目录
RL理解要点
1. RL数学基础
1.1 Random Variable 随机变量
1.2 概率密度函数 Probability Density Function(PDF)
1.3 期望 Expectation
1.4 随机抽样 Random Sampling
2. RL术语 Terminologies
2.1 agent、state 和 action
2.2 策略 policy π
2.3 奖励 reward
2.4 状态转移 state transition
2.5 agent environment interaction 环境交互
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
2.7 play the game using AI
2.8 rewards、returns
2.8.1 Discounted return Ut 折扣回报
2.8.2 Random in Returns
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)
2.9.2 Optimal action-value function Q*
2.9.3 State-value function Vπ
3. How does AI control the agent?
3.1 policy function π
3.2 Q*(s, a)函数
3.3 Open AI gym
参考
RL理解要点
- RL学什么呢?就是要学习policy策略函数
1. RL数学基础
1.1 Random Variable 随机变量
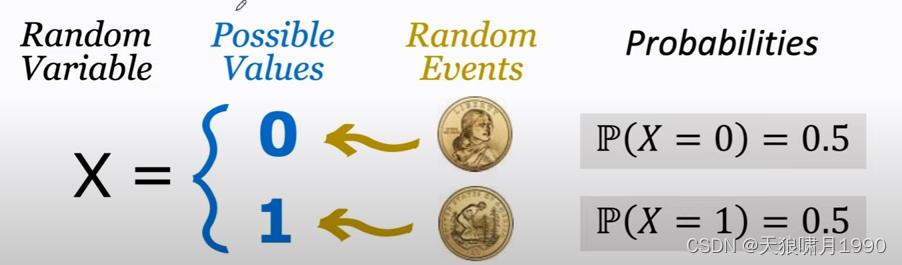
Random Variable: a variable whose values depend on outcomes of a random event. 随机变量是一个未知的量,它的值取决于随机事件的结果。
用大写字母表示随机变量 random variable,用小写字母表示随机变量观测值 observed value。
1.2 概率密度函数 Probability Density Function(PDF)
本质:就是一个概率分布(0.2, 0.3, 0.5)。
PDF provides a relative likelihood that the value of the random variable would equal that sample.
e.g. Gaussian distribution
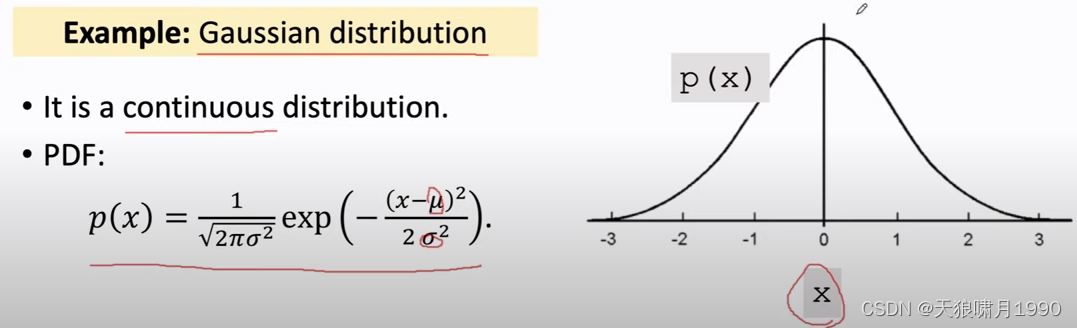
连续分布、离散分布。用表示其定义域domain

1.3 期望 Expectation
本质:是平均值,是预估结果。

1.4 随机抽样 Random Sampling

2. RL术语 Terminologies
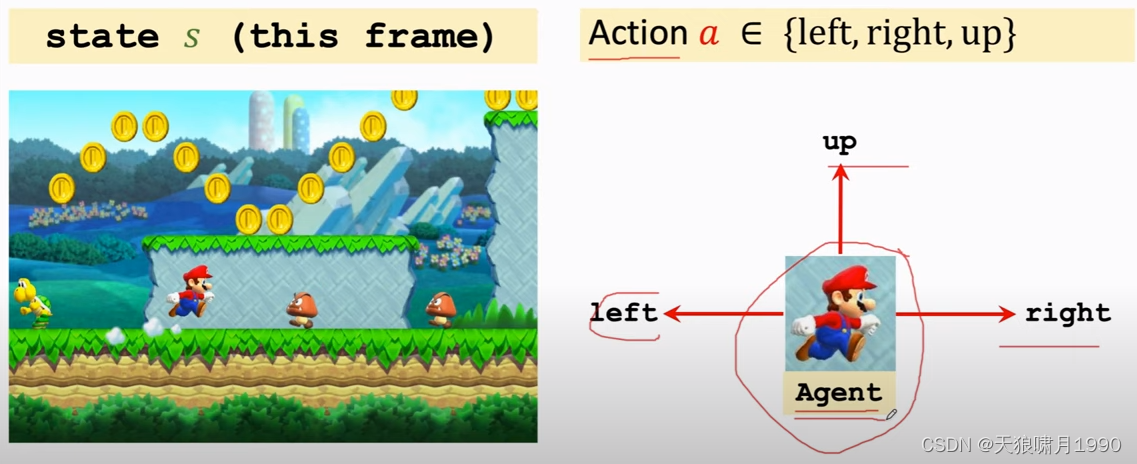
2.1 agent、state 和 action
- 可以近似理解当前图片frame就是state
- agent,翻译为“智能体”
- 当前state,agent可以做的动作叫action,包括{'left', 'right', 'up'}
2.2 策略 policy π
本质:policy策略是一个概率密度函数,就是根据state生成一个动作action概率分布。
policy根绝观测到状态state,做出决策,然后控制agent运动。
Note that policy函数是随机的。

