一、基础知识了解:
结构体的理解:
我们知道整型是由1位符号位和15位数值位组成,而就可以把结构体理解为我们定义的数据类型,如:
typedef struct
{
int data[2]; //存储顺序表中的元素
int len; //顺序表的表长
}SeqList; //顺序表类型
在这个结构体中我们定义前2*16位存放顺序表中的数据,最后1*16位存放表长
对于:
SeqList List;这个就是类似于整型的一个结构体类型的变量,我们可以通过(List.len/List.data[i])调用结构体变量中的元素。
对于:
SeqList *L;//等同于int *L;,只不过可指向的数据类型不同不过跟int *L;相同的,定义只是一个空指针,需要通过申请一段内存空间才能使用:
L=(SeqList*)malloc(sizeof(SeqList));结构体变量的地址:
结构体变量的地址为首个成员的地址
指针的理解:
指针是一种通过指向地址来操纵数据的方式
如:
typedef struct
{
//MAXSIZE是根据实际问题所定义的一个足够大的整数
//datatype为顺序表中元素的类型,在具体实现中可为int、float、char类型或其他结构类型
datatype data[MAXSIZE]; //存储顺序表中的元素
int len; //顺序表的表长
}SeqList; //顺序表类型
//构造一个空表
SeqList *Init_SeqList()
{
SeqList *L;//建立一个SeqList类型的空指针
L=(SeqList*)malloc(sizeof(SeqList));//申请空间,并让L指向该空间的地址
L->len=0; //顺序表的表长为0
return L;
}
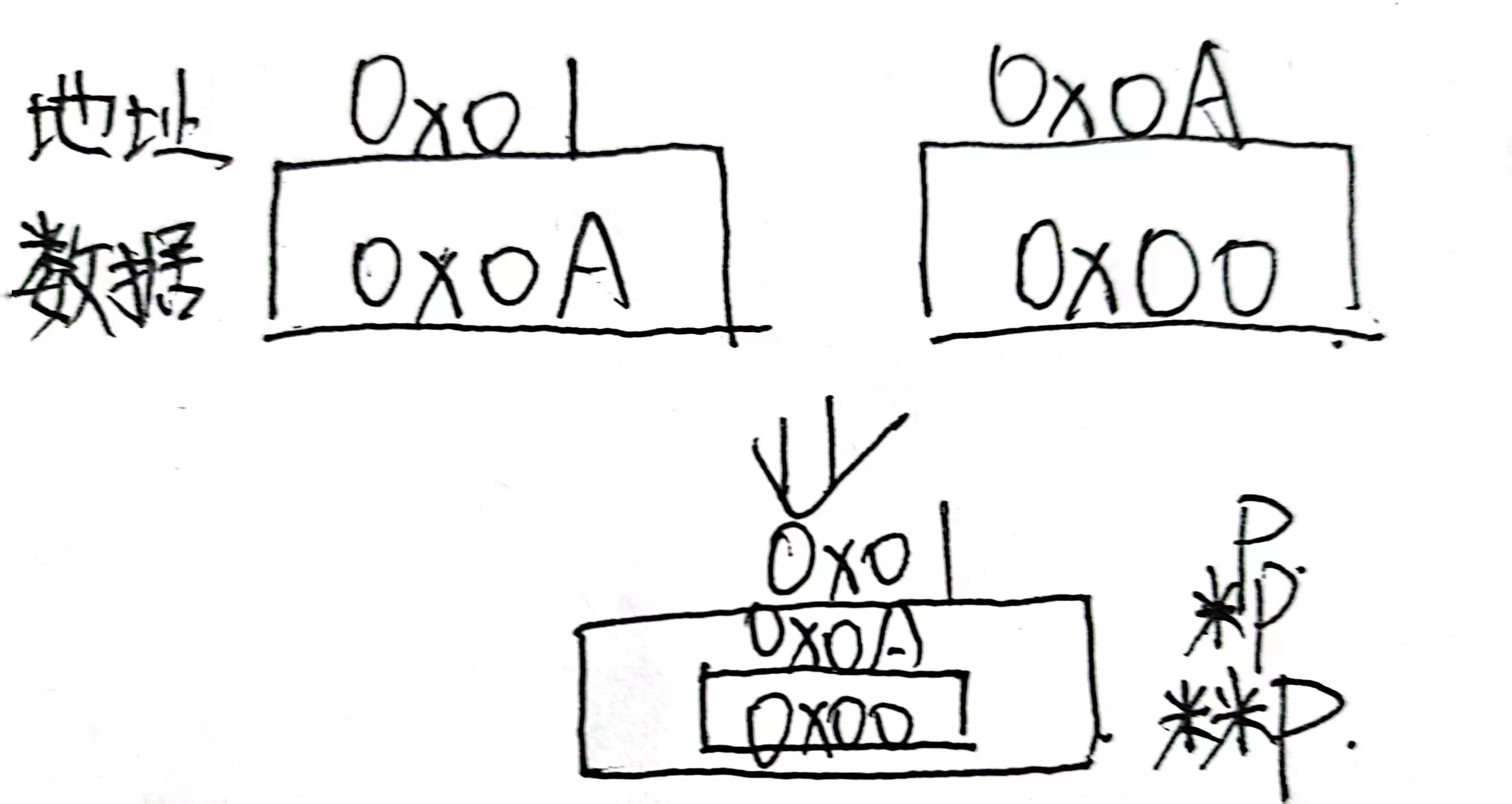
对SeqList **L的理解:
对于:
typedef struct node
{
datatype data; //data为结点的数据信息
struct node *next; //与SeqList *L;类似,存放了另一个LNode结构体变量的首地址
}LNode;
我们可以重点看struct node *next; ,如果我们要操作next地址对应结构体的数据data,我们就要用到SeqList **L
如:
一、顺序表
顺序表定义:
typedef struct
{
//datatype为表中元素类型(int,float等)
//元素存放在data数组中
//MAXSIZE是根据实际问题所定义的一个足够大的整数
datatype data[MAXSISE];
int len;//表长
}SeqList;指向顺序表的指针变量
SeqList list,*L;
//list是结构体变量,它内部含有一个可存储顺序表的data数组
//L是指向List这类结构体变量的指针变量其中:
(1)List.data[i]或L->data[i]均表示顺序表中第i个元素的值
(2)List.len或L->len均表示顺序表的表长
(3)“L=(SeqList*)malloc(sizeof(SeqList));”表示生成一个顺序表存储空间
顺序表的初始化

typdefine struct
{
datatype data[MAXSIZE];
int len;
}Seqlist;
Seqlist *seqlist_Init()
{
Seqlist *l;
l = (Seqlist*)malloc(sizeof(Seqlist));
l->len = 0;
return l;
}建立顺序表:(没搞懂)
(1)头部插入
先读取需要输入数据个数,再进行读取外部数据操作,最后将数据按顺序存放到顺序表中的数组
void CreatList(SeqList **L)
{
int i, n;
printf("Input length of List: ");
scanf("%d", &n);
printf("Input elements of List: \n");
