hive开窗函数
文章目录
- hive开窗函数
- 1. 开窗函数概述
- 1.1 窗口函数分类
- 1.2 窗口函数和普通聚合函数的区别
- 2. 窗口函数的基本用法
- 2.1 基本用法
- 2.2 设置窗口的方法
- 2.2.1 window_name
- 2.2.2 partition by
- 2.2.3 order by 子句
- 2.2.4 rows指定窗口大小
- 窗口框架
- 2.3 开窗函数中加 order by 和不加 order by 的区别
- 3. 窗口函数用法举例
- 3.1 序号函数: row_number() / rank() / dese_rank()
- 3.2 分布函数: percent_rank() / cume_dist()
- 3.2.1 percent_rank()
- 3.2.2 cume_dist()
- 3.2.3 前后函数lag(expr, n, defval) 、 lead(expr, n, defval)
- 3.2.4 头尾函数:first_value(expr) 、 last_value(expr)
- 4 聚合函数+窗口函数
1. 开窗函数概述
窗口函数也称OLAP函数,对数据库进行实时分析处理
1.1 窗口函数分类
- 序号函数:row_number() / rank() / dense_rank()
- 分布函数:percent_rank() / cume_dist()
- 前后函数:lag() / lead()
- 头尾函数:first_val() / last_val()
- 聚合函数+窗口函数:sum() over()、 max()/min() over() 、avg() over()
- 其他函数:nth_value() / nfile()
1.2 窗口函数和普通聚合函数的区别
聚合函数是将多条记录聚合成一条,窗口函数是每条记录都会执行,有几条记录执行完还是几条
窗口函数兼具group by子句的分组功能和order by子句的排序功能,但是partition by 子句不具备group by的汇总功能
2. 窗口函数的基本用法
准备基础数据
CREATE TABLE exam_record (
uid int COMMENT '用户ID',
exam_id int COMMENT '试卷ID',
start_time timestamp COMMENT '开始时间',
submit_time timestamp COMMENT '提交时间',
score tinyint COMMENT '得分'
)
COMMENT '考试记录表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
TBLPROPERTIES ("skip.header.line.count"="1");
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:02', 84),
(1006, 9001, '2021-09-01 12:11:01', '2021-09-01 12:31:01', 89),
(1006, 9002, '2021-09-06 10:01:01', '2021-09-06 10:21:01', 81),
