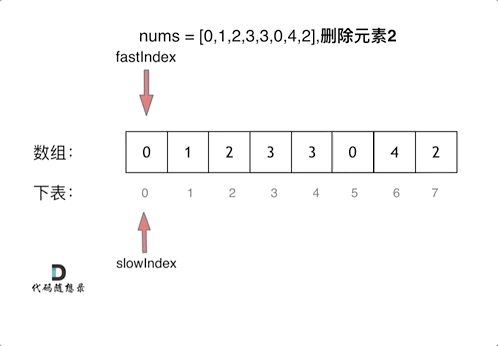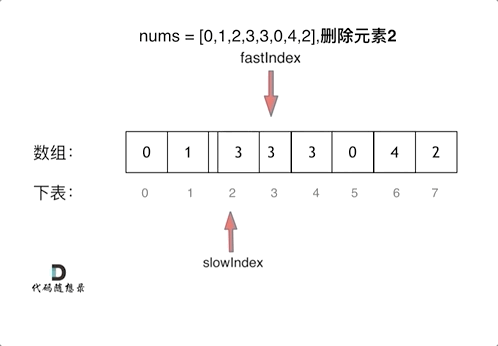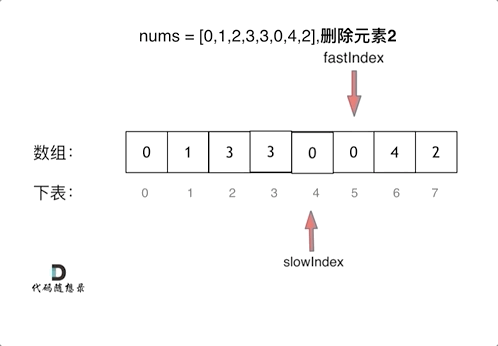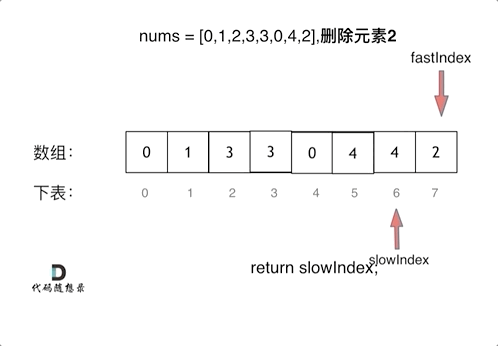
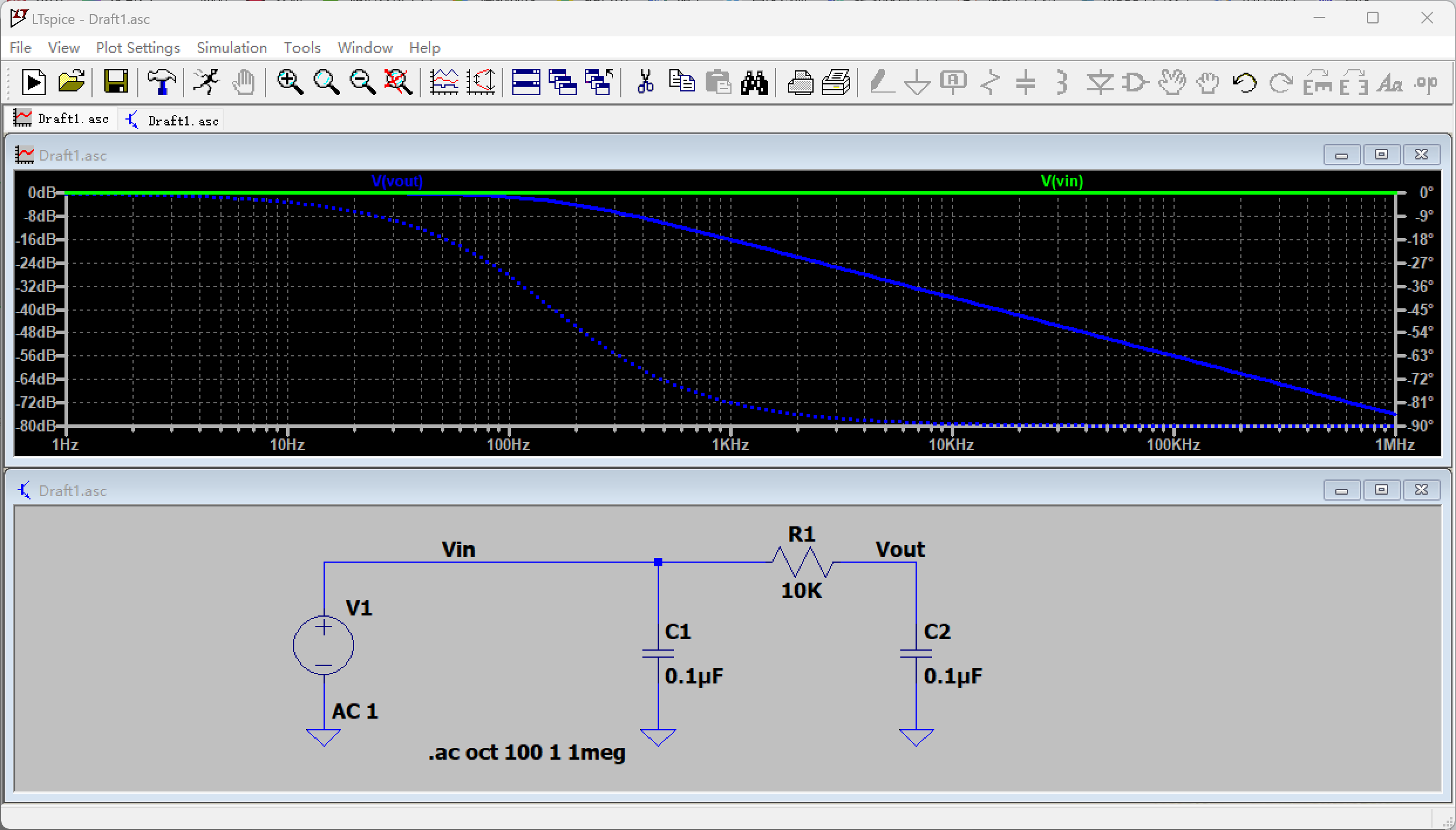
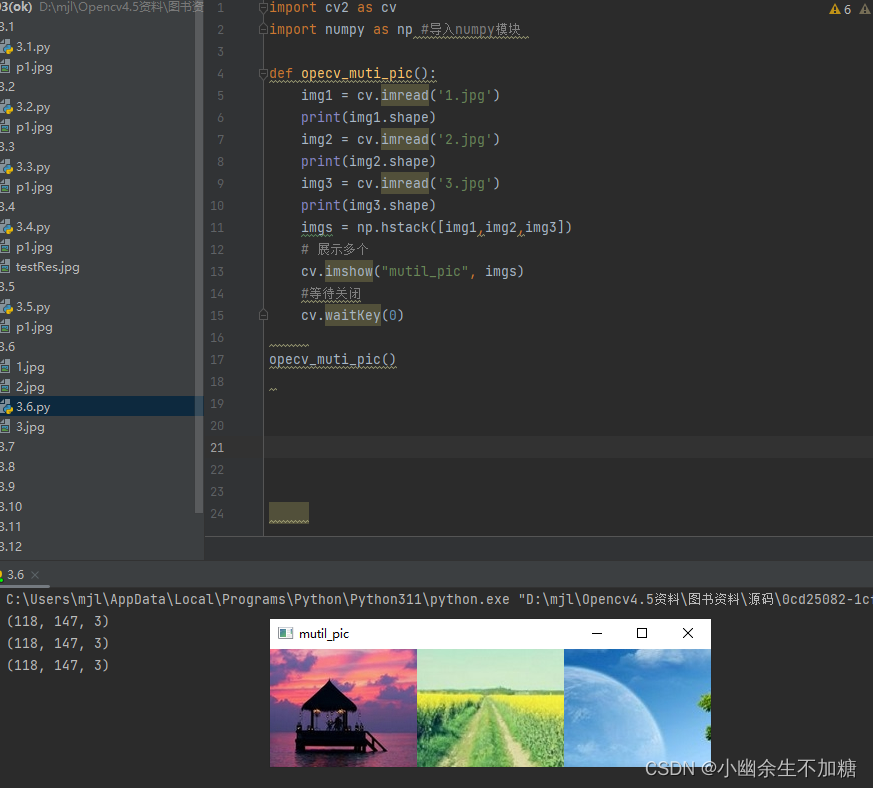
感知机
输入空间: X ⊆ R n \mathcal X\subseteq{\bf R^n} X⊆Rn ;输入: x = ( x ( 1 ) , x ( 2 ) , ⋅ ⋅ ⋅ , x ( n ) ) T ∈ X x=\left(x^{(1)},x^{(2)},\cdot\cdot\cdot,x^{(n)}\right)^{T}\in{\mathcal{X}} x=(x(1),x(2),⋅⋅⋅,x(n))T∈X
输出空间: Y = { + 1 , − 1 } {\mathcal Y}=\{+1,-1\} Y={+1,−1} ;输出: y ∈ Y y \in \mathcal{Y} y∈Y
感知机:
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
=
{
+
1
,
w
⋅
x
+
b
≥
0
−
1
,
w
⋅
x
+
b
<
0
f(x)=\mathrm{sign}(w\cdot x+b)=\left\{\begin{array}{l l}{{+1,}}&{{w\cdot x+b\geq0}}\\ {{-1,}}&{{w\cdot x+b\lt 0}}\end{array}\right.
