目录
1. 前言
1.1 操作分类
1.2 语法知识
2. transformations
2.1 map
2.2 mapPartitions
2.3 flatMap
2.4 glom
2.5 groupBy
2.6 filter
2.7 sample
2.8 distinct
2.9 coalesce
2.10 repartition
2.11 sortBy
2.12 partitionBy
2.13 reduceByKey
2.14 groupByKey
2.15 aggregateByKey
2.16 foldByKey
2.17 combineByKeyWithClassTag
2.18 combineByKey
2.19 sortByKey
2.20 cogroup
2.21 join、leftOuterJoin、rightOuterJoin、fullOuterJoin
2.22 intersection、union、subtract、zip
3. actions
3.1 reduce
3.2 collect
3.3 count
3.4 first
3.5 take
3.6 takeOrdered
3.7 aggregate
3.8 fold
3.9 countByKey
3.10 saveAsTextFile 、saveAsObjectFile 、 saveAsSequenceFile
3.11 foreach
1. 前言
我们可以将RDD想象成一张分布式的表,表中的数据以分区的形式分布在不同的计算节点上
对表操作称之为算子,可以用SQL的思想来理解这些操作
1.1 操作分类
在spark中,RDD支持两种类型的操作
1.transformations(转换算子)
功能:
从现有的RDD中通过某种转换规则,创建的新RDD
特点:
所有的转换操作都是懒加载,并不会立即进行转换操作
只有当驱动程序需要计算结果时,才会触发转换行为
2.actions(行动算子)
功能:
将各个计算节点上的结果数据,返回给驱动程序(客户端)
通常,我们也会将RDD的操作称之为算子,也就是人们常说 转换算子、行动算子
官方API链接: https://spark.apache.org/docs/latest/api/scala/org/apache/spark/rdd/RDD.html
1.2 语法知识
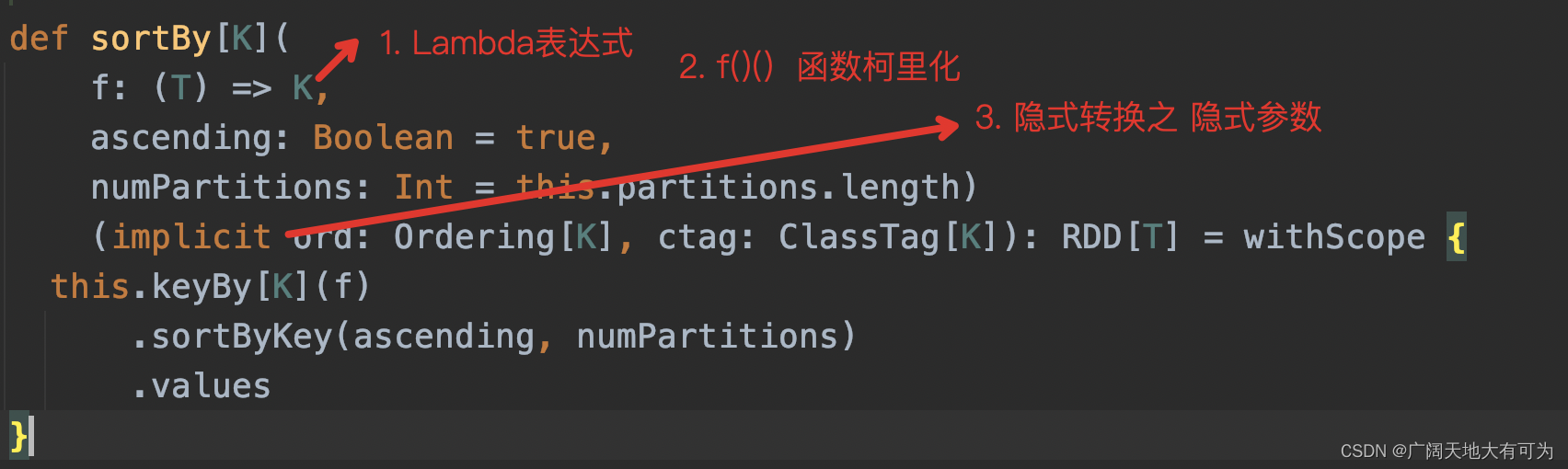
这块知识需要对scala基本语法有些了解,才会对API调用有更好的理解
什么是Lambda表达式? 传送门
什么是函数柯里化?传送门
什么是隐式转换及隐式函数?传送门
2. transformations
2.1 map
功能: 返回一个新的RDD,对父RDD的每个元素按照f函数进行转换
可以看我之前写的例子 : 传送门
重点关注:
分区内元素依次被指定Lambda表达式执行(串行),多个分区间并发执行(并行)
如果指定的Lambda表达式中存在消耗时间的逻辑(如 数据库连接、IO等)
请选择使用mapPartitions

