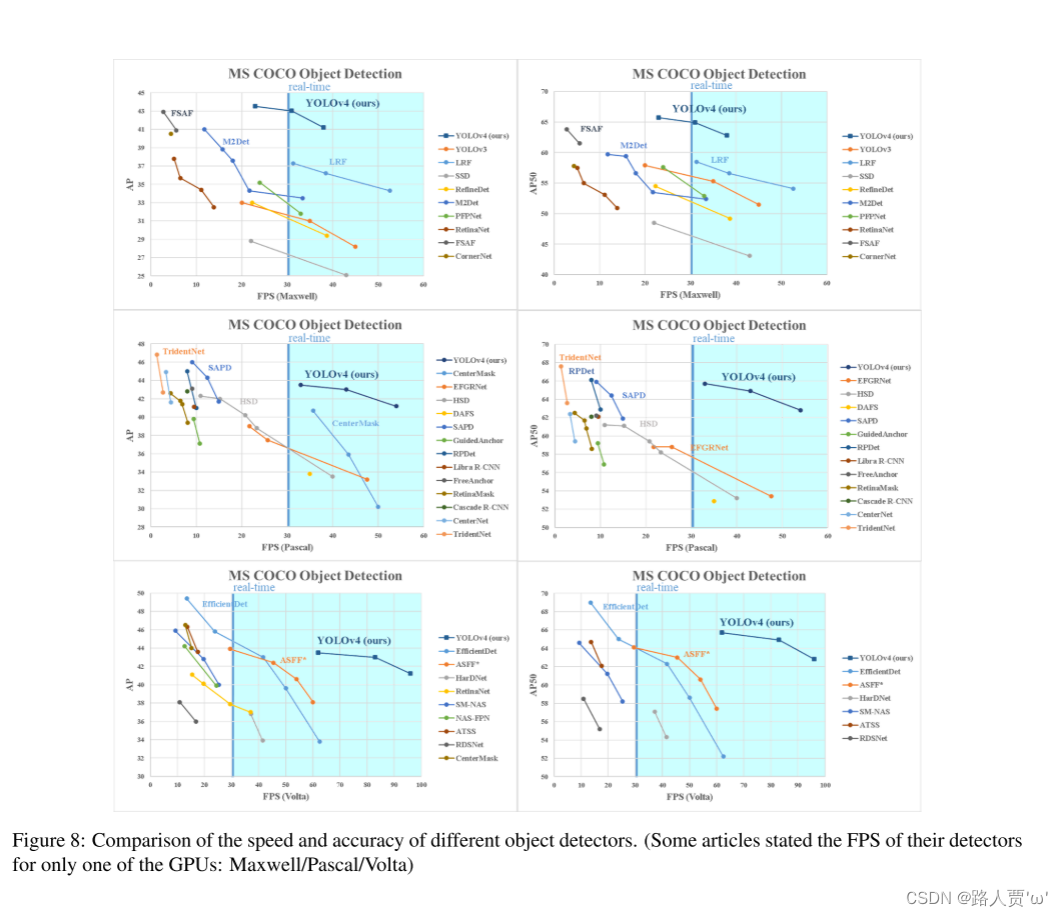
1 背景知识
1.1 CLOG使用的全局变量XactLastRecEnd
XLogRecPtr ProcLastRecPtr = InvalidXLogRecPtr;
XLogRecPtr XactLastRecEnd = InvalidXLogRecPtr;
XLogRecPtr XactLastCommitEnd = InvalidXLogRecPtr;
其中ProcLastRecPtr、XactLastRecEnd更新位置XLogInsertRecord:
XLogInsertRecord()
...
...
