消息队列:保存消息的一个容器,本质是个队列,但是需要支持高吞吐、高并发、高可用。
1 前世今生
1.1 业界消息队列对比
- Kafka:分布式的、分区的、多副本的日志提交服务,在高吞吐场景下发挥较为出色
- RocketMQ:低延迟、强一致、高性能、高可靠、万亿级容量和灵活的可扩展性,在一些实时场景中运用较广
- Pulsar:是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体、采用存算分离的架构设计
- BMQ:和Pulsar架构类似,存算分离,初期定位是承接高吞吐的离线业务场景,逐步替换掉对应的Kafka集群
2 Kafka
2.1 使用场景

2.2 如何使用
- 创建集群
- 新建Topic
- 编写生产者逻辑
- 编写消费者逻辑
2.3 基本概念

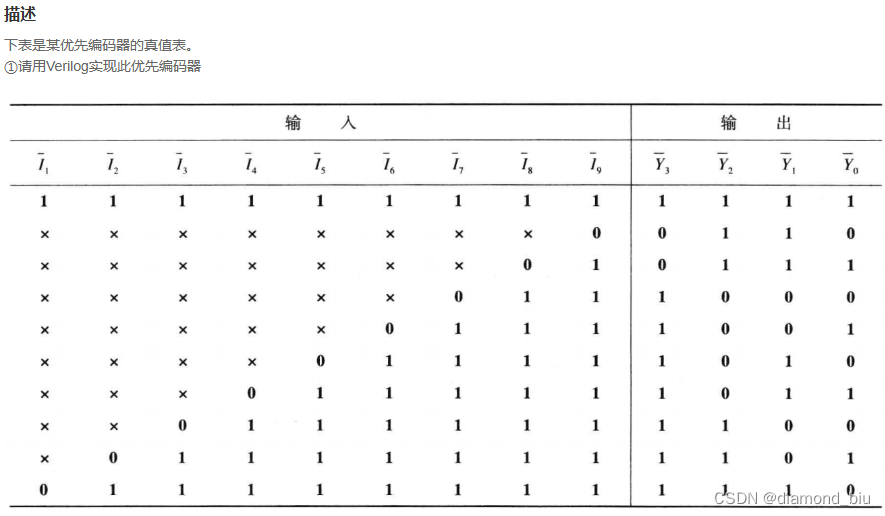
- Topic:逻辑队列,不同Topic可以建立不同的Topic
- Cluster:物理集群,每个集群中可以建立多个不同的Topic
- Producer:生产者,负责将业务消息发送到Topic中
- Consumer:消费者,负责消费Topic中的消息
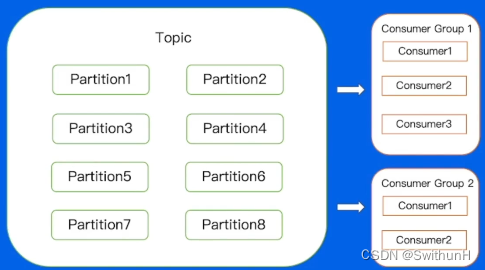
- ConsumerGroup:消费者组,不同组Consumer消费进度互不干涉
