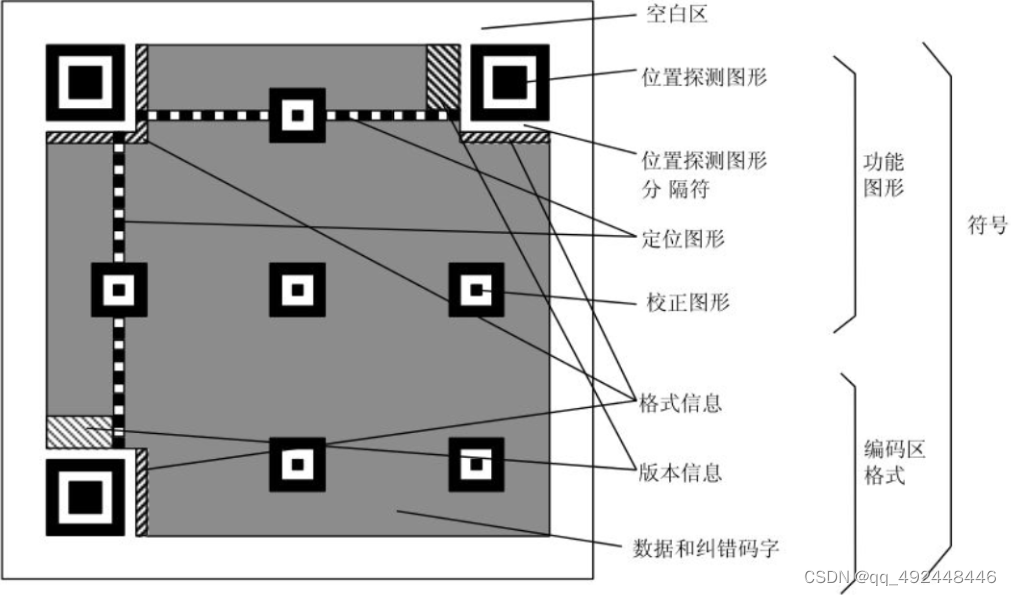
模型的输出集合(Tns,Tne,Cn),Tns是第n个预测动作开始时间,Tne是第n个预测动作结束时间,Cn是第n个预测动作的类别。
模型有三个输入:1.RGB帧 2.可学习的query points 3.query vector
在该模型中,预测一段连续的动作,称之为query。
例如,我规定了一条视频要预测20个连续动作,那么query_num = 20。
可学习的query points描述了一个query中的动作位置,一个query可以有Ns个point