(1005, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 81),
(1005, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 81),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 71),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 91),
(1004, 9002, '2021-09-05 10:01:01', '2021-09-05 10:21:01', 80),
(1004, 9001, '2021-09-05 10:31:01', '2021-09-05 10:51:01', 80);
select * from exam_record;
exam_record.uid exam_record.exam_id exam_record.start_time exam_record.submit_time exam_record.score
1006 9001 2021-09-01 12:11:01 2021-09-01 12:31:01 89
1006 9002 2021-09-06 10:01:01 2021-09-06 10:21:01 81
1005 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 81
1005 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 81
1004 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 71
1004 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 91
1004 9002 2021-09-05 10:01:01 2021-09-05 10:21:01 80
1004 9001 2021-09-05 10:31:01 2021-09-05 10:51:01 80
2.1 基本用法
窗口函数语法
<窗口函数> over[(partition by <列表清单>)] order by <排序列表清单> [rows between 开始位置 and 结束位置]
窗口函数:指要使用的分析函数,
over(): 用来指定窗口函数的范围,如果括号中什么都不写,则窗口包含where的所有行
select
uid
score,
sum(score) over() as sum_score
from exam_record;
运行结果
uid score sum_score
1006 89 654
1006 81 654
1005 81 654
1005 81 654
1004 71 654
1004 91 654
1004 80 654
1004 80 654
2.2 设置窗口的方法
2.2.1 window_name
给窗口指定一个别名
