【MinIO】文件断点续传和分块合并
文章目录
- 【MinIO】文件断点续传和分块合并
- 0. 准备工作
- 1. 检查文件是否存在
- 1.1 定义接口
- 1.2 编写实现方法
- 2. 检查分块文件是否存在
- 2.1 定义接口
- 2.2 编写实现方法
- 3. 上传分块文件接口
- 3.1 定义接口
- 3.2 编写实现方法
- 4. 合并分块文件接口
- 4.1 定义接口
- 4.2 编写实现方法
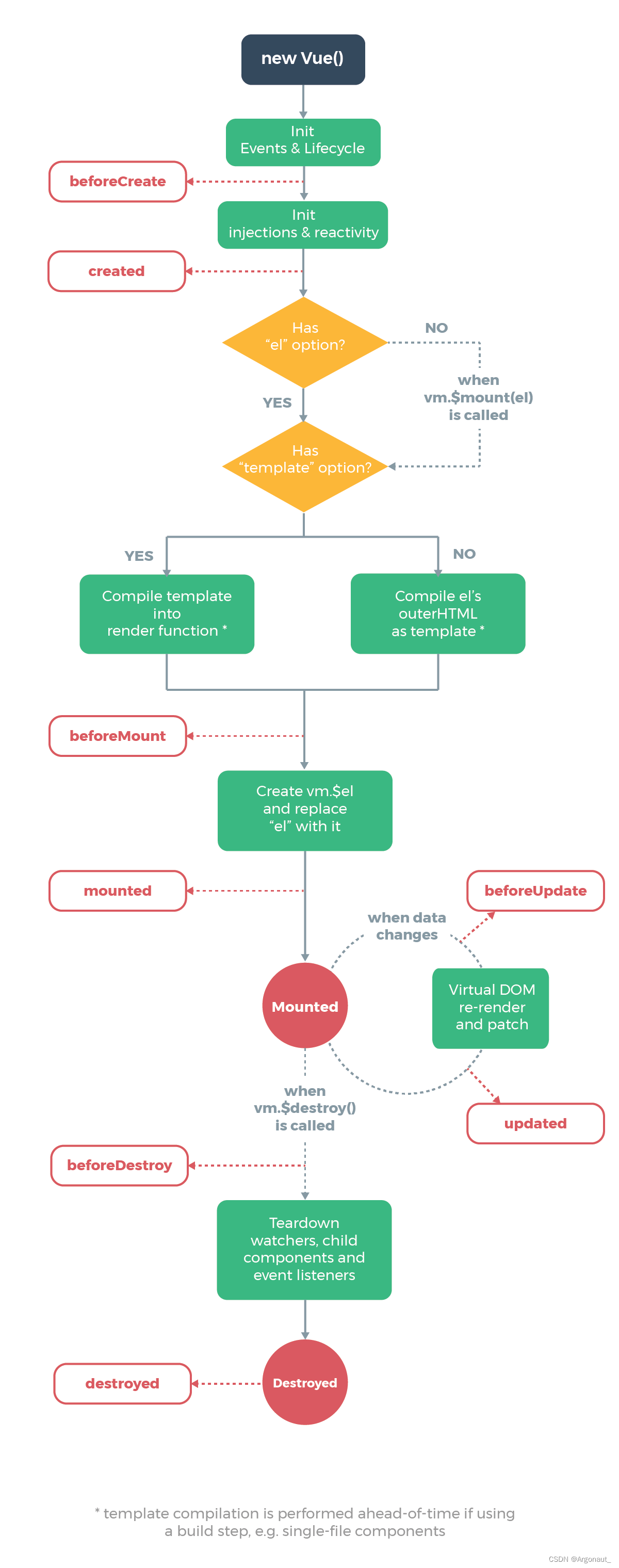
下图是上传视频的整体流程:
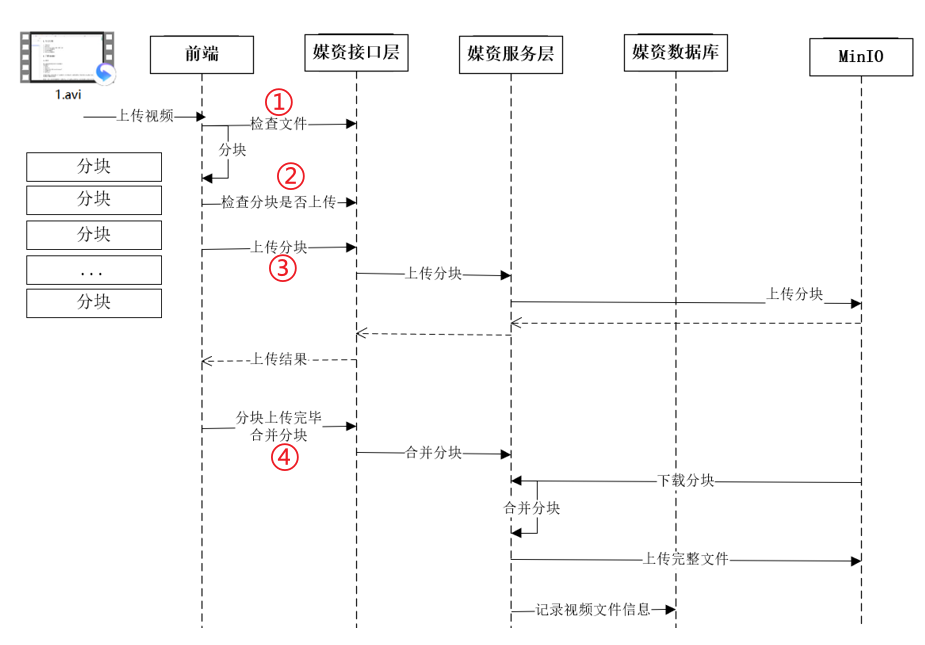
由图可知,我们需要在前端定义四个接口。
- 检查文件是否存在接口
- 检查分块文件是否存在接口
- 上传分块文件接口
- 合并分块文件接口
0. 准备工作
编写一个配置类,向Spring容器中注入一个minio客户端。
@ConfigurationProperties(prefix = "minio")
@Data
public class MinioConfig {
private String endpoint;
private String accessKey;
private String secretKey;
@Bean
public MinioClient minioClient() {
MinioClient minioClient =
MinioClient.builder()
.endpoint(endpoint)
.credentials(accessKey, secretKey)
.build();
return minioClient;
}
}
1. 检查文件是否存在
1.1 定义接口
@ApiOperation(value = "文件上传前检查文件")
@PostMapping("/upload/checkfile")
public RestResponse<Boolean> checkfile(@RequestParam("fileMd5") String fileMd5) throws Exception {
return mediaFileService.checkFile(fileMd5);
}
1.2 编写实现方法
检查文件是否存在,必须同时满足两个条件:
- 在数据库的文件表中存在记录
- 在文件系统中存在文件
只有满足以上两个条件才表示文件存在,任何一项不满足都将返回false。
@Override
public RestResponse<Boolean> checkFile(String fileMd5) {
//在数据库中存在并且文件系统中也存在,才说明真的才存在
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
return RestResponse.success(false);
}
//查看是否在文件系统存在
GetObjectArgs getObjectArgs = GetObjectArgs.builder().bucket(mediaFiles.getBucket()).object(mediaFiles.getFilePath()).build();
try {
InputStream inputStream = minioClient.getObject(getObjectArgs);
if (inputStream == null) {
//文件不存在
return RestResponse.success(false);
}
} catch (Exception e) {
e.printStackTrace();
return RestResponse.success(false);
}
return RestResponse.success(true);
}
2. 检查分块文件是否存在
2.1 定义接口
@ApiOperation(value = "分块文件上传前的检测")
@PostMapping("/upload/checkchunk")
public RestResponse<Boolean> checkchunk(@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