for(i=1;i<=n;i++)
scanf("%d", &(*L)->data[i]);
(*L)->len=n;
}(2)尾部插入
LNode *CreateLinkList()
{
LNode *head, *p, *q;
char x;
head=(LNode*)malloc(sizeof(LNode)); //生成头结点
head->next=NULL;
p=head; q=p; //指针q始终指向链尾结点
printf("Input any char string: \n");
scanf("%c", &x);
while(x!='\n') //生成链表的其他结点
{
p=(LNode*)malloc(sizeof(LNode));
p->data=x;
p->next=NULL;
q->next=p; //在链尾插入
q=p;
scanf("%c", &x);
}
return head; //返回单链表表头指针
}
插入运算:
先判断表是否满了和插入位置是否合理,再将i到len个从后面到前面逐个向后移,最后再插入到第i个位置
void Insert_SeqList(SeqList *L, int i, datatype x)
{
int j;
if(L->len==MAXSIZE-1) //表满
printf("The List is full!\n");
else
if(i<1|| i>L->len+1) //插入位置非法
printf("The position is invalid !\n");
else
{
for(j=L->len;j>=i;j--) //将an~ai顺序后移一个元素位置
L->data[j+1]=L->data[j];
L->data[i]=x; //插入x到第i个位置
L->len++; //表长增1
}
}}
删除运算:
void Del_LinkList(LNode *head , int i)
{ //删除单链表head上的第i个数据结点
LNode *p, *q;
p=Get_LinkList(head, i-1); //查找第i-1个结点
if(p==NULL)
printf("第i-1个结点不存在!\n ");
//待删结点的前一个结点不存在,无待删结点
else
if(p->next==NULL)
printf("第i个结点不存在!\n"); //待删结点不存在
else
{
q=p->next; //q指向第i个结点
p->next=q->next; //从链表中删除第i个结点
free(q); //系统回收第i个结点的存储空间
}
}
查找:
给值查找存储位置:以该一位元素是否为x和该位是否在在顺序表中为判断条件,最后如果跳出时的元素为x则返回i,不是则返回0
int Location_SeqList(SeqList *L, datatype x)
{
int i=1; //从第一个元素开始查找
while(i<L->len&&L->data[i]!=x)
//顺序表未查完且当前元素不是要找的元素
i++;
if(L->data[i]==x)
return i; //找到则返回其位置值
else
return 0; //未找到则返回0值
}
二、单链表
单链表结点定义:
只需要定义一个存放数据和后一个节点地址的结构体就行
typedef struct node
{
datatype data; //data为结点的数据信息
struct node *next; //next为指向后继结点的指针
}LNode; //单链表结点类型
建立单链表:
首先建立一个任意的头节点,读取外部输入数据,
void CreateLinkList(LNode **head)
{ //将主调函数中指向待生成单链表的指针地址(如&p)传给**head
char x;
LNode *p;
*head=(LNode *)malloc(sizeof(LNode)); //在主调函数空间生成链表头结点
(*head)->next=NULL; //*head为链表头指针