f(x)=sign(w⋅x+b)={+1,−1,w⋅x+b≥0w⋅x+b<0
其中,
w
=
(
w
(
1
)
,
w
(
2
)
,
⋅
⋅
⋅
,
w
(
n
)
)
T
∈
R
n
w = \left(w^{(1)},\,w^{(2)},\,\cdot\,\cdot\,\cdot\,\mathrm{,\,}w^{(n)}\right)^{T}\,\in {\bf R^n}
w=(w(1),w(2),⋅⋅⋅,w(n))T∈Rn (Weight),
b
∈
R
b \in \bf R
b∈R 称为偏置(Bias),
w
⋅
x
w \cdot x
w⋅x 表示内积
w
⋅
x
=
w
(
1
)
x
(
1
)
+
w
(
2
)
x
(
2
)
+
⋯
+
w
(
n
)
x
(
n
)
w \cdot x=w^{(1)} x^{(1)}+w^{(2)} x^{(2)}+\cdots+w^{(n)} x^{(n)}
w⋅x=w(1)x(1)+w(2)x(2)+⋯+w(n)x(n)
假设空间:
F
=
{
f
∣
f
(
x
)
=
w
⋅
x
+
b
}
{\mathcal{F}}=\{{\mathcal{f}}|\;{\mathcal{f}}(x)=w\cdot x+b\}
F={f∣f(x)=w⋅x+b}
几何含义

线性方程:
w
⋅
x
+
b
=
0
w \cdot x + b = 0
w⋅x+b=0
特征空间
R
n
{\bf R^n}
Rn 中的一个超平面:
S
\rm S
S ;法向量:
w
w
w ;截距:
b
b
b
条件
数据集的线性可分性:
给定数据集:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
⋅
⋅
⋅
⋅
,
(
x
N
,
y
N
)
}
T=\{(x_{1},y_{1}),(x_{2},y_{2})\cdot\cdot\cdot\cdot,(x_{N},y_{N})\}
T={(x1,y1),(x2,y2)⋅⋅⋅⋅,(xN,yN)}
若存在某个超平面
S
\rm S
S :
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0
能够将数据集的正负实例点完全正确的划分到超平面两侧,即:
{
y
i
=
+
1
,
w
⋅
x
i
+
b
>
0
y
i
=
−
1
,
w
⋅
x
i
+
b
<
0
\left\{\begin{array}{l l}{{y_{i}=+1,}}&{{ w\cdot x_{i}+b\gt 0}}\\ {{y_{i}=-1,}}&{{ w\cdot x_{i}+b\lt 0}}\end{array}\right.