每个query vector从被采样的特征中解码query中的动作语义和位置,一个query有一个vector。
1.模型的整体流程
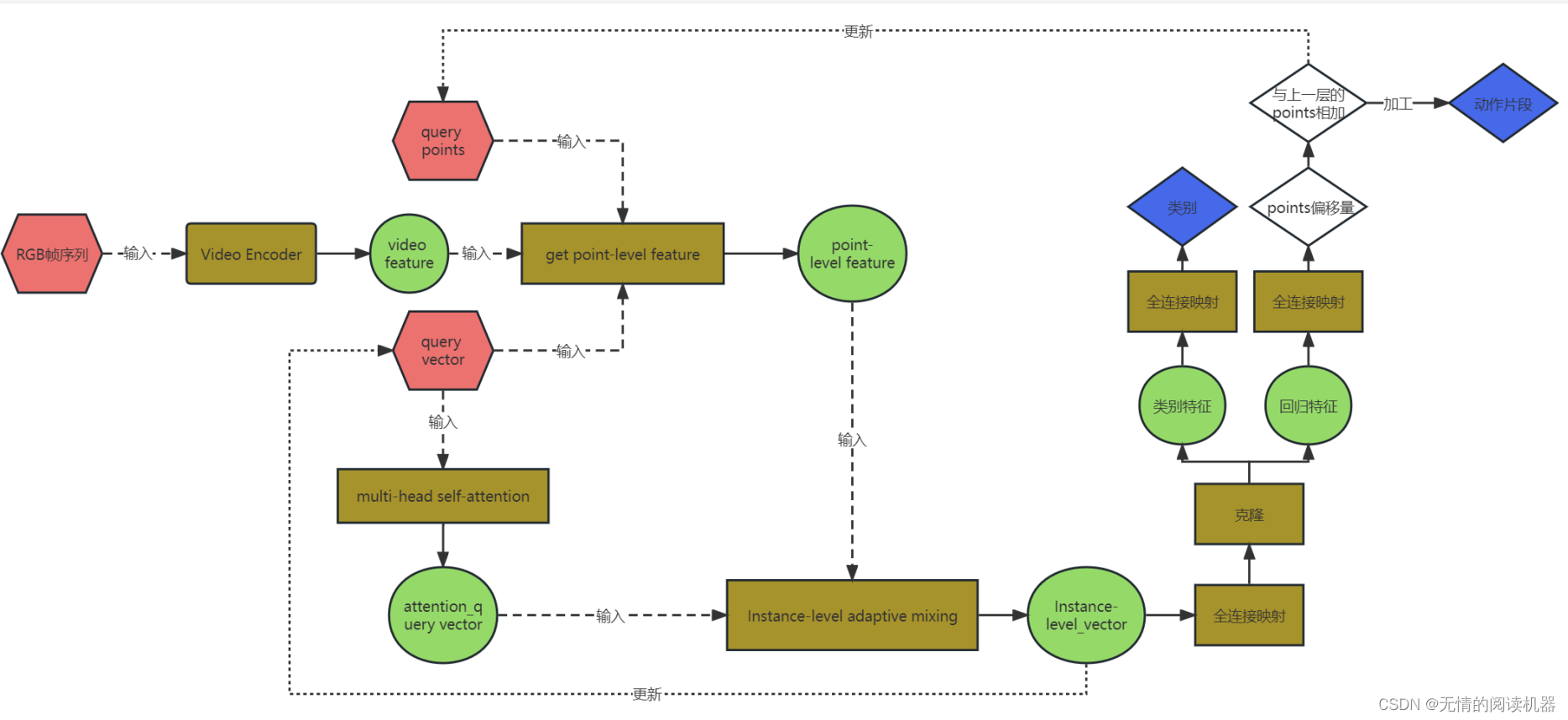
1.首先 RGB帧序列会被video Encoder提取特征
2.然后模型利用video feature、query points 、query vector 来得到点级别的视频特征
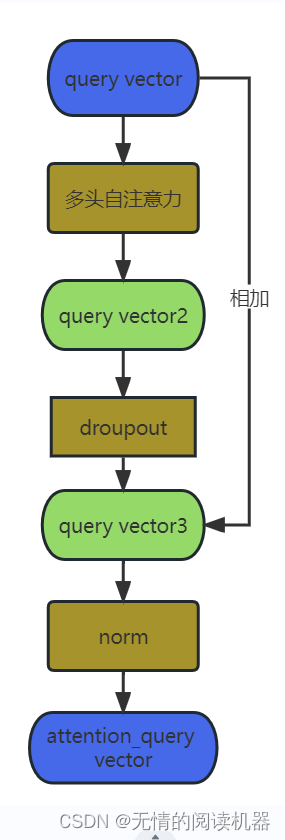
