极兔一二面面经:
1. mysql的acid怎么实现的
这一点先回答ACID分别是A(原子性),C(一致性),I(隔离性),D(持久性), 其中持久性是数据库落磁盘的操作,无需额外实现.
隔离性是通过事务的隔离级别来实现, MySQL默认的隔离级别是RR(可重复读), 虽然上面还有一层Serializable(串行化), 但是在单机情况下,因为存在nextKeyLock, 所以单机的MySQL,RR级别就级别实现了串行化.
而RR底层则是通过MVCC来实现读取已提交的.
原子性是事务的要么都做要么都不做, 这个是通过redoLog和binLog的两阶段提交来实现的.
一致性是结果论, 就是代码运行的结果始终符合业务逻辑的期望, 而通过实现了原子性和隔离性, 再搭配持久化, 就可以得出一致性.
2. Spring的三级缓存说一下
Spring的三级缓存是用来解决循环依赖的, 我这里循序渐进的说一下:
使用一级缓存就可以解决单线程的循环依赖, 因为在单线程下, ABA依赖中, B依赖可以拿到半初始化的A依赖. 从而打破循环.
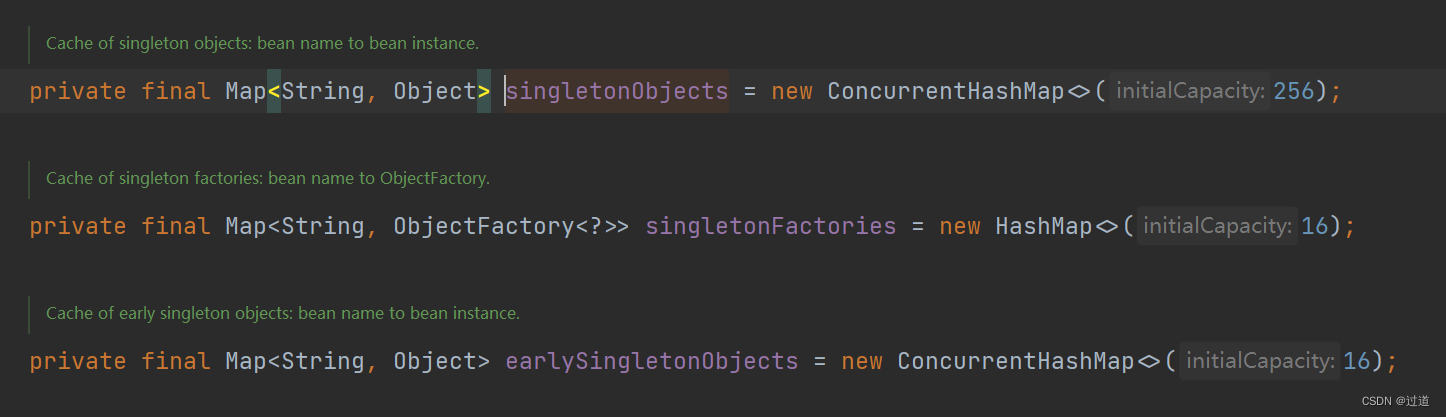
但是如果是多线程情况下,当A或者B没有初始化完成的时候, 有线程来访问, 就会得到一个没有初始化完成的对象, 比如A的B属性是null , 那么可能就会NullPointException, 为了避免这种情况, 我们需要二级缓存, 将初始化中的单例对象和完成的单例对象隔离. 这就是二级缓存.
Spring使用的三级缓存则是为了解决代理对象的问题. 因为Spring的第三层缓存存储的是ObjectFactory, 也就是生成bean方法的函数, 所以待生成的方法和已生成的代理对象需要隔离, 也就需要额外再加一层二级缓存.
3. Spring的三级缓存的实现容器是什么?
一级缓存是CHM, 二级缓存和三级缓存是HashMap, 这是因为二级和三级的存取都是在Sync锁里的, 所以不需要CHM, 而一级缓存是对外提供的需要保证线程安全性.
当然在我用的新版里面二级缓存因为在getSingleton里用了doubleCheck, 所以也需要保证线程安全性, 也改为了CHM了.
4. InnoDB和MyISAM的存储结构上的区别
太简单,不写了.
5. Synchronize和ReentrantLock的区别, 性能区别呢?
Sync锁是Java原生的并发锁, 主要是通过MonitorEnter和MonitorExit实现,锁在方法上则是通过给方法的flag增加一个标识. 而 Lock则是通过AQS, CAS,volatile等来实现的锁.
锁静态方法的锁是类对象, 普通方法上是实例对象, 锁代码块是实例对象, Lock锁则是锁的传入的对象.
Sync锁是升级锁,也就是自适应锁, Lock支持的情况更多元, 包括超时锁, 公平锁等情况,使用起来更加灵活.
6. 存在Sync锁的降级吗?
锁一旦升级只有释放, 没有降级, 锁的释放不是降级. 严格来说再Stop the world的时候存在, 但是基本上可以忽视.
