MobileNet V1
- 1、简介
- 2、Depthwise Separable Convolution
- 1)Depthwise Separable Convolution 的优点
- 2)Depthwise Separable Convolution 网络结构
- 3)pytorch 函数 实现 depth-wise convolution
- 2、Mobile 网络结构
- pytorch实现 Mobile 网络结构(benchmark)
- 3、超参数 α: Width Multiplier
- 4、超参数 β:Resolution Multiplier
文献名称: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
下载地址:https://arxiv.org/pdf/1704.04861.pdf
1、简介
1、MobileNets 基于流线型架构:流线型架构指的是像vgg那样,数据从头流到尾,没有resnet或desnet的那种跨层连接结构
2、使用深度可分离卷积(depthwise separable convolutions)来构建轻量级深度神经网络,在 损失一定的accuracy 的情况下,极大程度的减小了网络的计算量,适用于 计算能力较小的 移动应用 和 嵌入式应用。
3、该网络引入了两个简单的全局超参数:宽度乘数和分辨率乘数,可以有效地在 延迟(latency) 和 准确性(accuracy) 之间进行权衡。这些超参数允许模型构建者根据问题的限制条件为其应用程序选择合适大小的模型。
\quad \quad \quad
- α(宽度乘数 Width Multiplier)
\quad \quad \quad
- β(分辨率乘数 Resolution Multiplier)
以上标黄的就是 MobileNet 的重点,我们下面详细讲解。
2、Depthwise Separable Convolution
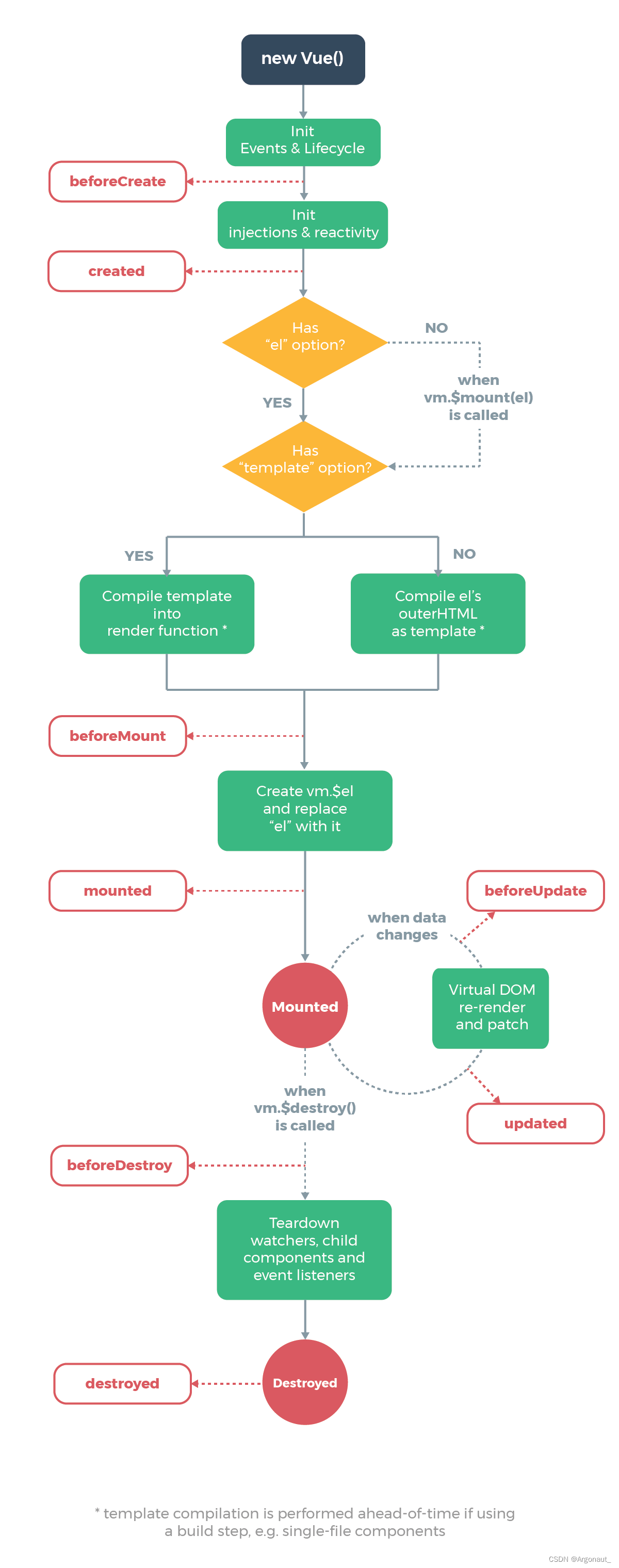
Mobile Net 是基于 Depthwise Separable Convolution 建立的,Depthwise Separable Convolution 是一种可分解的卷积的形式,它可以将 标准卷积 分解为 depth-wise卷积 和 point-wise卷积 (conv 1×1)
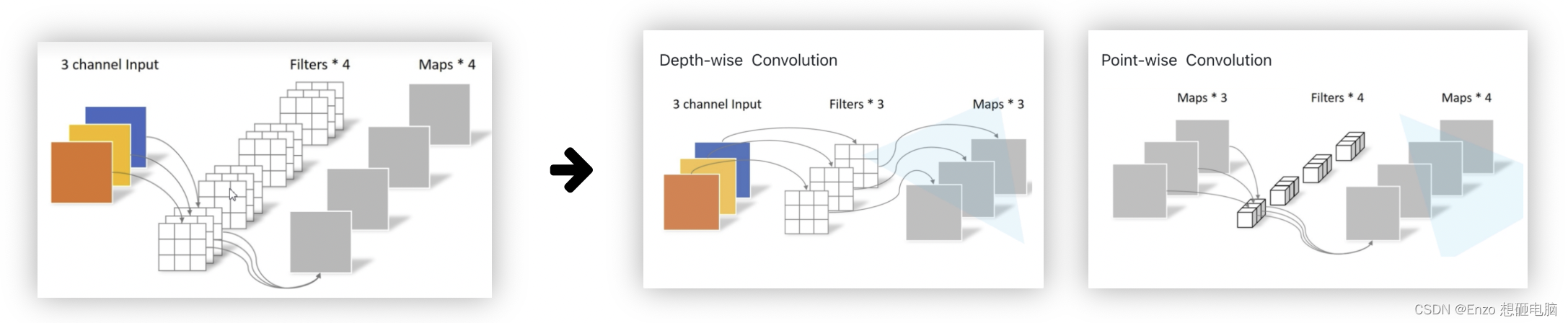

1)Depthwise Separable Convolution 的优点
这种因式分解大大减少了计算量和模型大小。
假设 输入图像的高宽皆为
D
F
D_F
DF, 通道数为
M
M
M; filter 的高宽皆为
D
K
D_K
DK,通道数也为
M
M
M, 个数为
N
N
N个
在 padding=same,stride=1 的情况下,也就是输出图像尺寸和输入图像尺寸一样,为
(
D
F
,
D
F
)
(D_F,D_F)
(DF,DF) 的情况下,
做一次 标准卷积的计算量是:
D
F
∗
D
F
∗
M
∗
N
∗
D
K
∗
D