3.query vector通过自注意力机制来提取vector之间的关联关系,从而得到attention_query vector
4.然后通过点级的视频特征和attention_query vector来得到实例级别的vector
5.将实例级别的vector利用全连接、激活函数等,得到预测结果
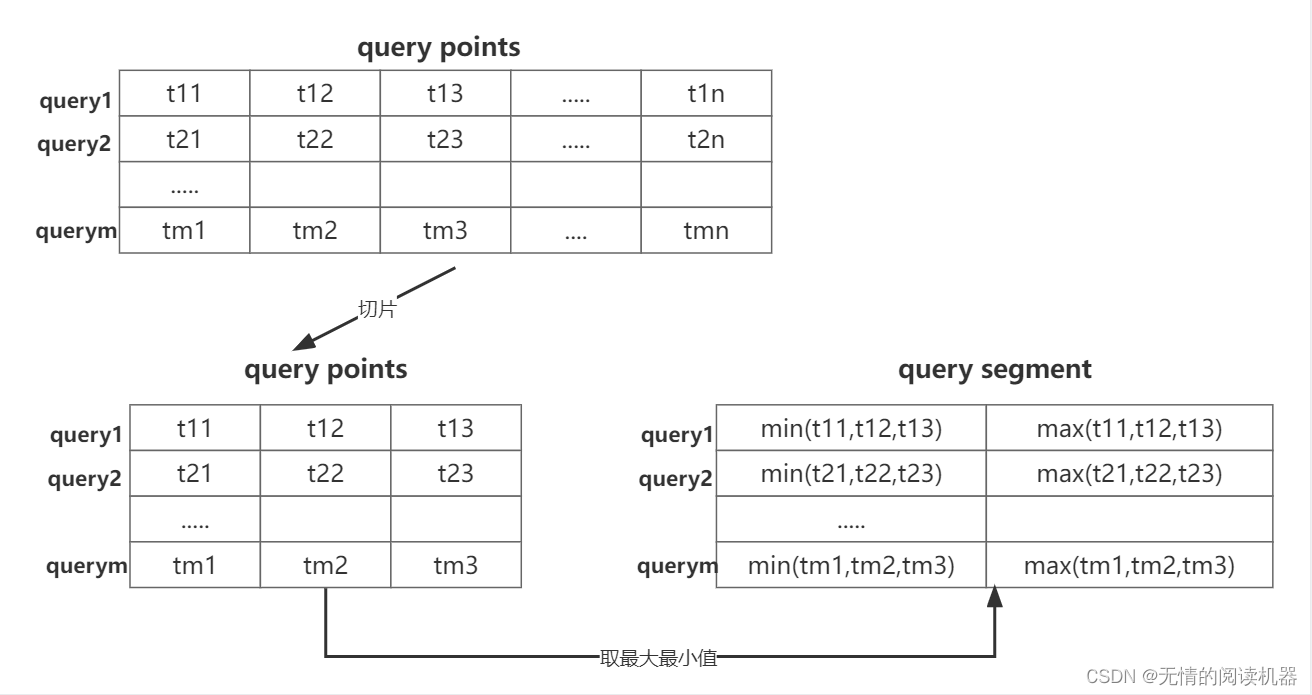
6.预测的points其实是偏移量,首先将points与原来的points相加,然后加工得到一个每个query的片段(中心点,长度)
2.视频编码器
视频编码器是由一系列的卷积、池化、等操作组成的,用来提取视频特征。