return mediaFileService.checkChunk(fileMd5, chunk);
}
2.2 编写实现方法
想要查询分块文件是否在文件系统中,我们必须要指导分块文件所在的路径。
如果将所有的文件都存在同一个目录,将会导致IO效率低下。所以我们应该尽可能使文件分撒存储在不同目录(同一个文件的分块文件还得在同一目录下)。
我们指定一个规则:
假设一个文件的MD5值为:1374c8160ea2da8dd33208a9ad369641,那么我们就取第一个数为一级目录的名字,取第二个数为二级目录的名字。那么这个文件的分块文件都存在 video/1/3/1374c8160ea2da8dd33208a9ad369641/chunk 目录下,源文件存储在 video/1/3/1374c8160ea2da8dd33208a9ad369641 目录下。
根据这一个规则,我们可以编写一个获得分块文件所在目录的方法:
//得到分块文件的目录
private String getChunkFileFolderPath(String fileMd5) {
//将文件MD5值的第一位数作为一级目录,第二位数作为二级目录
return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/" + "chunk" + "/";
}
接着编写检查分块文件是否存在的方法:
如果存在则返回true,不存在都返回false。
@Override
public RestResponse<Boolean> checkChunk(String fileMd5, int chunkIndex) {
//得到分块文件所在目录
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
//分块文件的路径
String chunkFilePath = chunkFileFolderPath + chunkIndex;
//查看是否在文件系统中存在
GetObjectArgs getObjectArgs = GetObjectArgs.builder().bucket(bucket_videofiles).object(chunkFilePath).build();
try {
InputStream inputStream = minioClient.getObject(getObjectArgs);
if (inputStream == null) {
//文件不存在
return RestResponse.success(false);
}
} catch (Exception e) {
e.printStackTrace();
return RestResponse.success(false);
}
return RestResponse.success(true);
}
3. 上传分块文件接口
3.1 定义接口
@ApiOperation(value = "上传分块文件")
@PostMapping("/upload/uploadchunk")
public RestResponse uploadchunk(@RequestParam("file") MultipartFile file,
@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
return mediaFileService.uploadChunk(fileMd5,chunk,file.getBytes());
}
3.2 编写实现方法
实现方法涉及文件上传,但是文件上传不是只有在上传视频时才使用到,图片和文档的上传也同样使用得到。所以我们应该编写一个通用的上传文件方法。
通用上传文件代码:
private void addMediaFilesToMinIO(byte[] bytes, String bucket, String objectName) {
//资源的媒体类型
String contentType = MediaType.APPLICATION_OCTET_STREAM_VALUE;//默认未知二进制流
