目录
1.什么是负载均衡
2.自定义负载均衡
3.基于Ribbon实现负载均衡
Ribbon⽀持的负载均衡策略
4.负载均衡原理
源码跟踪
LoadBalancerIntercepor
LoadBalancerClient
5.负载均衡策略IRule
总结
1.什么是负载均衡
2.自定义负载均衡



3. 修改 OrderServiceImpl 的代码,使用代码Random实现负载均衡
@Service
@Slf4j
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderDao orderDao;
@Autowired
private DiscoveryClient discoveryClient;
@Autowired
private RestTemplate restTemplate;
@Override
public Order createOrder(Long productId,Long userId) {
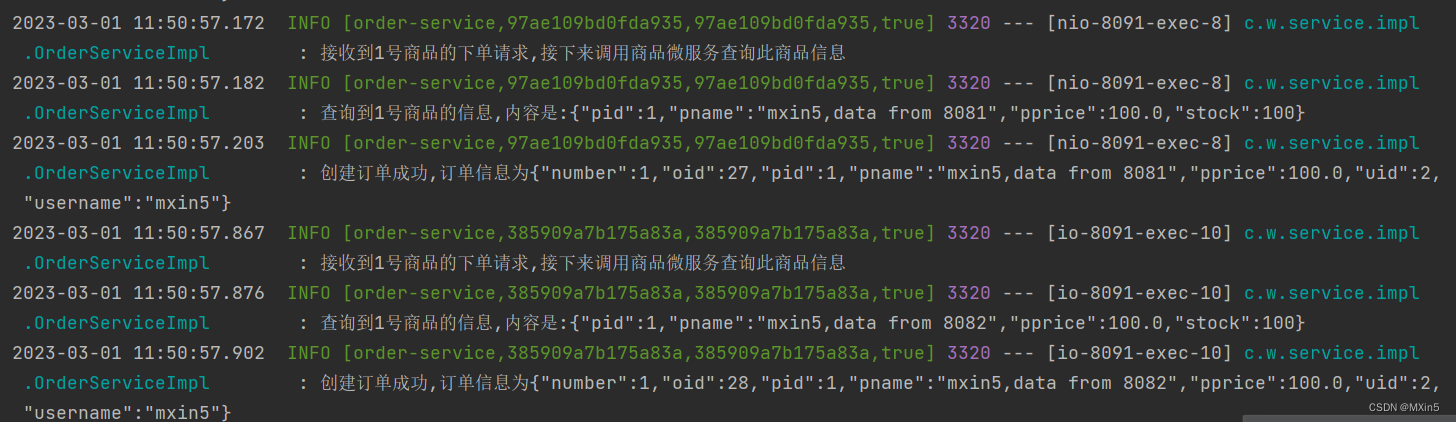
log.info("接收到{}号商品的下单请求,接下来调⽤商品微服务查询此商品信息",
productId);
//从nacos中获取服务地址
//⾃定义规则实现随机挑选服务
List<ServiceInstance> instances = discoveryClient.
getInstances("product-service");
int index = new Random().nextInt(instances.size());
ServiceInstance instance = instances.get(index);
String url = instance.getHost()+":"+instance.getPort();
log.info(">>从nacos中获取到的微服务地址为:" + url);
//远程调⽤商品微服务,查询商品信息
Product product = restTemplate.getForObject(
"http://"+url+"/product/"+productId,Product.class);
log.info("查询到{}号商品的信息,内容是:{}", productId,
JSON.toJSONString(product));
//创建订单并保存
Order order = new Order();
order.setUid(userId);
order.setUsername("mxin5");
order.setPid(productId);
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
orderDao.save(order);
log.info("创建订单成功,订单信息为{}", JSON.toJSONString(order));
return order;
}
}
3.基于Ribbon实现负载均衡
/**
* @LoadBalanced就可以实现负载均衡,原理就是一个标记,标记Resttemplate发出的请求要被我们的Ribbon进行拦截和处理
* */
@LoadBalanced
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}@Service
@Slf4j
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderDao orderDao;