其中最基础的单元操作就是Unit3D
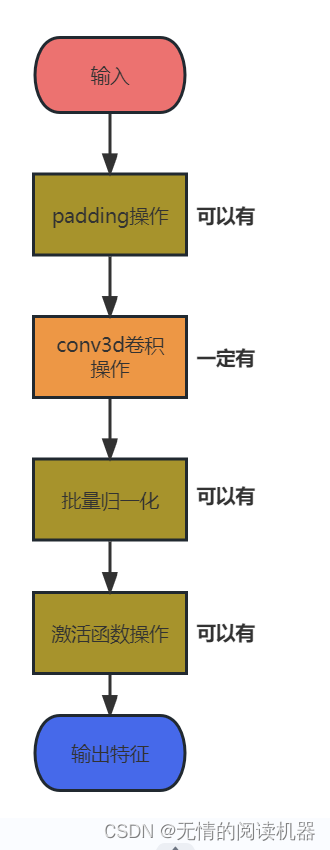
然后在此基础上,设计了特征提取模块,InceptionModule
其中in_c是输入的通道数,out_c是存放输出通道的数组
每个分支提取的特征会在channel维度进行拼接
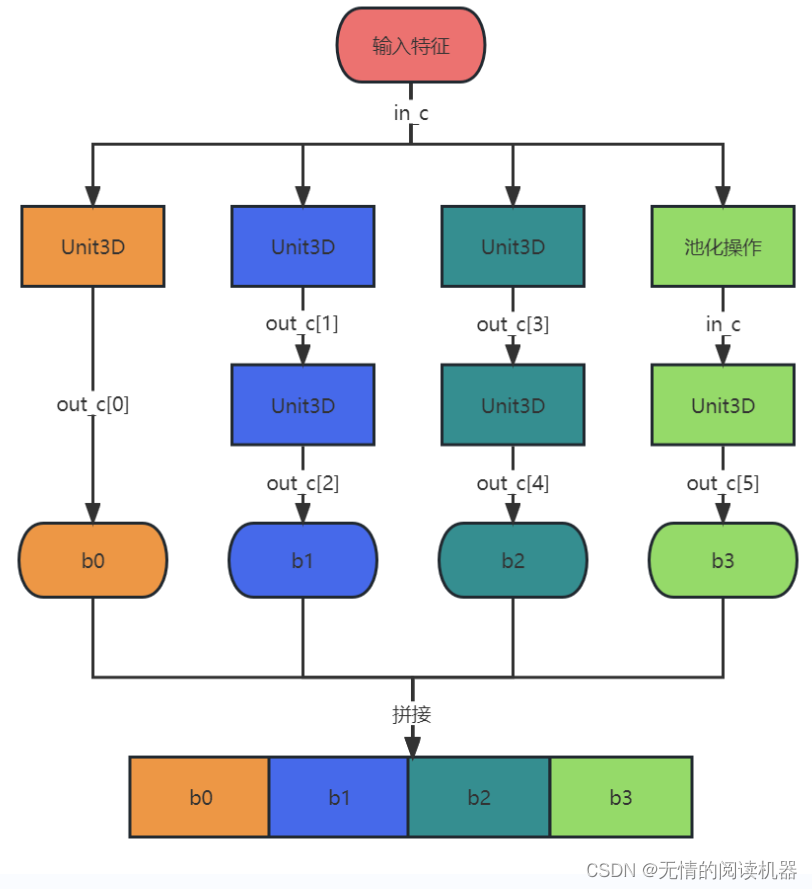
最终的特征提取网络结合了上述两个模块
在提取视频的过程中,作者用了Mixed_5c和Mixed_4c两层的输出
然后将其两层输出进一步卷积,池化,相加,变形,再卷积等最终输出了3维视频特征