if (objectName.indexOf(".") >= 0) {
//取objectName中的扩展名
String extension = objectName.substring(objectName.lastIndexOf("."));
ContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(extension);
if (extensionMatch != null) {
contentType = extensionMatch.getMimeType();
}
}
try {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
PutObjectArgs putObjectArgs = PutObjectArgs.builder().bucket(bucket)
.object(objectName)
//InputStream stream, long objectSize 对象大小,long partSize 分片大小(-1表示5M,最大不要超过5T,最多10000分片)
.stream(byteArrayInputStream, byteArrayInputStream.available(), -1)
.contentType(contentType)
.build();
//上传到minio
minioClient.putObject(putObjectArgs);
} catch (Exception e) {
e.printStackTrace();
log.debug("上传文件到文件系统出错:{}", e.getMessage());
XueChengPlusException.cast("上传文件出错!");
}
}
上传分块文件代码:
@Override
public RestResponse uploadChunk(String fileMd5, int chunk, byte[] bytes) {
//得到分块文件的目录路径
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
//得到分块文件的路径
String chunkFilePath = chunkFileFolderPath + chunk;
try {
//将文件存储至minIO
addMediaFilesToMinIO(bytes, bucket_videofiles, chunkFilePath);
return RestResponse.success(true);
} catch (Exception ex) {
ex.printStackTrace();
log.debug("上传分块文件:{},失败:{}", chunkFilePath, ex.getMessage());
}
return RestResponse.validfail(false, "上传分块失败");
}
4. 合并分块文件接口
4.1 定义接口
@ApiOperation(value = "合并文件")
@PostMapping("/upload/mergechunks")
public RestResponse mergechunks(@RequestParam("fileMd5") String fileMd5,
@RequestParam("fileName") String fileName,
@RequestParam("chunkTotal") int chunkTotal) throws Exception {
Long companyId = 1232141425L;
//下载分块
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
uploadFileParamsDto.setFilename(fileName);
uploadFileParamsDto.setFileType("001002");//视频
uploadFileParamsDto.setTags("课程视频");