@Autowired
private RestTemplate restTemplate;
@Override
public Order createOrder(Long productId,Long userId) {
log.info("接收到{}号商品的下单请求,接下来调⽤商品微服务查询此商品信息",
productId);
//远程调⽤商品微服务,查询商品信息
Product product = restTemplate.getForObject(
"http://product-service/product/"+productId,Product.class);
log.info("查询到{}号商品的信息,内容是:{}", productId,
JSON.toJSONString(product));
//创建订单并保存
Order order = new Order();
order.setUid(userId);
order.setUsername("叩丁狼教育");
order.setPid(productId);
order.setPname(product.getPname());
order.setPprice(product.getPprice());
order.setNumber(1);
orderDao.save(order);
log.info("创建订单成功,订单信息为{}", JSON.toJSONString(order));
return order;
}
}@RestController
@Slf4j
public class ProductController {
@Autowired
private ProductService productService;
@Value("${server.port}")
private String port;
//商品信息查询
@RequestMapping("/product/{pid}")
public Product findByPid(@PathVariable("pid") Long pid) {
log.info("接下来要进⾏{}号商品信息的查询", pid);
Product product = productService.findByPid(pid);
product.setPname(product.getPname()+",data from "+port);
log.info("商品信息查询成功,内容为{}", JSON.toJSONString(product));
return product;
}
}
Ribbon⽀持的负载均衡策略

product-service : # 调⽤的提供者的名称ribbon :NFLoadBalancerRuleClassName : com.netflix.loadbalancer.RandomRule # 轮询的方式
在上文的案例中我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
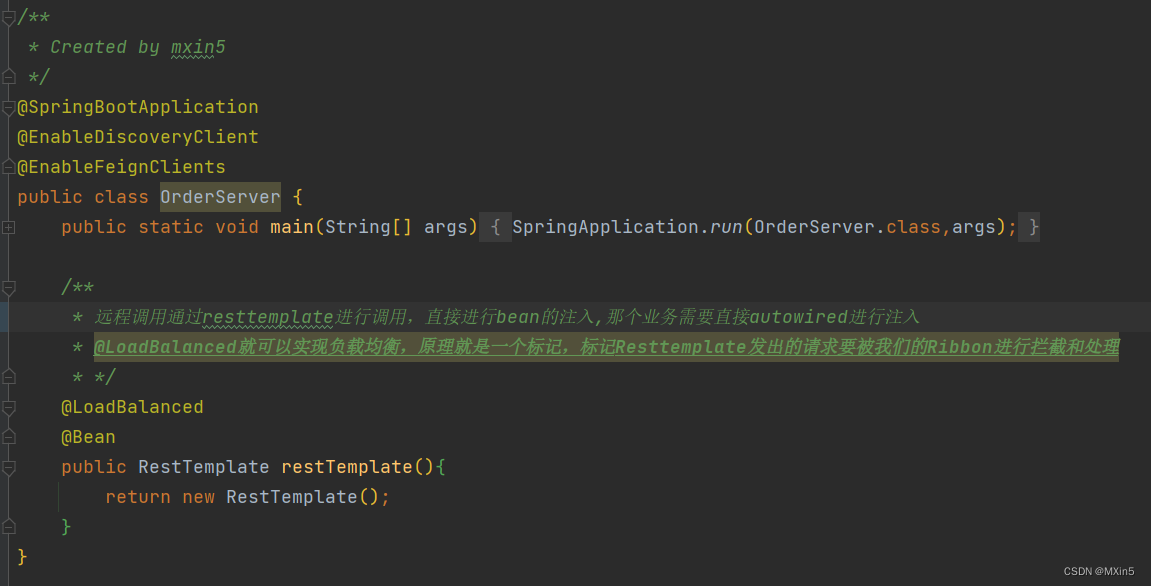
我们这里的@LoadBalanced相当于是一个标记,标记这个RestTemplate发出的请求要被我们的Ribbon拦截和处理。
4.负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081/user/1的呢?