3.点级别视频特征

每个query point附近的特征为
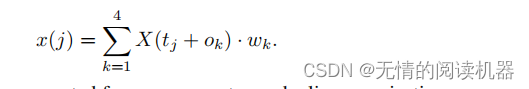
4.自注意力机制
为了挖掘不同动作(query)之间的关联,使用多头自注意力机制来学习query vector 得到对应的attention_query vector
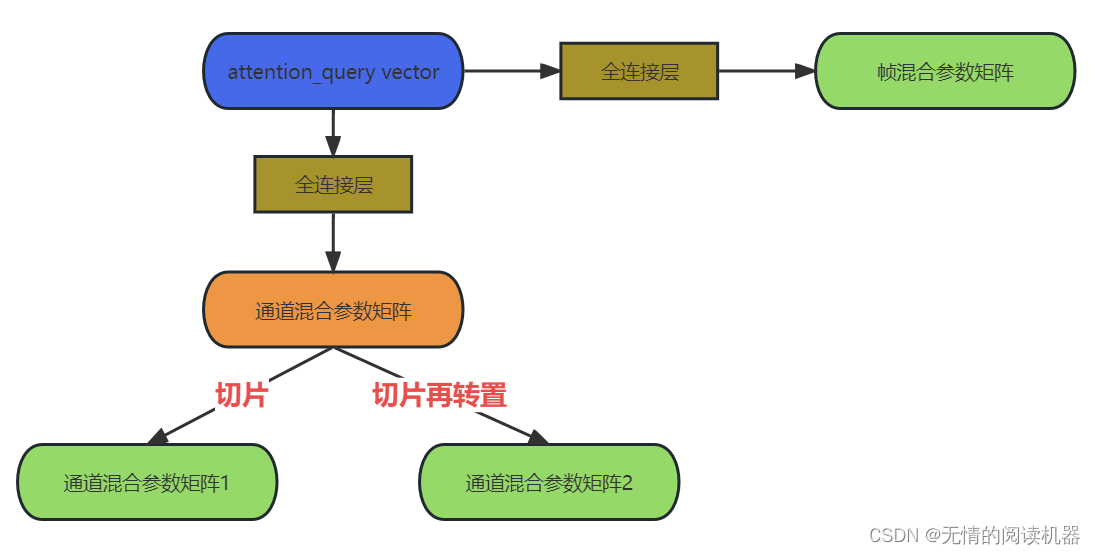
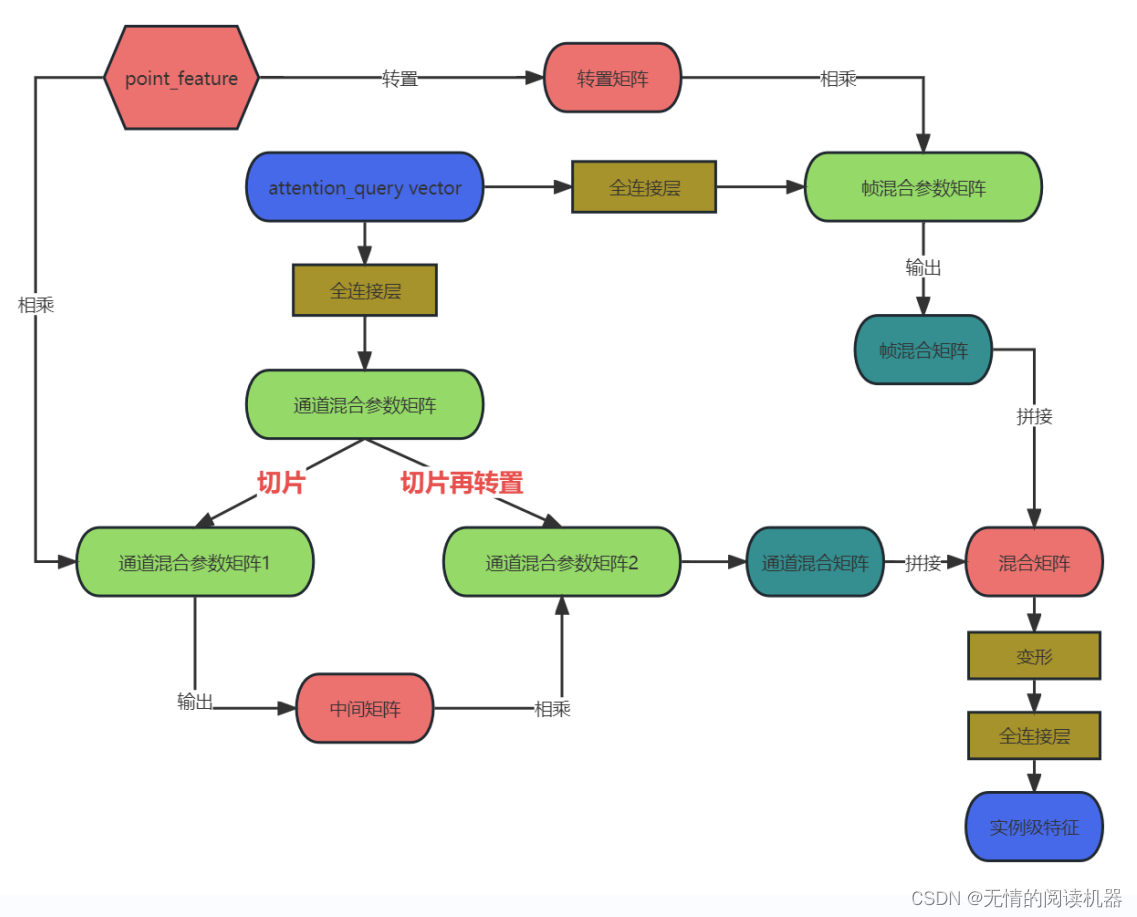
5.自适应混合帧和通道
