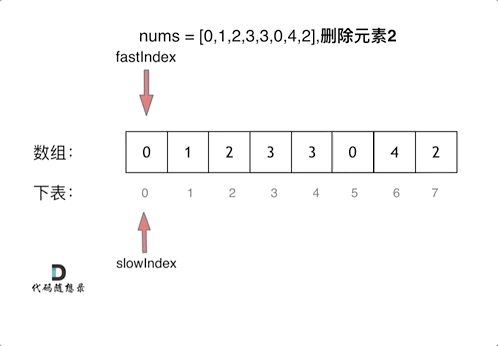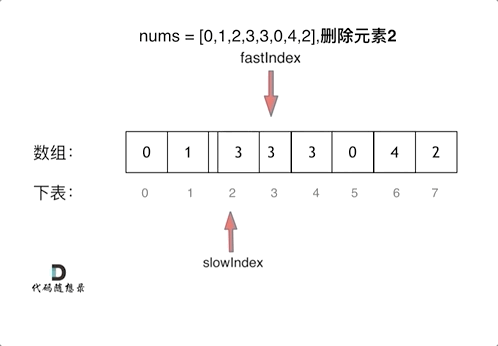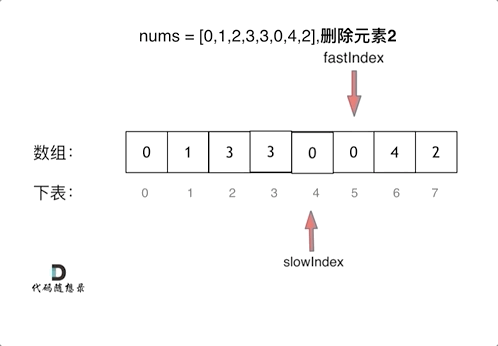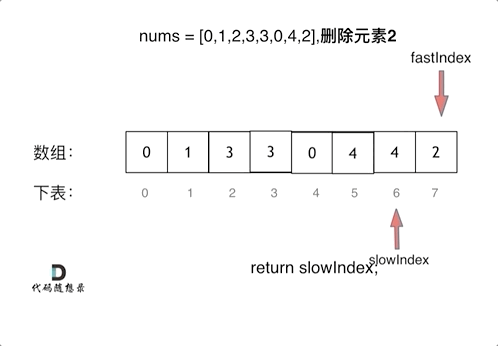
Mask R-CNN 相关知识点
- 整体框架
- 1.Resnet 深度残差学习
- 1.1 目的
- 1.2 深度学习深度增加带来的问题
- 1.3 Resnet实现思想【添加恒等映射】
- 2.线性插值
- 2.1 目的
- 2.2 线性插值原理
- 2.3 为什么使用线性插值?
- 3.FPN 特征金字塔
- 3.1 FPN介绍
- 3.2 为什么使用FPN?
- 3.3 自下而上层【提取特征】
- 3.4 自上而下层【横向连接,特征融合】
- 4. Anchors(候选框生成)
- 4.1 实现步骤
- 5. RPN 区域建议网络
- 5.1 目的
- 5.2 实现步骤
- 6. ROI 感兴趣区域
- 6.1 目的
- 6.2 实现步骤
- 7. DetectionTargetLayer【目标检测层】
- 7.1 目的
- 7.2 实现步骤
- 8. RoiAlign 水平对齐
- 8.1 为什么使用线性插值实现?【使用RoIPool带来的问题】
- 8.2 使用ROIAlign 与RoiPool的原因
- 8.3 ROIAlign优点
- 9.分类与回归
- 相关文章链接
- Resnet论文
- Mask R-cnn论文
- 线性插值原理
整体框架