/*
* Update our global variables
*/
ProcLastRecPtr = StartPos;
XactLastRecEnd = EndPos;
-
XactLastRecEnd表示,当前事务所有xlog的最后一个位置。
- 在顶层事务提交、回滚时更新。
- 可以从XactLastRecEnd知道当前事务有没有生成xlog。
-
ProcLastRecPtr表示,当前事务插入的最后一个xlog的 起始位置。
1.2 CLOG中的group_lsn
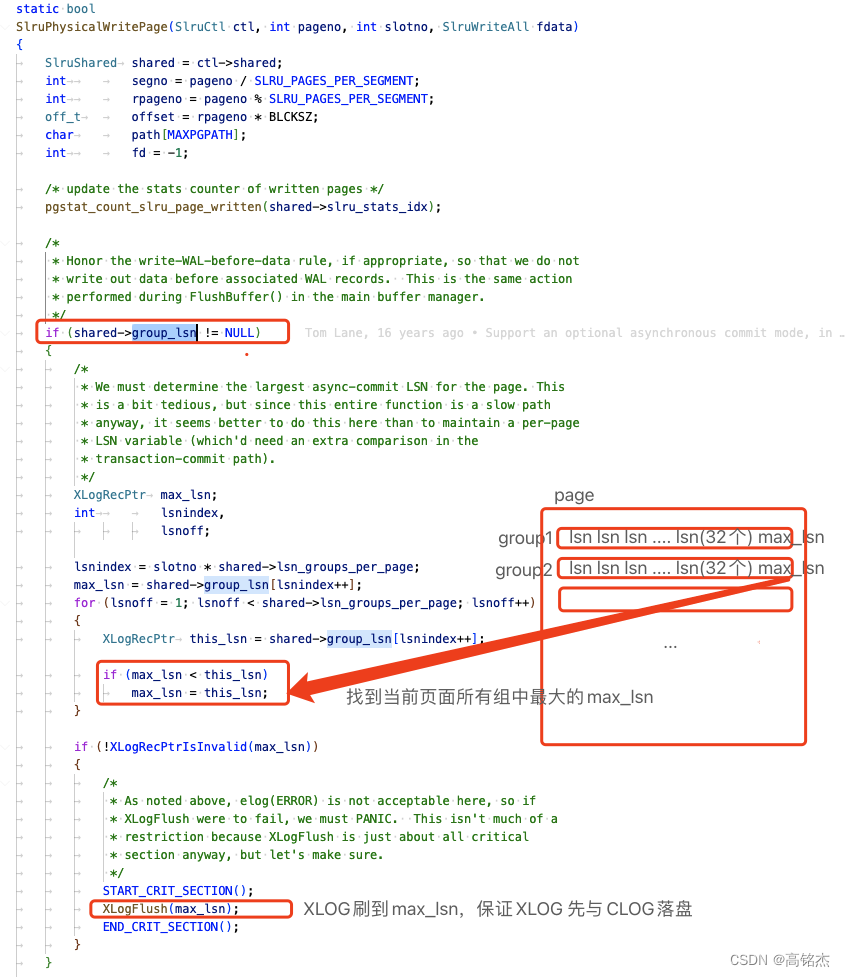
Postgresql中的XLOG和CLOG是分开保存的,所以存在先写后写的问题。
- 场景一:XLOG落盘,CLOG没落盘
- 没问题,XLOG中有commit log,在redo中会重建clog。
- 场景二:XLOG没落盘,CLOG落盘
- 有问题:事务在clog中查询到已提交,但XLOG丢失redo无法恢复该事物,所以该事物应该是未提交状态,与CLOG矛盾——发生数据不一致。
在同步提交场景下:可以保证XLOG一定先与CLOG落盘。
在异步提交场景下:从下图中可以看到,没有XlogFlush的过程,所以可能发生上述场景二的问题。
所以在异步移交场景下,Postgresql做了另外一层保护,使用group_lsn来保证xlog先与clog落盘,
/* We store the latest async LSN for each group of transactions */
#define CLOG_XACTS_PER_LSN_GROUP 32 /* keep this a power of 2 */
#define CLOG_LSNS_PER_PAGE (CLOG_XACTS_PER_PAGE / CLOG_XACTS_PER_LSN_GROUP)
每个逻辑组保存32个事务状态,每个页面有CLOG_LSNS_PER_PAGE个组。
1.3 全局唯一的PROC HDR结构
其中CLOG组提交会使用到的是clogGroupFirst,记录int类型,指向procs中,第一个等待组提交的那个proc(组提交leader)。
typedef struct PROC_HDR
{
/* Array of PGPROC structures (not including dummies for prepared txns) */
PGPROC *allProcs;
/* Array mirroring PGPROC.xid for each PGPROC currently in the procarray */
TransactionId *xids;
/*
* Array mirroring PGPROC.subxidStatus for each PGPROC currently in the
* procarray.