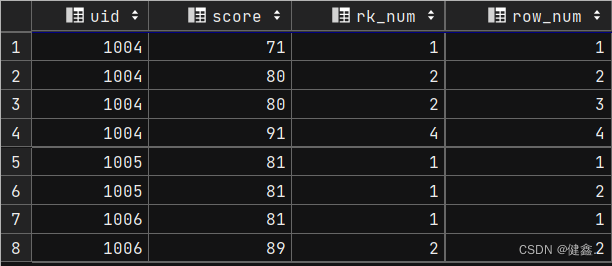
select
uid,
score,
rank() over my_window_name as rk_num,
row_number() over my_window_name as row_num
from exam_record
window my_window_name as (partition by uid order by score);
2.2.2 partition by
select
uid,
score,
sum(score) over(partition by uid) as sum_score
from exam_record;
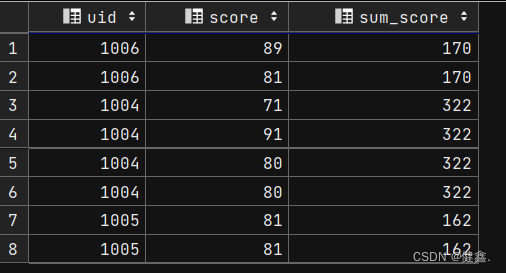
按照uid进行分组,分别求和
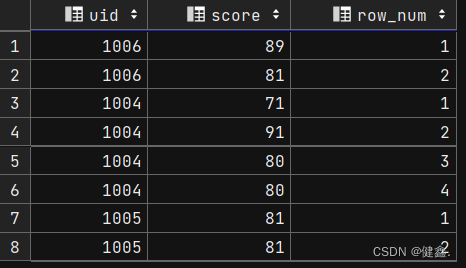
使用row_number()序号函数,表明序号
select
uid,
score,
row_number() over(partition by uid) as row_num
from exam_record;
2.2.3 order by 子句
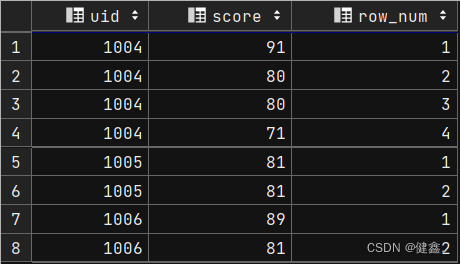
按照哪些字段进行排序,窗口函数将按照排序后的记录进行编号
select
uid,
score,
row_number() over (partition by uid order by score desc) as row_num
from exam_record
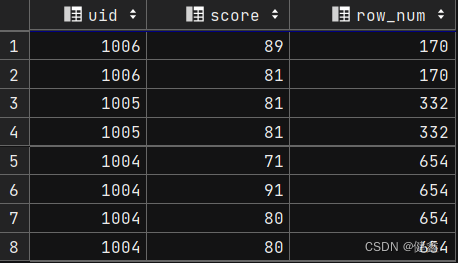
单独使用order by uid
select
uid,
score,
sum(score) over (order by uid desc) as row_num
from exam_record;
单独使用partition by uid
select
uid,
score,
sum(score) over (partition by uid) as row_num
from exam_record;
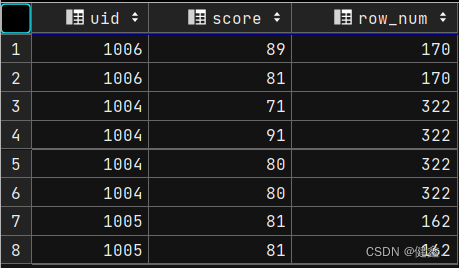
partition by进行分组内的求和,分区间独立
order by 对序号相同的进行求和,对序号不同的进行累加求和
单独使用order by score
select
uid,
score,
sum(score) over (order by score desc) as row_num
from exam_record;
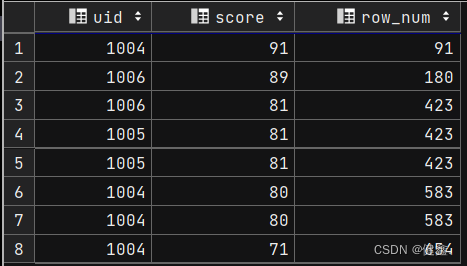
2.2.4 rows指定窗口大小
查看score的平均值
select
uid,
score,
avg(score) over(order by score desc) as avg_num
from exam_record
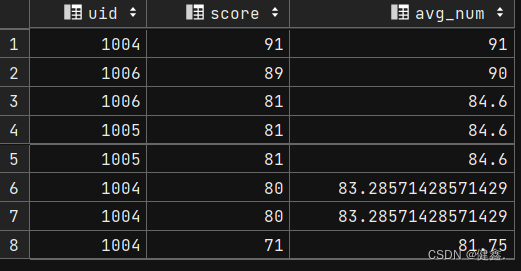
按照score降序排列,每一行计算前一行到当前行的score的平均值