1.Resnet 深度残差学习
1.1 目的
- 防止增加深度模型
loss增加问题
1.2 深度学习深度增加带来的问题
- 梯度消失与爆炸问题
退化问题:随着网络深度的增加,准确度会饱和,然后迅速退化。
1.3 Resnet实现思想【添加恒等映射】
- 增加模型层数与
恒等映射做对比,如果增加层数效果变差,就把权重设置接近于0的值。【近似于没有增加模型深度】 - 确保较深的模型应该不会比较浅的模型产生更高的训练误差。
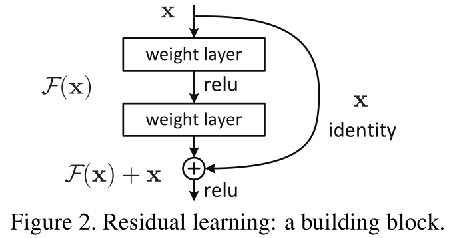
Convolution Block和identity Block区别Convolution Block通道数和特征图大小变化了

2.线性插值
2.1 目的
- 减少像素特征不对齐问题
- 降低预测框误差
2.2 线性插值原理
- 单线性插值: 根据2点确定一条直线,斜率固定,就可以得到插入值的位置
- 多线性插值就是多次的但线性插值得到的
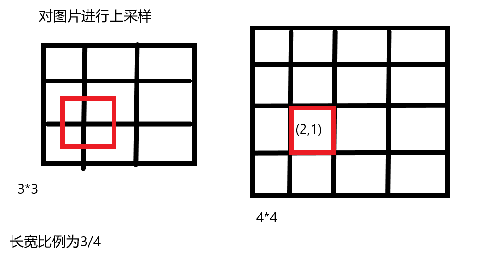
2.3 为什么使用线性插值?
- 对图片上采样,原始图片 3 ∗ 3 3*3 3∗3范围红色框中的值,会得到 4 ∗ 4 4*4 4∗4框中红色框的值。
- 假设目标图片红框坐标为 ( i , j ) (i,j) (i,j),那么在原始图片位置 ( i ∗ 3 / 4 , j ∗ 3 / 4 ) (i*3/4,j*3/4) (i∗3/4,j∗3/4)
- 已知
i
=
2
,
j
=
3
i
=
2
,
j
=
3
i
=
2
,
j
=
3
i = 2 , j = 3 i=2,j=3i=2,j=3
i=2,j=3i=2,j=3i=2,j=3,所以在原始图片位置
(
1.5
,
0.75
)
( 1.5 , 0.75 )
(1.5,0.75)
- 不是整数,在找原始图片位置时,会自动取整
- 即,需要使用线性插值,来降低误差
3.FPN 特征金字塔
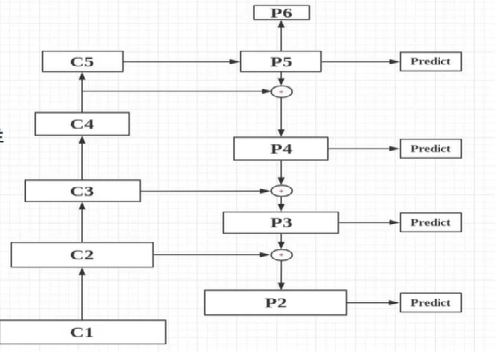
3.1 FPN介绍
- 横向连接的自顶向下结构
- 用来提取特征和特征融合
3.2 为什么使用FPN?
- 在特征提取中去最后一层特征图,对图片语义性较高,但是对于图片的小物体,零散特征不多,使小物体在图片中检测的效果不好
- 将多个阶段特征图融合在一起,有了高层语义特征,也有了底层轮廓特征,效果会更好

3.3 自下而上层【提取特征】
- 使用
Resnet深度残差算法主干结构提取特征,返回每个阶段最后一层的数据。- 不改变特征图大小的层为一个阶段
- 每次提取特征都是每个阶段最后一层的输出
3.4 自上而下层【横向连接,特征融合】
- 使用
1*1卷积核将特征图大小统一 - 使用线性插值进行上采样与此阶段的前一个阶段进行特征融合,以此类推,返回特征融合后每个阶段的值
- 例如:
C5阶段的特征图上采样后与C4的特征图融合,得到P4。
4. Anchors(候选框生成)
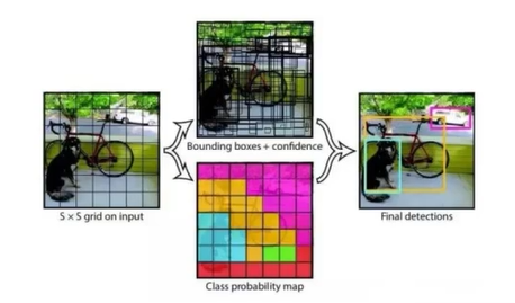
4.1 实现步骤
- 对提取的特征图进行区域金字塔网络
- 将生成很多不同的候选框,在图片上进行提取特征,一个图片会提取出多种特征图
anchors(候选框生成):以每个像素点为中心,设置3个不同大小的scales,每个scales有3个不同的roatis,生成各种框- 例如:
scales:(32, 64, 128),roatis([0.5, 1, 2]),所以每个像素点会生成9个不同的框