{yi=+1,yi=−1,w⋅xi+b>0w⋅xi+b<0
那么,称
T
T
T 为线性可分数据集;否则,称
T
T
T 为线性不可分。
∀
x
0
∈
R
n
\forall x_{0}\in{\bf R^n}
∀x0∈Rn 到
S
\rm S
S 的距离:
1
∥
w
∥
∣
w
⋅
x
0
+
b
∣
\frac{1}{\|w\|}\left|w \cdot x_0+b\right|
∥w∥1∣w⋅x0+b∣
这里,
∥
w
∥
\|w\|
∥w∥ 是
w
w
w 的
L
2
L_2
L2 范数。
- 若 x 0 x_0 x0 是正确分类点,则:
1 ∥ w ∥ ∣ w ⋅ x 0 + b ∣ = { w ⋅ x 0 + b ∥ w ∥ , y 0 = + 1 − w ⋅ x 0 + b ∥ w ∥ , y 0 = − 1 \frac{1}{\|w\|}\left|w \cdot x_0+b\right|=\left\{\begin{aligned} \frac{w \cdot x_0+b}{\|w\|}, & y_0=+1 \\ -\frac{w \cdot x_0+b}{\|w\|}, & y_0=-1 \end{aligned}\right. ∥w∥1∣w⋅x0+b∣=⎩ ⎨ ⎧∥w∥w⋅x0+b,−∥w∥w⋅x0+b,y0=+1y0=−1
- 若 x 0 x_0 x0 是错误分类点,则:
1 ∥ w ∥ ∣ w ⋅ x 0 + b ∣ = { − w ⋅ x 0 + b ∥ w ∥ , y 0 = + 1 w ⋅ x 0 + b ∥ w ∥ , y 0 = − 1 = − y 0 ( w ⋅ x 0 + b ) ∥ w ∥ \frac{1}{\|w\|}\left|w \cdot x_0+b\right|=\left\{\begin{array}{cc} -\frac{w \cdot x_0+b}{\|w\|}, & y_0=+1 \\ \frac{w \cdot x_0+b}{\|w\|}, & y_0=-1 \end{array}=\frac{-y_0\left(w \cdot x_0+b\right)}{\|w\|}\right. ∥w∥1∣w⋅x0+b∣={−∥w∥w⋅x0+b,∥w∥w⋅x0+b,y0=+1y0=−1=∥w∥−y0(w⋅x0+b)
误分类点
x
i
x_i
xi 到
S
\rm S
S 的距离:
$$
- \frac{1}{|w|}\left|w \cdot x_0+b\right|
KaTeX parse error: Can't use function '$' in math mode at position 10: 所有误分类点到 $̲\rm S$ 的距离:
-\frac{1}{|w|} \sum_{x_i \in M} y_i\left(w \cdot x_i+b\right)
$$
其中, M M M 代表所有误分类点的集合。
损失函数:
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b)
L(w,b)=−xi∈M∑yi(w⋅xi+b)
模型参数估计:
arg
min
w
,
b
L
(
w
,
b
)
\underset{w, b}{\arg \min } L(w, b)
w,bargminL(w,b)
梯度下降法
梯度:指某一函数在该点处最大的方向导数,沿着该方向可取得最大的变化率。
∇
=
∂
f
(
θ
)
∂
θ
\nabla={\frac{\partial f(\theta)}{\partial\theta}}
∇=∂θ∂f(θ)
若
f
(
θ
)
f(\theta)
f(θ) 是凸函数,可通过梯度下降法进行优化:
θ
(
k
+
1
)
=
θ
(
k
)
−
η
∇
F
(
θ
(
k
)
)
\theta^{(k+1)}=\theta^{(k)}-\eta\nabla F(\theta^{(k)})
θ(k+1)=θ(k)−η∇F(θ(k))
η
\eta
η 表示步长,在统计学中表示学习率。
输入:目标函数 f ( θ ) f(\theta) f(θ) ,步长 η \eta η ,计算精度 $\epsilon $ ;
输出: f ( θ ) f(\theta) f(θ) 的极小值点 θ ∗ \theta^* θ∗ 。
- 选取初始值 θ ( 0 ) ∈ R n \theta^{(0)}\in{\bf R^n} θ(0)∈Rn ,置 k = 0 k = 0 k=0 。
- 计算 f ( θ ( k ) ) f(\theta^{(k)}) f(θ(k)) 。
- 计算梯度 ∇ f ( θ ( k ) ) \nabla f(\theta^{(k)}) ∇f(θ(k)) 。