select
uid,
score,
avg(score) over(order by row_score) as avg_num
from(
select
uid,
score,
row_number() over(order by score desc) as row_score
from exam_record
)res
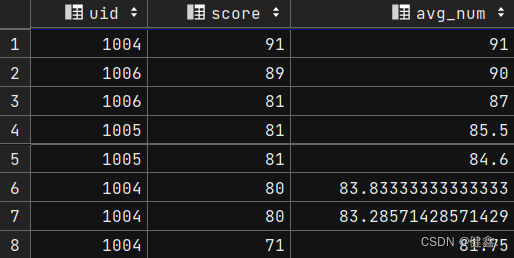
窗口框架
指定窗口大小,框架是对窗口的进一步分区,框架有两种限定方式:
使用rows语句,通过指定当前行之前或之后的固定数目的行来限制分区中的行数
使用range语句,按照排列序列的当前值,根据相同值来确定分区中的行数
order by 字段名 range|rows 边界规则0 | [between 边界规则1] and 边界规则2
range和rows的区别
range按照值的范围进行范围的定义,rows按照行的范围进行范围的定义

- 使用框架时,必须要有order by子句,如果仅指定了order by子句未指定框架,则默认框架会使用range unbounded preceding and current row (从第一行到当前行的数据)
- 如果窗口函数没有指定order by子句,就不存在 rows|range 窗口的计算
- range 只支持使用unbounded 和 current row
查询我与前两名的平均值
select
uid,
score,
avg(score) over(order by score desc rows 2 preceding) as avg_score
from exam_record;
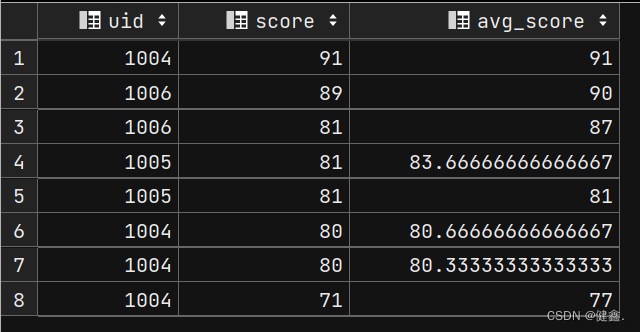
查询当前行及前后一行的平均值
select
uid,
score,
avg(score) over(order by score desc rows between 1 preceding and 1 following) as avg_score
from exam_record;
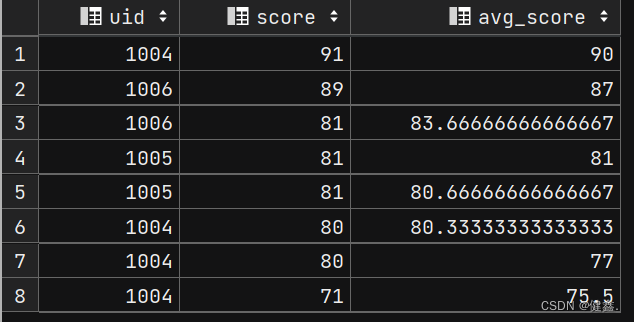
2.3 开窗函数中加 order by 和不加 order by 的区别
当开窗函数为排序函数时,如row_number()、rank()等,over中的order by 只起到窗口内排序的作用
当开窗函数为聚合函数时,如max、min、count等,over中的order by不仅对窗口内排序,还起到窗口内从当前行到之前所有行的聚合
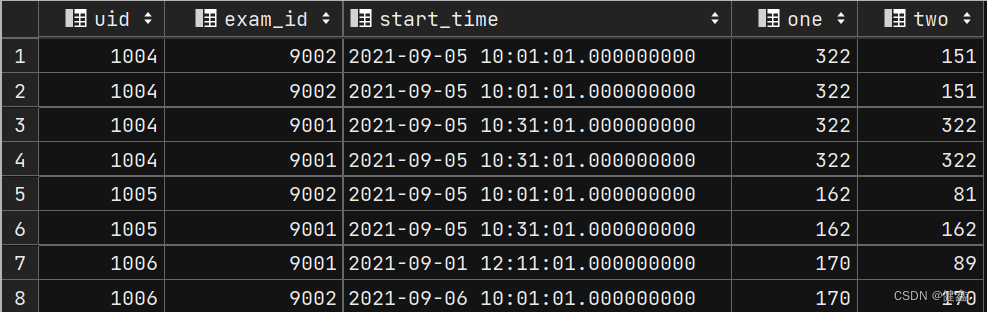
select
uid,
exam_id,
start_time,
sum(score) over(partition by uid) as one,
sum(score) over(partition by uid order by start_time) as two
from exam_record
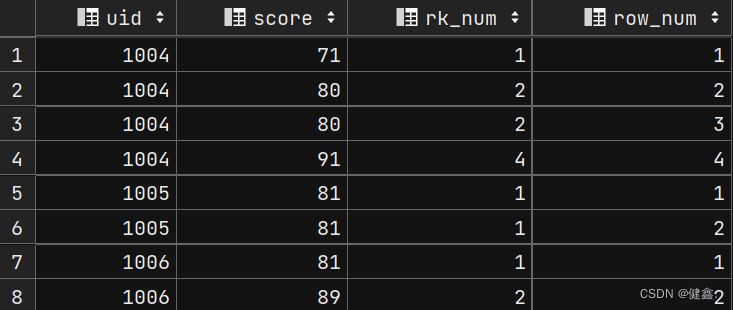
3. 窗口函数用法举例