*/
XidCacheStatus *subxidStates;
...
...
/* First pgproc waiting for group XID clear */
pg_atomic_uint32 procArrayGroupFirst;
/* First pgproc waiting for group transaction status update */
pg_atomic_uint32 clogGroupFirst; <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
...
...
} PROC_HDR;
1.4 每个进程的PROC结构
- clogGroupMember:布尔,当前proc是不是在使用组提交?
- clogGroupNext:原子int,指向下一个组成员proc(allprocs数组中的位置)
- clogGroupMemberXid:当前要提交的xid
- clogGroupMemberXidStatus:当前要提交xid的状态
- clogGroupMemberPage:当前要提交xid属于哪个page
- clogGroupMemberLsn:当前要提交的xid的commit日志的lsn号(异步提交会有、同步提交没有)
struct PGPROC
{
...
...
TransactionId xid; /* id of top-level transaction currently being
* executed by this proc, if running and XID
* is assigned; else InvalidTransactionId.
* mirrored in ProcGlobal->xids[pgxactoff] */
TransactionId xmin; /* minimal running XID as it was when we were
* starting our xact, excluding LAZY VACUUM:
* vacuum must not remove tuples deleted by
* xid >= xmin ! */
LocalTransactionId lxid; /* local id of top-level transaction currently
* being executed by this proc, if running;
* else InvalidLocalTransactionId */
int pid; /* Backend's process ID; 0 if prepared xact */
int pgxactoff; /* offset into various ProcGlobal->arrays with
* data mirrored from this PGPROC */
int pgprocno; /* Number of this PGPROC in
* ProcGlobal->allProcs array. This is set
* once by InitProcGlobal().
* ProcGlobal->allProcs[n].pgprocno == n */
...
...
/* Support for group transaction status update. */
bool clogGroupMember; /* true, if member of clog group */
pg_atomic_uint32 clogGroupNext; /* next clog group member */
TransactionId clogGroupMemberXid; /* transaction id of clog group member */
XidStatus clogGroupMemberXidStatus; /* transaction status of clog
* group member */
int clogGroupMemberPage; /* clog page corresponding to
* transaction id of clog group member */