2.2 mapPartitions
功能: 返回一个新的RDD,对父RDD每个分区按照f函数进行转换
可以看我之前写的例子 : 传送门
重点关注: 1.map和mapPartitions的区别
2.mapPartitions的使用风险和使用场景
3.Lambda表达式每次会处理整个分区的数,小心内存溢出哦😯

2.3 flatMap
功能: 返回一个新的RDD,将父RDD中每个元素转换成集合,再将集合打散
可以看我之前写的例子 : 传送门

2.4 glom
功能: 返回一个新的RDD,将父RDD每个分区中的所有元素封装到数组中去
可以看我之前写的例子 : 传送门

重点关注:
1. 用于将父RDD中每个分区的数据打包成数组
2. 不会触发shuffle操作哦
2.5 groupBy
功能: 返回一个新的RDD,对父RDD所有元素按照f函数的结果进行分组
可以看我之前写的例子 : 传送门
实现1: 使用默认分区器,分区数=父RDD分区数

实现2: 指定分区数,默认使用Hash分区器
 实现3: 使用指定分区器
实现3: 使用指定分区器

重点关注:
1.这个操作会触发shuffle操作,当数据分布不均时,可能会造成某个分区数据量过大
而导致内存溢出哦😯,也就是常说的数据倾斜
2.如果分组的目的是为了做 聚合操作,建议使用 reduceByKey、aggregateByKey
效率会高很多(这些算子,会map端先做一次聚合操作,来减少IO的数据量)
2.6 filter
功能: 返回一个新的RDD,对父RDD的所有元素按照 f(x) = true 进行过滤
可以看我之前写的例子 : 传送门

2.7 sample
功能: 返回一个新的RDD,对父RDD做抽样查询
可以看我之前写的例子 : 传送门

2.8 distinct
功能: 返回一个新的RDD,对父RDD元素去重
可以看我之前写的例子 : 传送门
实现1: 不指定分区个数

实现2: 指定分区个数

重点关注:
1. 会触发shuffle操作,会先在map端对数据去重后,再在reduce端去重
2.9 coalesce
功能: 返回一个新的RDD,增加或减少父RDD的分区个数(合并分区时,可以选择不shuffle)
可以看我之前写的例子 : 传送门

重点关注:
shuffle = true时,会触发shuffle操作,小心数据倾斜哦😱
合并分区时,建议使用 coalesce且shuffle=false
2.10 repartition
功能: 返回一个新的RDD,增加或减少父RDD的分区个数(必触发shuffle)
可以看我之前写的例子 : 传送门

重点关注:
一定会触发shuffle操作,如果是减少分区,建议使用 coalesce
2.11 sortBy
功能: 返回一个新的RDD,对父RDD根据f函数的结果排序
可以看我之前写的例子 : 传送门

重点关注:
会触发shuflle操作,小心数据倾斜哦😱
2.12 partitionBy
功能: 返回一个新的RDD,按照指定分区器对父RDD重新分区
可以看我之前写的例子 : 传送门

注意事项:
1.当父RDD数据分布不均时,可以使用此方法将数据打散
2.13 reduceByKey
功能: 返回一个新的RDD,根据指定的聚合规则对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑相同,且没有初始值参与聚合
可以看我之前写的例子 : 传送门
实现1:

实现2:
 实现3:使用默认分区器,分区数和父RDD相同
实现3:使用默认分区器,分区数和父RDD相同

重点关注:
1. 这个方法 会先在每个map端本地做一次聚合,合并完后再发送到reduce端聚合
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.14 groupByKey
功能: 返回一个新的RDD,按照key对父RDD做分组
可以看我之前写的例子 : 传送门
实现1:

实现2:

重点关注:
1. 目前实现方式,会先将每个key的所有键值对读取到内存中,如果一个key的值过多时
就会导致OutOfMemoryError错误,使用前一定要评估数据量和内存资源
2.这个操作会触发shuffle操作,当数据分布不均时,可能会造成某个分区数据量过大
而导致内存溢出哦😯,也就是常说的数据倾斜
3.如果分组的目的是为了做 聚合操作,那么可以使用 reduceByKey、aggregateByKey
效率会高很多(这些算子,会map端先做一次聚合操作,来减少IO的数据量)
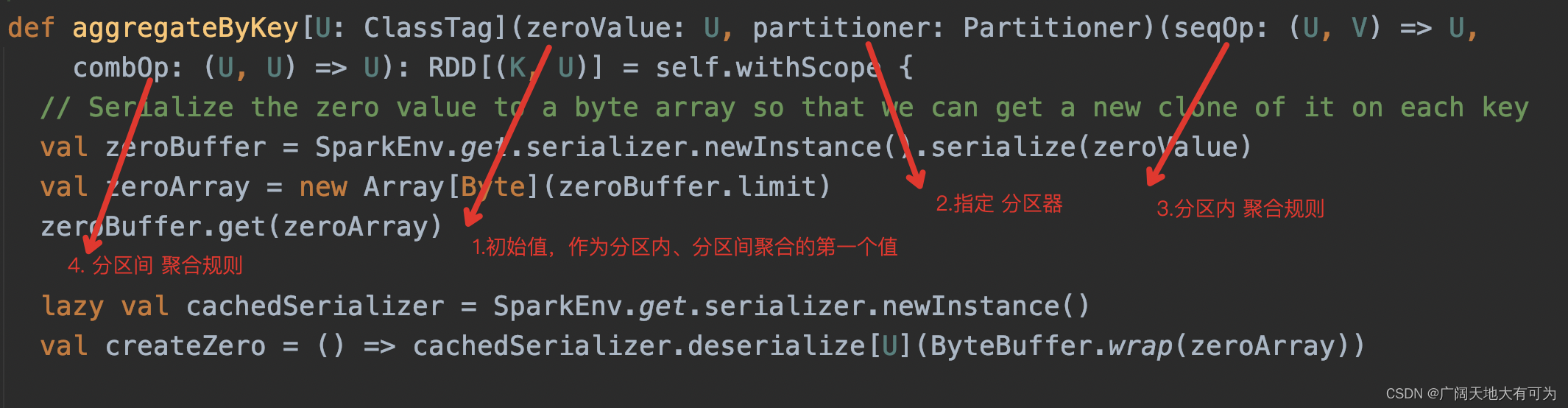
2.15 aggregateByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,且有初始值参与聚合
可以看我之前写的例子 : 传送门
方式1:
 方式2:
方式2:

方式3:
 重要关注:
重要关注:
1. zeroValue值 会参与分区聚合计算和分区间聚合计算
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.16 foldByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑相同,且有初始值参与聚合
可以看我之前写的例子 : 传送门
方式1:

方式2:
 方式3:
方式3:

重要关注:
1. zeroValue值 会参与分区聚合计算和分区间聚合计算
2. 此方法会触发shuffle操作,小心数据倾斜哦😟!!!
2.17 combineByKeyWithClassTag
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,且有初始值参与聚合
并且可以转换value的数据类型
可以看我之前写的例子 : 传送门
实现1: 实现2:
实现2: 实现3:
实现3:
重点关注:
1. 这是RDD聚合操作中最通用的方法,其他聚合函数都是对它的封装
2. RDD分区数量和数据分布直接会影响聚合操作的效率,使用时注意数据分布哦
2.18 combineByKey
功能: 返回一个新的RDD,根据指定的聚合规则 对父RDD 按照key做聚合
分区内(map端)、分区间(reduce端)聚合逻辑可以不相同,没有初始值参与聚合
并且可以转换value的数据类型
可以看我之前写的例子 : 传送门
方式1: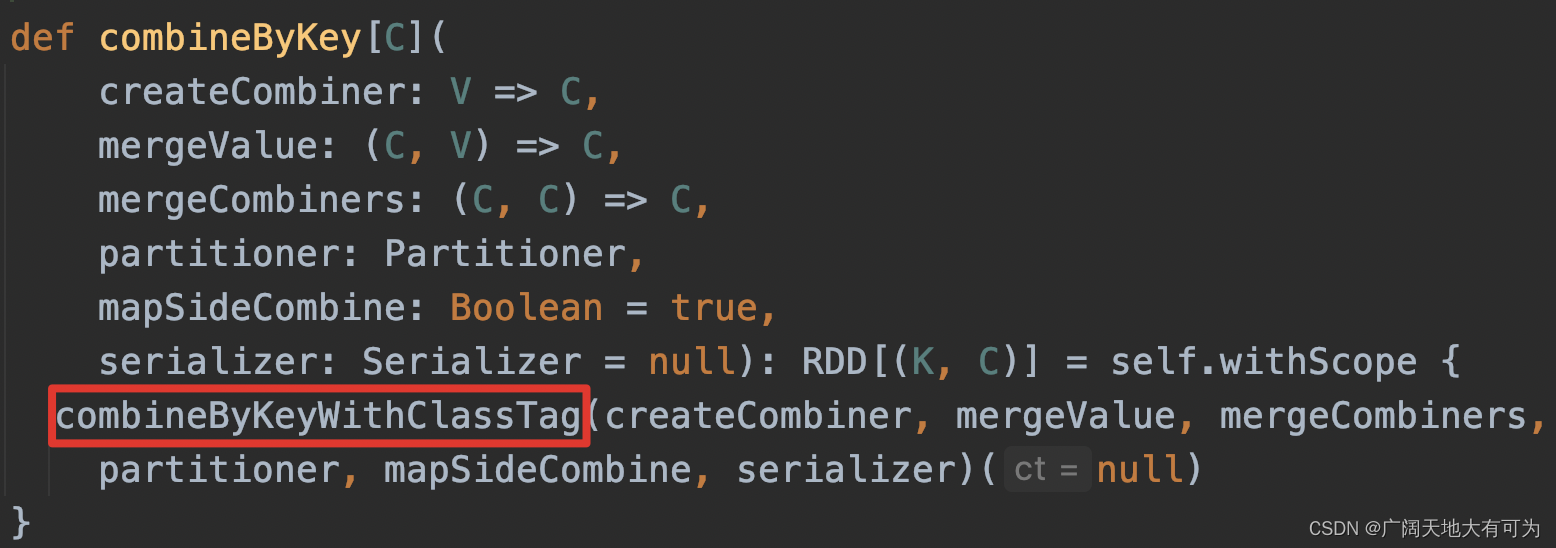 方式2:
方式2: 重点关注:
重点关注:
1. 查看源码,是对combineByKeyWithClassTag的封装
2.19 sortByKey
功能: 返回一个新的RDD,元素值为 父RDD 根据key排序的结果
可以看我之前写的例子 : 传送门