2.3.1 Offset
消息在partition内的相对位置信息,可以理解为唯一ID,在 partition内部严格递增。
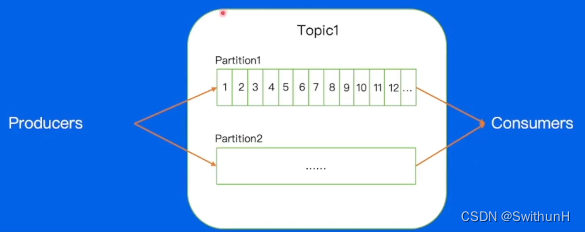
2.3.2 Replica
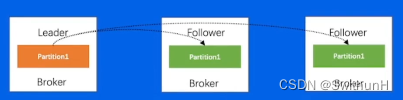
每个分片有多个 Replica,Leader Replica将会从ISR中选出。
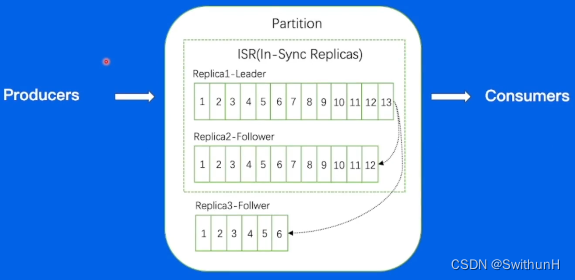
Follower可以理解为Leader的副本,与Leader差距过大会被踢出
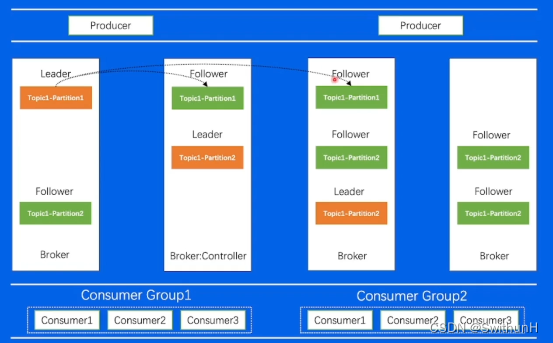
2.4 数据复制
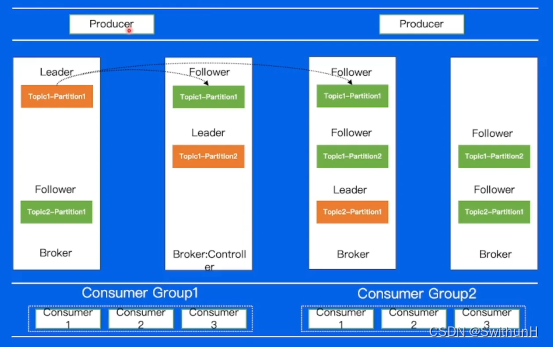
2.5 架构
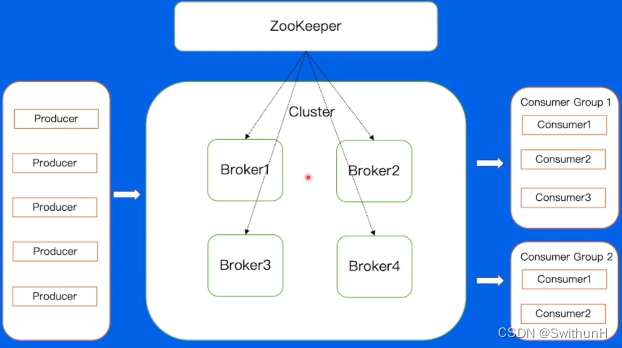
Zookeeper:负责存储集群元信息,包括分区分配信息等
2.6 一条消息的自述

2.7 Producer
2.7.1 批量发送
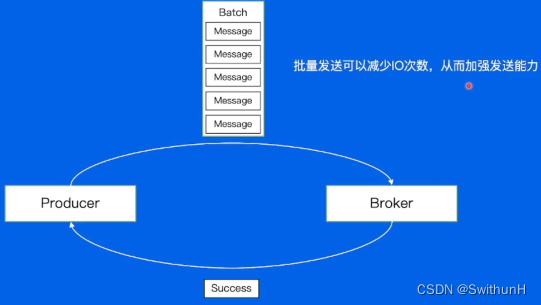
2.7.2 数据压缩

2.8 Broker
2.8.1 数据的存储
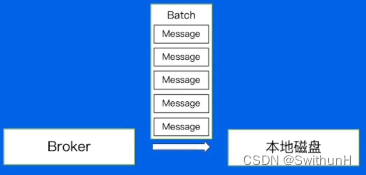
