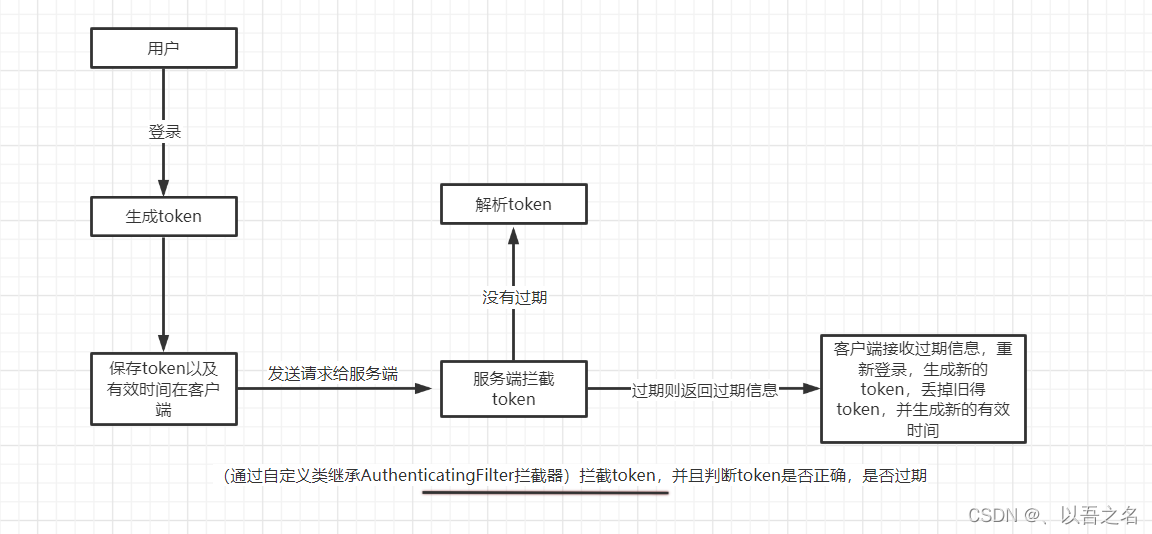
🎈一棵搜索树的最快查找数据的时间复杂度是O(logN),虽然这个速度已经是相当快了。但是又提出了,查找数据时间复杂度为O(1)的数据结构。意味着我们要找哪个数据,直接就知道这个数据在哪一块,它就是哈希表。
哈希表介绍
🪖哈希表的存储方式类似于我们之前学过的计数排序。每个数据会有自己相对应的哈希值,根据这个哈希值通过哈希函数计算其下标,存储到数组相应的位置。那么我们要找数据,只需通过哈希函数计算其下标就可在O(1)的时间复杂度内找到。
注意:如果不同的数据通过哈希函数计算到了同一个下标怎么办?
哈希冲突
🤞不同的数据通过哈希函数计算到了同一个下标,这样的情况被称为哈希冲突。解决哈希冲突常见的是用闭散列和开散列的方法。
🤞首先介绍下,负载调节因子。
= 填入数据个数 / 数组长度。
越大冲突率就会越大,一般控制在0.7 - 0.8之间,在Java中规定不能超过0.75。如果在插入数据时
超过了限定值,我们就会去减小它。由于填入数据个数是不变的,所以会考虑增加数组的长度。那么这个情况下相同的值就会被哈希到不同的位置,所以就需要将原有的数据重新哈希。只能降低冲突率不能完全避免它。

闭散列
🎈闭散列有两种方法,线性探测和二次探测。线性探测就是如果出现的哈希冲突,会在这个位置往下找到空位置,去存放这个元素。那么在删除的时候需要标记,不然会找不到其他冲突的数据。并且它会把冲突的数据集中在一块。
🎈二次探测是考虑线性探测会将冲突数据集中在一块。采用二次函数的方式找下一个空位置,Hi = (H0 + i^2)% m 或者 Hi = (H0 - i^2)% m。H0就是通过哈希函数计算的下标,i就是1,2,3,m是数组长度。这样会有效的避免冲突数据集中在一块,但同时也造成了空间浪费。