源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
LoadBalancerIntercepor
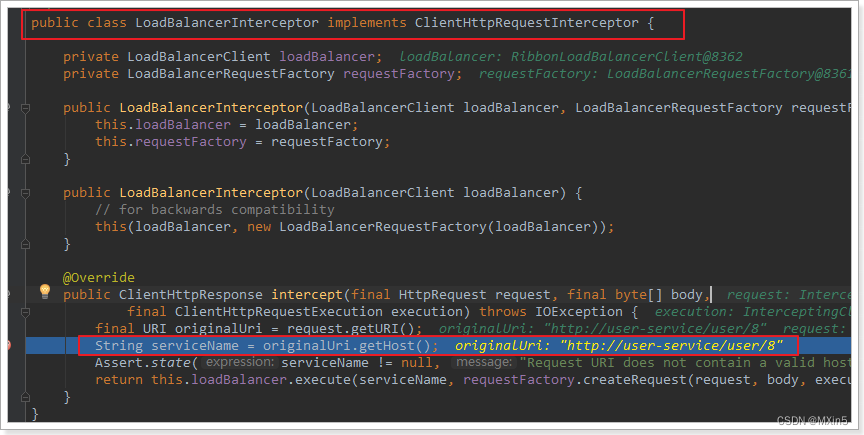
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是 http://user-service/user/8
originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-service
this.loadBalancer.execute():处理服务id,和用户请求。
这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
LoadBalancerClient
继续跟入execute方法:
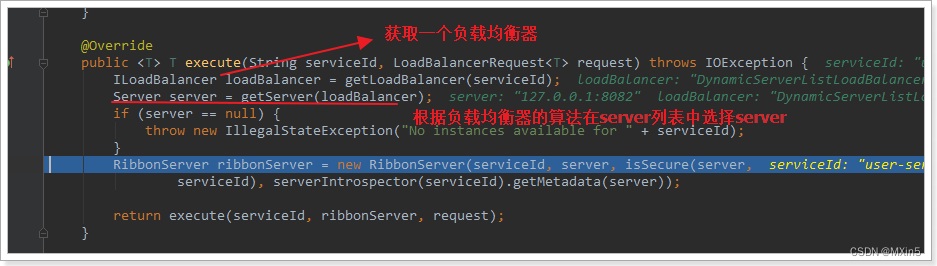
代码是这样的:
- getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。