printf("Input any char string: \n");
scanf("%c", &x); //结点的数据域为char型,读入结点数据
while(x!='\n') //生成链表的其他结点
{
p=(LNode *)malloc(sizeof(LNode)); //申请一个结点空间
p->data=x;
p->next=(*head)->next; //将头结点的next值赋给新结点*p的next
(*head)->next=p; //头结点的next指针指向新结点*p实现在表头插入
scanf("%c", &x); //继续生成下一个新结点
}
(1)为什么使用LNode **head?(未解决)
由于我们要与主函数联系起来,必须确定头节点的
查找:
(1)按序号:
根据指针域一直寻址到第i个结点,以循环次数与最后一个节点为结束标志
LNode *Get_LinkList(LNode *head, int i)
{ //在单链表head中查找第i个结点
LNode *p=head; //由第一个结点开始查找
int j=0;
while(p!=NULL&&j<i) //当未查到链尾且j小于i时继续查找
{
p=p->next;
j++;
}
return p; //找到则返回指向i结点的指针值,找不到则p返回空值
}
(2)按值查找:
根据指针域一直寻址,以找到目标值和最后一个数为结束标志
LNode *Locate_LinkList(LNode *head, char x)
{ //在单链表中查找结点值为x的结点
LNode *p=head->next; //由第一个数据结点开始查找
while(p!=NULL&&p->data!=x)
//当未查到链尾且当前结点不等于x时继续查找
p=p->next;
return p;
//找到则返回指向值为x的结点的指针值,找不到则p返回空值
}
求表长:
从第一个结点寻址到最后一个结点,并做计数
int Length_LinkList(LNode *head)
{
LNode *p=head; //p指向单链表头结点
int i=0; //i为结点计数器
while(p->next!=NULL)
{
p=p->next;
i++;
}
return i; //返回表长值i
}
插入:
利用查找函数获得第i-1个结点的地址,如果该结点地址为空(即最后一个结点),说明插入操作非法;如果不为空,创建一个新节点数据域存放插入数据,指针域域存放下一个结点的地址,上一个结点的指针域放新节点的地址
void Insert_LinkList(LNode *head, int i, char x)
{ //在单链表head的第i个位置上插入值为x的元素
LNode *p, *q;
p=Get_LinkList(head, i-1); //查找第i-1个结点*/
if(p==NULL)
printf("Error ! \n"); //第i-1个位置不存在而无法插入
else
{
q=(LNode *)malloc(sizeof(LNode)); //申请结点空间
q->data=x;
q->next=p->next; //完成插入操作①
p->next=q; //完成插入操作②
}
}
删除:
首先像插入操作一样判断删除操作是否非法,如果合法,则让第i-1个结点的地址域直接存放第i+1个结点的地址,同时把第i个结点的空间释放
算法如下:
void Del_LinkList(LNode *head , int i)
{ //删除单链表head上的第i个数据结点
LNode *p, *q;
p=Get_LinkList(head, i-1); //查找第i-1个结点
if(p==NULL)
printf("第i-1个结点不存在!\n ");
//待删结点的前一个结点不存在,无待删结点
else
if(p->next==NULL)
printf("第i个结点不存在!\n"); //待删结点不存在
else
{
q=p->next; //q指向第i个结点
p->next=q->next; //从链表中删除第i个结点