return mediaFileService.mergechunks(companyId, fileMd5, chunkTotal, uploadFileParamsDto);
}
4.2 编写实现方法
合并分块文件流程:
- 下载所有分块
- 按顺序合并所有分块
- 将合并完的文件上传至文件系统
- 将文件信息存入数据库
- 关闭流,删除分块文件和临时文件
我们先给实现方法写一个大致的框架:
@Override
public RestResponse mergechunks(Long companyId, String fileMd5, int chunkTotal, UploadFileParamsDto uploadFileParamsDto) {
//1.下载所有分块
//2.按顺序合并所有分块
//3.将合并完的文件上传至文件系统
//4.将文件信息存入数据库
}
1)下载所有分块
想要将分块文件合并成新的完整文件必须先将所有的分块文件下载下来,所以我们需要先编写一个下载分块文件的方法:
/***
* @description 下载分块
* @param fileMd5
* @param chunkTotal 分块总数
* @return java.io.File[] 分块文件数组
*/
private File[] checkChunkStatus(String fileMd5, int chunkTotal) {
//得到分块文件所在目录
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
File[] chunkFiles = new File[chunkTotal];
for (int i = 0; i < chunkTotal; i++) {
//分块文件的路径
String chunkFilePath = chunkFileFolderPath + i;
//分块临时文件
File chunkFile = null;
try {
//创建分块临时文件
chunkFile = File.createTempFile("chunk", null);
} catch (IOException e) {
e.printStackTrace();
XueChengPlusException.cast("创建分块临时文件出错" + e.getMessage());
}
//下载分块文件
chunkFile = downloadFileFromMinIO(chunkFile, bucket_videofiles, chunkFilePath);
chunkFiles[i] = chunkFile;
}
return chunkFiles;
}
下载分块文件的代码中调用了一个通用下载方法:
/***
* @description //根据桶和文件路径从minio下载文件
* @param file
* @param bucket 桶名字
* @param objectName 文件名路径
*/
public File downloadFileFromMinIO(File file, String bucket, String objectName) {
GetObjectArgs getObjectArgs = GetObjectArgs.builder().bucket(bucket).object(objectName).build();
try (
InputStream inputStream = minioClient.getObject(getObjectArgs);
FileOutputStream outputStream = new FileOutputStream(file);
) {
IOUtils.copy(inputStream, outputStream);
return file;
} catch (Exception e) {
XueChengPlusException.cast("查询分块文件出错");
}
return null;
}
2)按顺序合并所有分块
创建一个临时文件,循环将分块文件数组写入这个临时文件,合并完成后验证这个合并后的文件和源文件是否相同?
