Shuffle
-
- 一、配置项调优
- 二、减少shuffle数据量
- 三、避免shuffle
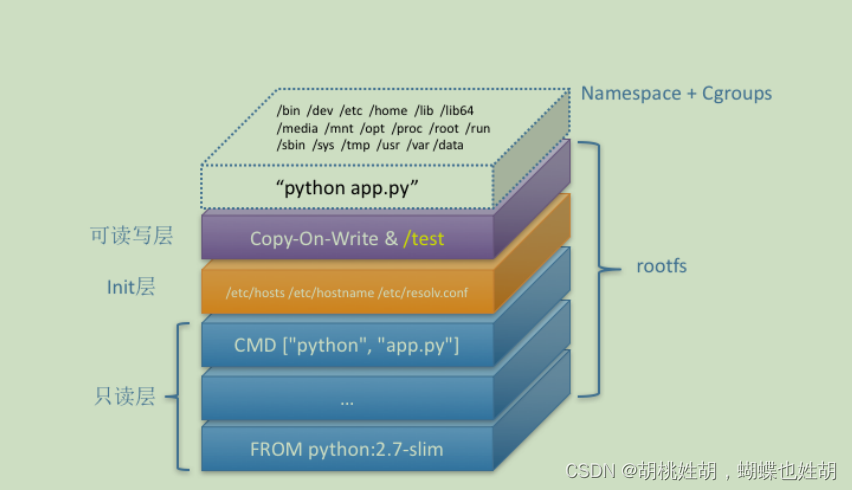
何为shuffle?
- 集群中跨进程、跨节点的数据分发(Map的输出文件写到本地磁盘,Reducer把Map的输出文件拉到本地)
为什么要shuffle?
- 准确的说,shuffle是刚需(业务场景决定的),分布式环境中,不同节点不能进行内存交换,只能先落到磁盘,然后通过网络分发
一、配置项调优

1、Shuffle Map阶段,计算结果会以中间文件形式写入到磁盘文件系统,为了避免频繁的IO操作,spark会把中间文件写入的缓冲区,就是上述Map端的参数,可以扩大spark.shuffle.file.buffer,缓冲区越大,spark需要刷盘次数越少
2、同样地,Shuffle reduce阶段,spark会通过网络分发从不同节点中拉取中间文件,读缓冲区越大,拉取数据的网络请求就越少,可以通过设置spark.reducer.maxSizeInFight来控制Reduce端缓冲区大小
3、Spark 1.6后,spark基本不用spark shuffle,开始使用sort shuffle,这在map和reduce阶段都会产生排序,但对于一些不需要排序的场景,可以设置spark.shuffle.byPassMergeThreshold Map阶段不进行排序的分区阈值,只要reducer数量小于这个值,就可以不排序,避免额外的排序开销