一、介绍
ABC语言时一个致力于为初学者设计编程环境的长达十年的研究项目。
Python也从ABC那里继承了用统一的风格去处理序列数据这一特点。不管是哪种数据结构,字符串、列表、字节序列、数组、XML元素,抑或是数据库查询结果,它们都共用一套丰富的操作:迭代、切片、排序,还有拼接。
二、Python内置序列类型概览
1、按照存放内容的类型分类
1)容器序列:存放的是它们所包含的任意类型的对象的引用,例如:list、tuple和collections.deque。
2)扁平序列:存放的是值而不是引用。换句话说,扁平序列其实是一段连续的内存空间, 例如:str、bytes、bytearray、memoryview和array.array。
2、按照内容能否被修改来分类
1)可变序列(MutableSequence):例如:list、bytearray、array.array、collections.deque和memoryview。
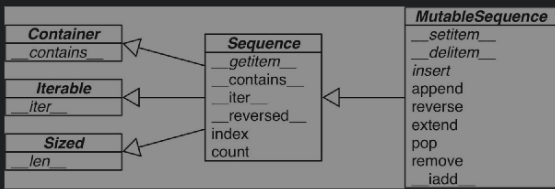
2)不可变序列(Sequence):例如:tuple、str和bytes
虽然内置的序列类型并不是直接从Sequence和MutableSequence这两个抽象基类(Abstract Base Class,ABC)继承而来的,但是了解这些基类可以帮助我们总结出那些完整的序列类型包含了哪些功能。
三、列表推导和生成器表达式
1、列表推导list comprehension:
1.1 基本语法
symbols='abcdefg'
codes = [ord(s) for s in symbols]
codes
Out[3]: [97, 98, 99, 100, 101, 102, 103]
1.2 列表推导同filter和map的比较
filter和map合起来能做的事情,列表推导也可以做,而且还不需要借助难以理解和阅读的lambda表达式。
比如,我们只想保留编码大于100 的字符
# map实现
beyond_ascii = list(filter(lambda c: c>100, map(ord, symbols)))
beyond_ascii
Out[5]: [101, 102, 103]
# 列表推导实现
beyond_ascii = [ord(s) for s in symbols if ord(s)>100]
beyond_ascii
Out[7]: [101, 102, 103]
1.3生成器表达式
虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。前面那种方式显然能够节省内存。
beyond_ascii = list(ord(s) for s in symbols if ord(s)>100)
beyond_ascii
Out[9]: [101, 102, 103]
四、tuple不只是不可变列表
1、tuple除了用作不可变的列表
它还可以用于没有字段名的记录。鉴于后者常常被忽略,我们先来看看元组作为记录的功用。
如果只把元组理解为不可变的列表,那其他信息——它所含有的元素的总数和它们的位置——似乎就变得可有可无。但是如果把元组当作一些字段的集合,那么数量和位置信息就变得非常重要
city,year,pop,chg,area=('Tokyo', 2003, 32450, 0.66, 8014)
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567')]
for passport in traveler_ids:
print('%s/%s'%(passport))
USA/31195855
BRA/CE342567
2、元组拆包
上面示例中,我们把元组(‘Tokyo’, 2003, 32450, 0.66, 8014)里的元素分别赋值给变量city、year、pop、chg和area,而这所有的赋值我们只用一行声明就写完了。同样,在后面一行中,一个%运算符就把passport元组里的元素对应到了print函数的格式字符串空档中。这两个都是对元组拆包的应用。
2.1另外一个很优雅的写法当属不使用中间变量交换两个变量的值:
a,b = b,a
2.2 还可以用*运算符把一个可迭代对象拆开作为函数的参数
divmod(20,8)
Out[12]: (2, 4)
t=(20,8)
divmod(*t)
Out[14]: (2, 4)
2.3 *args来获取不确定数量的参数
a, b, *rest = range(5)
a, b, rest
Out[16]: (0, 1, [2, 3, 4])
a, b, *rest = range(3)
a, b, rest
Out[18]: (0, 1, [2])
a, b, *rest = range(2)
a, b, rest
Out[20]: (0, 1, [])
a, *body, c, d = range(5)
a, body, c, d
Out[22]: (0, [1, 2], 3, 4)
*head, b, c, d = range(5)
head, b, c, d
Out[24]: ([0, 1], 2, 3, 4)
3、嵌套元组拆包
接受表达式的元组可以是嵌套式的,例如(a, b, (c, d))。只要这个接受元组的嵌套结构符合表达式本身的嵌套结构,Python就可以作出正确的对应。