3.1 序号函数: row_number() / rank() / dese_rank()
区别:rank() : 并列排序,跳过重复序号------1、1、3
row_number() : 顺序排序——1、2、3
dese_rank() : 并列排序,不跳过重复序号——1、1、2
select
uid,
score,
rank() over my_window as rk_num,
row_number() over my_window as row_num
from exam_record
window my_window as (partition by uid order by score);
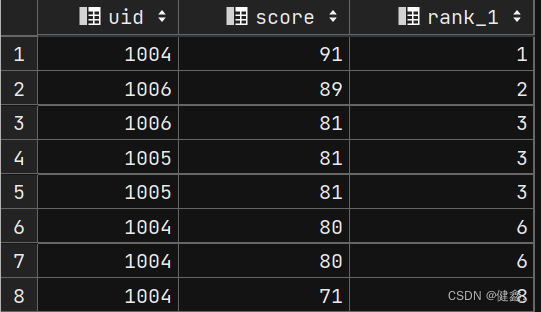
不使用窗口函数实现分数排序
SELECT
P1.uid,
P1.score,
(SELECT
COUNT(P2.score)
FROM exam_record P2
WHERE P2.score > P1.score) + 1 AS rank_1
FROM exam_record P1
ORDER BY rank_1;
3.2 分布函数: percent_rank() / cume_dist()
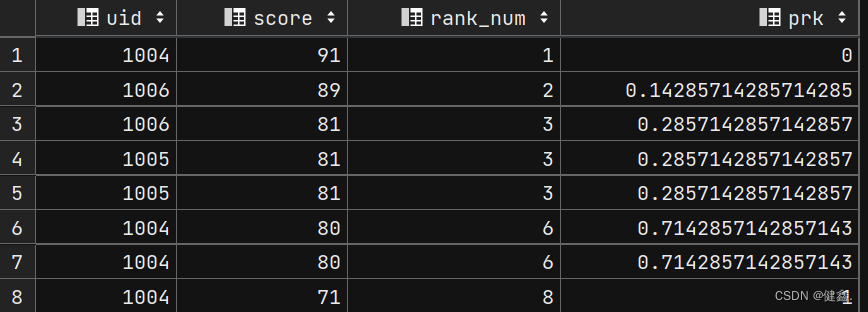
3.2.1 percent_rank()
percent_rank() 函数将某个数据在数据集的排位作为数据集的百分比值返回,范围0到1,
按照(rank - 1) / (rows - 1)进行计算,rank为rank()函数产生的序号,rows为当前窗口的记录总行数
select
uid,
score,
rank() over my_window as rank_num,
percent_rank() over my_window as prk
from exam_record
window my_window as (order by score desc)
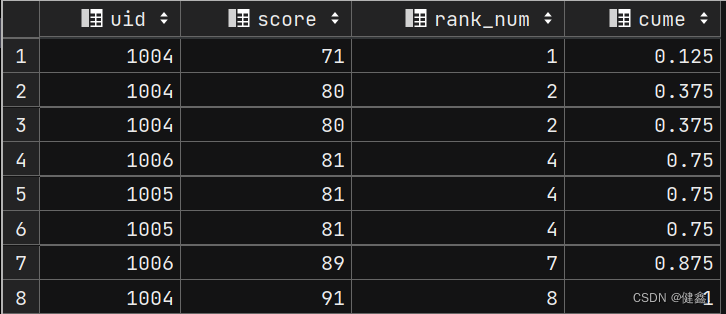
3.2.2 cume_dist()
如果升序排列,则统计:小于等于当前值的行数 / 总行数
如果降序排列,则统计:大于等于当前值的行数 / 总行数
查询小于等于当前score的比例
select
uid,
score,
rank() over my_window as rank_num,
cume_dist() over my_window as cume
from exam_record
window my_window as (order by score asc);
3.2.3 前后函数lag(expr, n, defval) 、 lead(expr, n, defval)
lag()和lead()函数可以在同一次查询中取出同一字段前 n 行的数据和后 n 行的数据作为独立列
lag( exp_str,offset,defval) over(partition by .. order by …)
lead(exp_str,offset,defval) over(partition by .. order by …)
- exp_str 是字段名