XLogRecPtr clogGroupMemberLsn; /* WAL location of commit record for clog
* group member */
...
...
};
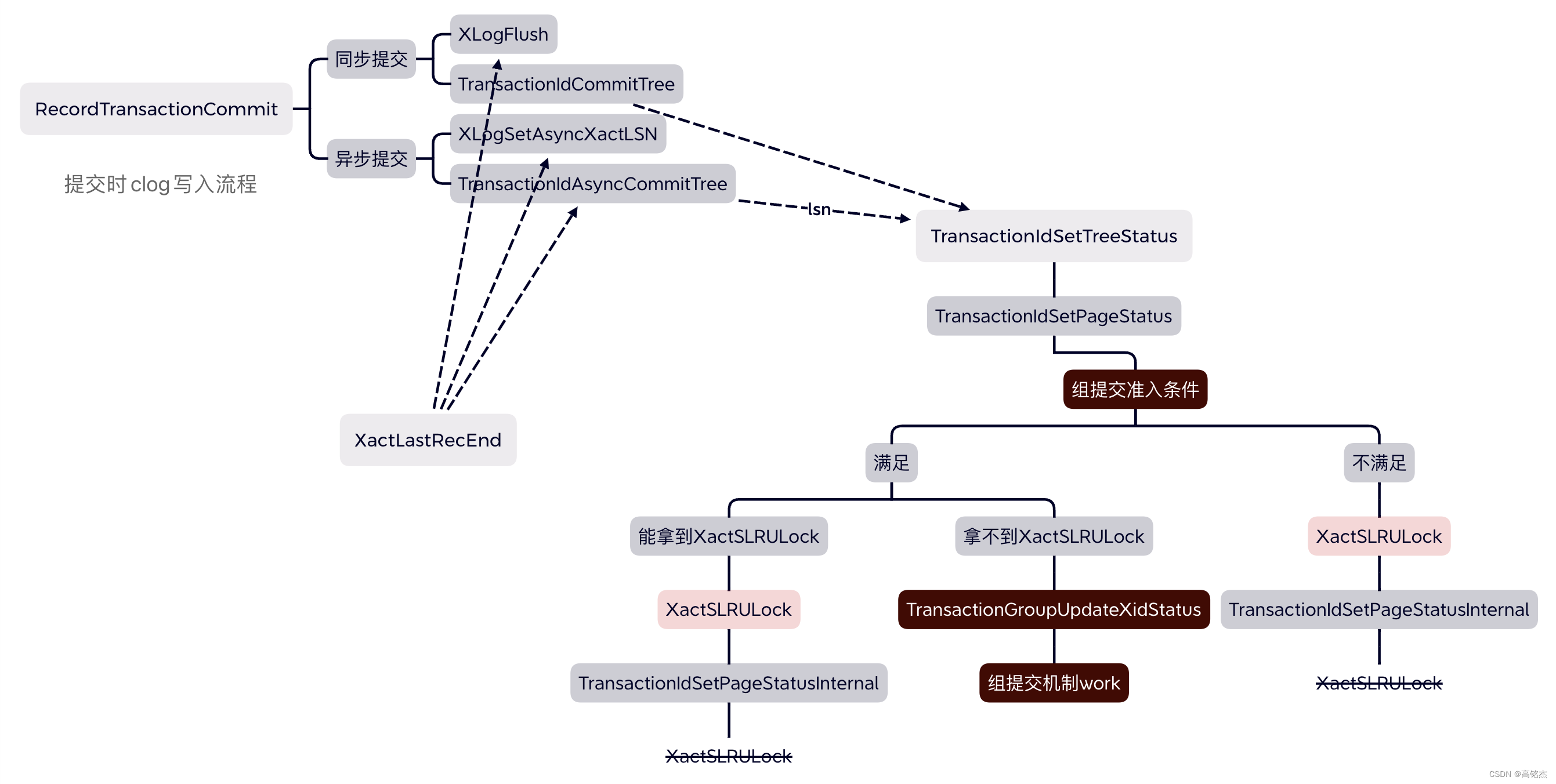
1.5 提交时CLOG写入流程
2 事务提交RecordTransactionCommit
RecordTransactionCommit
- 判断当前提交XID是否有效
if (!markXidCommitted) - 全局XactLastRecEnd判断当前事务是否有写入,
wrote_xlog = (XactLastRecEnd != 0) - 如果XID有效,写入一条commit的xlog,
XactLogCommitRecord,注意全局wrote_xlog是在上面记录的,不受这里影响。 - 记录提交时间
TransactionTreeSetCommitTsData - 如果
- 事务写了xlog
- xid有效
- synchronous_commit不是off
- 如果上述三个条件满足:同步提交
- XLogFlush(XactLastRecEnd)
TransactionIdCommitTree(xid, nchildren, children)
- 如果上述三个条件不满足:异步提交
- XLogSetAsyncXactLSN(XactLastRecEnd)
TransactionIdAsyncCommitTree(xid, nchildren, children, XactLastRecEnd)
同步提交和异步提交的区别就是是否传入XactLastRecEnd,XactLastRecEnd记录了当前事务(包含最后一条commit)产生的所有xlog的最后一条的最后一个位点。注意这个是进程私有变量。
3 CLOG写入TransactionIdSetPageStatus
老版本PG的CLOG写入流程比较简单,可以总结为下面三步:
- 拿大锁:
LWLockAcquire(CLogControlLock, LW_EXCLUSIVE) - 写入:
TransactionIdSetStatusBit;ClogCtl->shared->page_dirty[slotno] = true; - 放锁:
LWLockRelease(CLogControlLock)
新版本PG对CLogControlLock有了较大优化,主要是XactSLRULock锁优化(新版本XactSLRULock == 老版本CLogControlLock )(baaf272ac908ea27c09076e34f62c45fa7d1e448)
优化思路主要参考了procArray在高并发场景下使用单个进程来清理xid,避免ProcArrayLock的争抢。
(0e141c0fbb211bdd23783afa731e3eef95c9ad7a)

下面分析TransactionIdSetPageStatus的新流程
static void
TransactionIdSetPageStatus(TransactionId xid, int nsubxids,
TransactionId *subxids, XidStatus status,
XLogRecPtr lsn, int pageno,
bool all_xact_same_page)
{
/* Can't use group update when PGPROC overflows. */
StaticAssertDecl(THRESHOLD_SUBTRANS_CLOG_OPT <= PGPROC_MAX_CACHED_SUBXIDS,
"group clog threshold less than PGPROC cached subxids");
/*
* When there is contention on XactSLRULock, we try to group multiple
* updates; a single leader process will perform transaction status
* updates for multiple backends so that the number of times XactSLRULock
* needs to be acquired is reduced.