开散列(哈希桶)
😄开散列也叫做链地址法,用一个数组存储链表的头节点,每一个链表就是一个桶。如果一个数据通过哈希函数计算其下标产生了冲突,Java8之前是采用头插法插入到相应的链表中,Java8之后采用的是尾插法。如果链表长度超过8且数组长度大于64,会将其变为一颗搜索树。
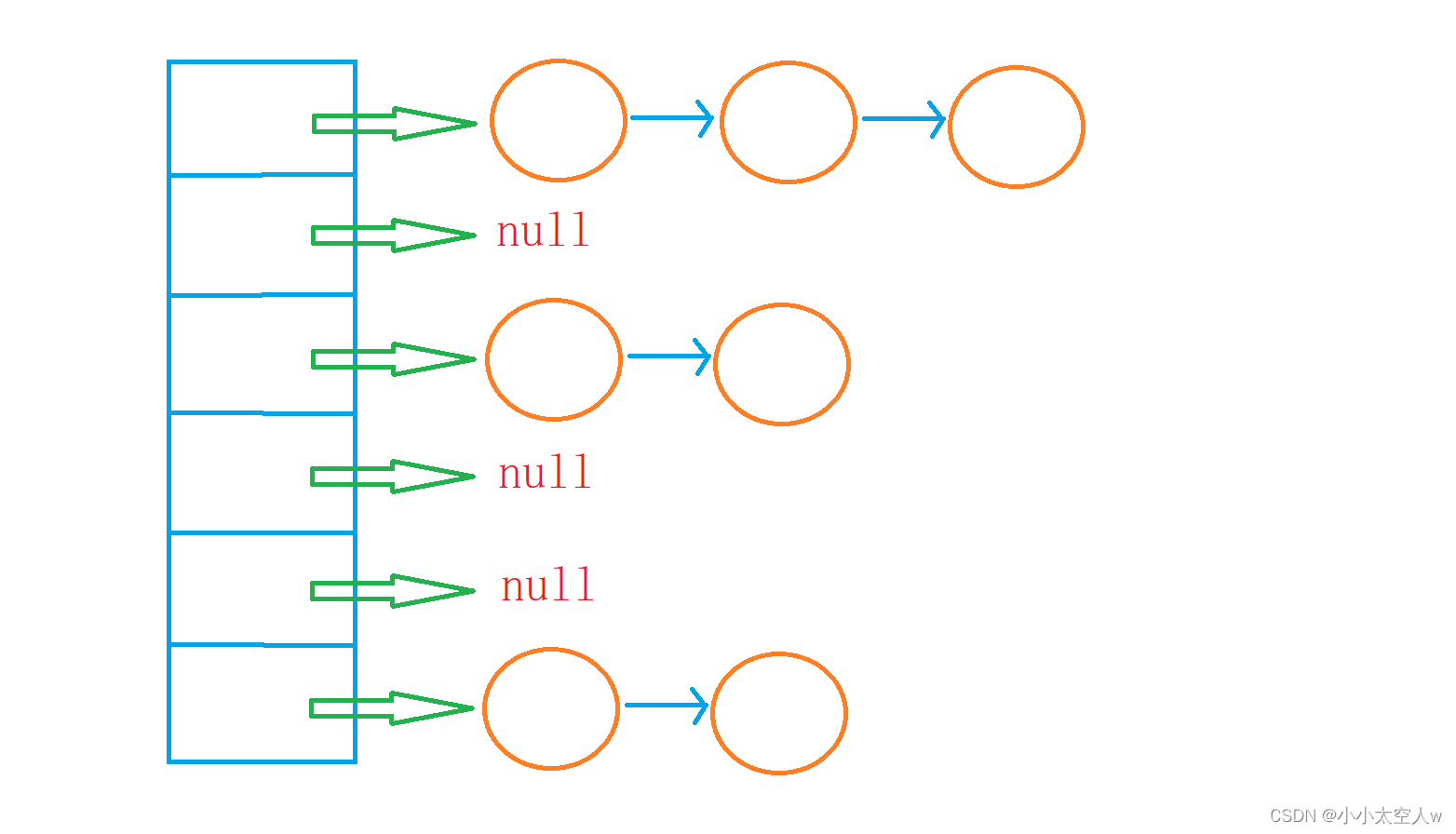
模拟实现哈希桶中插入和获取方法
😣哈希桶中不能有重复的数据,如果插入了重复数据会更新其原来的val值。负载调节因子不能超过0.75,因此需在插入时检查
。如果超过则需增加数组长度,但是相同的数据就会被哈希到不同的位置,因此扩容后需将原来的数据全部哈希到这个新的空间上来,然后再交给原来的指针去维护。
😣查找其中的key,只需通过哈希函数计算其下标,遍历其后面的链表或者树。
代码实现
public class MyHashList {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.val = val;
this.key = key;
}
}
private static final int DEFAULTSIZE = 10;
private Node[] arr;
private int size;
public MyHashList() {
arr = new Node[DEFAULTSIZE];
this.size = 0;
}
//扩容后,数组长度会改变,原来的值需重新Hash
private void addCapicity() {
Node[] tmp = new Node[arr.length * 2];