2.8.2 消息文件结构
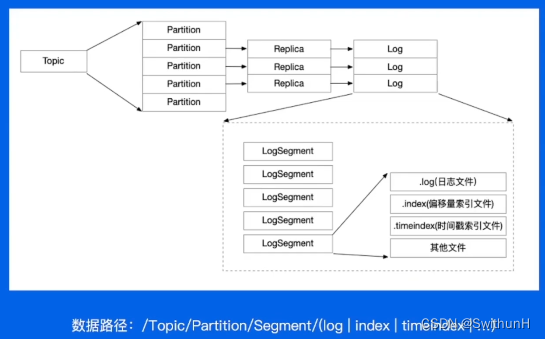
2.8.3 顺序写
采用顺序写的方式写入,提高写入效率
2.8.4 偏移量索引文件
目标寻找offset=28,二分找到小于目标offset的最大文件
2.8.5 时间戳索引文件
二分找到小于目标时间戳最大的索引位置,再通过寻找offset的方式找到最终数据
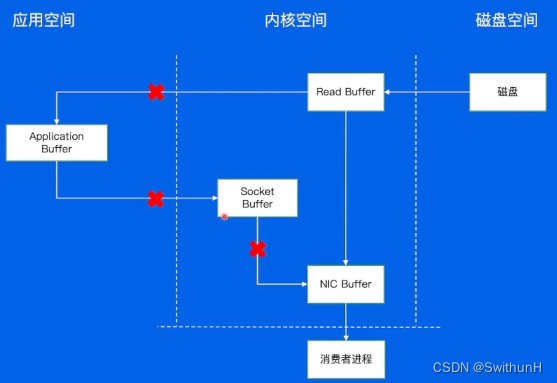
2.8.6 零拷贝
2.9 Consumer
2.9.1 消息的接收端
2.9.2 Low-Level
通过手动进行分配,哪一个 Consumer消费哪一个 Partition完全由业务来决定。
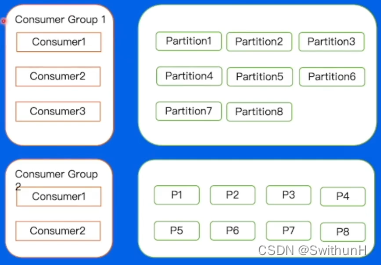
不能自动容灾,增加Consumer困难
2.9.3 High-Level
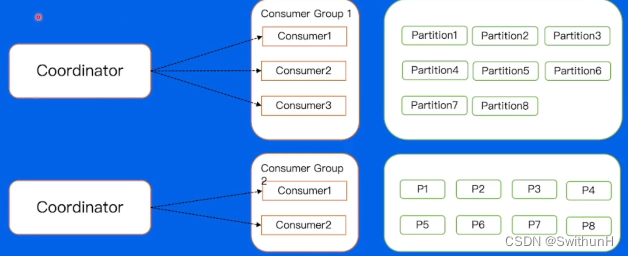
2.9.4 Rebalance
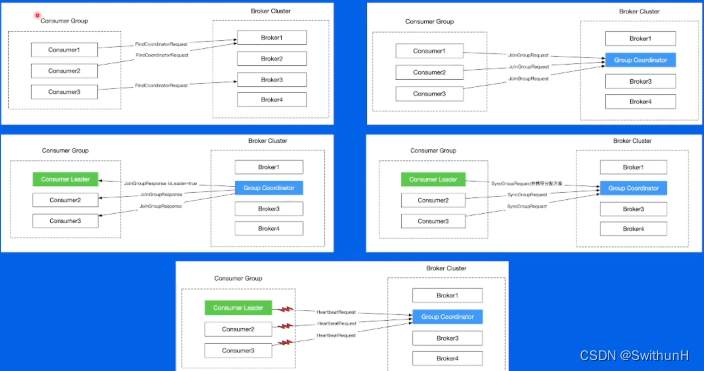
2.10 数据复制问题
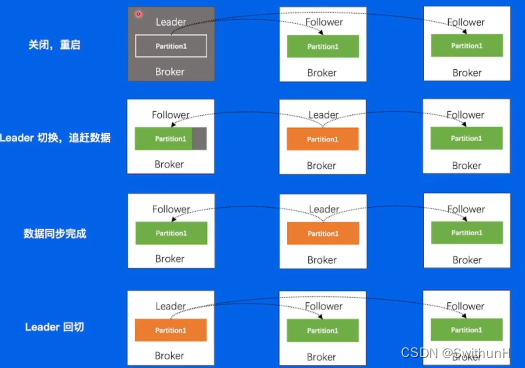
2.11 重启操作
2.12 替换、扩容、缩容
2.13 负载不均衡