*
* For this optimization to be safe, the XID and subxids in MyProc must be
* the same as the ones for which we're setting the status. Check that
* this is the case.
*
* For this optimization to be efficient, we shouldn't have too many
* sub-XIDs and all of the XIDs for which we're adjusting clog should be
* on the same page. Check those conditions, too.
*/
if (all_xact_same_page && xid == MyProc->xid &&
nsubxids <= THRESHOLD_SUBTRANS_CLOG_OPT &&
nsubxids == MyProc->subxidStatus.count &&
(nsubxids == 0 ||
memcmp(subxids, MyProc->subxids.xids,
nsubxids * sizeof(TransactionId)) == 0))
需要满足
- CLOG必须都在一个页面上。(有时提交xid需要一块提交多个subxid,所以可能分布在多个页面上)
- 为了性能考虑,子事务数要少于5个。
{
/*
* If we can immediately acquire XactSLRULock, we update the status of
* our own XID and release the lock. If not, try use group XID
* update. If that doesn't work out, fall back to waiting for the
* lock to perform an update for this transaction only.
*/
if (LWLockConditionalAcquire(XactSLRULock, LW_EXCLUSIVE))
{
/* Got the lock without waiting! Do the update. */
TransactionIdSetPageStatusInternal(xid, nsubxids, subxids, status,
lsn, pageno);
LWLockRelease(XactSLRULock);
return;
}
else if (TransactionGroupUpdateXidStatus(xid, status, lsn, pageno))
{
/* Group update mechanism has done the work. */
return;
}
/* Fall through only if update isn't done yet. */
}
/* Group update not applicable, or couldn't accept this page number. */
LWLockAcquire(XactSLRULock, LW_EXCLUSIVE);
TransactionIdSetPageStatusInternal(xid, nsubxids, subxids, status,
lsn, pageno);
LWLockRelease(XactSLRULock);
}
满足组提交条件后,所有拿不到锁的PROC都会进入TransactionGroupUpdateXidStatus。
由TransactionGroupUpdateXidStatus选一个最先进来的当leader,负责后续提交。
4 组提交TransactionGroupUpdateXidStatus
4.1 整体
static bool
TransactionGroupUpdateXidStatus(TransactionId xid, XidStatus status,
XLogRecPtr lsn, int pageno)
{
volatile PROC_HDR *procglobal = ProcGlobal;
PGPROC *proc = MyProc;
uint32 nextidx;
uint32 wakeidx;
/* We should definitely have an XID whose status needs to be updated. */
Assert(TransactionIdIsValid(xid));
/*
* Add ourselves to the list of processes needing a group XID status
* update.
*/
proc->clogGroupMember = true;
proc->clogGroupMemberXid = xid;
proc->clogGroupMemberXidStatus = status;
proc->clogGroupMemberPage = pageno;
proc->clogGroupMemberLsn = lsn;
nextidx = pg_atomic_read_u32(&procglobal->clogGroupFirst);
while (true)
{
// 不在同一个页面不交给leader去做。
// 可能判断完了又不在页面了,但逻辑没问题,性能可能会差。
if (nextidx != INVALID_PGPROCNO &&
ProcGlobal->allProcs[nextidx].clogGroupMemberPage != proc->clogGroupMemberPage)
{
/*
* Ensure that this proc is not a member of any clog group that
* needs an XID status update.