7. mq消息堆积了怎么办?
MQ消息堆积的原因很简单: 生产者速度>消费者, 这时候我们有三种方案:
- 加快消费者处理速度,
- 加硬件, 加软件,优化性能瓶颈
- 减慢生产者处理速度
- 熔断,降级,
- 加大队列存储量,避免死信
- 使用惰性队列, 就是将队列溢出的信息持久化, 当然会降低时效性.
8. redis有哪些类型, 你用过那些对应的场景
五大基本类型分别是:
String, 这个是最常用的, 我用过存token,
Hash, 自增器(阅读量,点赞数. 定时写入数据库)
List : 时间轴. 比如按更新时间排序, 更新时间我们没上索引, 就是直接在Redis中存储了最近的1000条数据.
Set: 抽奖.
zSet : 排行榜
三大进阶类型:HyperLogLog, Geo、BloomFilter
9. 介绍下跳表
太简单,不写了.
10. Redis分布式有哪些架构? 分别什么特点?
Redis 主从架构, 一般都是读写分离的, 可靠性不足, 无法自动完成主从切换.
Redis Sentinal 哨兵架构, 可以监控Redis节点, 能够故障自动迁移.
Redis Cluster 集群架构, 可以去中心化, 能够实现故障自动迁移, 数据分片. 并且优化了哨兵迁移时的连接中断问题.
11. Redis 分布式锁了解吗? 如何提升分布式锁的性能? 如何保证分布式下分布式锁失效的问题 ?
- Redis 分布式锁主要时为了解决多实例应用下, 实例之间的并发不安全问题, 比如库存超卖问题.
通过将锁放在Redis中, 保证实例, 线程之间是并发安全的. 实现分布式锁的命令是setnx, 在Java中我们往往不会选用原生的Redis去实现分布式锁, 因为需要考虑的事情太多, 比如超时问题,加锁与解锁的原子性问题.
在开发中,我们使用Redisson来解决分布式锁, 它自带超时补偿机制解决超时问题, 使用Lua脚本解决锁操作的原子性问题. - 分布式锁的性能在于把原来并行的线程编程了串行化的命令, 这就带来了性能问题, 这种情况一般分两种思路并行处理: 1. 降低锁的粒度, 减少需要锁的时间; 2. 采用CHM的分段锁, 比如库存拆分成多份库存.
- Redisson能保证代码级别的正确性, 但是因为Redis集群满足的是AP, 那么就会存在宕机后的不一致问题, 这种情况, 可以考虑采用ZK集群来替换Redis集群, 或者使用RedLock降低性能, 手动给半数以上的Redis发送setnx命令.
12. redis哨兵选举机制
先到先得, Redis哨兵负责监控所有Redis节点的状态, 当某台哨兵发现某节点连接超时, 会对其进行主观下线, 并通知给其他哨兵, 当半数哨兵都对其主观下线, 就会触发客观下线, 从从节点中选举新的主节点.
选举主节点的过程第一步是哨兵先选举出一个leader来做这个事情, 这个leader选举算法如下:每个节点以自己收到的第一个申请为准, 最终判断leader哨兵.
leader哨兵再去除故障节点后, 按照优先顺序, 复制区的偏移量大小, runId找到目标从节点, 将其变为主节点.
13. 缓存雪崩,缓存击穿,缓存穿透分别是什么?

大量数据同时过期导致的缓存雪崩解决方案:
- 均匀设置过期时间, 在原来的过期时间上加一些随机数.
- 互斥锁, 就是让第一个没有拿到缓存的数据设置一个超时锁, 然后再去数据库更新缓存, 这样之后的请求就会阻塞在超时锁上, 而不是打崩数据库.
- 双 key 策略, 就是设置一个超时变量, 一个不超时的变量, 更新的时候同时维护这两份. 相当于熔断操作.
- 后台更新缓存, 长期有效, 交由后台更新缓存数据, 此外为了避免缓存被LRU淘汰后失效 ,还需要定期刷缓存, 或者业务线程发现后通过MQ通知刷新缓存. 后者效果更好一些.
Redis 宕机的处理
- 搭建高可用集群, 主要是为了故障切换, 减少宕机带来的影响
- 熔断或者限流访问数据库.
缓存击穿:
缓存击穿是缓存雪崩的一个子集, 解决方案主要是互斥锁 or 双key or长期有效,后台更新
缓存穿透:
- 布隆过滤器来处理, 此处不再展开.
- 非法请求的限制.
- 缓存空值或者默认值.
14. Redis的大key,会有问题
大key并不是指的key很大, 往往出现的都是value过大, 因为key的大小在我们开发中是能预料到的, 格式都是我们自己定义的, 但是value可能往往欠缺考虑.
常见的大key有:
- String的size>10kb;
- zSet, Set,List,Hash等,成员数量超过1w个;
带来的影响主要是:
- 当前命令耗时增加,甚至超时
- 大key的存在会导致分布式系统中分片数据不平衡, CPU使用率也不平衡.