K
D_F * D_F * M * N * D_K * D_K
DF∗DF∗M∗N∗DK∗DK
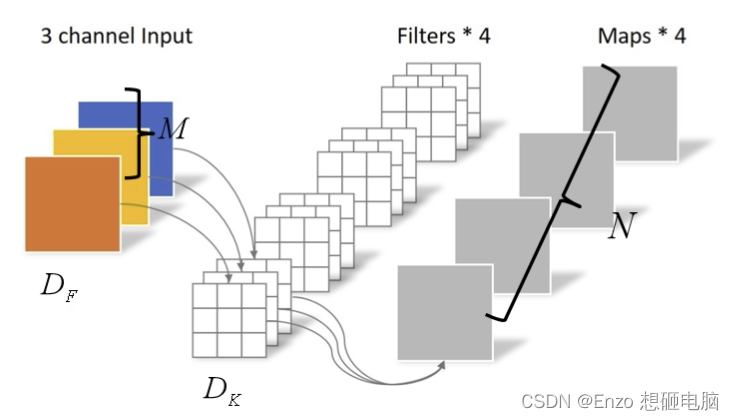
而达到相同输出尺寸效果,做一次 Depthwise Separable Convolution 需要的计算量是: D F ∗ D F ∗ M ∗ D K ∗ D K + M ∗ N ∗ D F ∗ D F D_F * D_F * M * D_K * D_K + M * N * D_F * D_F DF∗DF∗M∗DK∗DK+M∗N∗DF∗DF。 其中:
- D F ∗ D F ∗ M ∗ D K ∗ D K D_F * D_F * M * D_K * D_K DF∗DF∗M∗DK∗DK 是 depth- wish convolution 部分的计算量
- M ∗ N ∗ D F ∗ D F M * N * D_F * D_F M∗N∗DF∗DF是 point-wis convolution 部分的计算量

我把2种方式的计算量相除一下:( Mobile Net 基本上用的都是 filter=3*3 的 depth-wise conv,即
D
K
2
=
3
D_K^2=3
DK2=3 )
D
e
p
t
h
w
i
s
e
S
e
p
a
r
a
b
l
e
C
o
n
v
o
l
u
t
i
o
n
的计算量
标准卷积的计算量
=
D
F
∗
D
F
∗
M
∗
D
K
∗
D
K
+
M
∗
N
∗
D
F
∗
D
F
D
F
∗
D
F
∗
M
∗
N
∗
D
K
∗
D
K
=
1
N
+
1
D
K
2
=
1
N
+
1
9
\frac{Depthwise\ Separable\ Convolution 的计算量}{标准卷积的计算量} \\ \ \\ = \frac{D_F * D_F * M * D_K * D_K + M * N * D_F * D_F}{D_F * D_F * M * N * D_K * D_K} \\ \\ \ \\ = \frac{1}{N} +\frac{1}{D_K^2} \\ \ \\ = \frac{1}{N} +\frac{1}{9}
标准卷积的计算量Depthwise Separable Convolution的计算量 =DF∗DF∗M∗N∗DK∗DKDF∗DF∗M∗DK∗DK+M∗N∗DF∗DF =N1+DK21 =N1+91
所以,可以发现,Depthwise Separable Convolution 的计算量是 标准卷积计算量的 1/8 ~ 1/9 左右,计算量小好多,这样模型速度也会快很多。然而,这样的操作,会使 accuracy 有一定的下降,下降有,但不多。
2)Depthwise Separable Convolution 网络结构
- 左边是标准的卷积网络结构(一个 3x3 的卷积曾后面跟一个 BN层和ReLU层),
- 右边是Depthwise Separable Convolution 网络结构,先是一个 depth-with 卷积层,后面跟 BN层和ReLU层,再是一个 point-with 卷积层,再跟 BN层和ReLU层。