- 置 θ ( k + 1 ) = θ ( k ) − η ∇ F ( θ ( k ) ) \theta^{(k+1)}=\theta^{(k)}-\eta\nabla F(\theta^{(k)}) θ(k+1)=θ(k)−η∇F(θ(k)) ,计算 f ( θ ( k + 1 ) ) f(\theta^{(k +1)}) f(θ(k+1)) ,当 ∣ ∣ f ( θ ( k + 1 ) ) − f ( θ ( k ) ) ∣ ∣ < ϵ ||f(\theta^{(k+1)})-f(\theta^{(k)})||\lt \epsilon ∣∣f(θ(k+1))−f(θ(k))∣∣<ϵ 或者 ∣ ∣ θ ( k + 1 ) − θ ( k ) ∣ ∣ < ϵ ||\theta^{(k+1)}-\theta^{(k)}||\lt \epsilon ∣∣θ(k+1)−θ(k)∣∣<ϵ 时,停止迭代,令 θ ∗ = θ ( k + 1 ) \theta^* = \theta^{(k+1)} θ∗=θ(k+1) 。
- 否则,置 k = k + 1 k = k+1 k=k+1 ,转到第三步。
感知机的原始形式(随机梯度下降法)
损失函数:
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b)
L(w,b)=−xi∈M∑yi(w⋅xi+b)
梯度:
∇
w
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
x
i
;
∇
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
\nabla_{w}L(w,b)=-\sum_{x_{i}\in M}y_{i}x_{i} ; \qquad \qquad \nabla_{b}L(w,b)=-\sum_{x_{i}\in M}y_{i}
∇wL(w,b)=−xi∈M∑yixi;∇bL(w,b)=−xi∈M∑yi
梯度下降:
θ
(
k
+
1
)
=
θ
(
k
)
−
η
∇
F
(
θ
(
k
)
)
\theta^{(k+1)}=\theta^{(k)}-\eta\nabla F(\theta^{(k)})
θ(k+1)=θ(k)−η∇F(θ(k))
参数更新:
-
批量梯度下降法(Batch Gradient Descent):每次迭代时使用所有误分类点来进行参数更新。
w ← w + η ∑ x i ∈ M y i x i ; b ← b + η ∑ x i ∈ M y i w\leftarrow w+\eta\sum_{x_{i}\in M}y_{i}x_{i};\qquad\qquad b\leftarrow b+\eta\sum_{x_{i}\in M}y_{i} w←w+ηxi∈M∑yixi;b←b+ηxi∈M∑yi
其中, η ( 0 < η ≤ 1 ) \eta(0<\eta \leq 1) η(0<η≤1) 代表步长。 -
随机梯度下降法(Stochastic Gradient Descent):每次随机选取一个误分类点。
w ← w + η y i x i ; b ← b + η y i w\leftarrow w+\eta y_{i}x_{i};\qquad\qquad b\leftarrow b+\eta y_{i} w←w+ηyixi;b←b+ηyi
算法:
输入:训练集:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
⋅
⋅
⋅
⋅
,
(
x
N
,
y
N
)
}
T=\{(x_{1},y_{1}),(x_{2},y_{2})\cdot\cdot\cdot\cdot,(x_{N},y_{N})\}
T={(x1,y1),(x2,y2)⋅⋅⋅⋅,(xN,yN)}
其中,
x
i
∈
X
⊆
R
n
x_i \in \mathcal X \subseteq \bf R^n
xi∈X⊆Rn ,
y
∈
Y
=
+
1
,
−
1
y \in \mathcal Y = {+1,-1}
y∈Y=+1,−1 ;步长
η
(
0
<
η
≤
1
)
\eta(0 < \eta \leq 1)
η(0<η≤1)
输出: w , b w,b w,b ;感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) f(x) = \mathrm{sign}(w \cdot x + b) f(x)=sign(w⋅x+b)
- 选取初始值 w 0 , b 0 w_0, b_0 w0,b0 ;
- 于训练集中随机选取数据 ( x i , y i ) (x_i, y_i) (xi,yi) ;
- 若 y i ( w ⋅ x i + b ) ≤ 0 y_i (w \cdot x_i + b) \leq 0 yi(w⋅xi+b)≤0 :