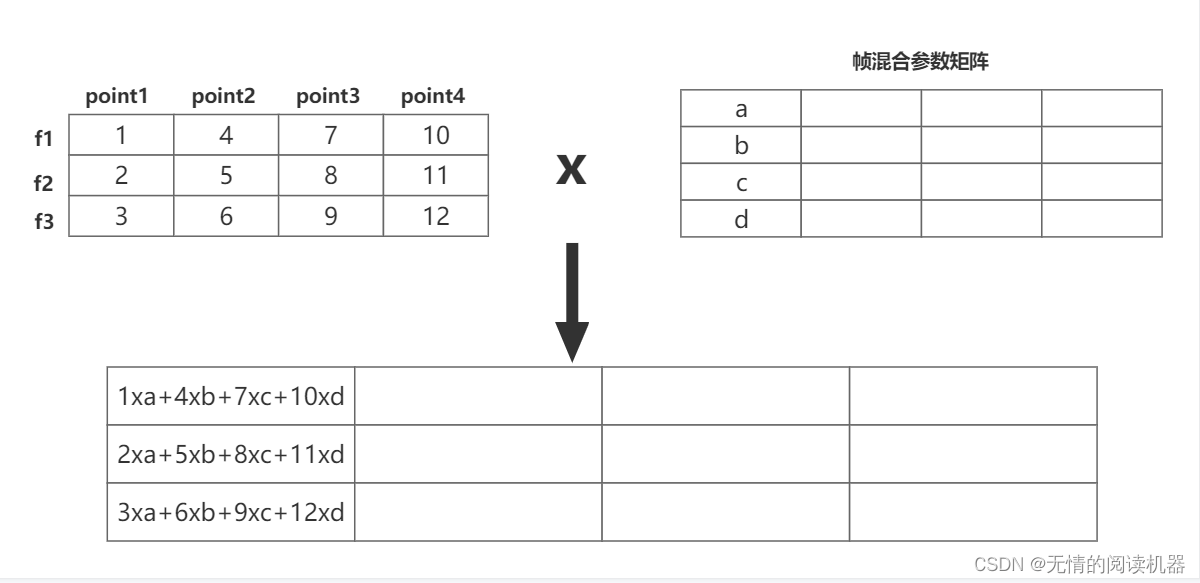
核心就是利用矩阵的乘法进行混合。
首先用attention_query vector得到三个参数矩阵
点级的视频特征point_feature如下所示:
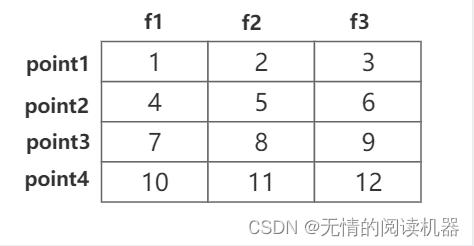
假如有4个点,每个点对应的特征是3为,点级视频特征如下所示:
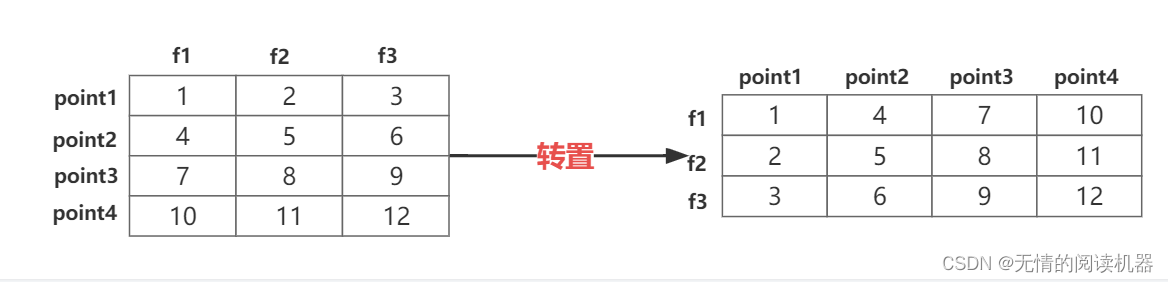
1)帧的混合
现在将point_feature转置