3)pytorch 函数 实现 depth-wise convolution
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
如上就是 pytorch 的卷积函数,要做 depth-wise 卷积的话,重点就在参数 groups
- 标准常规卷积时,
group=1,意思是将输入分为一组。 - 当将其设为
groups=in_channels时,意思是将输入的每一个通道作为一组,然后分别对其卷积,再将每组的输出concat,最后输出通道数等于输入通道数。举例如下:
nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=0, groups=in_channels, bias=False)
2、Mobile 网络结构

pytorch实现 Mobile 网络结构(benchmark)
pytorch 的模型实现:github 地址
3、超参数 α: Width Multiplier
虽然 MobileNet 架构已经很小,且延迟很低,但很多时候特定的场景或应用程序可能需要模型更小更快。为了构造这些更小、计算成本更低的模型,作者引入了一个非常简单的参数 - 宽度乘数 α \alpha α 。
宽度乘数 α \alpha α 的作用是在每一层上均匀地薄化网络,也就是每一层都按比例 α \alpha α 减小 channel 数量。比如,之前,上一层的输出 channel 为 M,输出 channel 为 N;那么现在使用 宽度乘数 α \alpha α,上一层的输出 channel 为 α \alpha αM,输出 channel 为 α \alpha αN。 这样的话,参数 数量大概是之前的 α 2 \alpha^2 α2。计算量为: D F ∗ D F ∗ α M ∗ D K ∗ D K + α M ∗ α N ∗ D F ∗ D F D_F * D_F * \alpha M * D_K * D_K + \alpha M * \alpha N * D_F * D_F DF∗DF∗αM∗DK∗DK+αM∗αN∗DF∗DF
α \alpha α 的取值一般为 : 1, 0.75, 0.5, 0.25
4、超参数 β:Resolution Multiplier
分辨率乘数
β
\beta
β 是用来减小图像尺寸的, 一般使用
β
\beta
β 将图像缩小为 (32的倍数):224, 192, 160 or 128。
这样,参数数量大概是之前的
β
2
\beta^2
β2, 计算量为:
β
D
F
∗
β
D
F
∗
M
∗
D
K
∗
D
K
+
M
∗
N
∗
β
D
F
∗
β
D
F
\beta D_F * \beta D_F * M * D_K * D_K + M * N * \beta D_F * \beta D_F
βDF∗βDF∗M∗DK∗DK+M∗N∗βDF∗βDF
![[数据结构]:07-二叉树(无头结点)(C语言实现)](https://img-blog.csdnimg.cn/c03810c0ee5a4796b7c06d9dd88cdce8.png)