w ← w + η y i x i ; b ← b + η y i w\leftarrow w+\eta y_{i}x_{i};\qquad\qquad b\leftarrow b+\eta y_{i} w←w+ηyixi;b←b+ηyi
感知机的对偶形式
在原始形式中,若
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi) 为误分类点,更新参数:
w
←
w
+
η
y
i
x
i
;
b
←
b
+
η
y
i
w\leftarrow w+\eta y_{i}x_{i};\qquad\qquad b\leftarrow b+\eta y_{i}
w←w+ηyixi;b←b+ηyi
假设初始值
w
0
=
0
,
b
0
=
0
w_0 = 0, b_0 = 0
w0=0,b0=0 ,对误分类点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi) 通过上述公式更新参数,修改
n
i
n_i
ni 次之后,
w
,
b
w,b
w,b 的增量分别为
α
i
y
i
x
i
\alpha_i y_i x_i
αiyixi 和
α
i
y
i
\alpha_i y_i
αiyi ,其中
α
i
=
n
i
η
\alpha_i = n_i \eta
αi=niη ,
n
i
n_i
ni 是点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi) 被误分类的次数。
最后学习到的参数为:
w
=
∑
i
=
1
N
α
i
y
i
x
i
;
b
=
∑
i
=
1
N
α
i
y
i
w=\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i};\qquad \qquad b=\sum_{i=1}^{N}\alpha_{i}y_{i}
w=i=1∑Nαiyixi;b=i=1∑Nαiyi
算法:
输入:训练集:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
⋅
⋅
⋅
⋅
,
(
x
N
,
y
N
)
}
T=\{(x_{1},y_{1}),(x_{2},y_{2})\cdot\cdot\cdot\cdot,(x_{N},y_{N})\}
T={(x1,y1),(x2,y2)⋅⋅⋅⋅,(xN,yN)}
其中,
x
i
∈
X
⊆
R
n
x_i \in \mathcal X \subseteq \bf R^n
xi∈X⊆Rn ,
y
∈
Y
=
+
1
,
−
1
y \in \mathcal Y = {+1,-1}
y∈Y=+1,−1 ;步长
η
(
0
<
η
≤
1
)
\eta(0 < \eta \leq 1)
η(0<η≤1)
输出: α , b \alpha,b α,b ;感知机模型 f ( x ) = s i g n ( ∑ j = 1 N α i y i x j ⋅ x + b ) f(x) = \mathrm{sign}(\sum_{j = 1}^{N} \alpha_i y_i x_j \cdot x + b) f(x)=sign(∑j=1Nαiyixj⋅x+b) ,其中 α = ( α 1 , α 2 , ⋯ , α N ) T \alpha = {(\alpha_1, \alpha_2, \cdots, \alpha_N)}^T α=(α1,α2,⋯,αN)T
-
选取初始值 α < 0 > = ( 0 , 0 , ⋅ ⋅ ⋅ , 0 ) T , b < 0 > = 0 \alpha^{\lt 0\gt }=(0,0,\cdot\cdot\cdot,0)^{T},\ b^{\lt 0\gt }=0 α<0>=(0,0,⋅⋅⋅,0)T, b<0>=0 ,上标表示被误分类的次数;
-
于训练集中随机选取数据 ( x i , y i ) (x_i,y_i) (xi,yi) ;
-
若 y i ( ∑ j = 1 N α j y j x j ⋅ x i + b ) ≤ 0 y_{i}(\sum_{j=1}^{N}\alpha_{j}y_{j}x_{j}\cdot\,x_{i}+b)\leq0 yi(∑j=1Nαjyjxj⋅xi+b)≤0 ,
α ← α + η ; b ← b + η y i {\alpha} \leftarrow {\alpha +\eta};\qquad\qquad b\leftarrow b+\eta y_{i} α←α+η;b←b+ηyi -
转(2),直至没有误分类点。
Gram 矩阵
对于感知机的对偶形式中的(3): y i ( ∑ j = 1 N α j y j x j ⋅ x i + b ) ≤ 0 y_{i}(\sum_{j=1}^{N}\alpha_{j}y_{j}x_{j}\cdot\,x_{i}+b)\leq0 yi(∑j=1Nαjyjxj⋅xi+b)≤0