然后与通道混合参数矩阵相乘,此时我们发现point1处的特征,其他位置的point的特征也被混合了进来
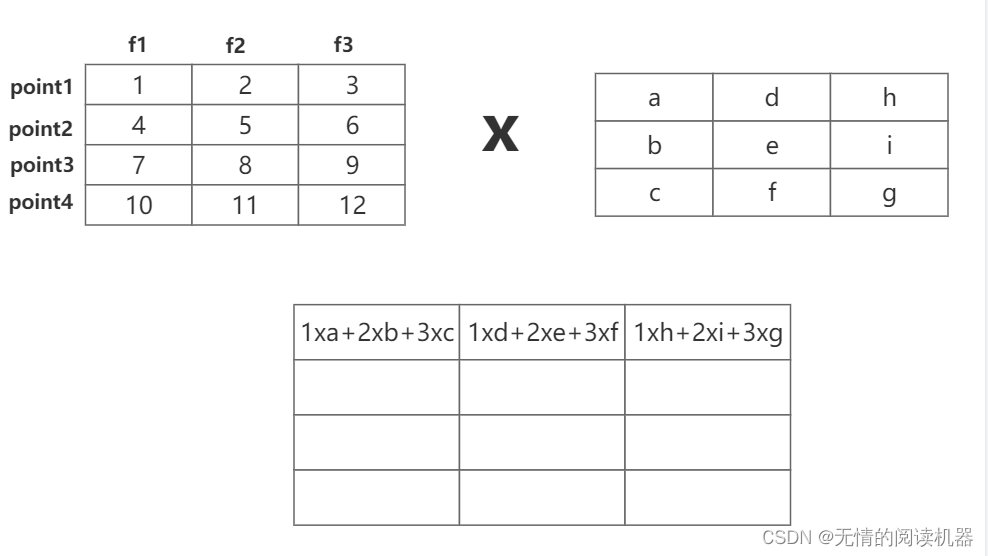
2)通道的混合
3)实例级特征的生成
6.预测过程
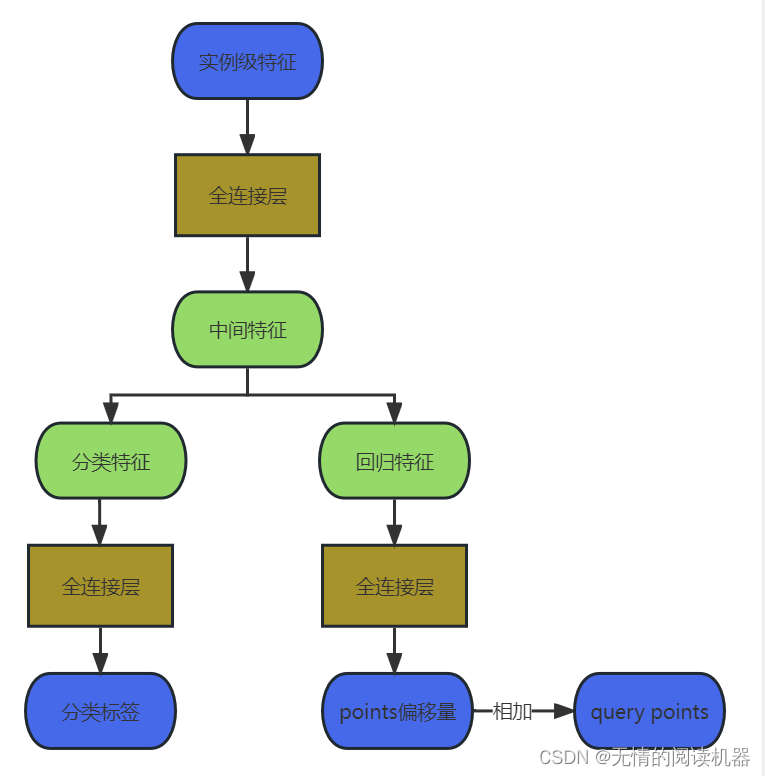
最终网络返回的不是query_points
而是segment,即一个动作开始到结束的范围
7.网络中的残差结构
需要注意的是网络运用了残差结构
1.在attention模块里面
2.实例级特征的产生
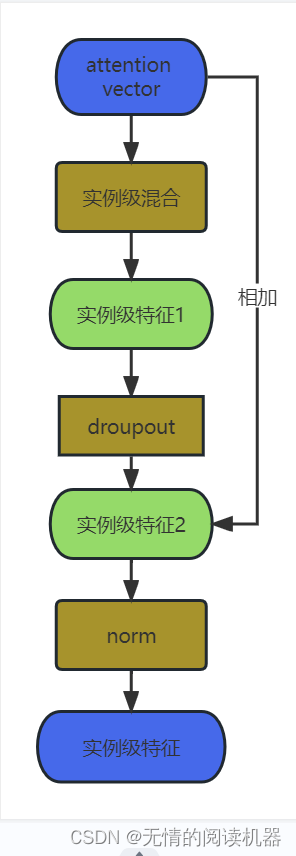
