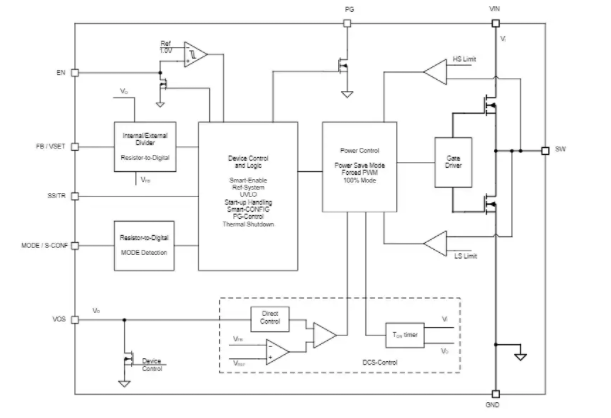
很久很久以前,C 语言统一了江湖。几乎所有的系统底层都是用 C 写的,当时定义的基本数据类型有
int、char、float 等整数类型、浮点类型、枚举、void、指针、数组、结构等等。然后只要碰到一串01010110010 之类的数据,编译器都可以正确的把它解析出来。
那么到了 C++ 诞生之后,出现了继承、派生这样新的概念,于是就诞生了一些新的数据结构。比如某个派生类,C 语言中哪有派生的概念啊,遇到这种数据编译器就不认识了。可是我们的计算机世界里,主要的系统还是用 C 写的啊,为了和旧的 C 数据相兼容,C++ 就提出了 POD 数据结构概念。
POD 是 Plain Old Data 的缩写,是 C++ 定义的一类数据结构概念,比如 int、float 等都是 POD 类型的。Plain 代表它是一个普通类型,Old 代表它是旧的,与几十年前的 C 语言兼容,那么就意味着可以使用memcpy() 这种最原始的函数进行操作。两个系统进行交换数据,如果没有办法对数据进行语义检查和解释,那就只能以非常底层的数据形式进行交互,而拥有 POD 特征的类或者结构体通过二进制拷贝后依然能保持数据结构不变。也就是说,能用 C 的 memcpy() 等函数进行操作的类、结构体就是 POD 类型的数据。
基本上谈到这个概念,一般都是说某某 class、struct、union 是不是 POD 类型的。
是不是 POD 类型的,可以用 is_pod::value 来判断。那什么样的类、结构体是拥有 POD 特性的
呢?要求有两个:
一个是它必须很平凡、很普通
另一个是布局有序。
能平凡就平凡trival(平凡)是个概念,满足以下条件即可:
不能写 构造/析构函数、拷贝/移动构造函数、拷贝/移动运算符,而是用编译器自动为我们生成,那这个数