2.3 奖励 reward
agent做出一个动作,游戏就会给出一个奖励reward
奖励定义的好坏,非常影响强化学习的结果。

2.4 状态转移 state transition
agent做出一个动作,游戏就会给出一个新的状态state,这个过程就叫state transition。
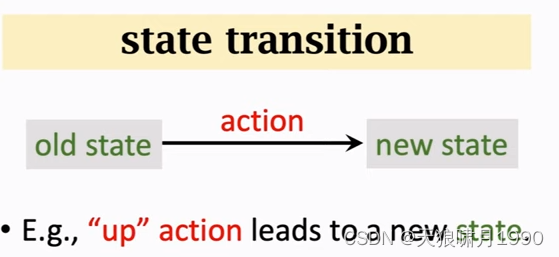
- state transition can be random.
- randomness is from the environment. 状态转移的随机性是从环境中来的,这里的环境是游戏的程序。
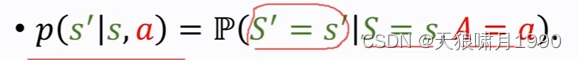
可以把状态转移用p函数来表示,这是个条件概率密度函数,意思是如果观测到当前状态s和动作a ,p函数就表示s prime的概率。
2.5 agent environment interaction 环境交互

agent和environment,agent看到状态st之后,要做出一个动作at,agent做出动作at后,环境environment会更新状态、把状态变成st+1,同时environment还会给agent一个奖励rt。
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
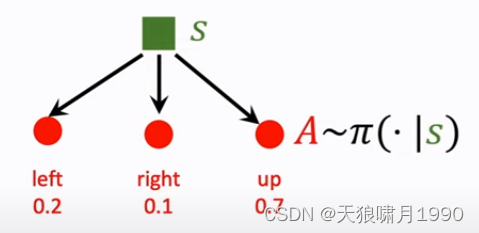
- Actions have randomness. actions是根据policy函数随机抽样得到的,我们用policy函数来控制agent,给定当前状态s,agent输出的动作a是根据策略函数policy输出的概率分布来随机抽样。
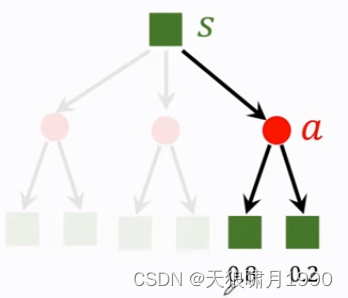
- state transitions have randomness. 假定agent做出了up action,环境environment就要生成下一个状态s',这个状态s'具有随机性,environment用状态概率转移函数p算出概率,然后用概率来随机抽样得到下一个状态s',
2.7 play the game using AI
通过强化学习学出policy function π,AI就是用policy函数来控制agent。

游戏当前状态s1,AI用policy函数来算一个概率,然后随机抽样得到动作a1,然后环境会生成下一个状态s2,并且给agent一个奖励r1,然后环境会拿新的状态s2作为输入,并用policy function来算概率,然后随机抽样得到新的动作a2,然后这样一直循环下去,直到打赢游戏或game over。
得到一个轨迹(state, action, reward)trajectory:s1,a1,r1,s2,a2,r2,...,st,at,rt。
2.8 rewards、returns
Return翻译为“回报”,也称作cumulative future reward,“未来的累积奖励”。
把t时刻的return记作Ut,就是把从t时刻开始的reward全都加起来,一直加到游戏结束时的最后一个奖励。
Question: Are Rt and Rt+1 equally important?
Future reward is less valuable than present reward.
Rt+1 should be given less weight than Rt. --> Discounted return
2.8.1 Discounted return Ut 折扣回报
γ,折扣率 discount rate gamma(tuning hyper-parameter),介于[0, 1]。