重点关注:
1. key的数据类型 必须实现 Ordered 接口(特质)
2. key类型为tuple时,无法使用该方法排序
3. 存在shuffle过程,小心数据倾斜哦
2.20 cogroup
功能: 返回一个新的RDD,元素值为 多个RDD下相同key下 各自value值的迭代器
可以看我之前写的例子 : 传送门
实现1: 实现2:
实现2:
 实现3:
实现3:
注意事项:
1. 多个RDD关联最通用的方法
2. 会触发shuffle操作,小心数据倾斜哦
2.21 join、leftOuterJoin、rightOuterJoin、fullOuterJoin
功能: 返回一个新的RDD,元素值为 多个RDD下相同key下 的各自value值
可以看我之前写的例子 : 传送门
join: leftOuterJoin:
leftOuterJoin: rightOuterJoin:
rightOuterJoin: fullOuterJoin:
fullOuterJoin: 重点关注:
重点关注:
1. 发下没有,都是通过封装 cogroup + flatMapValues 来实现的
2. 会触发shuffle操作,小心数据倾斜哦
2.22 intersection、union、subtract、zip
功能: 返回一个新的RDD,元素值为 两个RDD求交集、并集、差集 的结果
可以看我之前写的例子 : 传送门
intersection:返回两个RDD的交集,结果将不包含任何重复元素 (内部会触发shuffle过程)
union:返回多个RDD的并集,结果会有重复元素 (内部不会触发shuffle过程)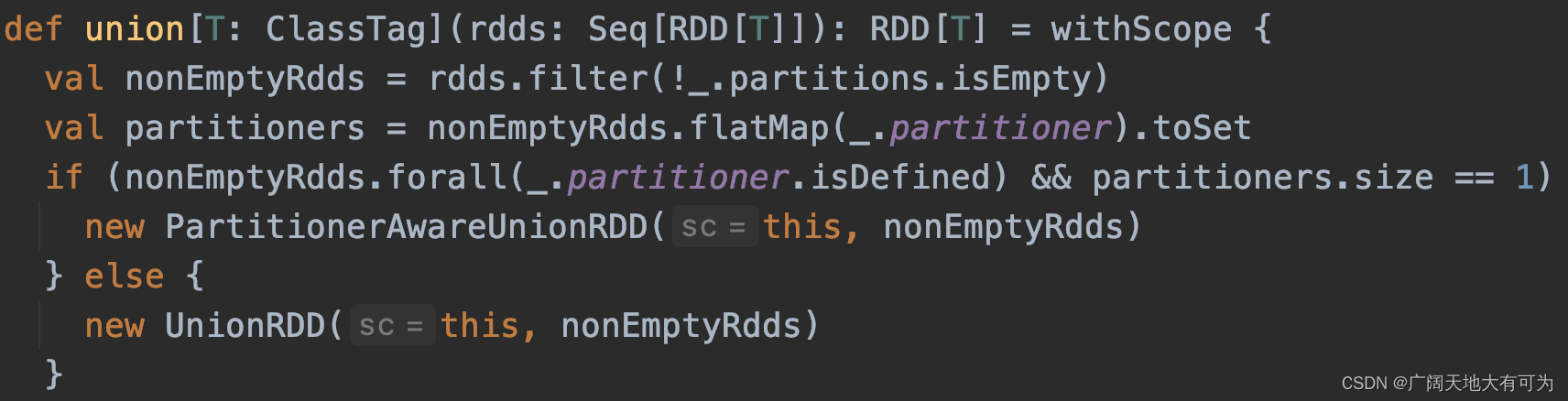
subtract:返回两个RDD的差集 (内部会触发shuffle过程)
zip:返回两个RDD按元素顺序对应的二元组 (内部不会触发shuffle过程)
3. actions
3.1 reduce
功能: 根据指定的计算规则,对RDD所有的元素依次做运算,并返回计算结果给驱动程序(Driver)
可以看我之前写的例子 : 传送门

注意事项:
1.先在每个分区内做聚合操作(Map端),再对各个分区的结果做聚合操作
如果操作不满足结合律和交换律时(如减法、除法), 当分区个数不同时,计算结果也会不同
3.2 collect
功能:返回给Driver端一个数组,数组内容为RDD所有的元素
可以看我之前写的例子 : 传送门

注意事项:
1. 当RDD元素过多时,小心Driver端内存溢出哦
3.3 count
功能:返回RDD元素个数给Driver端
可以看我之前写的例子 : 传送门