5. RPN 区域建议网络
5.1 目的
- 提取前景与背景
RPN具有平移不变性- 在不同位置的同一物体都可以检测出来,因为生成了很多框
5.2 实现步骤
- 分类:对生成的候选框进行二分类,判断是前景还是背景
- 回归:得到候选框偏移量【
ground-truth与候选框偏移大小】 - 将生成的候选框做前景和背景二分类
- 返回分类得分,分类概率,区域框数据

- 返回分类得分,分类概率,区域框数据
6. ROI 感兴趣区域
6.1 目的
- 筛选有用的候选框
6.2 实现步骤
- 按照前景得分排序,取前
n个的得分最高的候选框 - 根据候选框偏移量微调候选框位置,使候选框更接近
grouth-truth框 - 对于越界的候选框,进行范围修剪
IOU过滤:筛选出候选框与ground-truth重叠比例大于阈值的候选框MNS(非极大值抑制)过滤:候选框重叠比例大于阈值的最高得分候选框- 根据得分值选择前
n个得分最高的前景,获取正样本数据集
7. DetectionTargetLayer【目标检测层】
7.1 目的
- 找到正样本
GT的类别,IOU最大的类别 - 正样本与
GT-box的偏移量 - 正样本与
GT-box对应的掩码mask,即实例分割框 - 负样本的偏移量与
mask使用0填充
7.2 实现步骤
- 去除
padding填充的候选框 - 获取前
n个得分最高的前景数量不够,会使用padding填充,凑齐n个前景 - 去除一个框包含多个物体的去除
- 正负样本判断:基于
ROI和ground-truth,通过IOU值与默认阈值0.5判断 - 数据集正负比例为
1:3
8. RoiAlign 水平对齐
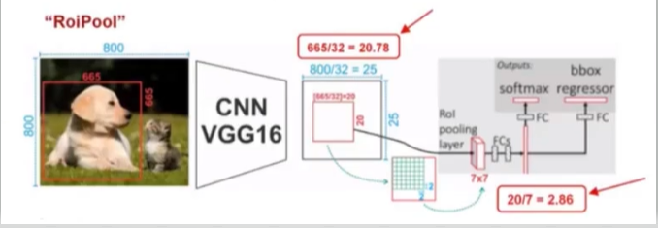
8.1 为什么使用线性插值实现?【使用RoIPool带来的问题】
- 当一个特征图大小为
800时,物体大小是665,对特征图进行卷积,假设特征图缩小了32倍,800/32=25,得到新的25大小特征图,但是665/32=20.78,所以物体的位置应该在25特征图上占20.78,但是他们会舍弃小数,实际是占20的大小 - 将物体映射到原图,会损失
0.78*32=24.96个像素点,对于大物体偏差不大,但是对于小物体偏差就会很大【如果出现奇数就会出现这个问题】
8.2 使用ROIAlign 与RoiPool的原因
- 网络进入全连接层,需要保持特征图大小一致
8.3 ROIAlign优点
- 消除了
RoIPool的苛刻量化【向下取整】,将提取的特征与输入正确对齐。 RoIPool没有pixel-to-pixel之间对齐关系,不能预测到原图位置的像素点,预测位置具有较大的误差。
9.分类与回归
- 将所有特征图大小统一后,就可以进入全连接层
- 进行相关分类与回归操作







![[架构之路-124]-《软考-系统架构设计师》-操作系统-3-操作系统原理 - IO设备、微内核、嵌入式系统](https://img-blog.csdnimg.cn/img_convert/97265df656e52926a882fff4c1bdb22b.jpeg)