我们只需要比对这两个文件的MD5值就可以判断是否相同。
3)将合并完的文件上传至文件系统
验证通过之后,我们就需要将文件上传至文件系统了,我们不能使用之前参数包含byte数组的上传方法,这样会导致内存被大量占用。
所以我们就需要编写一个不靠字节数组上传的方法,不靠字节数组靠什么呢?靠文件路径,因为我们创建的临时合并文件就存在文件系统中。
首先还是得定义一个规则,合并文件存储在哪?上面我们已经定义好了分块文件的路径,所以我们合并文件决定放在分块文件的上一级目录。
编写一个得到合并文件路径的方法:
/***
* @description 得到保存文件的目录
* @param fileMd5 文件MD5
* @param fileExt 文件后缀名
*/
private String getFilePathByMd5(String fileMd5, String fileExt) {
//将文件MD5值的第一位数作为一级目录,第二位数作为二级目录
return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/" + fileMd5 + fileExt;
}
如上面所说,我们还需要编写一个按照文件路径上传的方法:
//将文件上传到分布式文件系统
private void addMediaFilesToMinIO(String filePath, String bucket, String objectName) {
try {
UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder()
.bucket(bucket)
.object(objectName)//同一个桶内对象名不能重复
.filename(filePath)
.build();
//上传
minioClient.uploadObject(uploadObjectArgs);
log.debug("文件上传成功:{}", filePath);
} catch (Exception e) {
log.debug("文件上传失败");
XueChengPlusException.cast("文件上传到文件系统失败");
}
}
6)完整实现方法
步骤四和步骤五直接跳过,上完整实现方法:
@Override
public RestResponse mergechunks(Long companyId, String fileMd5, int chunkTotal, UploadFileParamsDto uploadFileParamsDto) {
//下载分块
File[] chunkFiles = checkChunkStatus(fileMd5, chunkTotal);
//得到合并后文件的扩展名
String filename = uploadFileParamsDto.getFilename();
//扩展名
String extension = filename.substring(filename.lastIndexOf("."));
//创建一个临时文件作为合并文件
File tempMergeFile = null;
try {
try {
tempMergeFile = File.createTempFile("merge", extension);
} catch (IOException e) {
e.printStackTrace();
XueChengPlusException.cast("创建临时合并文件出错");
}
//合并分块
//创建临时合并文件的流对象
try (RandomAccessFile raf_write = new RandomAccessFile(tempMergeFile, "rw");) {
byte[] b = new byte[1024];
for (File file : chunkFiles) {
//读取分块文件的流对象
try (RandomAccessFile raf_read = new RandomAccessFile(file, "r");) {
int len = -1;
while ((len = raf_read.read(b)) != -1) {
//向合并文件写数据
raf_write.write(b, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
XueChengPlusException.cast("合并文件过程出错");
}
//校验合并后的文件是否正确
try {
FileInputStream mergeFileStream = new FileInputStream(tempMergeFile);
String mergeMd5Hex = DigestUtils.md5Hex(mergeFileStream);
if (!fileMd5.equals(mergeMd5Hex)) {
log.debug("合并文件校验不通过,文件路径:{},原始文件md5:{}", tempMergeFile.getAbsolutePath(), fileMd5);
XueChengPlusException.cast("合并文件校验不通过");
}
} catch (IOException e) {
e.printStackTrace();
XueChengPlusException.cast("合并文件校验出错");
}
//得到合并文件在minio的存储路径
String mergeFilePath = getFilePathByMd5(fileMd5, extension);
//将合并后的文件上传至文件系统
addMediaFilesToMinIO(tempMergeFile.getAbsolutePath(), bucket_videofiles, mergeFilePath);
//将合并后的文件信息上传至数据库
//合并文件的大小
uploadFileParamsDto.setFileSize(tempMergeFile.length());
addMediaFilesToDb(companyId, fileMd5, uploadFileParamsDto, bucket_videofiles, mergeFilePath);
return RestResponse.success(true);
} finally {
//删除临时分块文件
if (chunkFiles != null) {
for (File chunkFile : chunkFiles) {
if (chunkFile.exists()) {
chunkFile.delete();
}
}
}
//删除合并的临时文件
if (tempMergeFile != null) {
tempMergeFile.delete();
}
}
}