4、具名元组
collections.namedtuple是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类——这个带名字的类对调试程序有很大帮助。
Card = collections.namedtuple('Card',['rank', 'suit'])
card = Card(28, 'heart')
card.rank
Out[30]: 28
card.suit
Out[31]: 'heart'
# 内部方法
card._fields
Out[32]: ('rank', 'suit')
card._asdict()
Out[33]: {'rank': 28, 'suit': 'heart'}
card_data = (27, 'heart')
card1 = Card._make(card_data)
card1
Out[36]: Card(rank=27, suit='heart')
5、作为不可变列表的元组
和列表相比,除了跟增减元素相关的方法之外,元组支持列表的其他所有方法。还有一个例外,元组没有__reversed__方法,但是这个方法只是个优化而已,reversed(my_tuple)这个用法在没有__reversed__的情况下也是合法的。
5.1列表或元组的方法和属性,那些有object支持的没有列出来
s = [1,2,3,4]
s1 = ['a', 'b', 'c', 'd']
# s 和s1拼接
s.__add__(s1)
Out[40]: [1, 2, 3, 4, 'a', 'b', 'c', 'd']
# add的结果会更改s的值
s.__iadd__(s1)
Out[41]: [1, 2, 3, 4, 'a', 'b', 'c', 'd']
s
Out[42]: [1, 2, 3, 4, 'a', 'b', 'c', 'd']
# 在尾部添加一个元素
s.append('e')
s
Out[46]: [1, 2, 3, 4, 'a', 'b', 'c', 'd', 'e']
# 删除所有元素
s.clear()
s
Out[48]: []
# 列表中是否包含某个元素
s.__contains__('a')
Out[49]: False
# copy():对于List来说,其第一层,是实现了深拷贝,但对于其内嵌套的List,仍然是浅拷贝。因为嵌套的List保存的是地址,复制过去的时候是把地址复制过去了,嵌套的List在内存中指向的还是同一个。
a = [1,[1,2,3],3]
b = a.copy()
b[0] = 3
b[1][0] = 3
a
Out[59]: [1, [3, 2, 3], 3]
# 'a'在s中出现的次数
s = ['a', 'b', 'c', 'a']
s.count('a')
Out[2]: 2
#把下标2位置的内容删除
s.__delitem__(2)
s
Out[4]: ['a', 'b', 'a']
# 在s中找到'a'第一次出现的位置
s.index('a')
Out[5]: 0
# 在位置1插入元素'z'
s.insert(1,'z')
s
Out[7]: ['a', 'z', 'b', 'a']
# 获取s的迭代器
s.__iter__()
Out[8]: <list_iterator at 0x2d4d4a35550>
iter(s)
Out[9]: <list_iterator at 0x2d4d4a35130>
# 获取s的元素数量
s.__len__()
Out[10]: 4
len(s)
Out[11]: 4
# 2个s的拼接
s*2
Out[12]: ['a', 'z', 'b', 'a', 'a', 'z', 'b', 'a']
s.__mul__(2)
Out[13]: ['a', 'z', 'b', 'a', 'a', 'z', 'b', 'a']
# 删除最后位置的值,并返回该值
s.pop()
Out[16]: 'a'
s
Out[17]: ['a', 'z', 'b']
# 删除1位置的值,并返回该值
s.pop(1)
Out[18]: 'z'
s
Out[19]: ['a', 'b']
# 删除s中第一次出现的'b'
s = ['a', 'b', 'c','a', 'b']
s.remove('b')
s
Out[22]: ['a', 'c', 'a', 'b']
# 将s的元素倒序排序
s.reverse()
s
Out[25]: ['b', 'a', 'c', 'a']
# 返回s的倒序迭代器
reversed(s)
Out[26]: <list_reverseiterator at 0x2d4d37589a0>
s.__reversed__()
Out[27]: <list_reverseiterator at 0x2d4d3758820>
# 将s中位置为1的元素设置为'f',替换现有元素
s.__setitem__(1, 'f')
s
Out[29]: ['b', 'f', 'c', 'a']
# 对s中的元素进行排序
s.sort()
s
Out[31]: ['a', 'b', 'c', 'f']
五、切片
1、在Python里,像列表(list)、元组(tuple)和字符串(str)这类序列类型都支持切片操作。
1.1 为什么切片和区间会忽略最后一个元素?
