点击查看题目详情
- 大思路:
创建哈希表,元素类型为<char, int>,分别是字符与其对应下标
用哈希表来存储未重复的子串,若有重复则记录下当前子串最大值maxhashsize
并且开始以相同方法记录下一子串
遍历完成以后,哈希表里记录的maxhashsize,也就是题目所需
如果没重复就一直遍历
当遇到了重复值,就进行新子串的长度计算
- 细节处
hashsize代表当前子串长度,start代表哈希表非重复子串的起点,i是遍历下标
值得注意的一点是,由于这种方法不像官解需要删除哈希表内容
所以当遇到重复的字符时,只需将下标与哈希表内重复字符的下标替换之
并且此时开始计算新子串的长度
例如a(0) b c a(3) b c d:()内代表对应下标
遍历到a(3)时,此时哈希表内已有:a(0) b c
需要进行的操作是将a(3)存入哈希表,其实就是将其下标存入,得到:a(3) b c
- 避免重复遍历/新字串的长度如何算
为了避免重复比较,走完a(0) b c以后,遇到重复值a(3)可以直接将子串的初始值赋值为a(0)-a(3)之间的字符个数;这样b c a(3)就不会重复比较了。因为a(0)-a(3)之间肯定没有重复的值,所以直接将其长度记录下来即可,就相当于跳过了这一段的遍历。
然后此时的的长度就是新子串的初始值,比如上例的b开始遇到第二个b的时候,其长度为3,那其实按照刚才的方法来说,就是下标:b(1)-b(4) = 3;如果没有遇到重复值,就在这个初始值的基础上一直++即可。
要实现这一点,要保证起点start与字符内存的value下标要正确
例如遍历完a2后,哈希表里面存的就是a(3) b(1) c(2),而不是a(0) b(1) c(2)
后续再碰到a的时候,就用当前i减去start就是新子串长度
因为上述表达式应该解释为:hashsize = i - start;
- 两个情况计算start
再要注意的一点,并不是每次的start都是哈希表存的重复值的下标
比如上例的a重复,其下标0就是start。或者b重复,其下标就是1就是start;这种是从某个字符(a(0))开始,到该字符结束(a(3))
而这种情况:a b c a d e(5) f e(7) ---- 从某个字符(b)开始,到另一字符(e(7))结束
当遍历到e(7)的时候,start是b的下标1
但是此时的e(5)下标是5,那此时的新字串(e(5)至f)的长度,总不能是e(7)-b(1)吧?
所以此时新字符串的初始值应该是e(7)-e(5)
那么根据上述两种情况,可知start的坐标是需要比较出来的:start = max(hashtable[s[i]],start)
在本例中,这里的hashtable[s[i]]就是e(5),star就是b(1)
也就是说判断e(5)的下标和此时的start谁大
更新了start后,新字符串的初始值为hashsize = i - start
这里的i其实就是e2的下标,那么上式也就是e2-e1
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<char,int> hashtable;
int hashsize = 0;//哈希表的长度
int start = 0;//哈希当前的起点,用于计算子串长度
int maxhashsize = 0;//哈希表最长长度
for(int i = 0;i < s.size();i++){
if(hashtable.find(s[i]) == hashtable.end()){
//未找到重复值
//将其存入哈希表
hashsize++;
hashtable[s[i]] = i;
}else{
//找到重复值,说明已经开始遍历下一个子串
//1.比较新旧哈希表的长度,得出maxhashsize
//2.更新哈希表的起点start
//3.更新hashsize为下一个字串的长度
//4.更新哈希表里重复值的下标
maxhashsize = hashsize>maxhashsize?hashsize:maxhashsize;
start = max(hashtable[s[i]],start);
hashsize = i - start;
hashtable[s[i]] = i;
}
}
//一条路走到黑的情况
maxhashsize = hashsize>maxhashsize?hashsize:maxhashsize;
return maxhashsize;
}
};
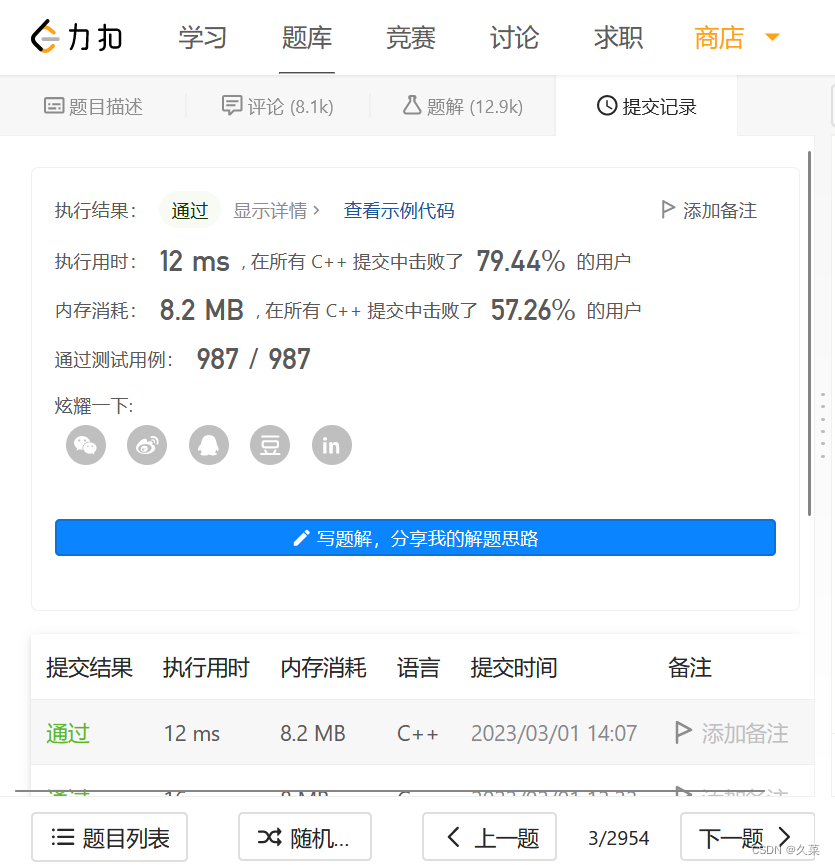
运行结果:
![[RDMA-高级计算机网络report] Congestion Control for Large-Scale RDMA Departments](https://img-blog.csdnimg.cn/img_convert/31c56991c60cecf226be33794ab9a43b.png)