*/
proc->clogGroupMember = false;
pg_atomic_write_u32(&proc->clogGroupNext, INVALID_PGPROCNO);
return false;
}
pg_atomic_write_u32(&proc->clogGroupNext, nextidx);
if (pg_atomic_compare_exchange_u32(&procglobal->clogGroupFirst,
&nextidx,
(uint32) proc->pgprocno))
break;
}
/*
* If the list was not empty, the leader will update the status of our
* XID. It is impossible to have followers without a leader because the
* first process that has added itself to the list will always have
* nextidx as INVALID_PGPROCNO.
*/
if (nextidx != INVALID_PGPROCNO)
{
int extraWaits = 0;
/* Sleep until the leader updates our XID status. */
pgstat_report_wait_start(WAIT_EVENT_XACT_GROUP_UPDATE);
for (;;)
{
/* acts as a read barrier */
PGSemaphoreLock(proc->sem);
if (!proc->clogGroupMember)
break;
extraWaits++;
}
pgstat_report_wait_end();
Assert(pg_atomic_read_u32(&proc->clogGroupNext) == INVALID_PGPROCNO);
/* Fix semaphore count for any absorbed wakeups */
while (extraWaits-- > 0)
PGSemaphoreUnlock(proc->sem);
return true;
}
/* We are the leader. Acquire the lock on behalf of everyone. */
LWLockAcquire(XactSLRULock, LW_EXCLUSIVE);
/*
* Now that we've got the lock, clear the list of processes waiting for
* group XID status update, saving a pointer to the head of the list.
* Trying to pop elements one at a time could lead to an ABA problem.
*/
nextidx = pg_atomic_exchange_u32(&procglobal->clogGroupFirst,
INVALID_PGPROCNO);
/* Remember head of list so we can perform wakeups after dropping lock. */
wakeidx = nextidx;
/* Walk the list and update the status of all XIDs. */
while (nextidx != INVALID_PGPROCNO)
{
PGPROC *nextproc = &ProcGlobal->allProcs[nextidx];
/*
* Transactions with more than THRESHOLD_SUBTRANS_CLOG_OPT sub-XIDs
* should not use group XID status update mechanism.
*/
Assert(nextproc->subxidStatus.count <= THRESHOLD_SUBTRANS_CLOG_OPT);
TransactionIdSetPageStatusInternal(nextproc->clogGroupMemberXid,
nextproc->subxidStatus.count,
nextproc->subxids.xids,
nextproc->clogGroupMemberXidStatus,
nextproc->clogGroupMemberLsn,
nextproc->clogGroupMemberPage);
/* Move to next proc in list. */
nextidx = pg_atomic_read_u32(&nextproc->clogGroupNext);
}
/* We're done with the lock now. */
LWLockRelease(XactSLRULock);
/*
* Now that we've released the lock, go back and wake everybody up. We
* don't do this under the lock so as to keep lock hold times to a
* minimum.