在切片和区间操作里不包含区间范围的最后一个元素是Python的风格,这个习惯符合Python、C和其他语言里以0作为起始下标的传统。这样做带来的好处如下。
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:range(3)和my_list[:3]都返回3个元素。
- 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop-start)即可。
- 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成my_list[:x]和my_list[x:]就可以了
l = [1, 2, 3, 4, 5, 6]
l[:2]
Out[33]: [1, 2]
l[2:]
Out[34]: [3, 4, 5, 6]
2、反向切片及间隔切片
s[::3]
Out[36]: 'bye'
s[::-1]
Out[37]: 'elcycib'
s[::-2]
Out[38]: 'eccb'
3、slice对象切片
price = slice(6,10)
l = 'banana10'
l[price]
Out[41]: '10'
4、给切片赋值
如果把切片放在赋值语句的左边,或把它作为del操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作。
l = list(range(10))
l
Out[43]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
l[2:5] = [20, 30]
l
Out[45]: [0, 1, 20, 30, 5, 6, 7, 8, 9]
del l[5:7]
l
Out[47]: [0, 1, 20, 30, 5, 8, 9]
# 如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。即便只有单独一个值,也要把它转换成可迭代的序列
l[2:5] = [100]
l
Out[49]: [0, 1, 100, 8, 9]
l[1:4] = 100
TypeError: can only assign an iterable
5、序列的加和乘
l = [1,2,3]
l*5
Out[52]: [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
2*'abcd'
Out[53]: 'abcdabcd'
l + ['a', 'b']
Out[55]: [1, 2, 3, 'a', 'b']
+和*都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列。
如果在a * n这个语句中,序列a里的元素是对其他可变对象的引用的话,你就需要格外注意了,因为这个式子的结果可能会出乎意料。比如,你想用my_list=[[]] * 3来初始化一个由列表组成的列表,但是你得到的列表里包含的3个元素其实是3个引用,而且这3个引用指向的都是同一个列表。这可能不是你想要的效果
6、序列的增量赋值
增量赋值运算符+=和*=的表现取决于它们的第一个操作对象。简单起见,我们把讨论集中在增量加法(+=)上,但是这些概念对*=和其他增量运算符来说都是一样的。+=背后的特殊方法是__iadd__ (用于“就地加法”)。
例:a+=b
如果a实现了__iadd__方法,就会调用这个方法。同时对可变序列(例如list、bytearray和array.array)来说,a会就地改动,就像调用了a.extend(b)一样。但是如果a没有实现__iadd__的话,a+=b这个表达式的效果就变得跟a=a+b一样了:首先计算a+b,得到一个新的对象,然后赋值给a。也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现__iadd__这个方法。
总体来讲,可变序列一般都实现了__iadd__方法,因此+=是就地加法。而不可变序列根本就不支持这个操作,对这个方法的实现也就无从谈起。
# 可变序列
l = [1, 2, 3]
id(l)
Out[57]: 3113136609344
l *=2
l
Out[59]: [1, 2, 3, 1, 2, 3]
id(l)
Out[60]: 3113136609344
# 不可变序列
t = (1,2,3)
id(t)
Out[65]: 3113136658752
t*=2
t
Out[67]: (1, 2, 3, 1, 2, 3)
id(t)
Out[68]: 3113123807680
6.1 关于+=的谜题
t = (1, 2, [20, 30])
t[2] += [50, 60]
到底会发生下面4种情况中的哪一种?