for(int i = 0; i < this.arr.length; i++) {
Node cur = arr[i];
//直接将cur拿起,插入到新位置
while(cur != null) {
Node curNext = cur.next;
int index = cur.key % tmp.length;
//头插法
cur.next = tmp[index];
tmp[index] = cur;
cur = curNext;
}
}
this.arr = tmp;
}
public int put(int key, int val) {
//遍历哈希表如果有相同key则替换其val
for(int i = 0; i < this.arr.length; i++) {
Node cur = arr[i];
while(cur != null) {
if(cur.key == key) {
cur.val = val;
return val;
}
cur = cur.next;
}
}
//采用头插法
//哈希值通过哈希函数计算其下表
int index = key % arr.length;
Node newNode = new Node(key, val);
newNode.next = this.arr[index];
this.arr[index] = newNode;
this.size++;
//负载因子大于0.75,冲突率会大,需扩容
float ret = size * 1.0f / arr.length;
if(ret >= 0.75) {
addCapicity();
}
return val;
}
public int get(int key) {
//对象,会有自己对应的哈希码
//根据哈希码可计算出对应的哈希值
int index = key % arr.length;
Node cur = arr[index];
while(cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;
}
public int size() {
return this.size;
}
}HashMap介绍
⚽HashMap底层就是哈希桶,它查找数据的时间复杂度为O(1)。数据存储是按照(key - val)键值对的方式去存储。HashMap是实现Map接口的,相对于Iterable是独立的。遍历其中的元素,需调用entrySet方法,将其(key - val)转换成Entry类型存储到set集合中,利用foreach遍历。也可以单独获取其中的key和val。
⚽通过HashMap对象调用keySet或者values方法,将key或者val分别利用Set集合或者Collection集合组织起来。如果在其中插入相同的数据会更新其原来的val值,那么相应的key值是不可以修改的。
⚽由于底层是哈希桶的结构,它其中的对象可以不具有比较性,因此可以入null。但是自定义类型需重写Objiect中equals和hashCode方法。
手撕源码
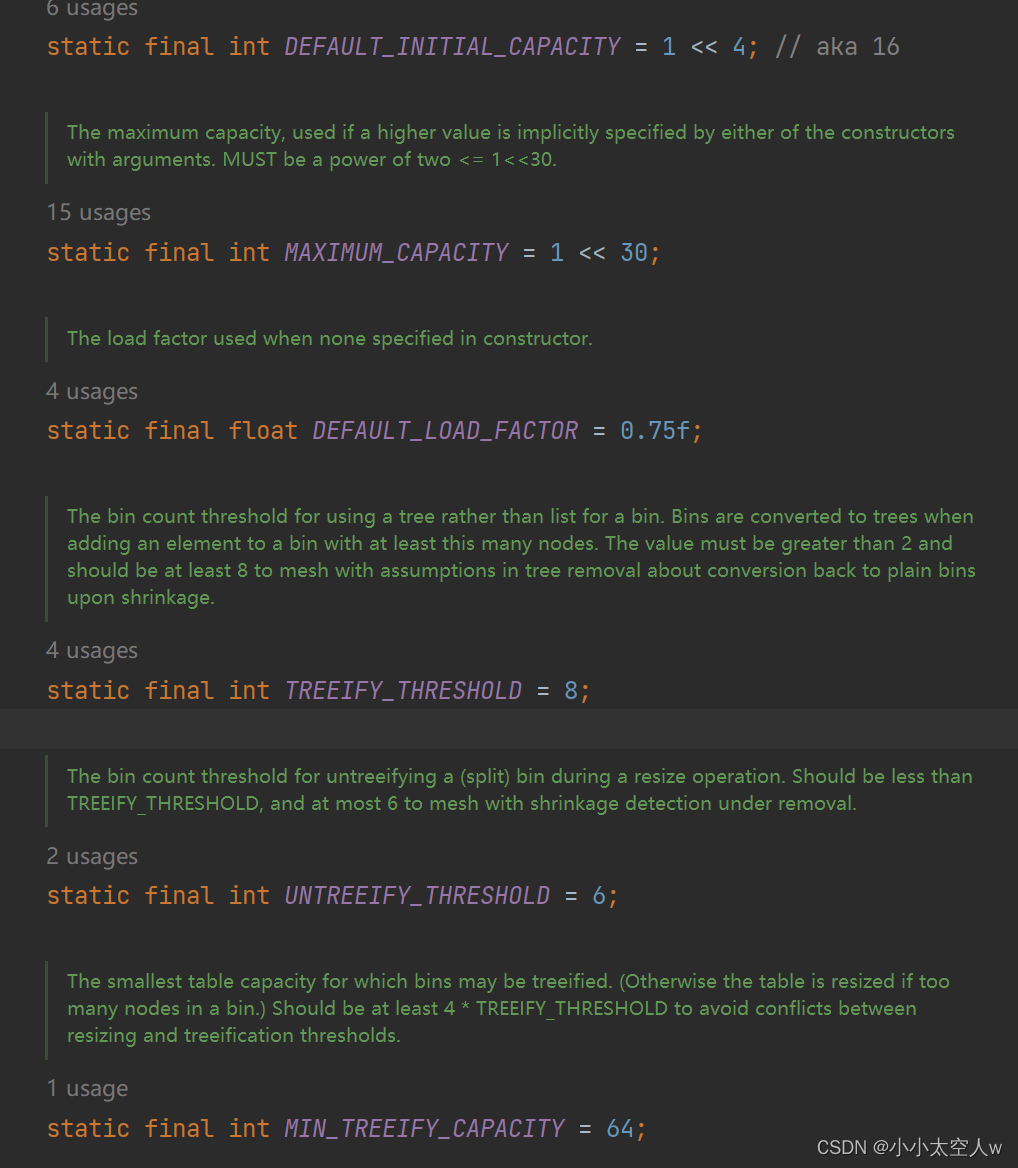
依次是:哈希表的默认容量,最大容量,负载调节因子,链表长度(链表树化条件),解树化条件,数组大小(链表树化条件)。
注意:树化条件是链表长度大于8且数组长度大于64。


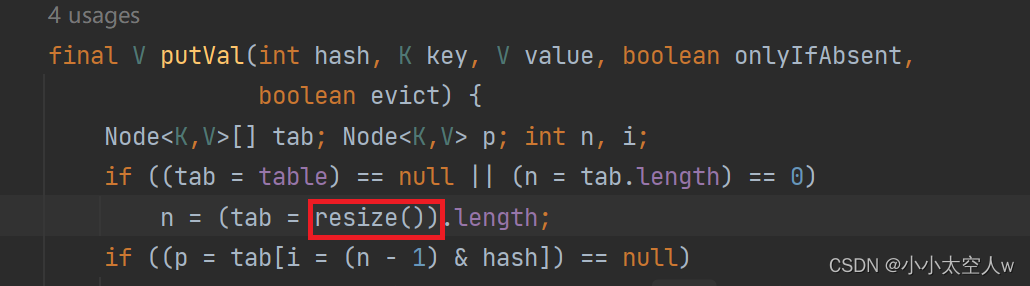
 注意:可以看见当调用无参构造方法时,并没有为数组开辟空间,而是在第一次put时为数组开辟默认的容量16。