*/
while (wakeidx != INVALID_PGPROCNO)
{
PGPROC *wakeproc = &ProcGlobal->allProcs[wakeidx];
wakeidx = pg_atomic_read_u32(&wakeproc->clogGroupNext);
pg_atomic_write_u32(&wakeproc->clogGroupNext, INVALID_PGPROCNO);
/* ensure all previous writes are visible before follower continues. */
pg_write_barrier();
wakeproc->clogGroupMember = false;
if (wakeproc != MyProc)
PGSemaphoreUnlock(wakeproc->sem);
}
return true;
}
4.2 选主逻辑与链表构造
使用pg_atomic_compare_exchange_u32函数构造链表:
uint32 nextidx;
nextidx = pg_atomic_read_u32(&procglobal->clogGroupFirst);
while (true)
{
pg_atomic_write_u32(&proc->clogGroupNext, nextidx);
if (pg_atomic_compare_exchange_u32(&procglobal->clogGroupFirst,
&nextidx,
(uint32) proc->pgprocno))
break;
}
pg_atomic_compare_exchange_u32逻辑:
- nextidx一定会更新为procglobal->clogGroupFirst
- procglobal->clogGroupFirst会视情况更新为proc->pgprocno(1、2参相等则更新)
- 如果发生更新了,pg_atomic_compare_exchange_u32为真退出循环。
实例:
| 进程 | 全局指针:procglobal->clogGroupFirst | nextidx | 链表指针:proc->clogGroupNext |
|---|---|---|---|
| 第一个进入的进程1997(☆) | proc->pgprocno = 1997 | invalid | invalid |
| 第二个进入的进程2001(△) | proc->pgprocno = 2001 | 1997 | 1997 |
| 第三个进入的进程1998(▢) | proc->pgprocno = 1998 | 2001 | 2001 |

总结:
- nextidx都会通过全局clogGroupFirst指向链表头,记录clogGroupFirst的旧值。用于更新clogGroupNext,形成链表。
- clogGroupFirst会更新为当前进程的procno。
4.3 非leader
nextidx有值说明他不在链表第一位,非leader。
- 等leader唤醒:proc->sem。
- 其他什么都不需要做。
if (nextidx != INVALID_PGPROCNO)
{
int extraWaits = 0;
/* Sleep until the leader updates our XID status. */
pgstat_report_wait_start(WAIT_EVENT_XACT_GROUP_UPDATE);
for (;;)
{
/* acts as a read barrier */
PGSemaphoreLock(proc->sem);
if (!proc->clogGroupMember)
break;
extraWaits++;
}
pgstat_report_wait_end();
Assert(pg_atomic_read_u32(&proc->clogGroupNext) == INVALID_PGPROCNO);
/* Fix semaphore count for any absorbed wakeups */
while (extraWaits-- > 0)
PGSemaphoreUnlock(proc->sem);
return true;
}
4.4 leader
- 拿XactSLRULock干活(Leader只能有一个,拿锁是为了避免和其他场景竞争,比如非组提交的场景 或是ExtendCLOG)。
- 拿着锁后,下一个进来的进程有两种结果:
- 第一种:clogGroupFirst还没清:继续挂链表
- 第二种:clogGroupFirst清理了:成为新的leader
LWLockAcquire(XactSLRULock, LW_EXCLUSIVE);
这里进来的新进程会继续挂链表
nextidx = pg_atomic_exchange_u32(&procglobal->clogGroupFirst,
INVALID_PGPROCNO);
这里进来的进程会成为新的leader,注意新的链表不会覆盖旧的,因为链表是由每个进程的proc->clogGroupNext构成的,新链表和旧链表的Proc不可能重复。
/* Remember head of list so we can perform wakeups after dropping lock. */
wakeidx = nextidx;
开始干活,从链表最后一个位置做。
while (nextidx != INVALID_PGPROCNO)
{
PGPROC *nextproc = &ProcGlobal->allProcs[nextidx];
/*
* Transactions with more than THRESHOLD_SUBTRANS_CLOG_OPT sub-XIDs
* should not use group XID status update mechanism.
*/
Assert(nextproc->subxidStatus.count <= THRESHOLD_SUBTRANS_CLOG_OPT);
TransactionIdSetPageStatusInternal(nextproc->clogGroupMemberXid,
nextproc->subxidStatus.count,
nextproc->subxids.xids,
nextproc->clogGroupMemberXidStatus,
nextproc->clogGroupMemberLsn,
nextproc->clogGroupMemberPage);
/* Move to next proc in list. */
nextidx = pg_atomic_read_u32(&nextproc->clogGroupNext);
}
/* We're done with the lock now. */
LWLockRelease(XactSLRULock);
都做完了,唤醒等待的进程。
while (wakeidx != INVALID_PGPROCNO)
{
PGPROC *wakeproc = &ProcGlobal->allProcs[wakeidx];
wakeidx = pg_atomic_read_u32(&wakeproc->clogGroupNext);
pg_atomic_write_u32(&wakeproc->clogGroupNext, INVALID_PGPROCNO);
/* ensure all previous writes are visible before follower continues. */
pg_write_barrier();
wakeproc->clogGroupMember = false;
if (wakeproc != MyProc)
PGSemaphoreUnlock(wakeproc->sem);
}
return true;