- a. t变成(1, 2, [30, 40, 50, 60])。
- b.因为tuple不支持对它的元素赋值,所以会抛出TypeError异常。
- c.以上两个都不是。
- d. a和b都是对的。
我刚看到这个问题的时候,异常确定地选择了b,但其实答案是d,也就是说a和b都是对的!示例2-15是运行这段代码得到的结果,用的Python版本是3.4,但是在2.7中结果也一样。
t = (1, 2, [20, 30])
t[2] += [50, 60]
TypeError: 'tuple' object does not support item assignment
t
Out[72]: (1, 2, [20, 30, 50, 60])
# 避免抛错的写法
t[2].extend([60,70])
t
Out[74]: (1, 2, [20, 30, 50, 60, 60, 70])
1. 不要把可变对象放在元组里面。2.增量赋值不是一个原子操作。我们刚才也看到了,它虽然抛出了异常,但还是完成了操作。3.查看Python的字节码并不难,而且它对我们了解代码背后的运行机制很有帮助
7、list.sort方法和内置函数sorted
list.sort方法会就地排序列表,也就是说不会把原列表复制一份。这也是这个方法的返回值是None的原因,提醒你本方法不会新建一个列表。在这种情况下返回None其实是Python的一个惯例:如果一个函数或者方法对对象进行的是就地改动,那它就应该返回None,好让调用者知道传入的参数发生了变动,而且并未产生新的对象。例如,random.shuffle函数也遵守了这个惯例。
与list.sort相反的是内置函数sorted,它会新建一个列表作为返回值。不管是list.sort方法还是sorted函数,都有两个可选的关键字参数。
- 如果被设定为True,被排序的序列里的元素会以降序输出(也就是说把最大值当作最小值来排序)。这个参数的默认值是False。
- 一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字。比如说,在对一些字符串排序时,可以用key=str.lower来实现忽略大小写的排序,或者是用key=len进行基于字符串长度的排序。这个参数的默认值是恒等函数(identity function),也就是默认用元素自己的值来排序。
fruits = ['grep', 'raspberry', 'apple', 'banana']
sorted(fruits)
Out[76]: ['apple', 'banana', 'grep', 'raspberry']
fruits
Out[77]: ['grep', 'raspberry', 'apple', 'banana']
sorted(fruits, reverse=True)
Out[78]: ['raspberry', 'grep', 'banana', 'apple']
8、 其他序列类型
虽然列表既灵活又简单,但面对各类需求时,我们可能会有更好的选择。比如,要存放1000万个浮点数的话,数组(array)的效率要高得多,因为数组在背后存的并不是float对象,而是数字的机器翻译,也就是字节表述。再比如说,如果需要频繁对序列做先进先出的操作,deque(双端队列)的速度应该会更快。
8.1 数组
如果我们需要一个只包含数字的列表,那么array.array比list更高效。数组支持所有跟可变序列有关的操作,包括.pop、.insert和.extend。另外,数组还提供从文件读取和存入文件的更快的方法,如.frombytes和.tofile。
8.2 内存视图
memoryview是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片
8.3 双向队列及其他形式的队列
利用.append和.pop方法,我们可以把列表当作栈或者队列来用(比如,把.append和.pop(0)合起来用,就能模拟队列的“先进先出”的特点)。但是删除列表的第一个元素(抑或是在第一个元素之前添加一个元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所有元素。
collections.deque类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存放“最近用到的几个元素”,deque也是一个很好的选择。这是因为在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素。
from collections import deque
dq = deque(range(10), maxlen=10)
dq
Out[81]: deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
dq.rotate(3)
dq
Out[83]: deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6])
dq.rotate(-4)
dq
Out[85]: deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
dq.appendleft(-1)
dq
Out[87]: deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9])
dq.extend([11, 22, 33])
dq
Out[89]: deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33])
dq.extendleft([10, 20, 30, 40])
dq
Out[91]: deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8])
除了deque之外,还有些其他的Python标准库也有对队列的实现。queue提供了同步(线程安全)类Queue、LifoQueue和PriorityQueue,不同的线程可以利用这些数据类型来交换信息。
- multiprocessing这个包实现了自己的Queue,它跟queue.Queue类似,是设计给进程间通信用的。同时还有一个专门的multiprocessing.JoinableQueue类型,可以让任务管理变得更方便。
- asyncioPython 3.4新提供的包,里面有Queue、LifoQueue、PriorityQueue和JoinableQueue,这些类受到queue和multiprocessing模块的影响,但是为异步编程里的任务管理提供了专门的便利。
- heapq跟上面三个模块不同的是,heapq没有队列类,而是提供了heappush和heappop方法,让用户可以把可变序列当作堆队列或者优先队列来使用。
参考《流畅的python》