8.计算损失
1)预测结果与真实实例的匹配
通过三个成本来计算每个query的segment对应每个真实数据segment的成本。
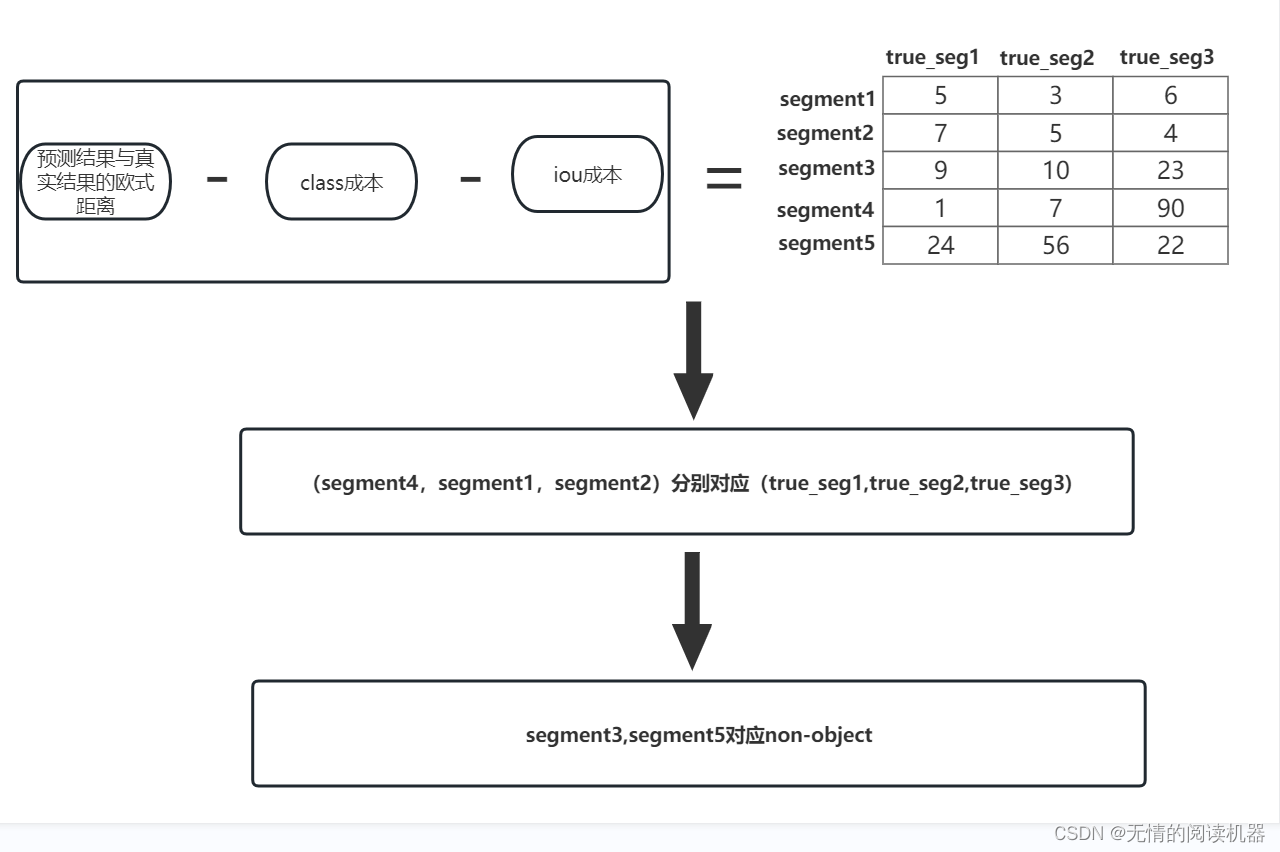
2) 交叉熵损失
假设:我们的动作类别为3类,那么再加上non-object就是4类
A类:1000,B类:0100,C类:0010,object:0001

3)位置损失
位置损失包含了回归损失和iou损失
其中回归损失如下:

损失就是sum(|x1-x2|+|y1-y2|)/真实segment的个数