- 我们在loadBalencer中可以看到拉取的服务列表;
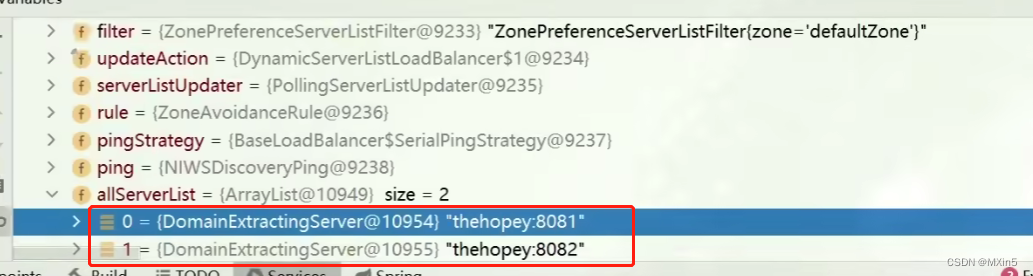
- getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。本例中,可以看到获取了8082端口的服务
放行后,再次访问并跟踪,发现获取的是8081:
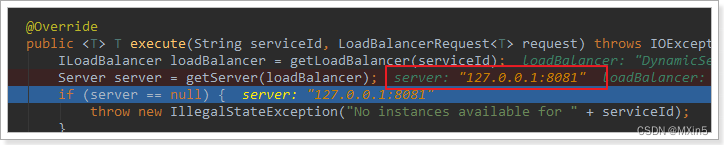
果然实现了负载均衡。
5.负载均衡策略IRule
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
我们继续跟入:

继续跟踪源码chooseServer方法,发现这么一段代码:

我们看看这个rule是谁:

这里的rule默认值是一个RoundRobinRule,看类的介绍:
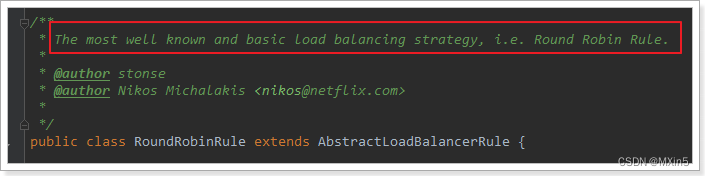
这不就是轮询的意思嘛。到这里,整个负载均衡的流程我们就清楚了。
总结