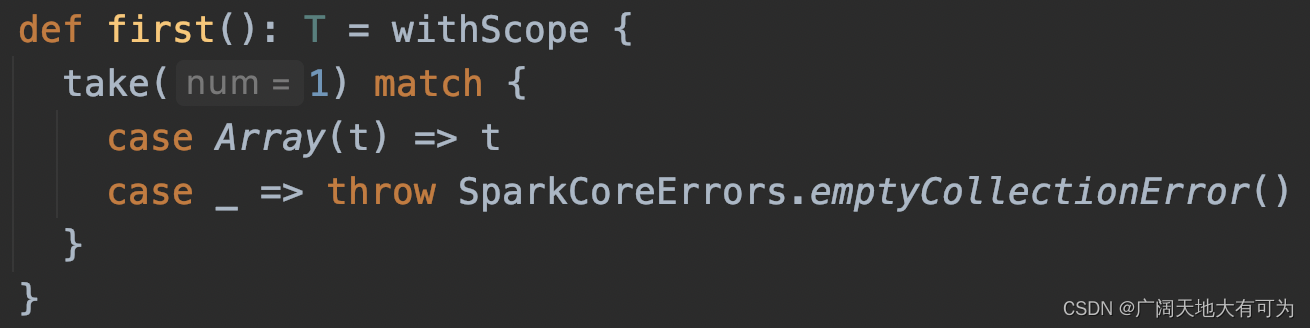
3.4 first
功能:返回RDD第一个元素的值 给Driver端
可以看我之前写的例子 : 传送门
3.5 take
功能: 返回给Driver端一个数组,数组内容为RDD的前n项元素
可以看我之前写的例子 : 传送门
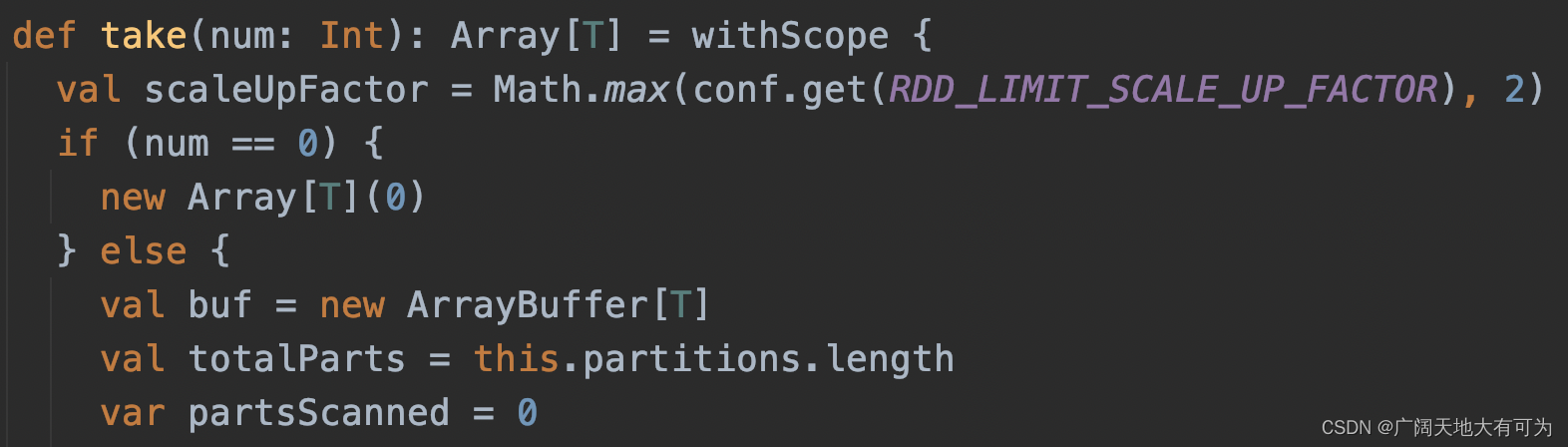 注意事项:
注意事项:
1. 当返回元素过多时,小心Driver端内存溢出哦
2. 如果在Nothing或Null的RDD上调用此方法将引发异常
3.6 takeOrdered
功能: 返回给Driver端一个数组,数组内容为RDD排序后的前n项元素
可以看我之前写的例子 : 传送门

注意事项:
1. 当返回元素过多时,小心Driver端内存溢出哦
3.7 aggregate
功能:对RDD做聚合操作,并将聚合的结果返回给Driver端
可以看我之前写的例子 : 传送门

注意事项:
1.zeroValue会参与分区内聚合运算和分区间聚合运算
通常会将它设置成一个中立元素(列表连接Nil 计数时为0)
3.8 fold
功能:对RDD做聚合操作,并将聚合的结果返回给Driver端
可以看我之前写的例子 : 传送门

3.9 countByKey
功能:计算RDD中每个key下的value的个数,并将结果返回给Driver端
可以看我之前写的例子 : 传送门

注意事项:
1. 当返回结果集过大时,小心Driver端内存溢出哦
3.10 saveAsTextFile 、saveAsObjectFile 、 saveAsSequenceFile
可以看我之前写的例子:传送门
saveAsTextFile:
功能:将RDD以文本文件的格式保存到指定路径
实现1:
实现2:
saveAsObjectFile
功能:将RDD以序列化对象的格式保存到指定路径

saveAsSequenceFile
功能:将RDD以Hadoop SequenceFile的格式保存到指定路径

3.11 foreach
功能:将指定的Lambda表达式,应用在RDD的每个元素上
可以看我之前写的例子:传送门

重点关注:
1. 分区内按元素顺序依次执行Lambda表达式,分区间是并行的