- offset是偏移量,即 n 的值
- defval默认值,如何当前行向前或向后 n 的位置超出表的范围,则会将defval的值作为返回值,默认为NULL
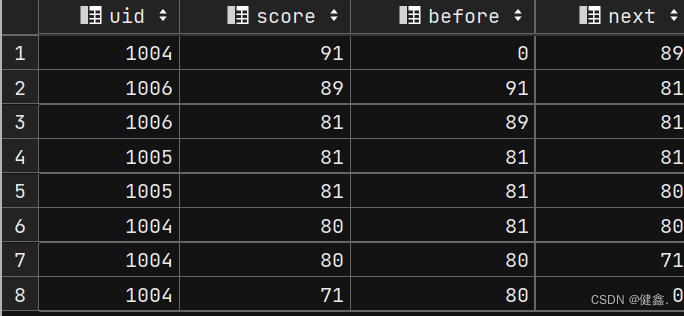
查询前1名同学和后一名同学的成绩和当前同学成绩的差值
- 先将前一名、后一名以及当前行的分数放在一起
select
uid,
score,
lag(score, 1, 0) over my_window as `before`,
lead(score, 1, 0) over my_window as `next`
from exam_record
window my_window as (order by score desc);
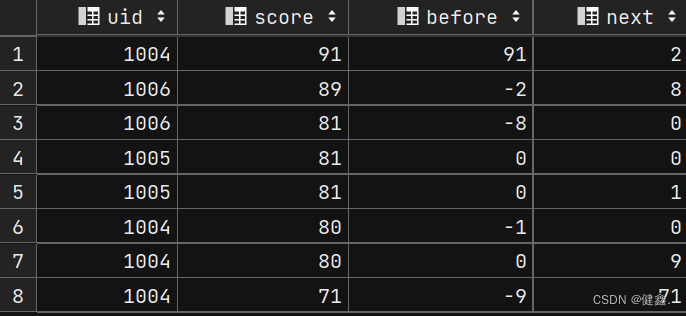
- 然后做差值
select
uid,
score,
score - before as before,
score - next as next
from (
select
uid,
score,
lag(score, 1, 0) over my_window as before,
lead(score, 1, 0) over my_window as next
from exam_record
window my_window as (order by score desc)
)res
3.2.4 头尾函数:first_value(expr) 、 last_value(expr)
- 返回第一个expr:first_value(expr)
- 返回第二个expr:last_value(expr)
查询第一个和最后一个分数
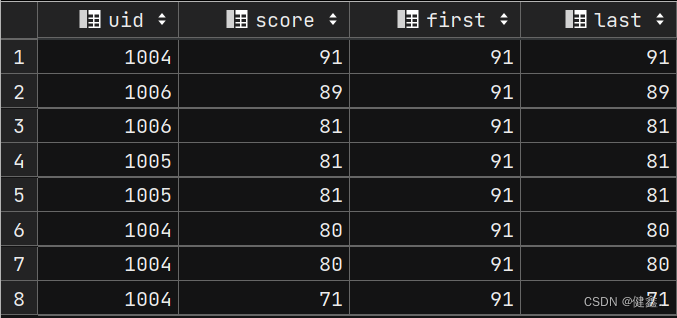
select
uid,
score,
first_value(score) over my_window as first,
last_value(score) over my_window as last
from exam_record
window my_window as (order by score desc);
4 聚合函数+窗口函数
窗口函数在where之后执行,所以where需要用窗口函数作为条件
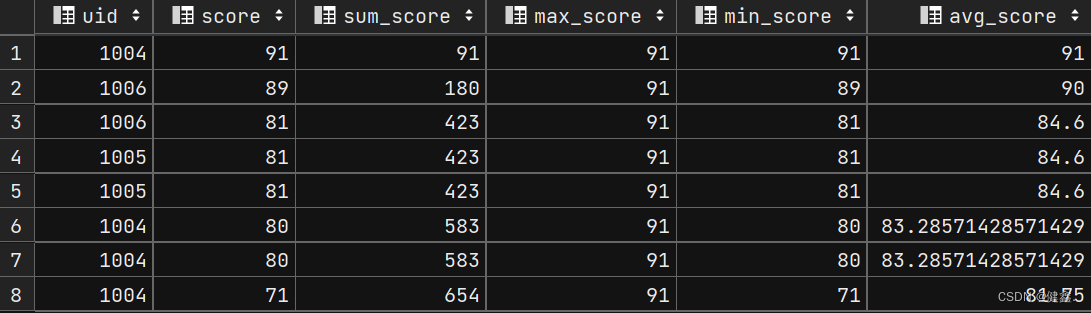
SELECT
uid,
score,
sum(score) OVER my_window_name AS sum_score,
max(score) OVER my_window_name AS max_score,
min(score) OVER my_window_name AS min_score,
avg(score) OVER my_window_name AS avg_score
FROM exam_record
WINDOW my_window_name AS (ORDER BY score desc)
![[数据结构]:07-二叉树(无头结点)(C语言实现)](https://img-blog.csdnimg.cn/c03810c0ee5a4796b7c06d9dd88cdce8.png)