据就是“平凡的”。非要写的话,用 C++ 11 的 default 关键字。例如下列代码用 std::is_trivial::value 来
判断是否“平凡”。

A 类手写了个构造函数,虽然什么都没填,但这构造函数已经不是编译器默认提供的了,所以不平凡,所
以就不是 POD 类,自然就不能用诸如 memcpy() 这种 C 语言的函数来操作;
B 类的一堆构造函数啥的都没写,默认由编译器提供,所以是平凡的;
C 类虽然写了构造函数,但用了 C++11 的 default 关键字修饰,也是平凡的。
不能有 虚函数 和 虚基类。只要满足以上条件,就是拥有平凡特征的数据类型。
布局要有序
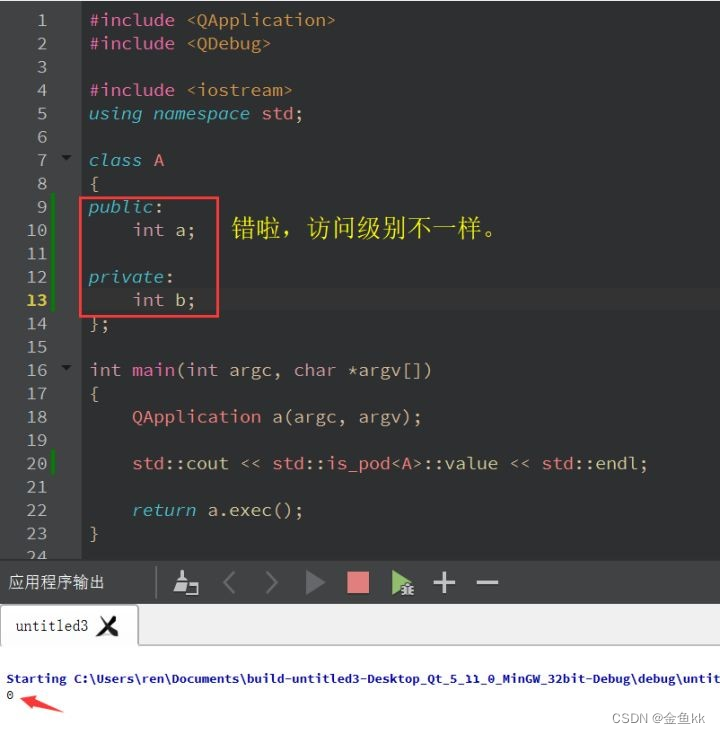
除了平凡之外,还对布局有要求。为了便于理解讲述,我们把非静态数据称为普通数据。普通成员有相同的访问级别。例如下面的类,因为 a 和 b 的访问级别不一样,所以布局无序,自然就不是POD 类型的数据。当然,如果 b 写成 static int b,例子中的 A 类就是 POD 类型的了。所以一定要看清每个字,是“普通成员”哦。
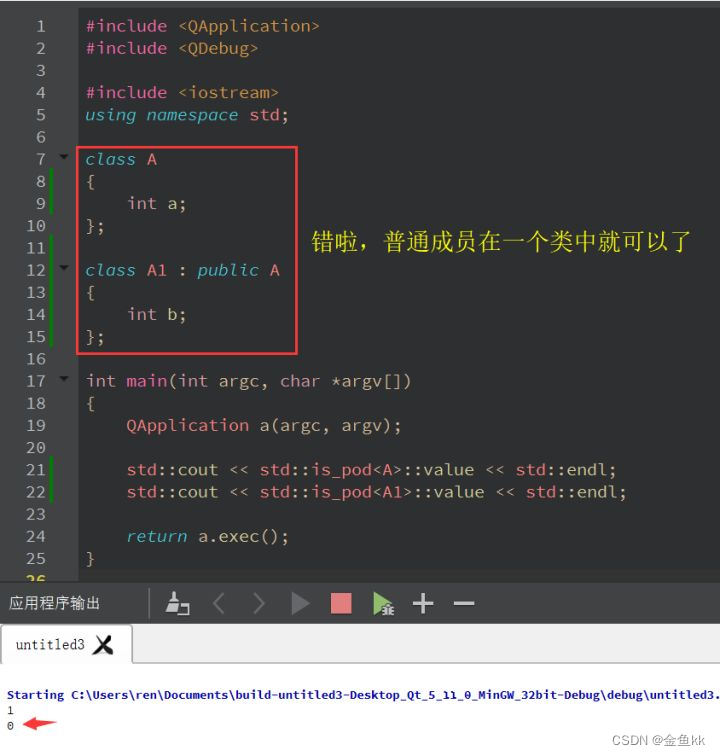
只要有父类,普通成员只能在其中一个类中,不可分散。因为 C 没有继承的概念,所以就别把普通成员在
两个类中都写,写在一个类中就像 C 的风格了。如下图的代码,从 A 的角度看上边没有父类,就按上文的
规则去判断是否是 POD 类型。从 A1 的角度看上边有个父类,这个时候就要看父子两个是否都有普通成员
了,都有的话肯定不行,只能其中一个有。
如何使用 POD 类型的数据?
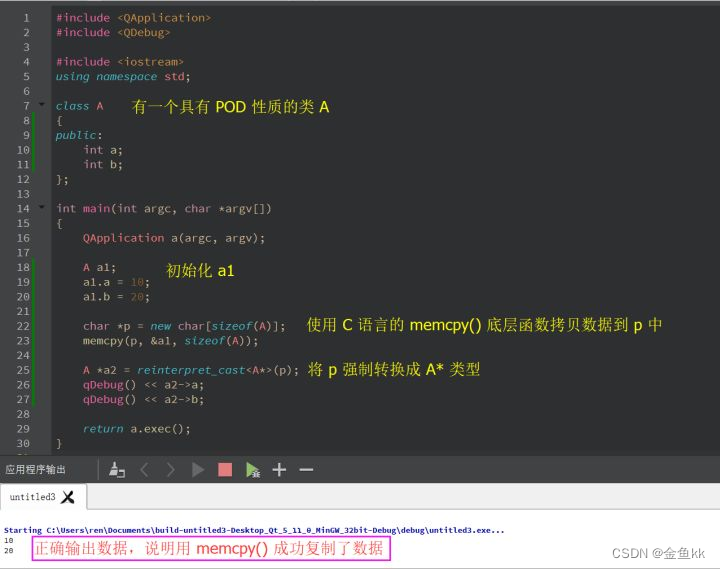
前面既然说了,具有 POD 性质的数据可以使用 C 语言中的 memcpy() 等底层函数,那我们来看看怎么
用。