- 阻塞线程,并发量下降,导致客户端超时,服务端业务成功率下降。
压缩和拆分key
- 当vaule是string时,比较难拆分,则使用序列化、压缩算法将key的大小控制在合理范围内,但是序列化和反序列化都会带来更多时间上的消耗。
- 当value是string,压缩之后仍然是大key,则需要进行拆分,一个大key分为不同的部分,记录每个部分的key,使用multi, get等操作实现事务读取。
- 当value是list/set等集合类型时,根据预估的数据规模来进行分片,不同的元素计算后分到不同的片。
Redis 4.0以前大key删除
4.0 以前 string,list,set,hash 不同数据类型的大 key,删除方式有所不同。一般有两种情况:del 命令删除单个很大的 key 和 del 批量删除 大 key。直接 del 命令粗暴的删大 key 容易造成 redis 线程阻塞。4.0 以前要优雅的删除就是针对不同的类型 写脚本,拆分链表,hash 表,分批删除。
6.2 Redis 4.0 以后优雅的删除大 key
- 主动删除
UNLINK xxxkey
unlink 命令是 del 的异步版本,由 Lazyfree 机制实现。Lazyfree 机制的原理是在删除的时候只进行逻辑删除,把 key 释放操作放在 bio (Background I/O)单独的子线程中惰性处理,减少删除大 key 对 redis 主线程的阻塞,有效地避免因删除大key带来的性能问题。unlink 即使在批量删除 大 key 时,也不会对阻塞造成阻塞。 - 被动删除
被动删除是指 Redis 自身的 key 清除策略,一个 大 key 过期或者被淘汰时,如何被清除,会不会导致阻塞?4.0 以前自动清除是有可能阻塞主线程的。
4.0 以后的版本,被动删除策略是可选的配置参数,允许以 Lazyfree 的方式清除。但是参数默认是关闭的,可配置如下参数开启。
lazyfree-lazy-expire on # 过期惰性删除
lazyfree-lazy-eviction on # 超过最大内存惰性删除
lazyfree-lazy-server-del on # 服务端被动惰性删除
7. sql优化和分库分区分表如何做的
太常见,不说了
8. mysql死锁怎么解决
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
设置事务等待锁的超时时间。当一个事务的等待时间超过该值后,就对这个事务进行回滚,于是锁就释放了,另一个事务就可以继续执行了。在 InnoDB 中,参数 innodb_lock_wait_timeout 是用来设置超时时间的,默认值时 50 秒。
开启主动死锁检测。主动死锁检测在发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑,默认就开启。
尽量降低锁的范围.
- 尽量让数据表中的数据检索都通过索引来完成,避免无效索引导致行锁升级为表锁。
- 尽量减少查询条件的范围,尽量避免间隙锁或缩小间隙锁的范围。
- 尽量控制事务的大小,减少一次事务锁定的资源数量,缩短锁定资源的时间。
- 如果一条SQL语句涉及事务加锁操作,则尽量将其放在整个事务的最后执行。 尽可能使用低级别的事务隔离机制。
9. es和mysql如何同步
- 双写。在代码中先向Mysql中写入数据,然后紧接着向Es中写入数据。这个方法的缺点是代码严重耦合,需要手动维护Mysql和Es数据关系,非常不便于维护。
- 发MQ,异步执行。在执行完向Mysql中写入数据的逻辑后,发送MQ,告诉消费端这个数据需要写入Es,消费端收到消息后执行向Es写入数据的逻辑。
优点是Mysql和Es数据维护分离,开发Mysql和Es的人员只需要关心各自的业务。
缺点是依然需要维护发送、接收MQ的逻辑,并且引入了MQ组件,增加了系统的复杂度。 - 基于Mysql表定时扫描同步。使用Datax进行全量数据同步
这个方式优点是可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。
缺点是Datax是一种全量同步数据的方式,不使用实时同步。如果系统对数据时效性不强,可以考虑此方式。 - 基于Binlog实时同步。使用Canal进行实时数据同步
各自只需要关心自己的业务,对代码侵入性几乎为零。
与Datax不同的是: Canal是一种实时同步数据的方式,对数据时效性较强的系统,我们会采用Canal来进行实时数据同步。
canal工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 bin log 给 slave (即 canal )
canal 解析 bin log 对象(原始为 byte 流)
最终推荐使用canal, 将ES伪装成MySQL的一个从库, 同步binLog数据到ES
十万数据,代码处理会频繁gc,数据库处理会深度分页,如何解决
我不会
ES的聚合查询会降低速度吗?
我不会
线下面试,差评, 不过是一口气一二面+HR面(我没过二面,所以没到HR面)
结果: 没过.


![[RDMA-高级计算机网络report] Congestion Control for Large-Scale RDMA Departments](https://img-blog.csdnimg.cn/img_convert/31c56991c60cecf226be33794ab9a43b.png)