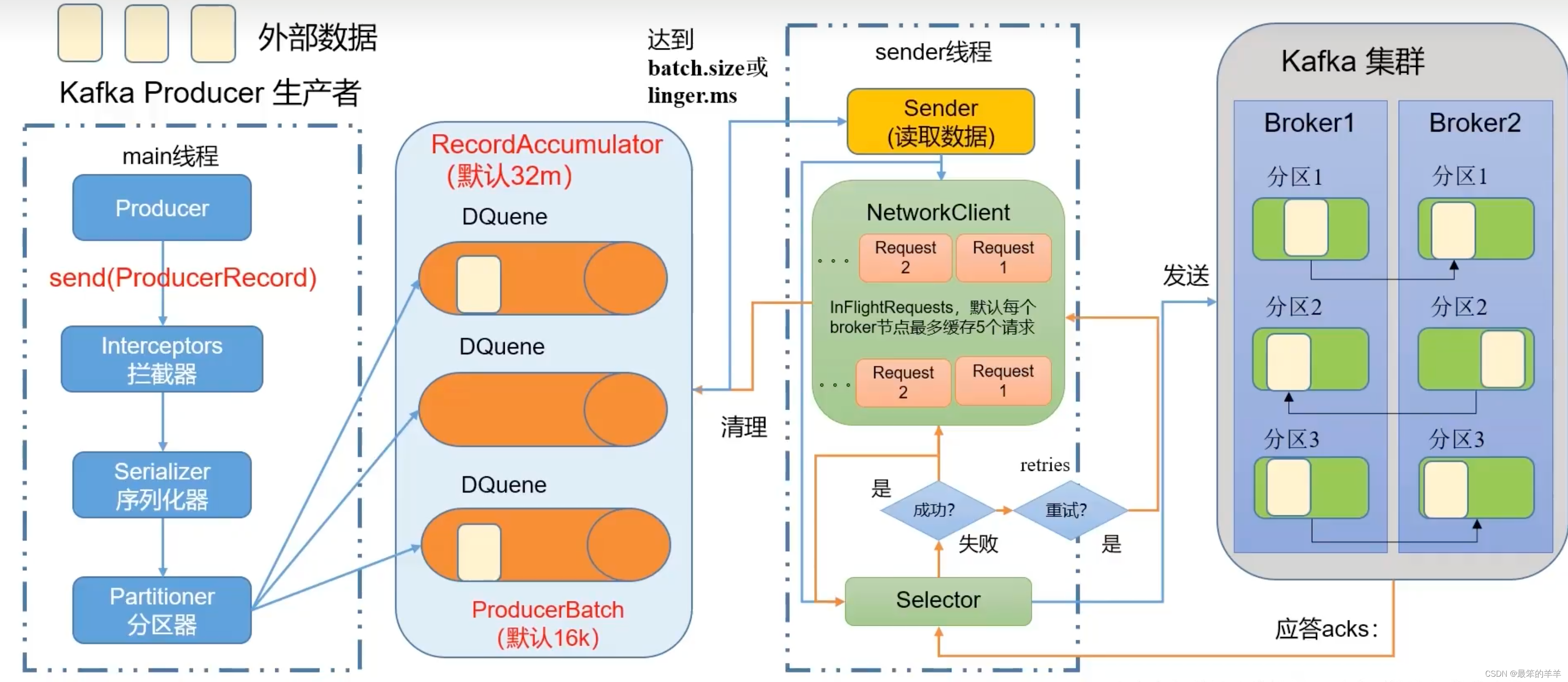
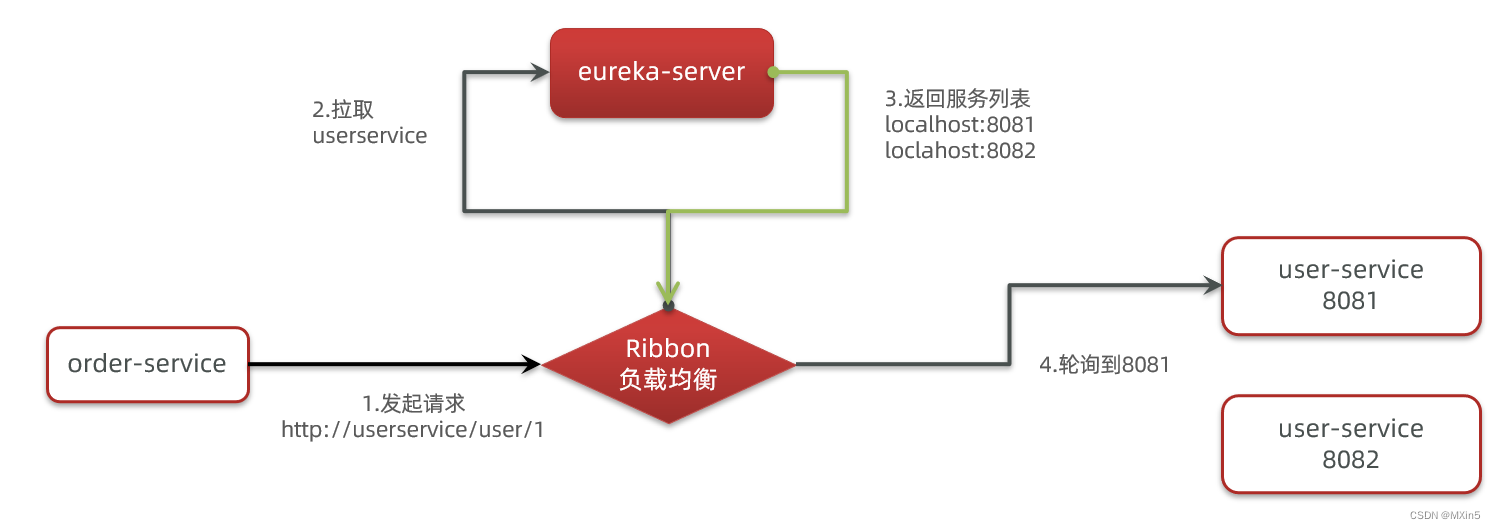
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
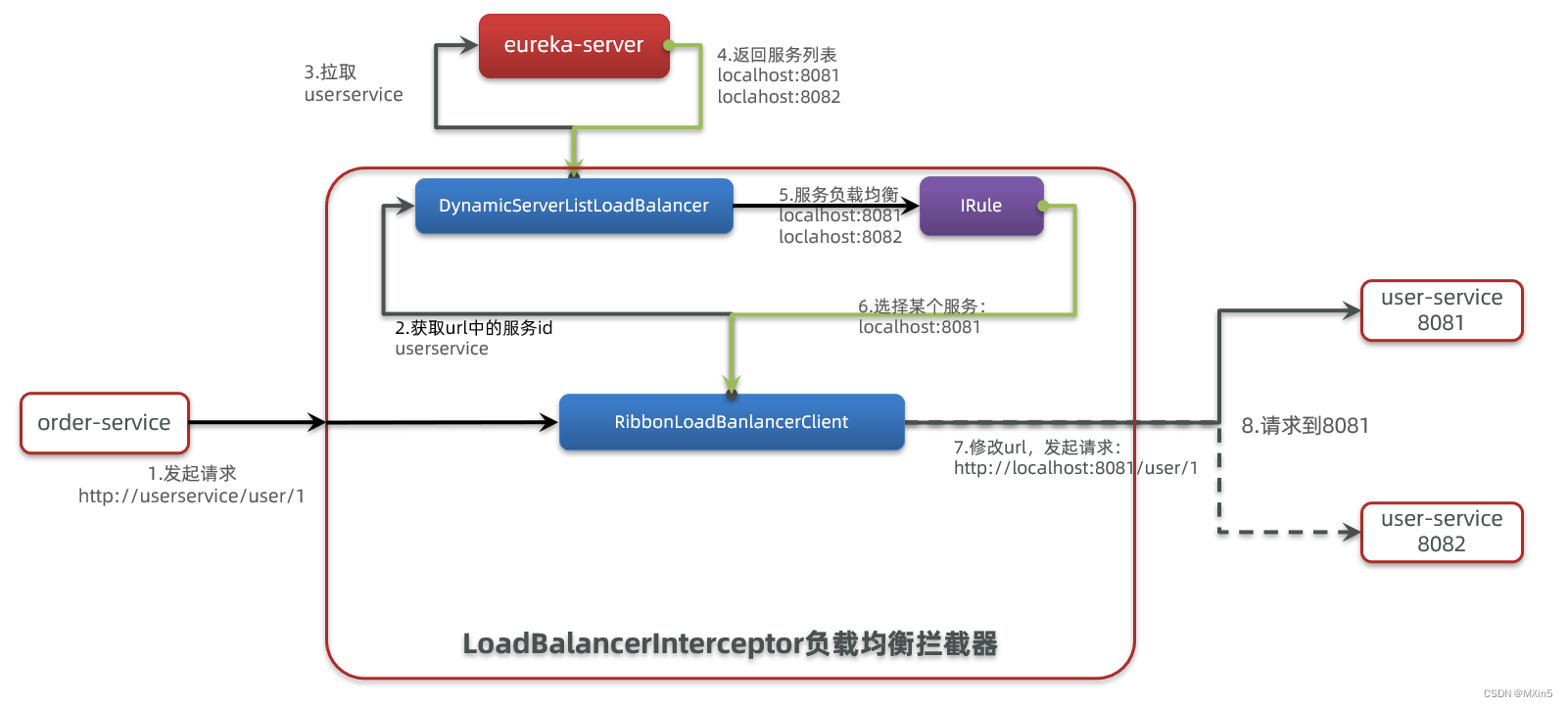
基本流程如下:
1.拦截我们的RestTemplate请求http://userservice/user/1
2.RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
3.DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
4.eureka返回列表,localhost:8081、localhost:8082
5.IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
6.RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求。