迭代条件:
y
i
(
∑
j
=
1
N
α
j
y
j
x
j
⋅
x
i
+
b
)
=
y
i
[
(
α
1
y
1
x
1
+
α
2
y
2
x
2
+
⋯
+
α
N
y
N
x
N
)
⋅
x
i
+
b
)
]
=
y
i
(
α
1
y
1
x
1
⋅
x
i
+
α
2
y
2
x
2
⋅
x
i
+
⋯
+
α
N
y
N
x
N
⋅
x
i
+
b
)
≤
0
\begin{aligned} y_i\left(\sum_{j=1}^N \alpha_j y_j x_j \cdot x_i+b\right) & \left.=y_i\left[\left(\alpha_1 y_1 x_1+\alpha_2 y_2 x_2+\cdots+\alpha_N y_N x_N\right) \cdot x_i+b\right)\right] \\ & =y_i\left(\alpha_1 y_1 x_1 \cdot x_i+\alpha_2 y_2 x_2 \cdot x_i+\cdots+\alpha_N y_N x_N \cdot x_i+b\right) \\ & \leq 0 \end{aligned}
yi(j=1∑Nαjyjxj⋅xi+b)=yi[(α1y1x1+α2y2x2+⋯+αNyNxN)⋅xi+b)]=yi(α1y1x1⋅xi+α2y2x2⋅xi+⋯+αNyNxN⋅xi+b)≤0
Gram 矩阵:
N
N
N 维欧式空间中任意
k
k
k 个向量之间两两的内积所组成的矩阵
G
=
[
x
i
⋅
x
j
]
N
×
N
=
[
x
1
⋅
x
1
x
1
⋅
x
2
⋯
x
1
⋅
x
N
x
2
⋅
x
1
x
2
⋅
x
2
⋯
x
2
⋅
x
N
⋮
⋮
⋮
x
N
⋅
x
1
x
N
⋅
x
2
⋯
x
N
⋅
x
N
]
G=\left[x_i \cdot x_j\right]_{N \times N}=\left[\begin{array}{cccc} x_1 \cdot x_1 & x_1 \cdot x_2 & \cdots & x_1 \cdot x_N \\ x_2 \cdot x_1 & x_2 \cdot x_2 & \cdots & x_2 \cdot x_N \\ \vdots & \vdots & & \vdots \\ x_N \cdot x_1 & x_N \cdot x_2 & \cdots & x_N \cdot x_N \end{array}\right]
G=[xi⋅xj]N×N=
x1⋅x1x2⋅x1⋮xN⋅x1x1⋅x2x2⋅x2⋮xN⋅x2⋯⋯⋯x1⋅xNx2⋅xN⋮xN⋅xN
在感知机的对偶形式中,可将 Gram 矩阵提前算出。
总结归纳
- 超平面:在几何空间中,如果环境空间中是 n n n 维,那么它所对应的超平面就是 n − 1 n - 1 n−1 维的子空间。
- 感知机必须要求数据集线性可分,因为算法的停止条件就是没有误分类点。
- 对于所有误分类点到 S \rm S S 的距离: − 1 ∥ w ∥ ∣ w ⋅ x 0 + b ∣ - \frac{1}{\|w\|}\left|w \cdot x_0+b\right| −∥w∥1∣w⋅x0+b∣ , 1 ∥ w ∥ \frac{1}{\|w\|} ∥w∥1 不影响损失函数的正负值判断,同时不影响感知机的分类结果,故在损失函数中不体现。
- 梯度可以简单理解为对损失函数求偏导。
- 梯度下降算法无法处理鞍点的情况,故梯度下降算法只能得到局部最优点,无法找到全局最优解。
- 当数据维度过高时,批量梯度算法的求解过于复杂,甚至会出现无法求出最优解的情况,故在相关算法中,随机梯度下降法仍是求解的第一选择。
- 提前将 Gram 矩阵算出,在对偶形式的感知机进行函数计算时,直接利用 Gram 矩阵预先计算的结果,会提高算法的速度。
- 若采用随机梯度下降法, y i ( ∑ j = 1 N α j y j x j ⋅ x i + b ) ≤ 0 y_{i}(\sum_{j=1}^{N}\alpha_{j}y_{j}x_{j}\cdot\,x_{i}+b)\leq0 yi(∑j=1Nαjyjxj⋅xi+b)≤0 实际上只有一个误分类点,并无求和。
- 感知机求得的超平面不唯一,若唯一则需要添加限定条件,这是支持向量机的内容。

![[架构之路-124]-《软考-系统架构设计师》-操作系统-3-操作系统原理 - IO设备、微内核、嵌入式系统](https://img-blog.csdnimg.cn/img_convert/97265df656e52926a882fff4c1bdb22b.jpeg)