折扣率是个超参数,需要我们自己来调,折扣率的设置对强化学习的效果有一定的影响。
Ut用来衡量未来总收益。
2.8.2 Random in Returns
Return Ut的随机性。假如游戏已经结束了,所有的奖励已经观测到了,那么奖励是数值,用rt表示;如果在t时刻游戏还没结束,那么奖励还是随机变量,还没被观测到,用Rt表示。

随机性有两个来源:一是action a是从policy概率分布中随机抽样得到的;二是下一状态new state,状态转移函数p输出一个概率分布,environment从中随机抽样得到一个新的状态s'。
- For any i ≥ t, the reward Ri depends on Si and Ai. 当前agent处在的状态s和做出的动作a,就决定了奖励Ri是什么。
- 回报Ut是Rt、Rt+1等等的加权求和,而Ri是由Si和Ai决定的,所以给定st,Ut跟t时刻开始所有的动作At,At+1,At+2,..和状态St+1,St+2,...都有关了。
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)

在t时刻,你并不知道Ut是什么。Ut是个随机变量,它依赖于未来所有的动作At,At+1,At+2,...和未来所有的状态St,St+1,St+2,...
Ut未知,那我该怎么评估当前的形势呢?
对Ut求期望,把里面的随机性都用积分积掉,得到一个实数。
把Ut当作未来所有动作Ai和所有状态Si的一个函数,未来的动作和状态都有随机性,动作Ai的概率密度函数是policy function π,状态Si的概率密度函数是状态转移函数p,期望就是针对未来Si和Ai求得,出了St和At,其余的随机变量都是积分积掉,被积掉的是At+1,At+2等动作、St+1,St+2等动作,求期望得到的动作价值函数Qπ,其只跟当前动作at、状态st有关。
函数Qπ还与policy function π有关,因为积分时会用到policy函数,π函数不一样,Qπ就会不一样。
Qπ的直观意义:如果用状态价值函数Qπ,那么在当前状态st下做动作at是好还是坏。
已知policy函数π,那么Qπ就会给当前状态下所有动作A打分,然后就知道哪个动作好、哪个动作不好。
2.9.2 Optimal action-value function Q*
如何把action-value function中的π去掉呢?
可以对Qπ关于π求最大化。意思是我们有无数种policy函数π,但我们应该使用最好的那一种!
最好的policy函数就是让Qπ最大化的那个π,得到函数Q*称为optimal action-value function。

Q*跟π无关,它的直观意义:Q*可以用来对当前动作at做评价--分数,比如下围棋是,你把棋子放在这个位置胜算有多大,你把棋子放在那个位置胜算有多大。
Q*非常有用,agent可以根据Q*对actions的评价来做决策。
2.9.3 State-value function Vπ

状态价值函数Vπ,它是action-value function动作价值函数Qπ的期望。
Qπ与状态st、动作A有关,可以把A当作随机变量,求期望把它消掉,这样Vπ只跟st和π有关。
Vπ直观意义:Vπ可以告诉我们当前局势好不好,比如下围棋,Vπ可以告诉我们当前胜算有多大,是快赢了还是快输了。
![]()
这里的期望是根据A求得,A的概率密度函数是policy function π。根据期望定义,可以把期望写成连加或积分的形式。
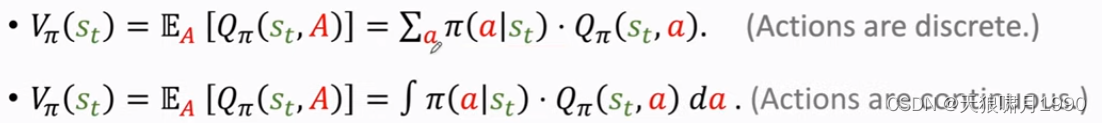
For fixed policy π, Vπ(s) evaluates how good the situation is in state s.
Es[Vπ(S)] evaluates how good the policy π is.
3. How does AI control the agent?
3.1 policy function π
一种方法是学一个策略函数policy π
有了policy 函数π,就可以用来控制agent来做动作。

3.2 Q*(s, a)函数
另一种方法是学习optimal action-value function Q*(s, a)函数,它是value based model
假如有了Q*函数,agent可以根据Q*函数来做动作了。
如果处在状态s,那么做动作a是好还是坏。没观测到一个状态st,就把st作为Q*函数的输入,让Q*函数对每一个函数做一个评价,假如up move的q值最大,因为q值是对未来奖励reward总和的期望,所以选up获取以期在未来获得更多奖励。

3.3 Open AI gym
- 经典控制问题
- atari game
- 连续控制问题 continuous control tasks


参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html