free(q); //系统回收第i个结点的存储空间
}
}
三、循环链表
查找循环链表中某个数:
与单链表类似,只不过最后的一个查找的地址不是NULL而是头节点
LNode *Locate_CycLink(LNode *head, datatype x)
{
LNode *p=head->next; //由第一个数据结点开始查
while(p!=head&&p->data!=x)//未查完循环链表且当前结点不等于x时继续查找
p=p->next;
if(p!=head) //head 代表结束点
return p; //找到值等于x的结点*p,返回其指针值p
else
return NULL; //当p又查到头结点时则无等于x值的结点,故返回NULL值
}
四、单链表应用
例1:

通过两个指针将
void Convert(LNode *H)
{
LNode *p, *q;
p=H->next; //p指向剩余结点链表的第一个数据结点
H->next=NULL; //新链表H初始为空
while(p!=NULL)
{
q=p; //从剩余结点链表中取出第一个结点
p=p->next; //p继续指向剩余结点链表新的第一个数据结点
q->next=H->next; //将取出的结点*q插入新链表H的链首
H->next=q;
}
}
例2:

首先把A的头节点赋给C,释放B的头节点,再将A、B中较小的用头插法赋给C,再该链表推进到下一个结点,循环该操作直到A,B中任意一方到最后一个结点,最后将剩余元素用头插法赋给C
void Merge(LNode *A, LNode *B, LNode **C)
{ //将增序链表A、B合并成降序链表*C
LNode *p, *q, *s;
p=A->next; //p始终指向链表A的第一个未比较的数据结点
q=B->next; //q始终指向链表B的第一个未比较的数据结点
*C=A; //生成链表的*C的头结点
(*C)->next=NULL;
free(B); //回收链表B的头结点空间
while(p!=NULL&&q!=NULL)
{ //将A、B两链表中当前比较结点中值小者赋给*s
if(p->data<q->data)
{
s=p; p=p->next;
}
else
{
s=q; q=q->next;
}
s->next=(*C)->next; //用头插法将结点*s插到链表*C的头结点之后
(*C)->next=s;
}
if(p==NULL) //如果指向链表A的指针*p为空,则使*p指向链表B
p=q;
while(p!=NULL)
{//将*p所指链表中的剩余结点依次摘下插入链表*C的链首
s=p;p=p->next;
s->next=(*C)->next; (*C)->next=s;
}
例3:

首先建立一个单链表,再将最后一个地址域赋上头节点地址形成循环列表,
void Josephus(int n, int m, int k)
{
LNode *p, *q;
int i;
p=(LNode*)malloc(sizeof(LNode));
q=p;
for(i=1;i<n;i++) //从编号k开始建立一个单链表
{
q->data=k;
k=k%n+1;
q->next=(LNode*)malloc(sizeof(LNode));
q=q->next;
}
q->data=k; q->next=p; //链接成循环单链表,此时p指向编号为k的结点
while(p->next!=p) //当循环单链表中的结点个数不为1时
{
for(i=1;i<m;i++)
{
q=p; p=p->next;
} //p指向报数为m的结点,q指向报数为m-1的结点
q->next=p->next; //删除报数为m的结点
printf("%4d", p->data); //输出出圈人的编号
free(p); //释放被删结点的空间
p=q->next; //p指向新的开始报数结点
}
printf("%4d", p->data); //输出最后出圈人的编号
}