注意:可以看见当调用无参构造方法时,并没有为数组开辟空间,而是在第一次put时为数组开辟默认的容量16。


 注意:可以看见当我们指定哈希表容量后,它会计算调整比指定容量大,且最接近的二的指数。
注意:可以看见当我们指定哈希表容量后,它会计算调整比指定容量大,且最接近的二的指数。

注意:当实例化对象不具有比较性的时候,会根据其哈希值进行比较来建树。


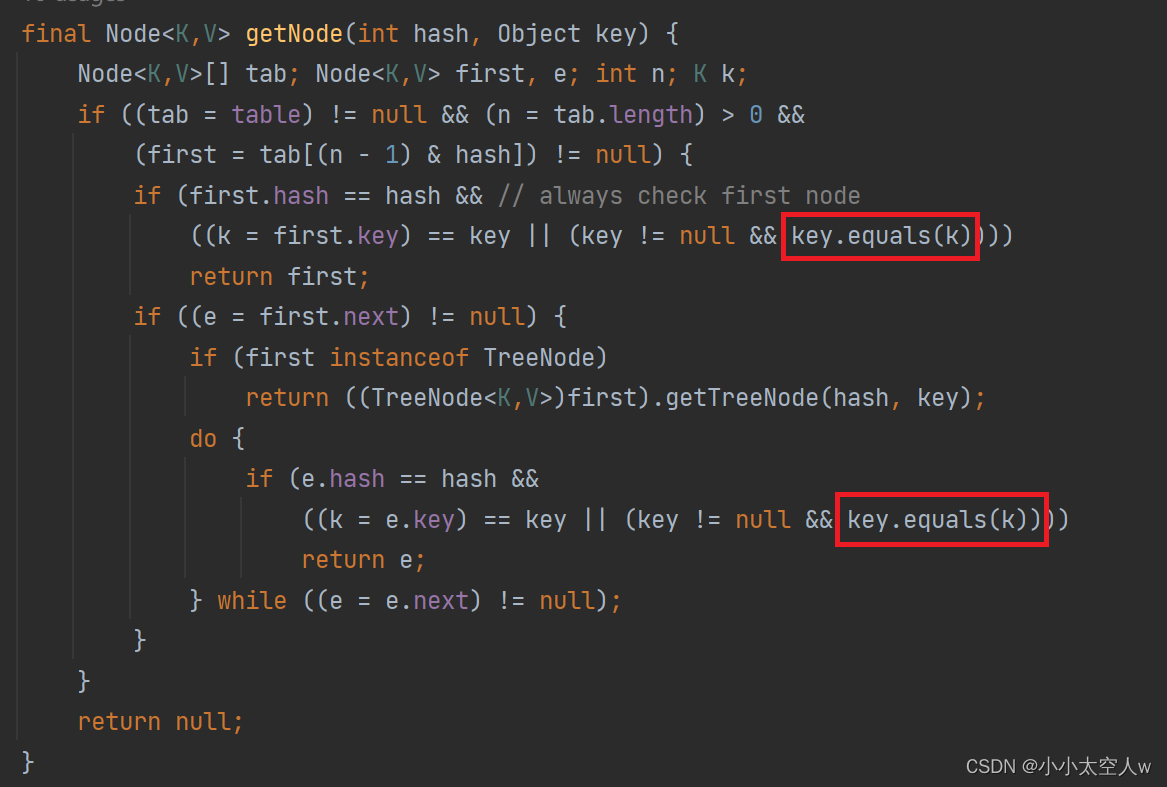 注意:我们在传key的时候,需重写Object类下equals和hashCode方法,不然就会调用Object的equals和hashCode方法。
注意:我们在传key的时候,需重写Object类下equals和hashCode方法,不然就会调用Object的equals和hashCode方法。
HashSet介绍
🎉HashSet底层是用HashMap实现的,那么相应的底层也是哈希桶。它只存储key,其中的val都是Object对象。
🎉HashSet是实现set接口的,在Iterable下。因此可以直接利用foreach遍历。其数据不能重复,key值不可以修改,自定义类型需重写equals和hashCode方法,具有去重功能。
手撕源码
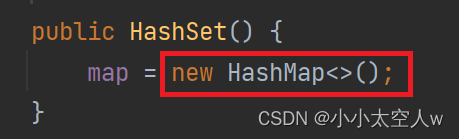

 注意:HashSet的三个构造方法都是实例化HashMap对象的。
注意:HashSet的三个构造方法都是实例化HashMap对象的。

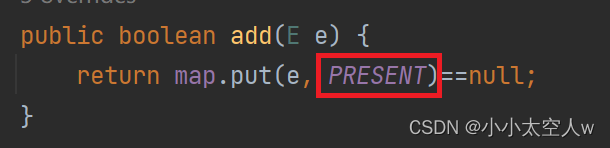
注意:它的val值都是Object对象。
小结:
🐵我们在理解原理的同时,去查看源码,会增加我们对其的理解性。