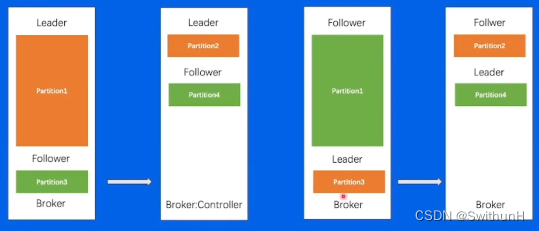
迁移Partition3后:
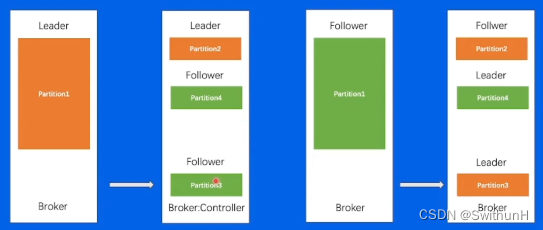
会造成IO问题
2.14 问题总结
- 运维成本高
- 对于负载不均衡的场景,解决方案复杂
- 没有自己的缓存,完全依赖Page Cache
- Controller和Coordinator和Broker 在同一进程中,大量IO会造成其性能下降
3 BMQ
3.1 简介
兼容Kafka协议,存算分离,云原生消息队列
3.2 HDFS写文件流程

4 RocketMQ
4.1 基本概念
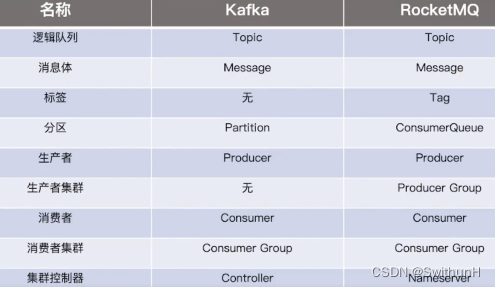
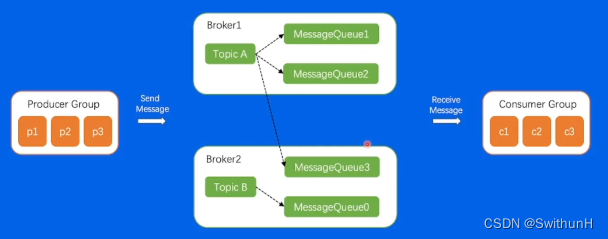
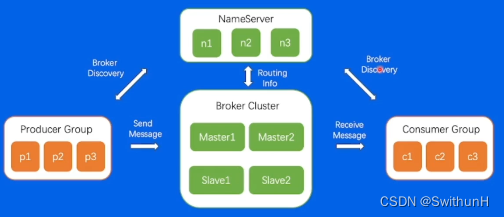
4.2 RocketMQ架构
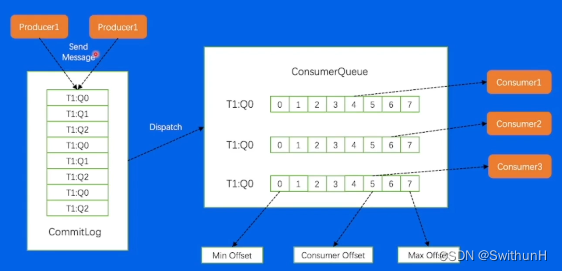
4.3 存储模型
4.4 高级特性
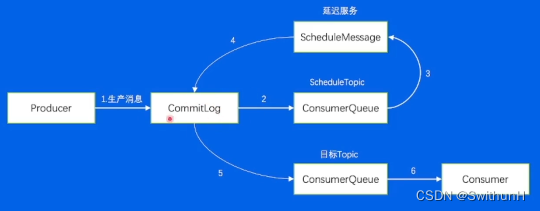
4.4.1 延迟发送
提前编辑→消息队列→定时发送→接收菜单
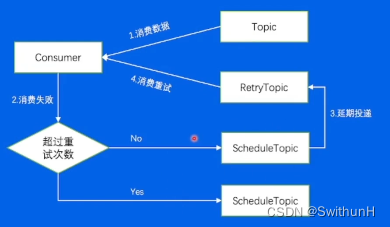
4.4.2 消费重试和死信队列